- The paper introduces UniRec-0.1B, a unified recognition model that uses hierarchical supervision and semantic-decoupled tokenization in a 0.1B parameter architecture.
- It demonstrates significant improvements in formula and multi-level text recognition, outperforming models like Mathpix and PP-OCRv5 with gains up to 20.3%.
- The model achieves up to 7× faster full-page parsing, enabling scalable deployment in constrained environments such as mobile and embedded systems.
UniRec-0.1B: Efficient Unified Text and Formula Recognition at Scale
Introduction and Motivation
UniRec-0.1B addresses a fundamental challenge in document parsing—the efficient, unified recognition of textual and mathematical content, which collectively constitute the overwhelming majority of informational regions in scientific and enterprise documents. Analysis on OmniDocBench reveals that text and formulas represent 97.43% of page regions and consume 87.9% of parsing time, strongly motivating targeted acceleration in these modalities (Figure 1).
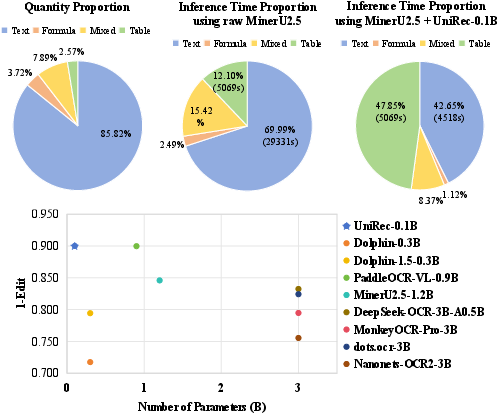
Figure 1: Text and formulas constitute 97.43% of document page regions in OmniDocBench and dominate inference latency; UniRec-0.1B delivers a 4× parsing speedup over MinerU2.5.
Traditional approaches treat text and formula recognition as disjoint tasks, leveraging specialized models mostly at line-level granularity. Recent VLM-based unified models enable end-to-end recognition, but their memory and compute requirements limit practical scalability and on-device deployment. UniRec-0.1B is proposed as a unified recognition model with only 0.1B parameters, delivering multi-granular recognition (character, word, line, paragraph, document) for both text and formulas, with strong empirical indications of both accuracy and efficiency advantages over large VLMs and expert models.
Dataset Construction: UniRec40M
Effective unified recognition demands large-scale, diverse data covering the spectrum of document layouts, languages, handwriting, and formula structures. To this end, UniRec40M is introduced: 40 million samples comprising Chinese and English text, formulas, and mixed text-formula content. The dataset integrates multiple sources—TeX-generated synthetic documents, real-world PDFs from domains including research, journalism, and industry, and a variety of public scene-text and handwriting corpora. This results in a comprehensive multi-domain, multi-level corpus, with rigorous alignment at word, line, and paragraph levels (Figure 2).
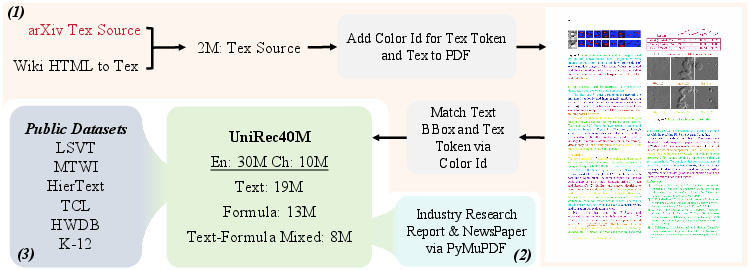
Figure 2: UniRec40M construction integrates synthetic TeX, digital PDFs, and public datasets for high-coverage, multi-level document recognition.
The dataset enables balanced sampling during training to avoid modality imbalance, ensuring robust multi-task learning within a compact parameter budget.
Model Architecture and Innovations
UniRec-0.1B adopts an encoder-decoder architecture utilizing FocalNet for visual feature extraction. Adhering to native aspect ratio processing, input images are capped at 960 × 1408 pixels, with spatial features tokenized for multimodal Transformer decoding. The decoder consists of six cross-attention layers to autoregressively generate symbol sequences under causal masking, supervised by cross-entropy over all output tokens (Figure 3).
