MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
Abstract: Optical character recognition (OCR) has evolved from line-level transcription to structured document parsing, requiring models to recover long-form sequences containing layout, tables, and formulas. Despite recent advances in vision-LLMs, most existing systems rely on autoregressive decoding, which introduces sequential latency and amplifies error propagation in long documents. In this work, we revisit document OCR from an inverse rendering perspective, arguing that left-to-right causal generation is an artifact of serialization rather than an intrinsic property of the task. Motivated by this insight, we propose MinerU-Diffusion, a unified diffusion-based framework that replaces autoregressive sequential decoding with parallel diffusion denoising under visual conditioning. MinerU-Diffusion employs a block-wise diffusion decoder and an uncertainty-driven curriculum learning strategy to enable stable training and efficient long-sequence inference. Extensive experiments demonstrate that MinerU-Diffusion consistently improves robustness while achieving up to 3.2x faster decoding compared to autoregressive baselines. Evaluations on the proposed Semantic Shuffle benchmark further confirm its reduced dependence on linguistic priors and stronger visual OCR capability.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MinerU‑Diffusion: A simple explanation
What is this paper about?
This paper introduces a new way to read text from document images (like PDFs, scans, or photos of pages). This task is called OCR, short for Optical Character Recognition. Instead of reading the text one token at a time from left to right (like typing a sentence), the authors build a system that fills in many parts of the text at once, guided by the image. They call this approach MinerU‑Diffusion.
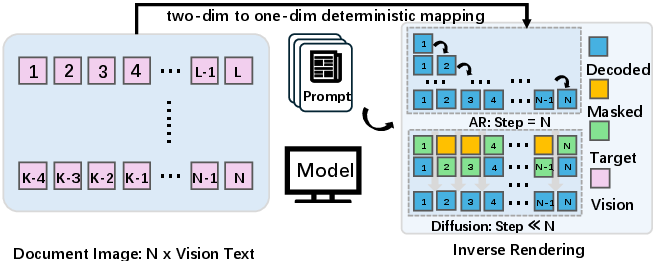
The big idea: treat OCR like “reverse printing.” A printer turns text into pixels; OCR does the opposite—turning pixels back into text. The authors use a “diffusion” process that starts with lots of unknowns and gradually fills in the correct characters, layouts, tables, and formulas in parallel.
What were the main questions?
The authors focus on three simple questions:
- Can we make OCR faster by filling in many characters at once instead of reading left‑to‑right?
- Can we avoid mistakes that spread through long documents (like when one early error messes up later parts)?
- Can we build a system that trusts what it sees in the image more than what “sounds right” in language, especially for tricky layouts like tables and math formulas?
How does their method work?
Think of three helpful analogies:
- Typing vs. puzzle‑building
- Old way (autoregressive decoding): like typing a sentence one letter at a time from left to right. It’s slow and one bad letter can mess up the sentence.
- New way (diffusion decoding): like solving a puzzle by filling in many pieces at once, guided by the picture. You revise and refine the pieces over several rounds.
- Scratch‑off reveal
- The model starts with many masked (unknown) tokens and the document image. In each step, it “confidently reveals” the text it is sure about, keeps the unsure parts masked, and tries again. This repeats until the whole page is filled in.
- Chapters and pages (block‑wise decoding)
- Long documents are split into blocks (like chapters).
- Within each block: the model can look both ways and refine many tokens in parallel.
- Across blocks: it moves forward in order (earlier blocks first), which helps keep the overall structure stable and prevents drift.
- Long documents are split into blocks (like chapters).
Two extra tricks make this work well:
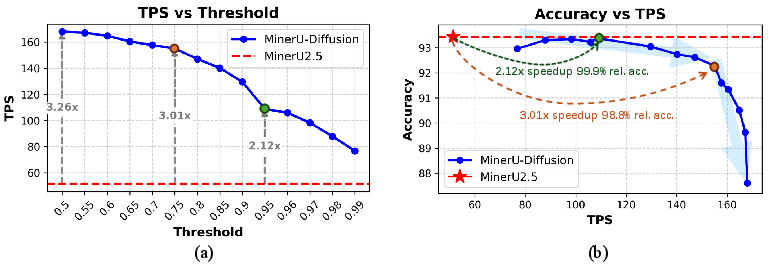
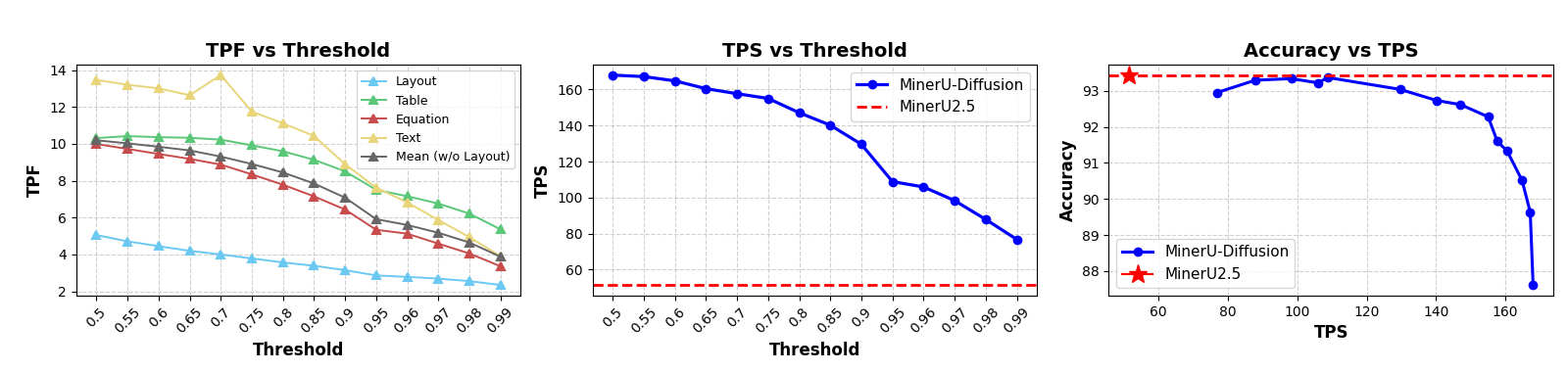
- A confidence threshold “knob”: The model only confirms tokens it’s confident about. Lower thresholds = more parallel speed; higher thresholds = more careful decoding. You can tune this knob to balance speed and accuracy.
