- The paper demonstrates an autoregressive Transformer that generates explicit 3D Gaussian point clouds without fixed template constraints.
- It introduces a dual-stage pipeline combining AR-based geometry prediction with a Gaussian Decoder for detailed attribute rendering.
- It achieves state-of-the-art performance with metrics like FID (95.18) and LPIPS (0.15), enabling high-fidelity, real-time avatar animation.
AvatarPointillist: AutoRegressive 4D Gaussian Avatarization
Introduction
The paper "AvatarPointillist: AutoRegressive 4D Gaussian Avatarization" (2604.04787) presents an end-to-end pipeline for constructing dynamic, animatable 4D Gaussian avatars from a single portrait image. The primary contribution is the introduction of a decoder-only Transformer architecture that autoregressively generates explicit 3D Gaussian point clouds, entirely eschewing fixed template constraints and enabling adaptivity in both spatial point density and count as required by subject complexity. This method directly addresses the limitations of static-topology approaches, particularly their inability to capture fine-geometry and identity details, and their poor handling of subject-specific topology variation.
Traditional 2D-based avatar animation approaches, primarily GAN- and diffusion-based, suffer from a lack of explicit 3D awareness, leading to artifacts under large pose changes and a lack of view-consistency. 3D-aware methods, while more robust in handling pose and multi-view requirements, are often built on NeRF representations—incurring slow rendering and limited fine-detail control—or use 3D Gaussian Splatting (3DGS) over rigid templates, leaving no mechanism for allocating points adaptively.
The proposed method is motivated by the observation that explicit, adaptive control of geometry is essential for fidelity and generalizability of avatars, especially in complex facial regions such as hair and beards. Figure 1 illustrates the inability of template-based 3DGS methods (e.g., LAM) to reconstruct subject-specific features, contrasting with the output of the proposed autoregressive model.
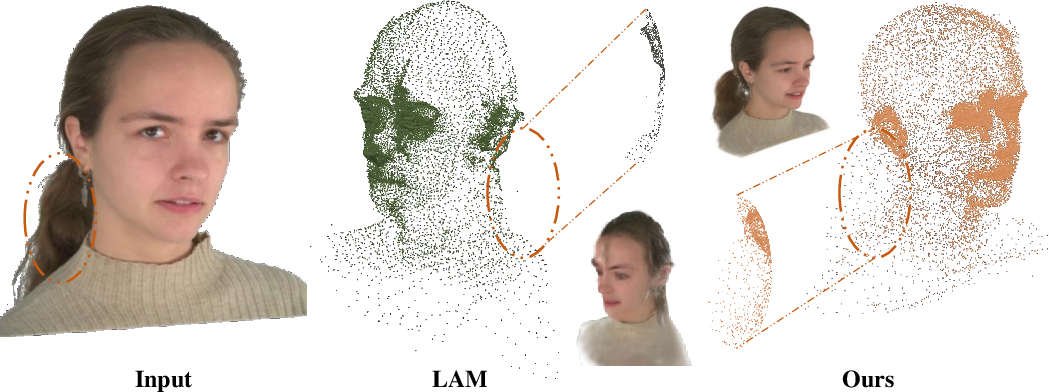
Figure 1: Comparison between LAM and the autoregressive approach on Gaussian point cloud modeling and final rendering, demonstrating superior adaptability to geometric detail.
Method
Data Construction and Quantization
High-quality, rigged 3DGS data is constructed for each subject via a fitting protocol on the Nersemble and GaussianAvatars datasets. The resulting explicit Gaussian point cloud for each identity is quantized to integer tokens using a fixed y-z-x sorting order, with coordinates and binding indices discretized into 1024 and up to 11167 bins, respectively. This processing is critical for compatibility with autoregressive token modeling, ensuring consistent, permutation-invariant representations.
Autoregressive Point Cloud Generation
The core of the system is a decoder-only Transformer model which, conditioned on DINOv2 and point cloud encoder features, autoregressively predicts the tokenized Gaussian point cloud sequence. Multi-source conditioning is delivered via cross-attention between visual features extracted from the input image and implicit geometric cues (FLAME parameters, mesh vertices). The autoregressive, next-token prediction objective enables the model to capture geometric priors for adaptive point placement, eschewing any fixed topology or template.
