- The paper introduces CodeAct, integrating executable Python code into LLM agents to expand action spaces and enable dynamic multi-turn interactions.
- It demonstrates a 20% success rate improvement and a 30% reduction in action steps compared to traditional JSON or text-based methods.
- The approach paves the way for more autonomous agents with enhanced task-solving and self-debugging through integrated Python libraries.
Executable Code Actions Elicit Better LLM Agents
In the paper "Executable Code Actions Elicit Better LLM Agents," the authors investigate the use of executable Python code to enhance the capabilities of LLM agents. The traditional approach for LLMs has been to generate actions using JSON or text within pre-defined formats, which often restricts the scope and flexibility of the actions due to constrained action spaces. The proposed solution, CodeAct, seeks to address these limitations by consolidating LLM agents’ actions into a unified action space using executable Python code.
CodeAct Framework and Implementation
CodeAct integrates Python code directly into LLM agents, allowing them to execute code actions and dynamically adapt their actions based on new observations through multi-turn interactions. The framework leverages a Python interpreter to facilitate code execution, enabling dynamic revisions and new action emissions as the agent interacts with its environment. This approach significantly broadens the action space, allowing LLMs to utilize a diverse range of Python packages and automated feedback mechanisms, such as error messages for self-debugging, to optimize task-solving.
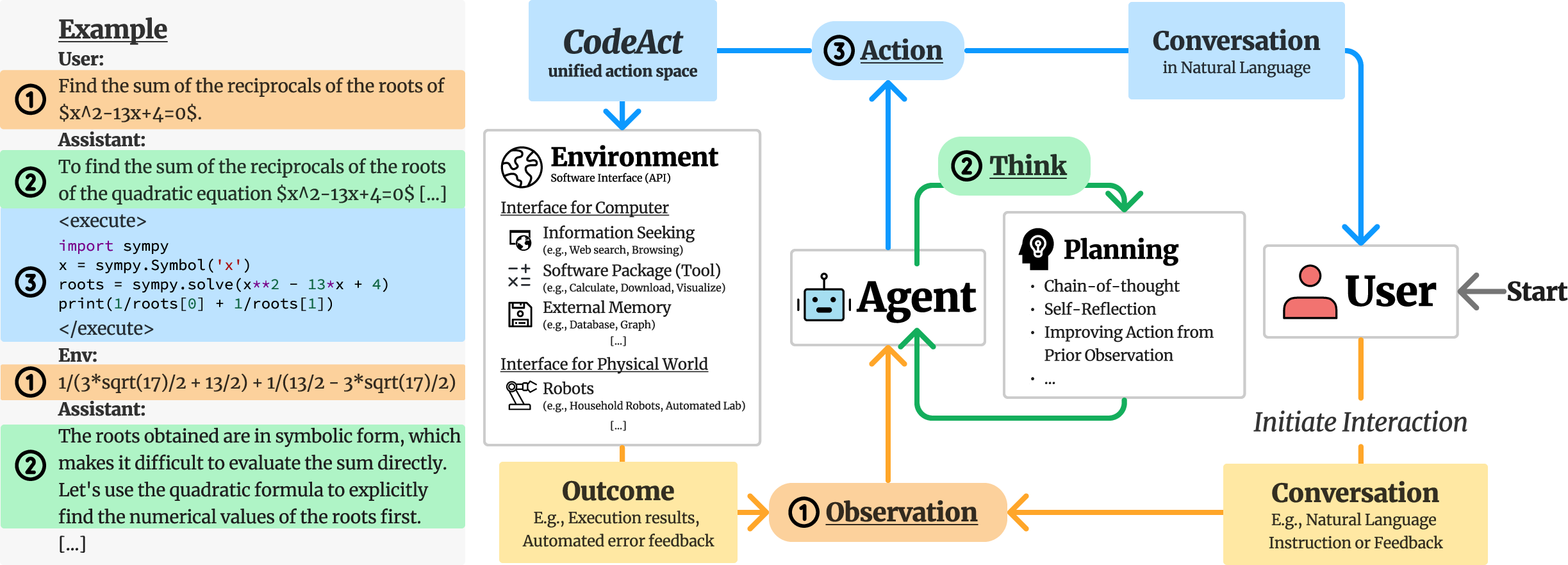
Figure 1: General agent multi-turn interaction framework highlighting the role of CodeAct in agent-environment and agent-user interaction.