- Two‑stage learning (like a good study plan):
- Stage 1 (foundation): train on large, diverse data to learn general reading skills.
- Stage 2 (refinement): find the cases the model is unsure about, improve the labels for those, and train more on them. This teaches the model to handle difficult edges, symbols, and layouts.
Key terms explained simply:
- Autoregressive (AR) decoding: generating text one token at a time in order.
- Diffusion decoding: starting with unknowns and repeatedly “denoising” (filling in) multiple tokens at once.
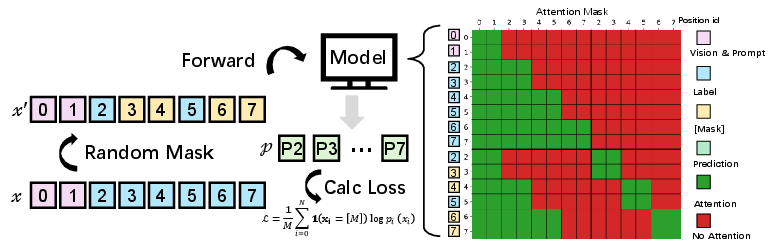
- Block attention: the model focuses fully within a block and only looks backward to earlier blocks—this keeps things fast and stable.
What did they find, and why does it matter?
In tests on standard document tasks (full pages, tables, and math formulas), MinerU‑Diffusion:
- Was faster: about 2–3× faster than strong left‑to‑right systems, depending on the confidence setting, while keeping similar accuracy.
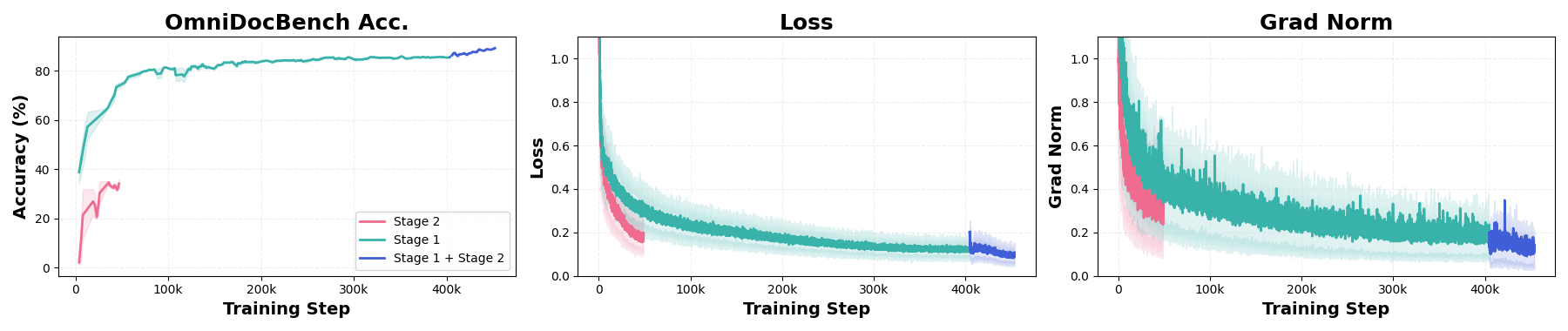
- Stayed accurate: on a big benchmark (OmniDocBench), it reached top‑tier accuracy when given correct layout regions (like where paragraphs and tables are). Even without that help, it beat many existing systems.
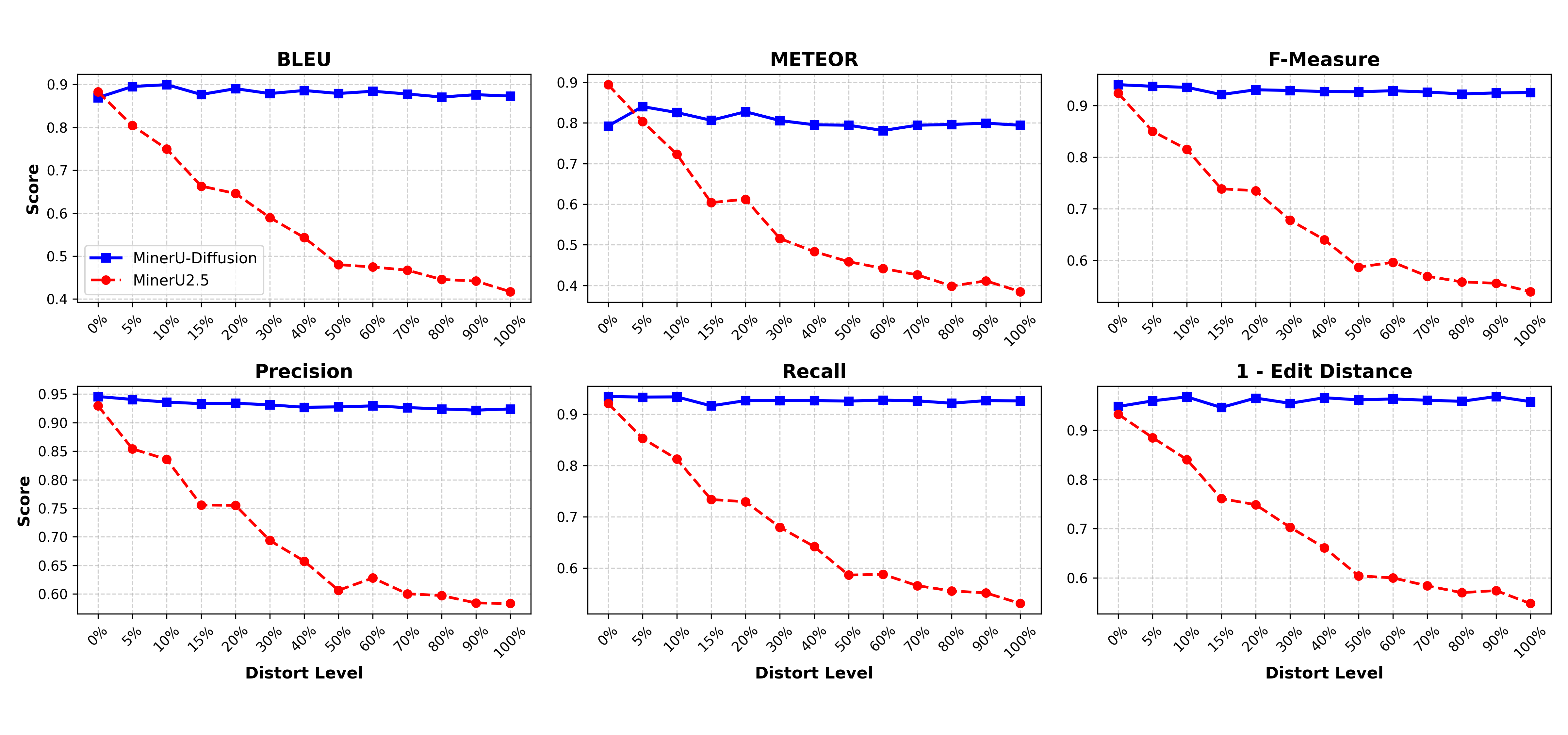
- Was more robust to nonsense text: using a “Semantic Shuffle” test, they scrambled words so the text made less sense but looked the same. Traditional left‑to‑right models relied more on language patterns and failed more as the meaning broke down. MinerU‑Diffusion held up better, showing it reads what’s actually on the page rather than guessing what “should” be there.
