- The paper shows that data-centric strategies, rather than architecture changes, drive performance gains, achieving 95.69 on OmniDocBench v1.6.
- It introduces a robust Data Engine with diversity-aware sampling (DDAS) and cross-model consistency verification (CMCV) to enhance annotation quality.
- A three-stage progressive training strategy improves complex layout parsing, yielding superior results on tables, formulas, and multi-page documents.
MinerU2.5-Pro: Data-Centric Advances in Document Parsing
Introduction
The paper "MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale" (2604.04771) reorients the paradigm of document parsing research from architectural innovation to systematic data engineering. While recent state-of-the-art (SOTA) models in vision-language document parsing converge in design and saturate on classic benchmarks, failure mode analysis reveals enduring bottlenecks due to data coverage and annotation fidelity rather than architecture. MinerU2.5-Pro addresses these limitations, keeping the 1.2B-parameter decoupled coarse-to-fine model architecture fixed and targeting performance uplifts through an integrated Data Engine and progressive training methods. The resulting model achieves 95.69 on OmniDocBench v1.6, surpassing all extant systems, including those with orders-of-magnitude more parameters.
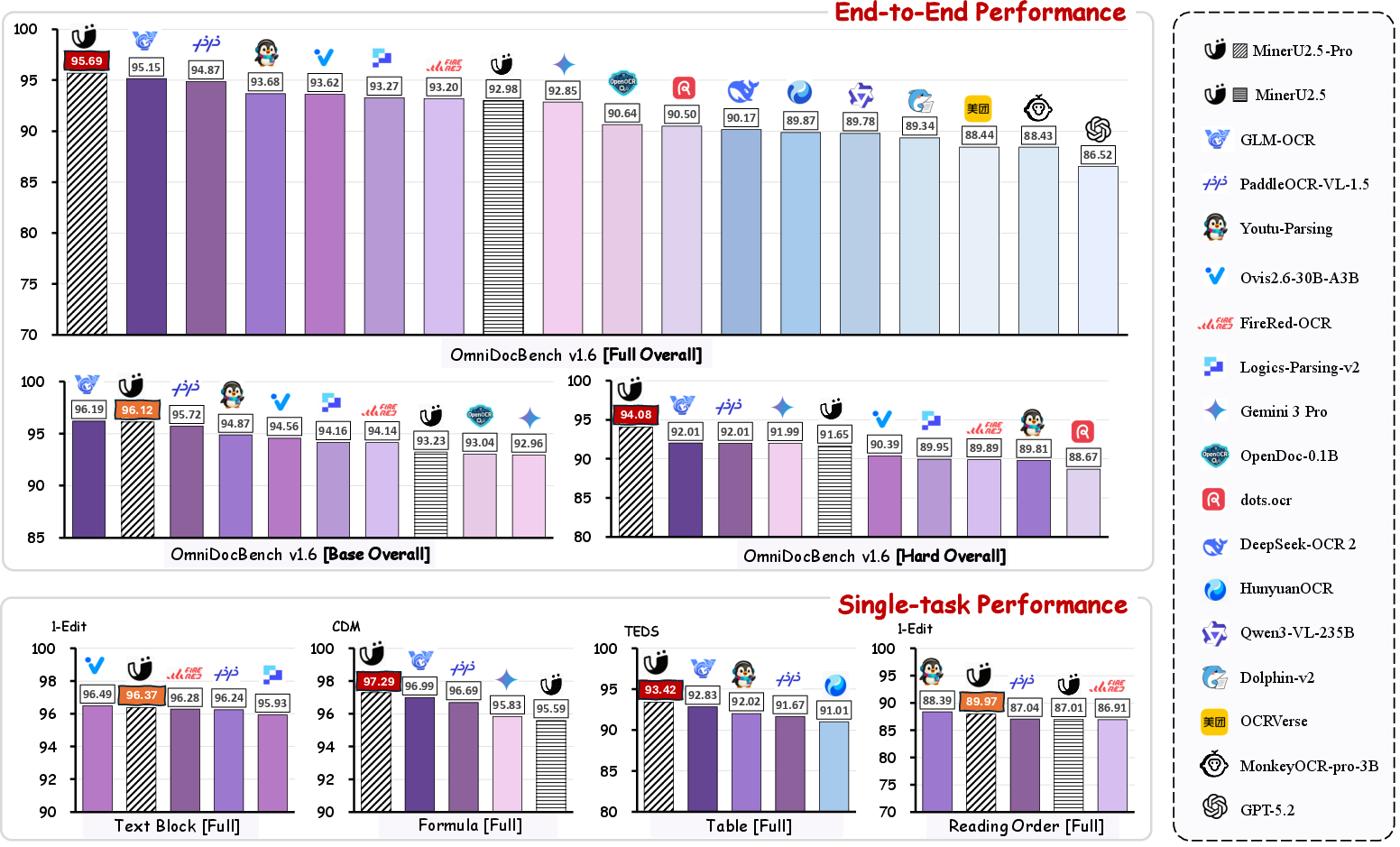
Figure 1: MinerU2.5-Pro, without architectural modification, outperforms all specialized and general-purpose VLMs on OmniDocBench v1.6 Base, Hard, and Full protocols.
