- The paper proposes a VR system that uses 3D Gaussian Splatting and Binocular Batching to enable photorealistic, real-time avatar rendering.
- It reconstructs a full-body, animatable avatar from a single image by leveraging SMPL-X pose estimation and transformer-based feature encoding.
- Experimental results show improved image fidelity (L1, LPIPS, PSNR, SSIM) and enhanced user embodiment compared to traditional mesh-based methods.
VRGaussianAvatar: Real-Time 3D Gaussian Avatars in Virtual Reality
Overview and Motivation
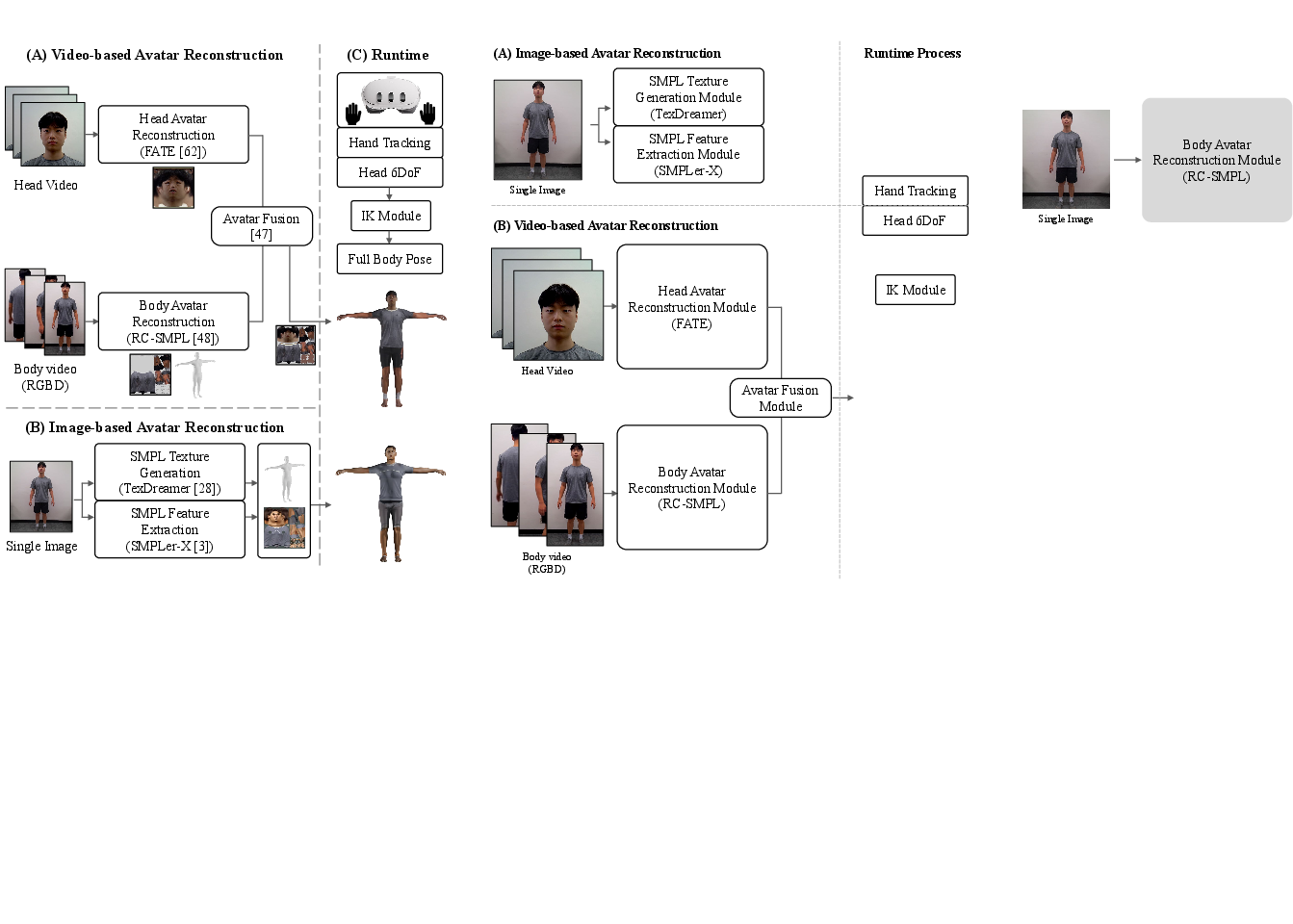
The paper "VRGaussianAvatar: Integrating 3D Gaussian Avatars into VR" (2602.01674) presents a system for full-body, photorealistic avatar representation in VR, leveraging 3D Gaussian Splatting (3DGS) as a rendering primitive. Unlike prior mesh- or NeRF-based pipelines, the proposed system supports the reconstruction and real-time control of a complete animatable avatar directly from a single image, using only the tracking signals available from commercial head-mounted displays (HMDs). The system architecture is designed to minimize redundant computation and streamline VR integration.