- Handled structure well: it did a strong job recognizing tables and formulas, keeping layouts and math symbols consistent.
Why this matters:
- Speed + stability: Reading many tokens at once makes long document processing much faster, which is great for large reports, books, and scanned archives.
- Fewer cascading mistakes: Because it confirms multiple confident tokens each step and revises others, errors don’t snowball down the line.
- Better faithfulness: It trusts the image over language guesses, which is crucial for numbers, code, IDs, and formulas where a small change can be wrong.
What could this change in the future?
- Faster, more reliable document tools: Scanners, PDF readers, and data extraction systems (for receipts, contracts, spreadsheets, math papers) could work faster and make fewer errors.
- More honest OCR: Systems that don’t “make up” text just because it sounds right are safer for business, science, and legal use.
- New research direction: This shows that OCR fits “parallel diffusion” better than “left‑to‑right typing,” encouraging more work on diffusion‑style decoding for structured text.
In short: MinerU‑Diffusion treats OCR like reconstructing a page from its image, filling in many parts at once and checking its confidence along the way. It’s faster, stays accurate, and relies more on what it sees than what it predicts, especially for tricky layouts and long documents.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable gaps for future research:
- Generalization beyond high-resource languages
- No evaluation on low-resource scripts/languages (e.g., Arabic, Devanagari, Thai, RTL, vertical text). Assess recognition quality, tokenization choices (char vs BPE), and layout markers across diverse scripts.
- Unclear robustness to mixed-language pages and code-switching.
- Robustness to real-world imaging conditions
- No tests under common degradations (blur, compression, low contrast, skew, rotation, perspective warping, shadows/occlusion, bleed-through in scans, camera-captured docs). Establish stress tests and quantify diffusion vs AR resilience.
- Lack of evaluation on historical/documents with non-standard fonts, noisy backgrounds, stamps, watermarks, or annotations.
- Layout understanding as a bottleneck
- Large w/o GT vs w/ GT layout gap indicates layout detection/reading order remains limiting. Need integrated or joint layout-visual diffusion modules, explicit 2D layout priors, or multi-task training to close the gap.
- Reading order accuracy trails strong AR baselines; investigate diffusion-aware reading order modeling and evaluation beyond page-level (e.g., multi-column, rotated text, footnotes, marginalia).
- Sequence serialization and 2D structure modeling
- Despite arguing serialization is an artifact, the method still decodes a 1D sequence. Explore 2D diffusion over grids/graphs that align with spatial layout, or hybrid 1D–2D decoders with explicit structure constraints.
- Examine whether block boundaries align with natural 2D regions; investigate layout-aware or adaptive block partitioning rather than fixed-length blocks.
- Block-wise diffusion design choices
- Block-size selection is fixed (32) without systematic study. Derive scaling laws for block size vs accuracy/latency/memory and propose adaptive block sizing driven by uncertainty or layout.
- The autoregressive dependency across blocks reintroduces causal bias; quantify how this affects global coherence, cross-region dependencies, and long-range consistency.
- Confidence thresholding and calibration
- Speed–accuracy control relies on a confidence threshold, but token confidence calibration is unexamined. Assess calibration (e.g., ECE) and explore temperature scaling, focal losses, or Bayesian heads to improve threshold reliability.
- Define stopping criteria and failure handling when many tokens remain low-confidence; analyze convergence guarantees and worst-case behaviors.
- Diffusion schedule and objective choices
- The paper does not ablate corruption schedules, number of denoising steps, noise types, or continuous vs discrete diffusion variants. Systematically evaluate how these choices impact stability, repetition, and long-sequence performance.
- Compare alternative non-AR paradigms (e.g., MaskGIT-style, CTC, EDICT, flow-based) under identical settings to isolate diffusion-specific benefits.
- Training cost, data efficiency, and compute budget
- No quantified training-time/compute cost comparisons vs AR (steps, epochs, FLOPs). Provide efficiency metrics (GPU hours, energy) and investigate strategies (teacher forcing, distillation, replay buffers) to improve data utilization in diffusion.
- Analyze sample efficiency of the two-stage curriculum; how much of the 7.5M data is necessary to match AR performance?
- Hard-sample mining and Stage II curriculum
- The uncertainty mining uses task-specific metrics (PageIoU, CDM, TEDS) but lacks a text-specific consistency metric; design a robust metric for general text recognition uncertainty.
- Stage II relies on AI-assisted human refinement; report annotation workload, inter-annotator agreement, and biases. Explore fully automated pseudo-labeling with confidence filtering and its effect on performance.
- Generalize the uncertainty-driven mining to new document types/tasks without bespoke metrics; investigate metric-agnostic or learned uncertainty estimators.
- Semantic Shuffle benchmark scope
- The benchmark uses only 112 English pages and shuffles words; expand to more languages/scripts, larger scale, and richer perturbations (sentence/character-level shuffles, synonym swaps, non-words, symbol insertions).