Diversity-and-Difficulty-Aware Sampling (DDAS)
Effective document parsing requires coverage of the extensive long-tail of complex layouts, tables, and formulas. DDAS addresses the underrepresentation and bias of previous datasets via multi-level diversity and difficulty stratified sampling.
The process operates at both page and element levels: pages are first embedded (ViT-base), clustered, and sampled with weights reflecting both cluster diversity and multi-model-derived difficulty. Subsequently, elements (text, formula, table blocks) are clustered and sampled along analogous axes. Jointly, these mechanisms yield 60M+ balanced pages and comprehensive element-level datasets, correcting both frequency imbalance and sample informativeness.
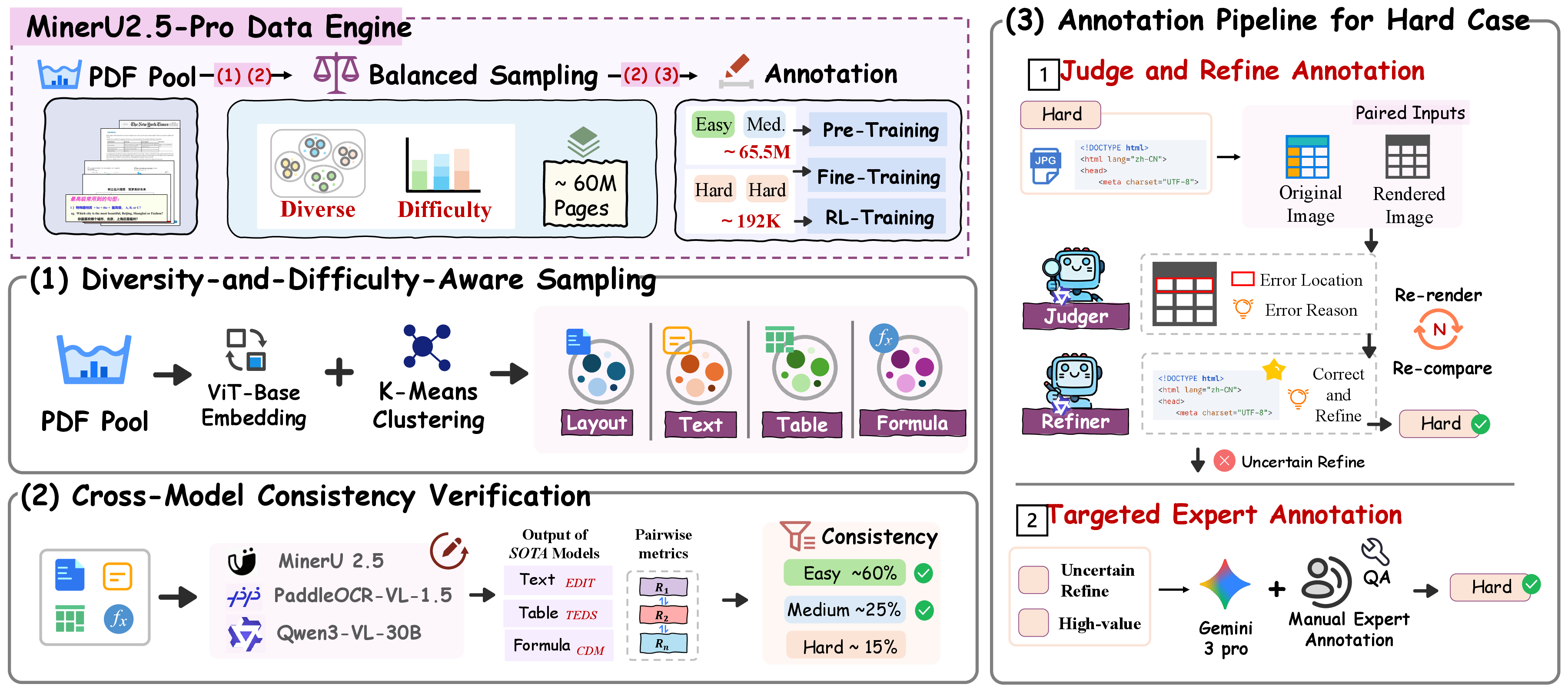
Figure 2: Four-stage Data Engine pipeline jointly expands coverage, stratifies informativeness, corrects annotation, and integrates targeted expert labeling.
