- The paper establishes a systematic benchmark using 3,400 images across 17 languages to evaluate document parsing in both digital-born and photographed real-world scenarios.
- It employs a robust annotation pipeline combining automated layout detection, OCR/VLM recognition, and strict human verification for high annotation fidelity.
- Experimental results highlight significant performance drops in non-Latin scripts and photographed conditions, stressing the need for improved multilingual, context-aware models.
MDPBench: A Benchmark for Multilingual Document Parsing in Real-World Scenarios
Motivation and Scope
MDPBench addresses significant gaps in document parsing research by establishing a systematic benchmark for multilingual and real-world photographed document parsing. While legacy benchmarks focus predominantly on well-formatted, digital-born documents from high-resource languages, MDPBench explicitly targets both digital and photographed documents across 17 languages, including low-resource scripts and diverse capture conditions. This benchmark is designed to serve as a rigorous standard for evaluating document parsing systems and general-purpose VLMs, emphasizing robustness, linguistic diversity, and practical deployment scenarios.

Figure 1: Overview of the MDPBench, illustrating the distribution of languages, document types, and conditions.
Dataset Construction and Annotation Pipeline
MDPBench comprises 3,400 document images, curated to maximize diversity in type, layout complexity, visual elements (e.g., formulas, tables, charts), and authenticity of real-world conditions. Electronic documents are sourced from global platforms encompassing academic papers, business reports, handwritten notes, archives, newspapers, textbooks, and comics in 17 languages. Samples undergo multi-stage filtering to eliminate low-quality or trivial documents, and are then converted to photographed data through printing/screens and capture under indoor/outdoor, variable lighting, deformation, and background variation scenarios.

Figure 2: Visualization of digital-born vs. photographed documents, capturing real-world variability.
Annotation follows a three-stage pipeline: initial layout detection via expert models (dots.ocr, PaddleOCR-VL), block-level recognition by multiple state-of-the-art OCR/VLMs, followed by consensus-based selection, comprehensive manual correction for layout, reading order, and element validation, and final strict human verification to ensure high annotation fidelity.
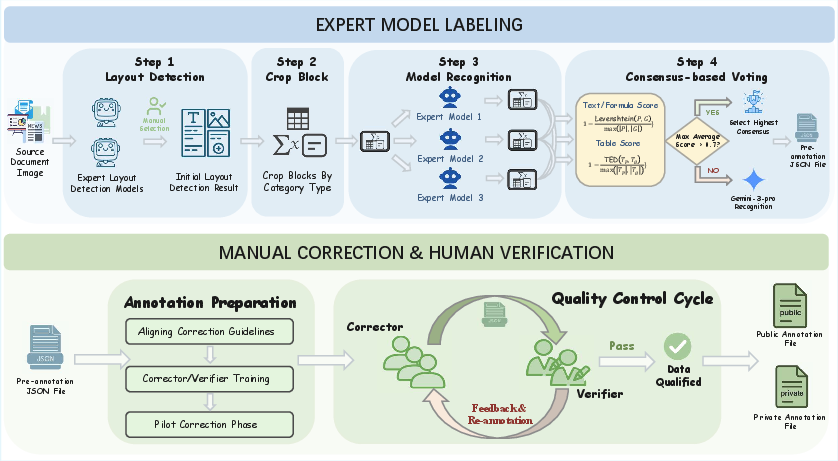
Figure 3: Pipeline of the rigorous annotation process, integrating automated modeling and manual review.
Evaluation Protocols
MDPBench adopts a page-level aggregation evaluation strategy to counter element-type distribution imbalances, which are severe in multilingual and photographed document contexts. This mitigates biases inherent in benchmarks such as OmniDocBench, where overall metrics may be disproportionately influenced by element types (e.g., formulas in English academic papers). For evaluation, Normalized Edit Distance (NED) is used for text and reading order; formulas rely on CDM to address syntactic variations; tables employ TEDS for structural verification. Benchmark splits are enforced for public (2720 samples) and private (680 samples) subsets to prevent targeted training and data leakage.
Experimental Results
A comprehensive evaluation across general VLMs, specialized VLMs, and pipeline systems exposes substantial performance differentials:
Error Analysis and Model Limitations
MDPBench enables fine-grained analysis of multilingual document parsing failure modes:
- Language-specific errors: Hindi vowel diacritic neglect, Russian Cyrillic misclassification with Latin, Thai unspaced hallucinations that disrupt lexical segmentation.
- Repetitive outputs and language drift: Models hallucinate repeated content or erroneously decode Vietnamese as Chinese, reflecting training data bias and insufficient linguistic modeling.
- Reading order errors in right-to-left scripts: Models consistently misorder Arabic two-column documents, failing to handle script directionality.