- Differentiate robustness to semantic disruption from robustness to layout and font variations; control for rendering artifacts introduced by re-typesetting.
- Vision encoder and input resolution
- The effect of native-scale features, input resolution, and patch sizing is not ablated. Quantify OCR performance vs resolution and assess trade-offs in compute and memory, especially for tiny text and high-density pages.
- Investigate whether multi-scale features or zoom-in modules improve small text, superscripts/subscripts in formulas, and dense tables.
- Structured output validity and constraints
- The framework outputs structured tokens (layout, tables, math) but lacks grammar-/schema-constrained decoding. Explore constrained diffusion (e.g., CFGs, stack-based constraints) to enforce syntactic validity of HTML/LaTeX/Markdown trees.
- Analyze failure modes in tables (merged cells, nested tables) and formulas (baseline alignment, operator precedence) and incorporate structure-aware losses.
- Task coverage and datasets
- No evaluation on receipts, forms, invoices, ID documents, scientific plots with embedded text, or handwriting beyond formulas. Extend benchmarks and define element-specific metrics for these domains.
- Multi-page documents and cross-page reading order/hyperlinking remain untested; assess session-level memory, KV-cache behavior, and consistency across pages.
- Throughput, latency, and deployment
- Speedups (TPS) are reported on an H200 GPU at batch=1; profile end-to-end latency, memory footprint, and energy across hardware (A100, consumer GPUs, CPU/edge).
- Quantify KV-cache reuse benefits with block attention; provide ablations vs full attention within the same architecture (not different backbones) and report memory/latency curves for very long sequences.
- Comparisons and baselines
- Lack of direct comparisons against strong non-AR OCR baselines (CTC/segmentation pipelines) and AR-accelerated techniques (speculative decoding, blockwise parallelism). Include fairness-controlled studies with matched model sizes and training data.
- The full-attention vs block-attention ablation uses a different model (LLaDA-MoE-7B), confounding conclusions; repeat within the same MinerU-Diffusion backbone.
- Error analysis and interpretability
- Limited qualitative/quantitative analysis of failure modes (by element type, page type, text size, language, and layout complexity). Provide structured error taxonomies to guide targeted architectural changes.
- Study how denoising updates propagate across tokens/blocks; visualize uncertainty evolution and error localization to design more effective selection/confirmation policies.
- Reproducibility and release
- Stage II hard set and annotation pipeline details (selection thresholds, volumes per task, annotator guidelines) are not provided; releasing these would enable reproducibility and fair comparisons.
- Missing details on the diffusion corruption schedule, number of steps at different thresholds, tokenization for multilingual OCR, and training hyperparameters (optimizers, LR schedules) impede replication.
- Theoretical grounding
- The paper motivates conditional independence in OCR but lacks formal analysis of when this assumption breaks (e.g., overlapping glyphs, extreme noise) and how block-wise AR across blocks affects posterior consistency.
- Provide theoretical or empirical convergence diagnostics for the dynamic confirmation process and conditions under which diffusion decoding fails or cycles.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging MinerU-Diffusion’s block-wise diffusion decoding, confidence-guided parallelism, and uncertainty-aware training/selection. Each item indicates likely sectors, concrete workflows or products, and key assumptions/dependencies affecting feasibility.
- Sector: Software/Enterprise Automation (RPA)
- Use case: High-throughput document ingestion for back offices (invoices, purchase orders, contracts, KYC documents) with 2–3× faster decoding on long pages while preserving tables, formulas, and reading order.
- Tools/Workflows: MinerU-Diffusion API as a recognizer; hybrid pipeline = external layout detector (e.g., PP-StructureV3 or existing layout models) + block-diffusion recognizer; confidence threshold knob (e.g., τ≈0.95) tuned to SLA; human-in-the-loop review triggered by low-confidence spans.
- Assumptions/Dependencies: High-resolution scans; primarily English/Chinese; on-prem or cloud GPUs for inference; layout detection remains a bottleneck without GT layout.
- Sector: Finance and Insurance
- Use case: Statement, invoice, claim, and policy document parsing with reduced hallucinations on numeric strings and codes due to lower reliance on linguistic priors (Semantic Shuffle robustness).
- Tools/Workflows: “Confidence-Tuned OCR Engine” with per-token uncertainty export; “Table-to-CSV/JSON” extractor; audit logs showing confidence and edits for compliance.
- Assumptions/Dependencies: Regulated environments require on-prem deployment and auditability; performance on non-English scripts may need adaptation.
- Sector: Legal/eDiscovery
- Use case: Parsing long legal PDFs (briefs, discovery productions) with preserved reading order and layout for search, summarization, and clause extraction.
- Tools/Workflows: PDF-to-structured-HTML/Markdown pipeline; “Reading Order Engine” to reconstruct document flow; batch-mode threshold tuning for speed/accuracy trade-offs per matter.
- Assumptions/Dependencies: Accurate layout segmentation improves results; content often scanned at variable DPI—preprocessing (de-skew, denoise) recommended.
- Sector: Healthcare Administration
- Use case: Intake forms, lab reports, discharge summaries, and reimbursement forms digitization with reduced semantic hallucination risk on identifiers (MRNs, CPT/ICD codes).
- Tools/Workflows: OCR microservice integrated with EHR ingestion; uncertainty-driven routing of sensitive fields to human verification; “Form-to-FHIR” converter for structured export.
- Assumptions/Dependencies: Strict PHI handling (HIPAA, GDPR); domain adaptation for handwriting and low-quality scans may be required; clinical validation prior to deployment.
- Sector: Logistics and Supply Chain
- Use case: Bills of lading, packing lists, customs forms, and shipping labels recognition at scale with improved table parsing (TEDS-S).
- Tools/Workflows: Edge or warehouse GPU node; “Table Extractor” to normalize to CSV; confidence-aware exception handling for damaged or low-contrast scans.
- Assumptions/Dependencies: Multilingual support may be needed; domain-specific templates help throughput.
- Sector: Government and Public Sector Digitization
- Use case: Large-scale archival digitization of forms and records (tax, census, land titles) with faster throughput and structured exports that preserve layout.
- Tools/Workflows: “Archive-to-XML/HTML” converter; uncertainty-based triage to archivists; semantic-shuffle-style checks to ensure visual fidelity over language priors in official records.