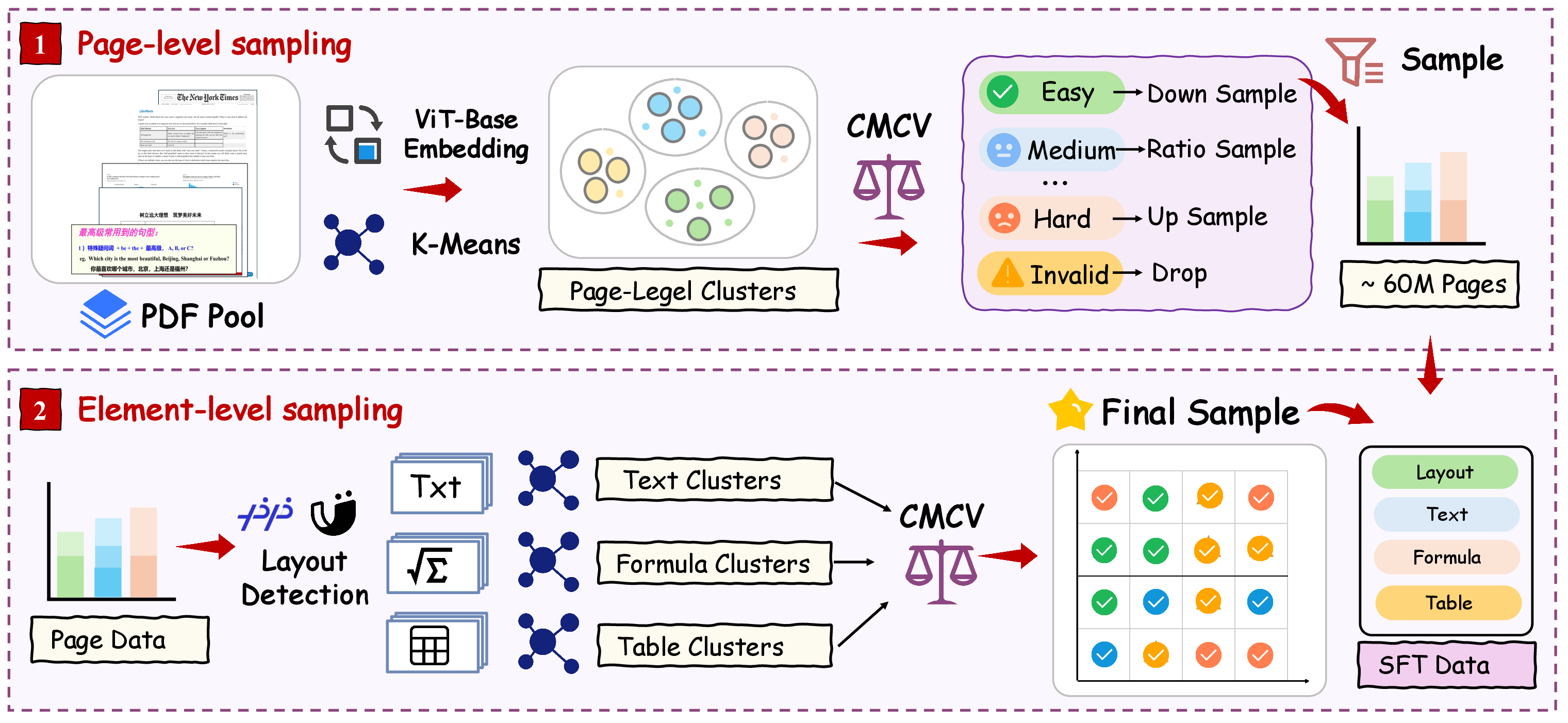
Figure 3: DDAS constructs final training data via diversity/difficulty balancing at page- and element-granularity.