Figure 5: Typical language-specific parsing errors across Hindi, Russian, and Thai.

Figure 6: Hallucination phenomena—repetitive outputs and language drift in document parsing.
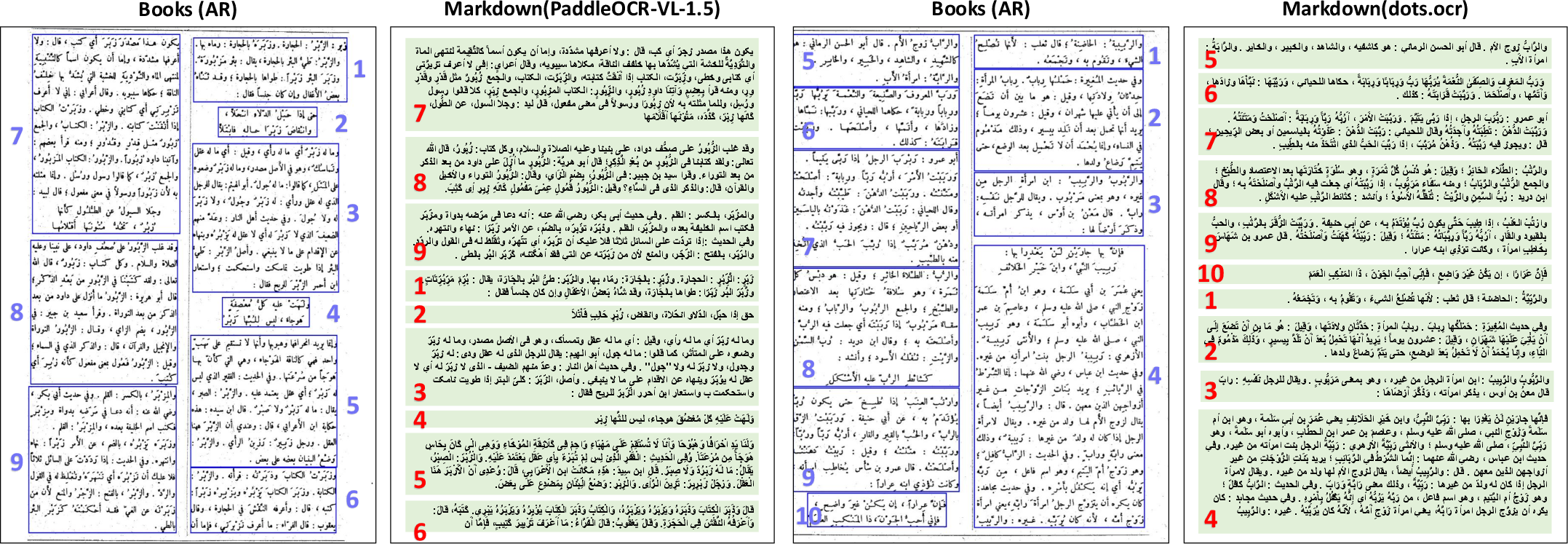
Figure 7: Misreading order in Arabic documents; models overlook right-to-left and column structure.
Pipeline-based tools exhibit error accumulation, inefficiency, and context-induced hallucinations. End-to-end VLMs demonstrate competitive efficiency but are limited by long-context reasoning and SOTA proprietary training paradigms.
Implications and Future Perspectives
MDPBench exposes fundamental weaknesses in current document parsing approaches regarding multilingual robustness, photographed document reliability, and script diversity. The pronounced performance collapse in real-world and non-Latin scenarios indicates that both open-source and proprietary models require enhanced data coverage, linguistic modeling, and architectural adaptation. Practical deployments will demand improvements in visual encoding, context management, reading order prediction, and bias mitigation.
MDPBench will catalyze research in:
- Unified multimodal architectures with improved script handling and layout reasoning
- Augmentation of training data for under-represented scripts/photographed conditions
- Advanced evaluation protocols for out-of-distribution robustness and cross-linguistic generalization
- Benchmark-driven progress in deployment-ready document parsing for pre-training corpora, business/institutional applications, and global archival digitization
Conclusion
MDPBench establishes a rigorous foundation for evaluating and advancing multilingual, real-world document parsing. Its comprehensive coverage, high-quality annotation, and strict evaluation illuminate deficiencies in both open-source and proprietary models, especially for photographed and non-Latin-script documents. MDPBench will underpin future work in robust, inclusive document parsing and facilitate the development of VLMs with superior multilingual and practical deployment capabilities (2603.28130).