- Assumptions/Dependencies: Procurement may require on-prem deployment and accessibility-compliant outputs (e.g., MathML, tagged PDF).
- Sector: Publishing and Scientific Communication
- Use case: PDF-to-LaTeX/HTML conversion for scientific articles with reliable equation and table reconstruction.
- Tools/Workflows: “Formula-to-LaTeX” and “Table-to-HTML” modules; batch conversion pipelines for journals and preprint servers; QA guided by per-block uncertainty.
- Assumptions/Dependencies: Very complex notation may still need manual passes; integration with editorial workflows.
- Sector: Education and EdTech
- Use case: Digitizing textbooks, worksheets, and exams; auto-generating structured materials with preserved formulas and tables.
- Tools/Workflows: Classroom scanning apps connected to MinerU-Diffusion backend; “STEM Content Exporter” to LaTeX/MathML; accuracy threshold tuned per assignment.
- Assumptions/Dependencies: Handwriting quality and diagrams vary; add layout detectors and domain-specific fine-tuning for best results.
- Sector: Accessibility (Assistive Tech)
- Use case: Producing accessible, structured outputs (e.g., headings, reading order, MathML) from PDFs for screen reader users.
- Tools/Workflows: “Accessible PDF-to-HTML/EPUB” converter; reading-order reconstruction; export of alt-structured math.
- Assumptions/Dependencies: Requires robust layout detection; ensure markup conforms to accessibility standards.
- Sector: Developer Tools and Data Engineering
- Use case: ETL for document lakes: convert PDFs to normalized JSON/HTML/CSV for search and analytics with configurable speed–accuracy trade-offs.
- Tools/Workflows: MinerU-Diffusion as a microservice in data pipelines; KV-cache reuse and batch scheduling; per-file dynamic thresholding based on compute budgets.
- Assumptions/Dependencies: GPU scheduling and memory constraints; content diversity may need domain adapters.
- Sector: Quality Assurance and Dataset Curation
- Use case: Active learning for OCR datasets using the paper’s uncertainty-driven curriculum: automatically mine hard samples that cause inconsistent outputs, then refine labels.
- Tools/Workflows: “Uncertainty-Aware Annotator” with PageIoU/TEDS/CDM-based consistency scoring; human-in-the-loop correction panel; retraining loop.
- Assumptions/Dependencies: Requires annotation budget and task-specific consistency metrics; governance for label updates.
- Sector: Mobile Scanning Apps (Consumer and SMB)
- Use case: Faster multi-page scans of receipts, worksheets, and contracts with better table/text structure preservation.
- Tools/Workflows: Cloud inference via MinerU-Diffusion API; client-side confidence summaries to prompt user rescans; “Table-to-Spreadsheet” share action.
- Assumptions/Dependencies: On-device deployment of a 2.5B dVLM is unlikely; rely on cloud or explore quantized/distilled variants.
- Sector: Information Security/Compliance
- Use case: Reducing OCR-induced hallucinations on sensitive sequences (bank accounts, IDs) by prioritizing visual evidence over language priors; generating audit trails of token-level confidence.
- Tools/Workflows: “Sensitive-field Sentinel” flags low-confidence numerics for manual verification; differential decoding with a higher τ for sensitive regions.
- Assumptions/Dependencies: Policy configuration; potential requirement to combine with regex/format validators.
- Sector: Research/Academia (Evaluation)
- Use case: Measuring reliance on linguistic priors in OCR systems via the Semantic Shuffle benchmark; fair comparisons across decoding paradigms.
- Tools/Workflows: “Semantic Shuffle Test Suite” integrated into CI for OCR models; cross-model evaluation dashboards.
- Assumptions/Dependencies: Benchmark currently English-focused; extend to other languages for broader coverage.
Long-Term Applications
These applications will benefit from further research, scaling, domain adaptation, and/or engineering. Many build on the inverse-rendering view and block-diffusion design.
- Sector: End-to-End Page Understanding (Unified Models)
- Use case: Single model jointly handling layout detection and recognition (closing the gap between w/ and w/o GT layout).
- Tools/Workflows: Unified diffusion model with integrated layout module; multi-task training (detection + recognition) under uncertainty-aware curricula.
- Assumptions/Dependencies: Stronger layout priors and datasets; more compute and architecture refinements for long-page stability.
- Sector: Multilingual and Multi-script OCR
- Use case: Robust recognition across low-resource scripts (Arabic, Indic, CJK variants) with the same diffusion decoding advantages.
- Tools/Workflows: Language-agnostic vocabularies; synthetic data generation; curriculum learning extended to multilingual hard-sample mining.
- Assumptions/Dependencies: Large, diverse training data; script-specific tokenization; handwriting adaptation.
- Sector: On-Device/Edge OCR
- Use case: Industrial and mobile scenarios with strict latency/compute envelopes (e.g., handheld scanners, smart glasses).
- Tools/Workflows: Distilled/quantized diffusion VLMs; low-rank adapters; block-size optimization; NPU-friendly kernels.
- Assumptions/Dependencies: Research into compact discrete diffusion architectures; hardware acceleration support.
- Sector: Scientific Content Intelligence
- Use case: Structure-aware math OCR beyond recognition—automatic semantic disambiguation, symbol-level linking, and conversion to executable CAS code or interactive math.
- Tools/Workflows: “Equation Understanding Engine” producing MathML + semantic annotations; linking tables/equations to text references.
- Assumptions/Dependencies: Advanced symbol grounding datasets; integration with CAS/knowledge graphs.
- Sector: Document Restoration and Repair (Inverse Rendering)
- Use case: Reconstructing degraded scans (faded text, occlusions) using diffusion refinement guided by visual evidence and layout structure.
- Tools/Workflows: Joint enhancement + OCR modeling; uncertainty-aware inpainting constrained by document priors.
- Assumptions/Dependencies: Paired or synthetic degraded/clean datasets; careful bias control to avoid hallucinated content.
- Sector: Federated/Privacy-Preserving OCR
- Use case: Training/serving OCR where documents cannot leave the premises (hospitals, banks) using federated learning and privacy budgets.
- Tools/Workflows: Federated diffusion training; uncertainty-based sample selection shared as privacy-preserving statistics.