Cross-Model Consistency Verification (CMCV)
Annotating the hardest and most informative samples is foundational. CMCV leverages output consistency among multiple heterogeneous SOTA parsing models (MinerU2.5, PaddleOCR-VL, Qwen3-VL-30B) to assign difficulty labels:
- Easy: Target agrees with at least one peer, suitable for direct pseudo-labeling.
- Medium: External models agree but diverge from target, best for model gap bridging.
- Hard: All models diverge, annotation is unreliable, necessitating further correction.
CMCV thereby enables unsupervised, scalable difficulty annotation on millions of unlabeled samples, ensuring that added data is maximally informative rather than amplifying bias.
Judge-and-Refine and Expert Annotation
Hard samples yield maximal utility but are high risk for noisy annotation. MinerU2.5-Pro introduces a render-then-verify iterative correction mechanism, wherein output is rendered (e.g., LaTeX, HTML) and compared visually with the original, enabling effective error detection via direct visual feedback to the model. Multiround correction is applied, using external models (Qwen3-VL-235B, Gemini 3 Pro) to avoid confirmation bias. Samples exceeding automatic correction are routed for targeted expert annotation—substantially increasing annotation ROI via DDAS/CMCV prioritization.
Three-Stage Progressive Training Strategy
A sequential curriculum leverages data of ascending quality:
- Stage 1: Large-scale supervised fine-tuning (SFT) with 65.5M CMCV-annotated samples. All model parameters are trained; primary gains derive from scale and coverage.
- Stage 2: High-quality expert-annotated (192K hard samples) stage with mixed replay to preserve generalization. Fine-tuning employs non-uniform replay ratios to account for subtask imbalance, with largest improvements in hard table and formula scenarios.
- Stage 3: GRPO-based reinforcement alignment—directly optimizing for downstream metrics (edit distance, CDM, TEDS, IOU), using high-fidelity reward computation on expert-labeled data. This drives further gains on structured outputs and hard cases.
The cumulative effect improves the MinerU2.5 baseline by 2.71 points (92.98→95.69) on OmniDocBench v1.6 Full, with pronounced robustness on the Hard subset.
OmniDocBench v1.6: Towards Discriminative and Unbiased Evaluation
Previous evaluations suffered from element-matching biases—systems producing semantically correct but differently segmented outputs were systematically penalized.

Figure 4: v1.5 element-matching biases led to under-rating semantically correct but differently segmented predictions.
OmniDocBench v1.6 introduces Multi-Granularity Adaptive Matching (MGAM), which aligns predicted and annotated elements by flexibly splitting, merging, and matching segments, neutralizing format and granularity artifacts. It also adds a curated Hard subset covering previously under-measured scenario categories (dense formulas, nested tables, complex layouts), forming a three-tier protocol (Base/Hard/Full). This enables fine-grained differentiation of system capabilities beyond the saturated “Base” regime.
System-Level Recognition Results
End-to-End Parsing and Stagewise Gains
MinerU2.5-Pro demonstrates state-of-the-art performance:
- OmniDocBench v1.6 Full: 95.69 (+2.71 over MinerU2.5 baseline).
- Hard subset: 94.08, outperforming all comparators (best alternative: PaddleOCR-VL-1.5/GLM-OCR at 92.01).
- Formulas (CDM): 97.29
- Tables (TEDS): 93.42
Stage ablation shows the largest gain from data-centric SFT (Stage 1, +1.31), followed by expert hard-sample fine-tuning (+0.96), and metric-aligned RL (GRPO, +0.45).
Advanced Parsing Capabilities
MinerU2.5-Pro extends parsing fidelity for challenging real-world document structures:
- Layout Detection: Enables robust localization across varied layout schemas.

Figure 5: MinerU2.5-Pro accurately localizes document regions with bounding boxes and category/rotation labels.
- Text, Formula, Table, and Image-Aware Parsing: Top scores across language, math, and structure tasks.

Figure 6: Superior text recognition on mixed-language regions.