Rendering high-fidelity personalized avatars has long been recognized as essential for presence and communication in virtual environments. The paper positions its technical contributions at the intersection of high-resolution neural rendering (specifically, 3DGS), efficient VR streaming architectures, and user-driven perceptual evaluation, seeking to address the computational, interaction, and perceptual constraints impeding current approaches.
System Architecture
The core system is a two-part pipeline: a VR Frontend and a GA Backend (Gaussian Avatar Backend). The VR Frontend acquires 6DoF head and articulated hand tracking from the HMD, estimates full-body SMPL-X–compatible pose parameters using inverse kinematics (IK), generates real-time stereo camera parameters, and streams this per-frame data to the rendering backend. The GA Backend animates and renders a 3DGS avatar, which is reconstructed from a single A-pose image via an LHM-based model, supporting SMPL-X articulation.
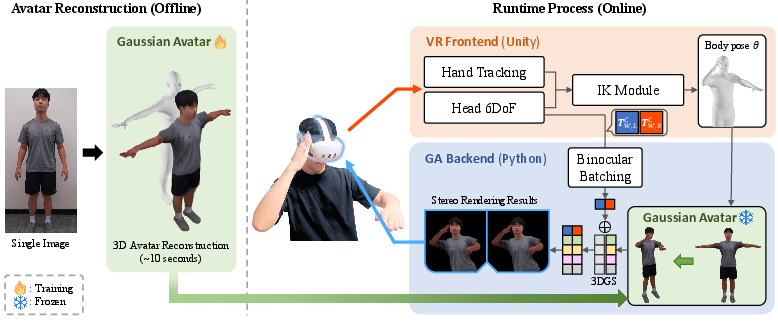
Figure 1: Architecture of VRGaussianAvatar: left, the offline avatar reconstruction stage from a single image; right, the parallel VR Frontend (pose estimation/tracking) and GA Backend (stereoscopic 3DGS rendering and Binocular Batching) for real-time deployment.
A key innovation is the Binocular Batching approach for stereoscopic rendering: both left and right eye images are rendered in a single GPU batch, sharing memory for dynamic Gaussian attributes, which substantially reduces per-frame latency and redundant computation. This enables high-FPS, high-resolution VR rendering without perceptible compromise in image quality.
Avatar Reconstruction and Animation Pipeline
The avatar reconstruction pipeline employs a transformer-based architecture that encodes geometric and appearance features from the SMPL-X template and input image, producing a canonical 3D Gaussian set with parametric rigging suitable for SMPL-X pose control. Canonical Gaussians are animated via linear blend skinning with per-Gaussian bone weights, then rendered with standard 3DGS rasterization for both eye views under the Binocular Batching strategy.
The modularity of the backend supports integration of various state-of-the-art single-image 3DGS avatar construction methods, but the paper adopts LHM [qiu2025lhm] for its efficiency and quality, enabling full-body avatar reconstruction in approximately 10 seconds.
Experimental Evaluation
Baseline Comparisons
Two primary baselines are used for comparison under strict HMD-only control (no external trackers):
Quantitative Results
Quantitative measures (L1, LPIPS, PSNR, SSIM) demonstrate that VRGaussianAvatar delivers the best photorealistic fidelity, clearly outperforming both video- and image-based mesh methods:
- L1: 0.033 (VRGA, ↓ best), 0.042 (video), 0.043 (image)
- LPIPS: 0.082 (VRGA, ↓ best), 0.099 (video), 0.103 (image)
- PSNR: 17.92 dB (VRGA, ↑ best), 16.33 (video), 16.74 (image)
- SSIM: 0.934 (VRGA, ↑ best), 0.927 (video), 0.917 (image)
Binocular Batching achieves ≈40 FPS at 1024×1024 per eye, exhibiting ~35% reduction in rendering time compared to sequential stereo passes.