- Assumptions/Dependencies: Secure aggregation; legal approvals; model update governance.
- Sector: Compliance, Standards, and Certification
- Use case: Standardizing robustness tests (e.g., Semantic Shuffle) as part of procurement and certification for OCR in regulated domains.
- Tools/Workflows: “OCR Robustness Certification Suite” that scores models on visual fidelity under semantic perturbations; policy templates for agencies.
- Assumptions/Dependencies: Consensus across regulators and vendors; multilingual benchmarks.
- Sector: Human–AI Collaborative Document Workflows
- Use case: Real-time, adaptive speed–accuracy control in multi-operator settings—dynamic τ adjustment based on operator load and SLA targets.
- Tools/Workflows: Control-plane for confidence thresholding; UI surfacing token/block uncertainties; semi-automatic correction loops feeding back into continuous learning.
- Assumptions/Dependencies: Ergonomic HCI; safe continuous-learning pipelines.
- Sector: UI/Code and Diagram Understanding
- Use case: Extending diffusion-based inverse rendering to UI screenshots, engineering drawings, and charts for code/graph extraction.
- Tools/Workflows: “UI-to-Code” and “Diagram-to-Graph” modules leveraging structured token vocabularies and block diffusion.
- Assumptions/Dependencies: New vocabularies and supervision; domain-specific constraints.
- Sector: Real-Time Document Streams
- Use case: Live capture and transcription of multi-page scans or camera feeds with progressive, blockwise refinement and early partial results.
- Tools/Workflows: Streaming diffusion decoding with KV-cache reuse; early-exit strategies when confidence thresholds are met.
- Assumptions/Dependencies: Low-latency hardware; streaming APIs and partial-result UX.
- Sector: Knowledge Extraction and RAG
- Use case: Reliable conversion of PDFs to high-fidelity, chunked, structured corpora for retrieval-augmented generation with minimal OCR artifacts.
- Tools/Workflows: “PDF-to-RAG Packager” producing layout-aware chunks and confidence annotations; table/equation serializers linked to text.
- Assumptions/Dependencies: Downstream RAG models tuned to consume structure and uncertainty metadata.
- Sector: Safety-Critical OCR (Aviation, Pharma, Manufacturing)
- Use case: Reading gauges, labels, and batch numbers in environments where errors are costly, prioritizing visual evidence over language priors.
- Tools/Workflows: Domain-adapted diffusion OCR with strict confidence thresholds and dual-operator verification.
- Assumptions/Dependencies: Domain datasets; rigorous validation and certification.
- Sector: Benchmarking Methodology Transfer
- Use case: Adapting the Semantic Shuffle idea to other modalities (e.g., speech transcripts, code OCR) to quantify model reliance on priors vs. evidence.
- Tools/Workflows: “Shuffle Bench” generators that perturb semantics while preserving perceptual form; cross-paradigm evaluations (AR vs. diffusion).
- Assumptions/Dependencies: Task-specific rendering tools and metrics.
Cross-cutting assumptions and deployment notes
- Model readiness: Current release targets Chinese/English; performance on low-resource scripts and heavy handwriting requires additional training.
- Layout is still a key bottleneck w/o GT layout; best production accuracy comes from hybrid pipelines that pair MinerU-Diffusion with strong layout detectors.
- Infrastructure: 2.5B-parameter dVLM suggests GPU-backed inference; throughput benefits from KV-cache reuse and block attention; consider quantization/distillation for cost-sensitive settings.
- Governance: For healthcare/legal/finance, introduce human verification on low-confidence spans; maintain audit logs of token-level confidence; validate domain-specific performance before go-live.
- Licensing and privacy: Confirm model and code licenses for commercial use; for sensitive data, prefer on-prem deployment and privacy-preserving training where applicable.
- Speed–accuracy control: Expose the confidence threshold (τ) as a product-level knob to hit SLA targets and cost budgets; adopt dynamic scheduling to balance throughput and quality per document.
Glossary
- Autoregressive decoding: Sequential left-to-right token generation that can cause latency and error accumulation in long outputs. "most existing systems rely on autoregressive decoding, which introduces sequential latency and amplifies error propagation in long documents."
- Block-attention: An attention scheme that allows full bidirectional attention within blocks and causal attention across blocks to improve efficiency and stability. "we introduce MinerU-Diffusion, a block-attention dVLM"
- Block-wise diffusion decoder: A diffusion-based decoder that updates tokens in parallel within contiguous blocks to stabilize long-sequence generation. "MinerU-Diffusion employs a block-wise diffusion decoder and an uncertainty-driven curriculum learning strategy to enable stable training and efficient long-sequence inference."
- Causal factorization: A directional decomposition of the output distribution that enforces a fixed generation order, typical of autoregressive models. "This fragility stems not merely from data or training strategy, but from the causal factorization inherent in autoregressive decoding."
- CDM: A formula-recognition metric used to evaluate structural similarity of mathematical expressions. "We define a task-specific consistency metric S(·,·): (1) PageIoU for layout, (2) CDM for formula, (3) TEDS for tables."