Figure 7: Accurate LaTeX reconstruction of single- and multi-line formulas.
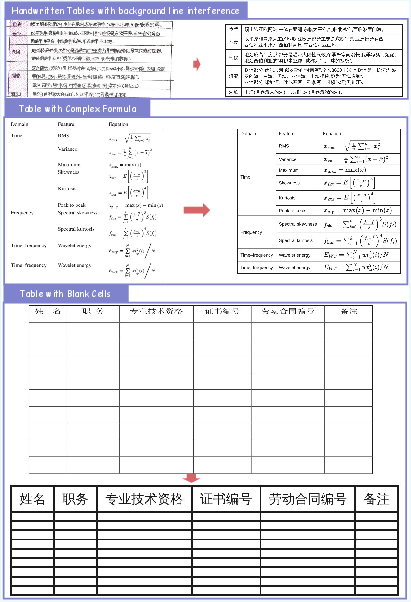
Figure 8: High-fidelity table parsing and HTML rendering, robust to nesting and merged cells.
- Truncated Paragraph and Cross-Page Table Merging: Effective merging logic for complex layouts/multi-page continuations.

Figure 9: The model merges truncated paragraphs split by layout segmentation for coherent rendering.
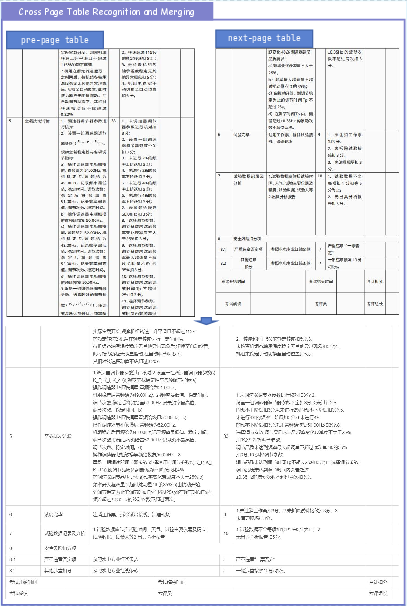
Figure 10: Cross-page table merging with column-level semantic decision making.
- In-Table Image Handling: Detects and references embedded images in tabular cells.
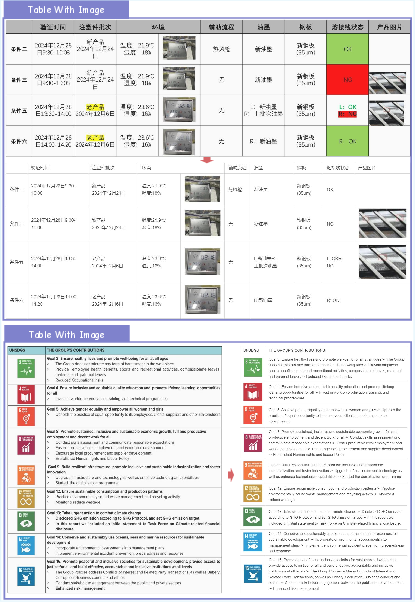
Figure 11: Embedded table images are detected and referenced in final outputs.
- Image Region Structural Analysis: Structured content extraction from chart/image blocks.
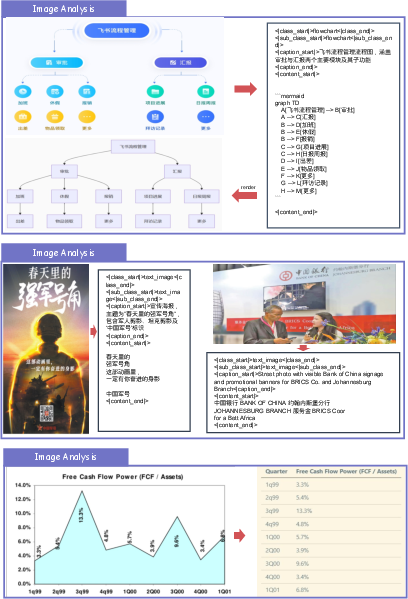
Figure 12: Image-aware parsing enables extraction and classification of structured image regions.
Qualitative Comparisons
MinerU2.5-Pro exhibits structural robustness in challenging and ambiguous scenarios, including rotated tables, multi-line or complex formulas, and precise recovery of chart data from figures, outperforming all baselines.