User Study: Embodiment, Plausibility, and Realism
A within-subject user study with N=24 compares avatar types (self, other) and methods (VRGA, video, image) via established questionnaires (VEQ, VEQ+, VHPQ). Participants performed controlled pose-matching mirroring tasks in VR.

Figure 3: (A) User study setup—participants perform and observe mirrored poses. (B) Self (left) and other (right) avatar exemplars.
Key findings:
- Ownership and Agency: VRGaussianAvatar yields significantly higher body ownership (VBO), agency (AG), self-location (SL), self-attribution (SA), and self-similarity (SS) than both baselines (all p < .001 in main effects).
- Plauribility: Appearance and behavior plausibility (VHPQ) trended higher for VRGaussianAvatar, with significant main effects for method.
- Motion perception: VRGA outperforms baselines in subjective measures of motion realism, naturalness, and synchrony.
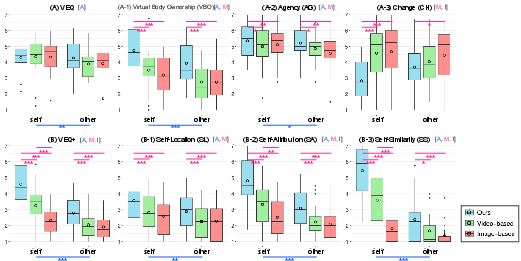
Figure 5: Aggregate results for embodiment (VEQ, VEQ+, and subscales) as a function of avatar method and type, highlighting VRGA's robust advantage.
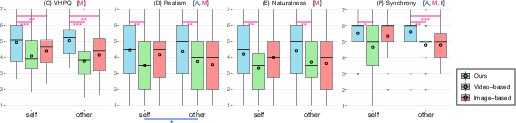
Figure 4: Plausibility questionnaire results and subjective ratings for avatar realism, naturalness, and synchrony. VRGA shows consistent improvements.
Qualitative feedback underscores improved human-likeness, natural appearance, and behavioral consistency for 3DGS-based avatars. While some limitations remain in the hand/finger region due to high articulation, overall fidelity and identification are rated conspicuously higher.

Figure 6: Qualitative comparison of VRGA and baselines for identical HMD-only control. VRGA preserves sharper features (face, clothing; sky-blue/orange boxes) superior to mesh counterparts.

Figure 7: Additional qualitative results emphasizing fine detail retention and highlighting hand-region challenges specific to current pipeline limits.
Technical and Practical Implications
The introduction of Binocular Batching for 3DGS avatars establishes an efficient rendering primitive for VR stereoscopic setups. This approach ensures that high-resolution, photorealistic avatar rendering can be performed interactively, even on a consumer-grade GPU. By decoupling pose estimation (frontend) from the large-scale neural rendering (backend), latency is minimized, and system extensibility is facilitated.
The results provide robust evidence that 3DGS-based representations, when coupled with efficient streaming and animation, attain not just higher image fidelity but also tangible perceptual and behavioral gains (embodiment, synchrony, self-likeness) critical for practical VR deployment. Of particular note is the system's ability to support self- and other-representative avatars from only monocular image input, making personalized avatar creation more accessible.
Limitations and Future Directions
Limitations include the lack of dynamic facial expression, gaze, and hand model articulation due to reliance on single-image reconstruction and HMD sensor constraints. Full compliance in generic, occluded, or arbitrary poses remains an open challenge, as does scalability to remote/cloud setups with additional network latency.
Planned future work includes:
- Integration of dynamic facial/hand modeling for emergent facial expression and gesture control.
- Robustness to unconstrained, in-the-wild input for generalized avatar construction.
- Deployment on mobile/edge devices using lightweight 3DGS distillation approaches (e.g., [iandola2025squeezeme]).
- Expanded evaluation, including egocentric and multi-user VR, to validate generalization.
Conclusion
VRGaussianAvatar demonstrates technically and perceptually validated advances in VR avatar representation by tightly integrating 3D Gaussian Splatting with VR-specific optimization (Binocular Batching) and user-centered evaluation. Strong numerical and subjective evidence illustrates consistent advantages over mesh-based approaches, especially in realistic embodiment and appearance. The proposed framework marks a meaningful step toward practical, photorealistic, and self-representative real-time avatars, opening avenues for more immersive and socially relevant VR experiences.