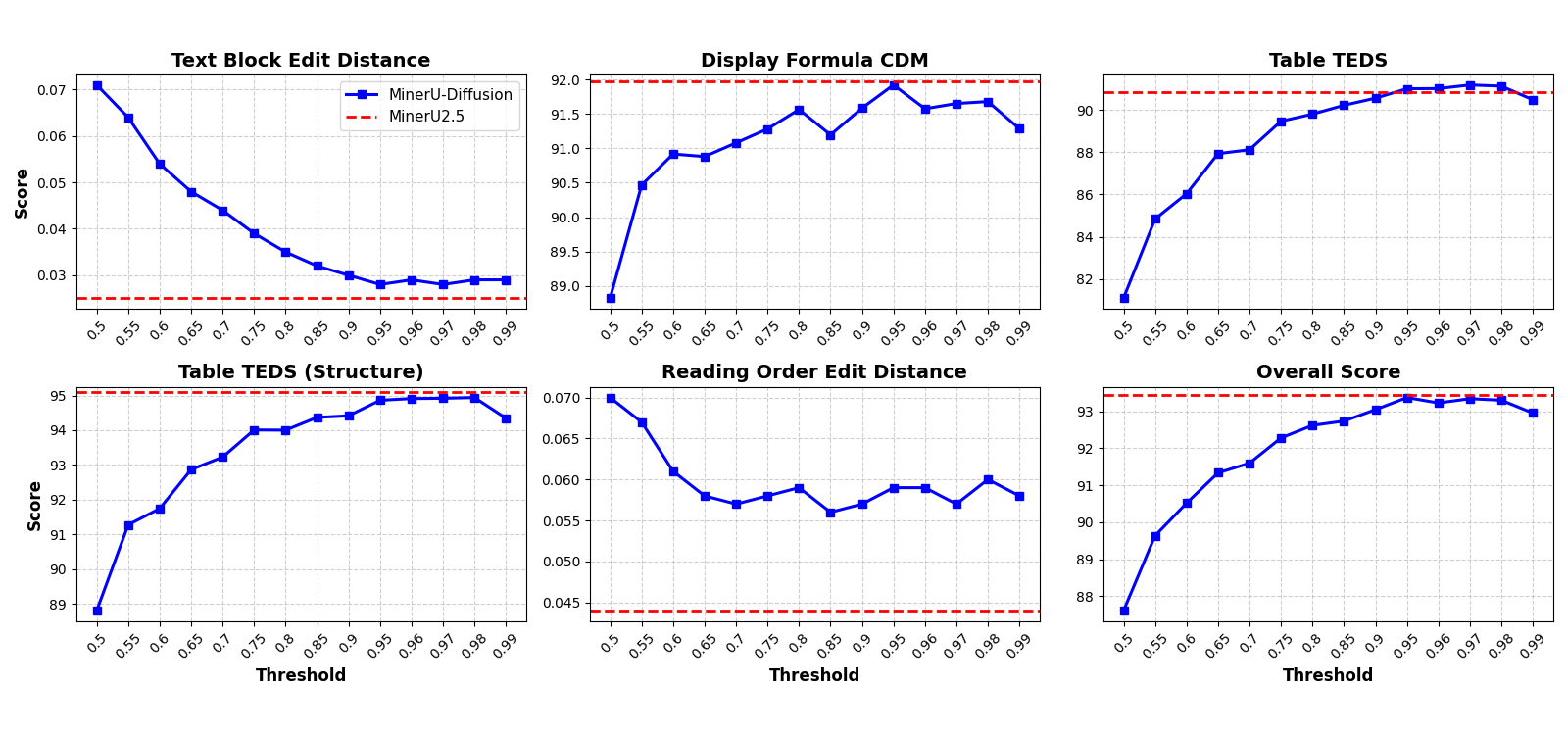
- Confidence threshold: A tunable parameter controlling when tokens are confirmed during parallel decoding, trading off speed and accuracy. "(a) The confidence threshold controls decoding parallelism in MinerU-Diffusion."
- Conditional independence: The assumption that each token can be predicted independently given inputs and partially observed sequences, used by masked diffusion. "Masked diffusion models assume conditional independence among tokens given partially observed sequences and visual inputs"
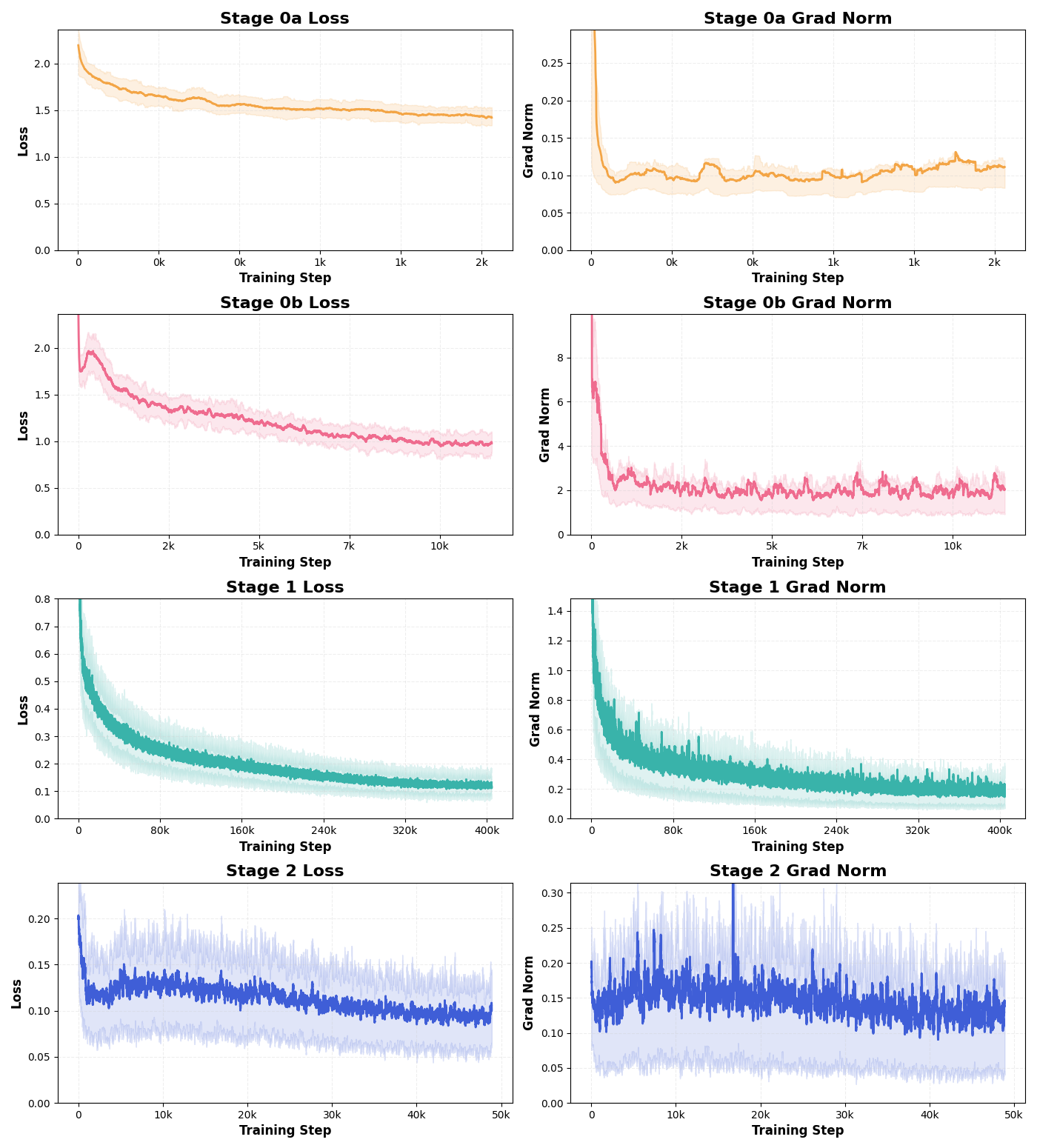
- Curriculum learning: A training strategy that orders data from easier to harder to stabilize optimization and improve robustness. "we propose a two-stage curriculum learning framework to train the MinerU-Diffusion."