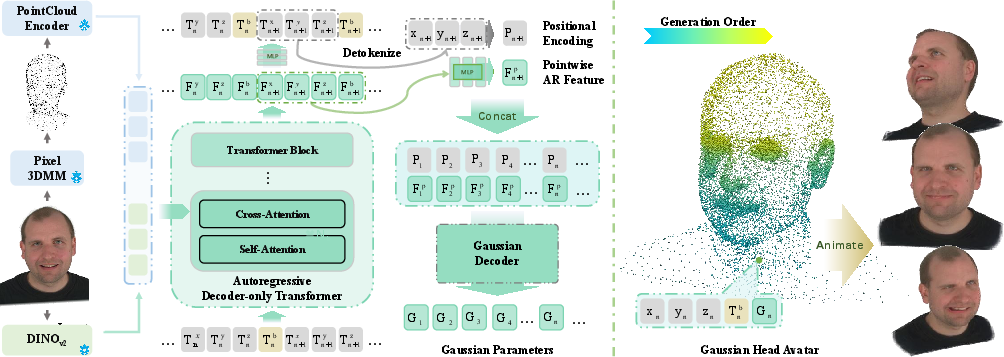
Figure 2: Diagram of the two-stage AvatarPointillist pipeline, with autoregressive Gaussian geometry generation followed by attribute prediction via the Gaussian Decoder.
Gaussian Decoder and Attribute Prediction
Upon predicting the geometry and binding tokens, a separate Transformer-based Gaussian Decoder predicts full attribute sets for every Gaussian (color, opacity, scale, rotation, position offset). This decoder leverages both the reconstructed spatial embeddings and the final hidden states from the AR model, merging geometric context with pointwise semantic features. The decoder’s ability to operate on explicit, unconstrained point clouds further empowers high-fidelity appearance synthesis and precise animation control.
Animation and Rigging
Animation is achieved by utilizing the predicted point-to-face bindings. LBS and blendshapes, informed by barycentric interpolation of FLAME mesh attributes, are used to animate Gaussian points according to target pose and expression parameters. This architectural choice ensures temporal and geometric consistency during pose-driven reenactment.
Results
Qualitative Assessment
The method demonstrates substantial qualitative improvements over NeRF-based (Portrait4Dv2, AvatarArtist) and template-based Gaussian (LAM, GAGAvatar) baselines. The produced avatars display high-fidelity pose and expression transfer across wide pose variation, with robust preservation of subject identity and intricate features (see Figure 3).

Figure 3: Qualitative comparison showcasing expression, pose, and identity preservation in both self- and cross-reenactment scenarios by the proposed method and several baselines.
Quantitative Evaluation
The approach surpasses all compared baselines in FID (95.18), LPIPS (0.15), AKD (2.38), APD (22.86), and CLIPScore (0.75), establishing new state-of-the-art metrics on the Nersemble evaluation benchmark. Both self- and cross-reenactment are handled with marked accuracy, and identity leakage/over-smoothing seen in prior systems is substantially reduced.
Ablation Studies
Ablations confirm that dynamic point cloud generation and the use of both AR model features and spatial embeddings in the Gaussian Decoder are directly responsible for quality gains. Static-topology baselines, including LAM-like variants, fail to adapt point allocations to geometry, resulting in geometric and photometric degradation (see Figure 4). Using the internal AR features alone is insufficient; only their combination with explicit spatial cues yields maximal performance.

Figure 4: Visual ablation of Gaussian Decoder input settings, showing the necessity of fusing position and semantic AR features for maximal rendering quality.
Implications and Future Directions
The introduction of an explicit, autoregressive token-based pipeline for 4D Gaussian avatarization marks a divergence from topology-constrained paradigms, enabling scalable, template-free adaptation of geometric density and distribution. This advance is crucial for high-fidelity, controllable avatar synthesis and supports arbitrary reanimation across large motion and pose domains in telepresence, VR, and entertainment.
The autoregressive discretization strategy draws methodologically from transformer-based shape generation, pointing toward future unification of geometry, appearance, and semantics under a generalized AR or large multimodal model scaffold. The flexible architecture lends itself to rapid extension—potentially towards multimodal input (e.g., audio-driven dynamics), domain-agnostic arbitrary subject adaptation, or hierarchical/hybrid explicit-implicit systems.
On the theoretical front, this framework invites further exploration into geometry-aware tokenization, scale-specific AR inference, and efficient cross-modal conditioning, especially as model sizes and training data continue to scale.
Conclusion
AvatarPointillist substantiates the viability of template-free, autoregressive generation of 4D Gaussian avatars, supporting high-fidelity, real-time animation from a single input portrait. The explicit modeling of both geometry and attributes via a dual-Transformer pipeline yields significant quality improvements in geometric adaptation, identity preservation, and photorealistic rendering, establishing new baselines for 4D human avatar synthesis. This work signals a convergence of language-model-style AR generative techniques and geometric explicit modeling, opening several promising research avenues for future avatar and geometric generative models.