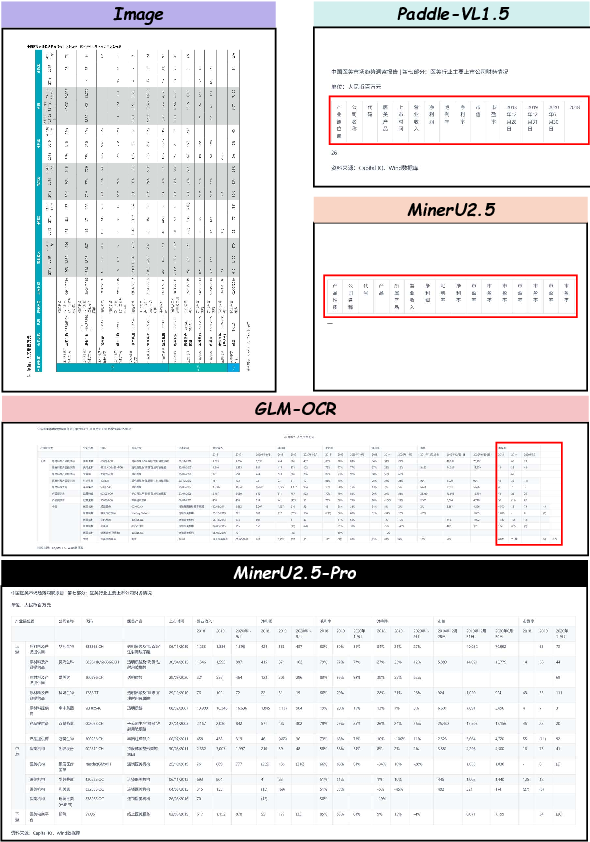
Figure 13: Rotated table recognition—structural fidelity despite orientation.
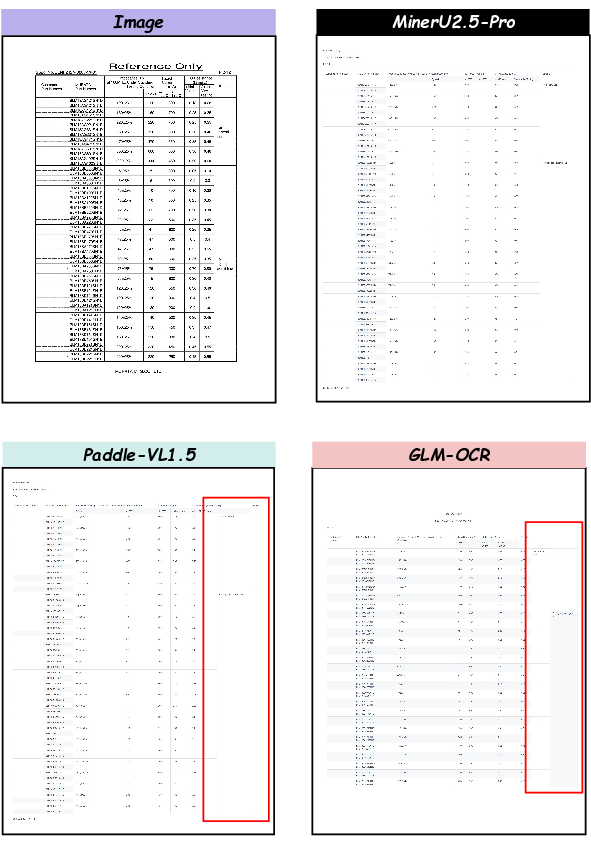
Figure 14: Recovery of long merged cells—span structure preserved, unlike in rival models.

Figure 15: Accurate multi-line matrix reconstruction, mitigating symbol and alignment errors.

Figure 16: Multi-line formula recognition—row-wise accuracy surpassing holistic approaches.