- Diffusion denoising: Iterative reconstruction of clean tokens from masked or corrupted tokens guided by a diffusion process. "parallel diffusion denoising under visual conditioning."
- Diffusion LLMs (DLMs): Non-autoregressive LLMs based on discrete diffusion processes for parallel token updates. "Diffusion LLMs (DLMs) offer a non-autoregressive generative framework based on discrete diffusion processes."
- Edit distance: A text evaluation metric that measures the minimum number of edits needed to transform one string into another. "On OmniDocBench, text is evaluated by edit distance ()"
- Evidence Lower Bound (ELBO): A variational objective that lower-bounds the log-likelihood and is optimized during training. "resulting in an evidence lower bound (ELBO) on :"
- Full-attention diffusion: A diffusion setup using full self-attention across the sequence, which can be computationally expensive and unstable. "Full-attention diffusion operates globally, which introduces positional instability as early denoising errors can propagate across the sequence."
- GT Layout: Ground-truth layout regions provided during evaluation to isolate recognition quality from layout detection. "When evaluated with GT Layout, MinerU-Diffusion further improves to 93.37 Overall"
- Hybrid matching: An evaluation protocol that combines multiple matching criteria to assess document parsing quality. "follow the latest evaluation protocol on 1,355 pages with hybrid matching."
- Inverse rendering: Framing OCR as recovering the underlying token sequence from a rendered document image. "we formulate document OCR explicitly as an inverse rendering problem under visual conditioning"
- KV-cache: Cached key–value tensors for attention that enable faster inference by reusing past computations. "Their structured attention patterns naturally enable KV-cache reuse, alleviating the inference latency commonly observed in full-attention DLMs"
- Mask token: A special token (e.g., [MASK]) used to replace original tokens during the corruption process in masked diffusion. "tokens in a clean sequence are progressively replaced by mask tokens under a continuous corruption schedule"
- Masked diffusion: A discrete diffusion approach where tokens are masked and predicted in parallel under conditioning. "Masked diffusion models assume conditional independence among tokens given partially observed sequences and visual inputs"
- Maximum likelihood estimation (MLE): A training principle that derives objectives by maximizing the likelihood of observed data. "The corresponding training objective can be derived from maximum likelihood estimation"
- M-RoPE: A variant of rotary positional embeddings; a positional encoding technique used (and here removed) in the architecture. "except that M-RoPE is removed."
- Native-scale visual features: Visual representations extracted at the document’s original resolution to ground decoding in fine-grained evidence. "MinerU-Diffusion conditions the diffusion process on native-scale visual features"
- Non-autoregressive: A generation paradigm that updates multiple tokens simultaneously without a fixed causal order. "offer a non-autoregressive generative framework based on discrete diffusion processes."
- Oracle layout: Provided ground-truth layout regions used during evaluation to avoid errors from layout detection. "oracle layout regions are provided"
- PageIoU: An intersection-over-union metric defined at the page layout level to measure layout prediction consistency. "We define a task-specific consistency metric S(·,·): (1) PageIoU for layout, (2) CDM for formula, (3) TEDS for tables."
- Posterior (posterior inference): The conditional distribution over token sequences given the input image, which the model seeks to approximate. "Document OCR can be framed as posterior inference over a latent structured token sequence"
- Semantic hallucination: The generation of plausible but visually unsupported content due to over-reliance on language priors. "leading to semantic hallucinations and cumulative errors."
- Semantic Shuffle: A benchmark that shuffles text semantics to test models’ reliance on linguistic priors versus visual evidence. "Evaluations on the proposed Semantic Shuffle benchmark further confirm its reduced dependence on linguistic priors and stronger visual OCR capability."
- Structured attention mask: A masking pattern that permits full attention within blocks and causal attention to preceding blocks during decoding. "At each denoising step, a structured attention mask is applied."
- Temperature: A sampling parameter controlling the randomness of token selection during decoding. "with top-, temperature , and top-."
- TEDS: A table evaluation metric based on tree edit distance that measures structural and content similarity of tables. "tables by TEDS / TEDS-S ()."
- TEDS-S: A structure-focused variant of TEDS emphasizing table structural similarity. "tables by TEDS / TEDS-S ()."
- Throughput Per Second (TPS): The number of tokens or decoding operations processed per second during inference. "TPF denotes tokens per forward, and TPS refers to throughput measured on an NVIDIA H200 GPU with a batch size of 1."
- Tokens Per Forward (TPF): The number of tokens updated in each forward pass during diffusion decoding. "TPF denotes tokens per forward, and TPS refers to throughput measured on an NVIDIA H200 GPU with a batch size of 1."
- Top-k: A sampling strategy that restricts generation to the k most probable tokens. "with top-, temperature , and top-."
- Top-p (nucleus sampling): A sampling strategy that restricts generation to the smallest set of tokens whose cumulative probability exceeds p. "with top-, temperature , and top-."
- Vision-LLMs (VLMs): Models that jointly process visual and textual information for tasks like OCR. "Vision-LLMs (VLMs) have become the dominant paradigm for document Optical Character Recognition (OCR)"
- Visual conditioning: Conditioning the diffusion process on visual features so token predictions are grounded in the image. "parallel diffusion denoising under visual conditioning."
- Visual Question Answering (VQA): A task where a model answers questions about an image, used here for initial fine-tuning. "We first fine-tune the MinerU-Diffusion on the LLaVA-NeXT dataset for visual question answering (VQA) tasks."
Collections
Sign up for free to add this paper to one or more collections.