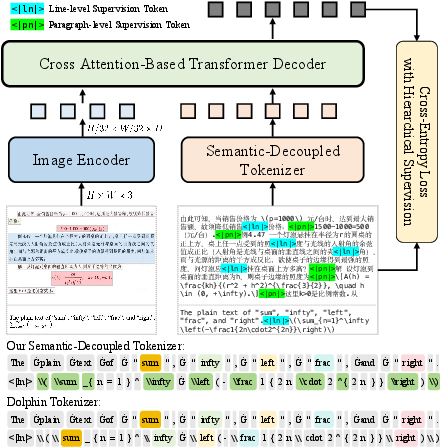
Figure 3: UniRec-0.1B model architecture featuring FocalNet encoder, hierarchical supervision, and semantics-decoupled tokenization.
Two principal innovations underpin UniRec-0.1B’s capability in multi-level, multi-modality recognition:
- Hierarchical Supervision Training (HST): Explicit insertion of line- and paragraph-level tokens (<|ln|>, <|pn|>) into the label sequence enables model awareness of document organization, facilitating accurate reconstruction of line and paragraph boundaries during inference.
- Semantic-Decoupled Tokenizer (SDT): Separate token vocabularies for text and formula modalities eliminate semantic entanglement present in coupled tokenizers. This design ensures contextually appropriate representations and enhances small-model discriminative power, especially in formula-heavy cases.
Experimental Validation
UniRec-0.1B is evaluated on both the fine-grained UniRec-Bench, covering block-level recognition across modalities, levels, languages, and domains, and OmniDocBench, targeting full-page document parsing.
Block-Level Recognition and Ablations
UniRec-0.1B achieves superior or on-par edit distance performance compared to larger VLM-based models and expert recognizers. For text and formula recognition:
- UniRec-0.1B outperforms Mathpix, Pix2Tex, and UniMERNet-B by 18.8%, 20.3%, and 10.4% respectively for formulas.
- For multi-level text, it exceeds PP-OCRv5, PP-Recv5, and OpenOCR-Rec consistently across character, word, line, and paragraph levels in both Chinese and English.
Ablation on HST and SDT confirms design efficacy: removing HST drops performance by up to 2.9% on complex layouts; removing SDT reduces formula accuracy by 11.1%. The synergy of both innovations is required for robust fine-grained and cross-modal recognition.
Qualitative Analysis
Visualization of recognition results (Figure 4—Figure 5) exposes accuracy characteristics and model error modes:
- UniRec-0.1B maintains semantic integrity in mixed text-formula blocks and correctly recognizes multi-line, multi-domain handwritten and degraded content (Figures 4, 5, 6, 7).
- Competing models misclassify inline formulas or hallucinate structural elements, especially in layouts or domains deviating from standard templates (Figures 5, 8, 10).

Figure 4: Recognition result visualizations—UniRec-0.1B preserves character, formula, and layout details in diverse scenarios.