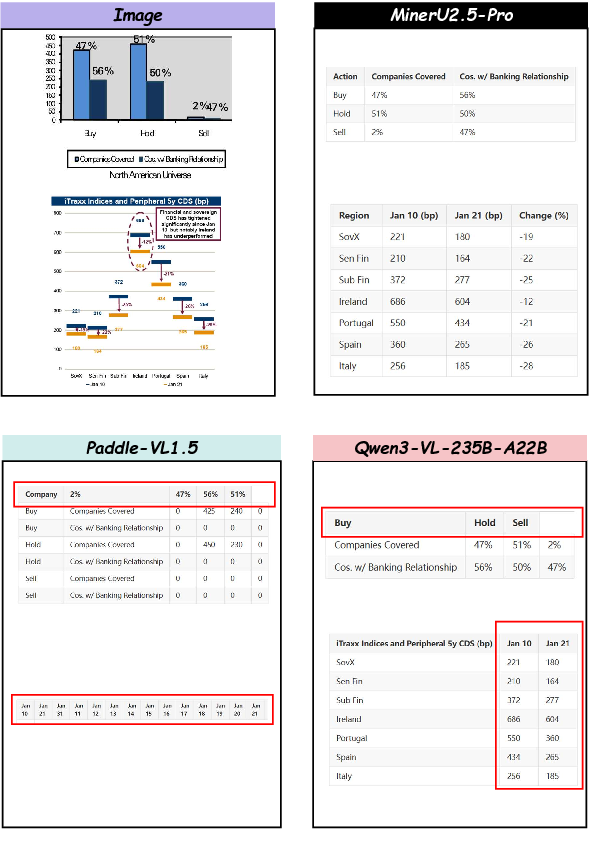
Figure 17: Chart parsing extracts structured data, unlike competing models.
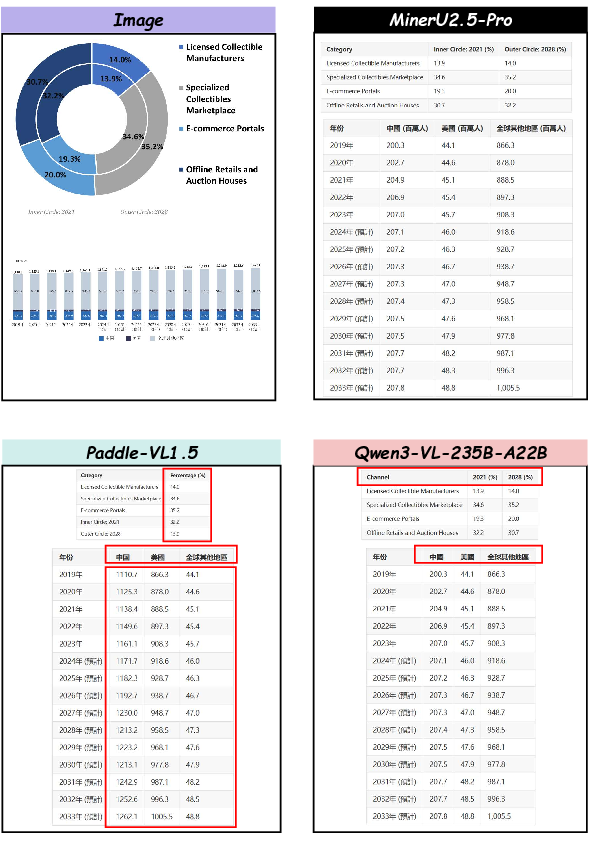
Figure 18: MinerU2.5-Pro generalizes chart pipeline to diverse image types.
Implications and Future Prospects
Theoretical Implications: The principal finding is that, for high-fidelity document parsing, targeted data-centric interventions now yield greater marginal gains than further architectural scaling or complexity. This challenges the conventional research focus on model design, relegating architectural improvements to a secondary axis.
Evaluation Advances: By rectifying element matching biases and adding hard scenario coverage, OmniDocBench v1.6 sets a better-defined empirical ceiling. However, format/structural ambiguity and the challenge of constructing true semantic equivalence metrics persist as open research problems.
Downstream Applications and Research Directions: Robust, structured PDF-to-markup parsing directly benefits LLM training data curation, knowledge extraction, and automatable retrieval systems. Yet, evolving from content-accurate parsing towards higher-order document semantic understanding—e.g., relational and cross-modal reasoning—remains the next frontier for document intelligence.
Conclusion
MinerU2.5-Pro (2604.04771) establishes new SOTA in machine document parsing by scaling, stratifying, and refining data, rather than modifying architecture. The interplay of DDAS, CMCV, iterative annotation, and a progressive curriculum is shown to deliver robust, measurable gains, particularly on previously bottlenecked scenarios. The approach furnishes a road map for future research axes emphasizing data-centric methodology and disambiguated, comprehensive evaluation.