An extensive evaluation of 17 LLMs on both existing benchmarks like API-Bank and a newly curated benchmark, M3ToolEval, reveals that CodeAct significantly outperforms traditional text or JSON actions. Notably, CodeAct achieves up to 20% higher success rates in complex task scenarios requiring multiple tool invocations over multi-turn interactions.
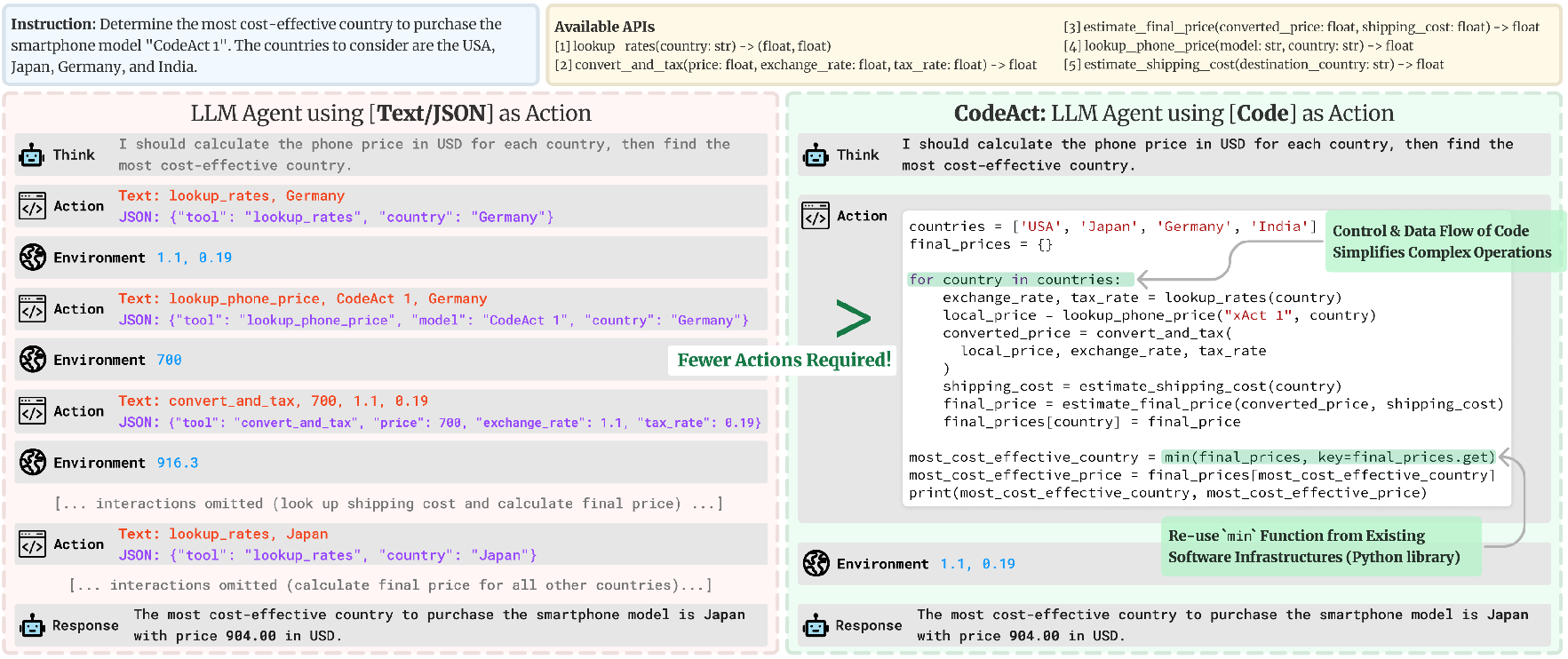
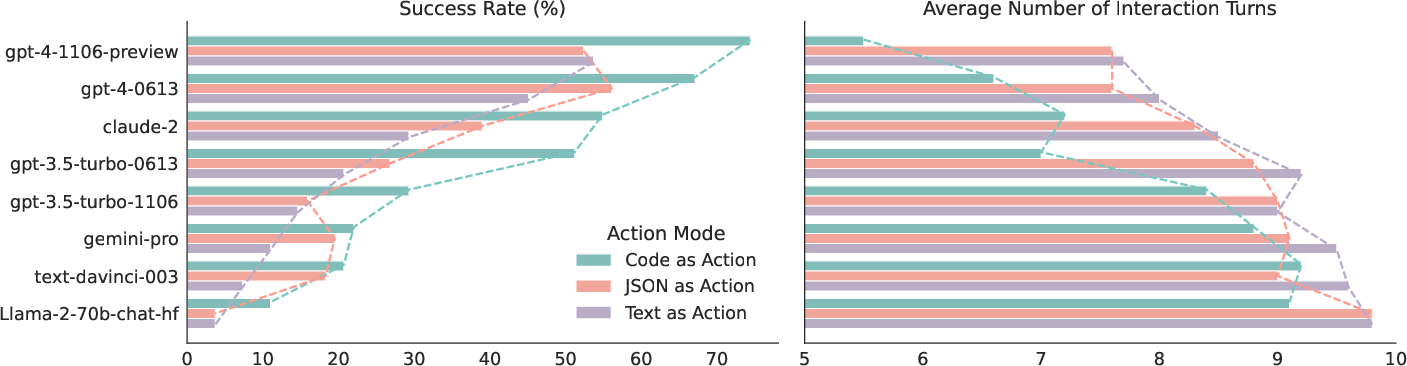
Figure 2: Comparison between CodeAct and Text / JSON as action, showing CodeAct's superior performance on M3ToolEval.
The evaluation criteria focused on the capability of LLMs to utilize control and data flow features inherent to Python, allowing more sophisticated logical operations such as loops and conditional statements within a single code block. This approach proved more efficient, reducing the number of necessary actions by up to 30% compared to JSON or text.
CodeActAgent Development
Motivated by CodeAct's success, the authors developed an open-source LLM agent, CodeActAgent, which integrates seamlessly with Python interpreters. This agent is capable of handling complex tasks such as model training and data visualization autonomously by leveraging existing libraries. The CodeActAgent was finetuned using CodeActInstruct, a dataset consisting of 7,000 multi-turn interactions focused on improving the agent's task-solving and self-debugging capabilities.

Figure 3: Example multi-turn interaction with Python packages using CodeActAgent.
Implications and Future Directions
The findings from the study suggest significant practical implications for the design of LLM agents. By directly integrating executable code actions, developers can construct more flexible and capable agents that require less human intervention for fine-tuning and can autonomously adapt to complex, dynamic environments. This approach opens pathways for more generalized task-solving abilities across diverse applications, potentially reducing the overhead required to tailor LLMs for specific use-cases.
Future research may explore further optimizations and extensions of the CodeAct framework to other programming environments, expanding its applicability to different domains and further enhancing the adaptability of LLM agents. Additionally, work could be aimed at improving the open-source LLM models to reduce the performance gap observed with proprietary models.
Conclusion
"Executable Code Actions Elicit Better LLM Agents" introduces a compelling approach to developing more versatile and powerful LLM agents. By harnessing the capabilities of executable Python code, CodeAct addresses existing limitations in LLM agent design, offering a scalable solution to enhance real-world task-solving through multi-turn interactions and dynamic action adjustments. The findings underscore the potential of this approach to significantly impact AI applications across various fields, setting the stage for future advancements in autonomous agent development.