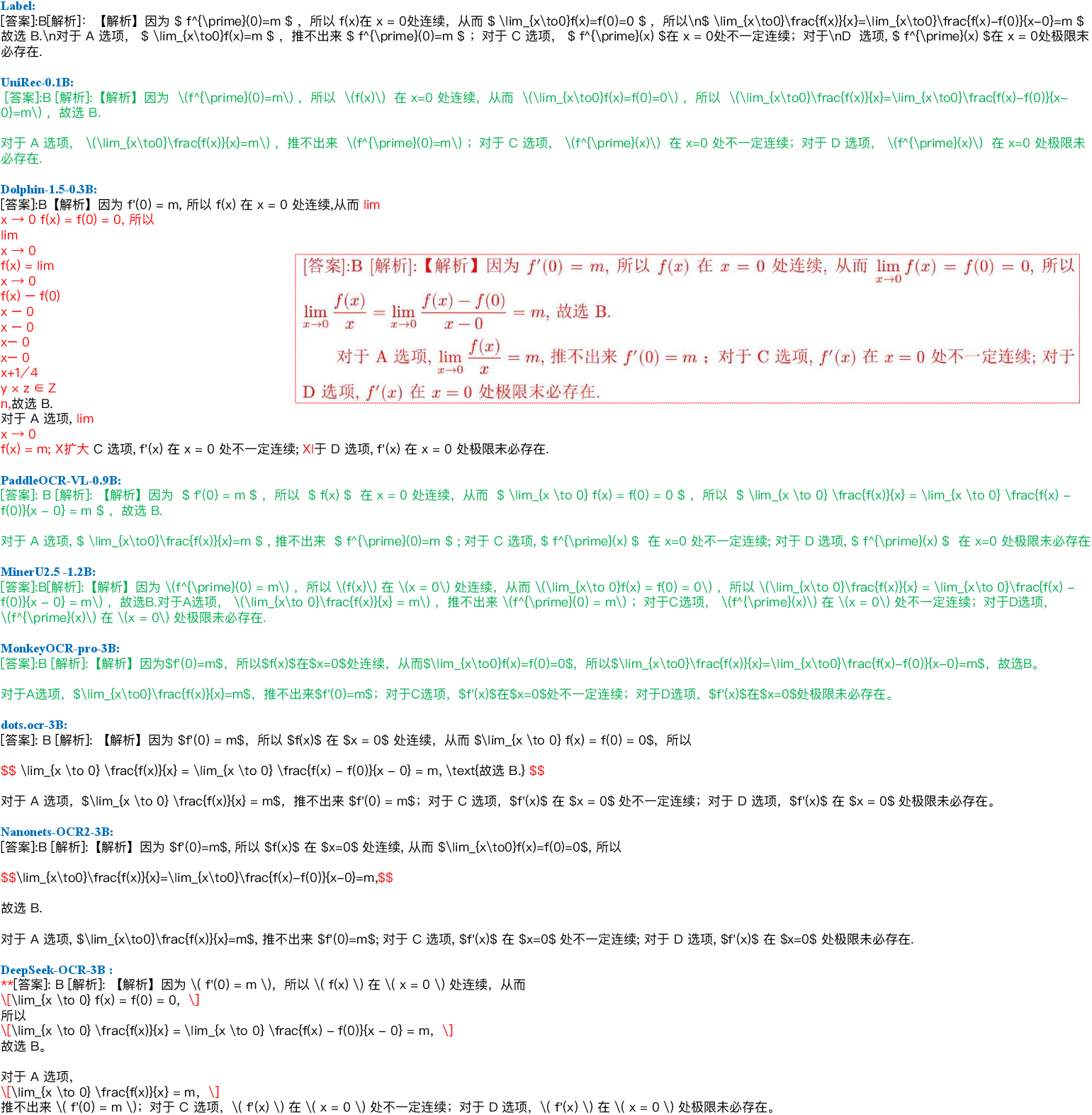
Figure 6: Recognition of mixed Chinese text with inline formulas—UniRec-0.1B disambiguates inline versus display formulas; others misclassify.

Figure 7: Clean text recognition—UniRec-0.1B avoids common mispredictions in circled character and styled symbol cases.

Figure 8: Multi-line handwritten text—UniRec-0.1B robustly deciphers both Chinese and English handwriting without translation errors.

Figure 5: Multi-line formula recognition—UniRec-0.1B, MonkeyOCR, and Nanonets-OCR2 fully capture formula layout and semantic structure.
Full-Page Document Parsing
Integrating UniRec-0.1B into multi-stage parsing systems (MinerU2.5, PaddleOCR-VL) yields a 2.3% and 0.2% improvement in edit distance, respectively. The average page parsing time is reduced from ~42.7s to 6.2s (~7× speedup). These figures establish UniRec-0.1B as not only accurate but highly practical for real-world deployment under computational constraints.
Implications and Future Directions
UniRec-0.1B demonstrates a strong contradiction in conventional wisdom, delivering leading block- and page-level text/formula recognition with only 0.1B parameters—contrary to the assumption that unified multimodal document parsing requires large VLMs. This enables scalable deployment in constrained environments, including mobile, embedded, and browser-based document analysis.
The study further reveals architectural trade-offs in the field: hybrid multi-stage models remain optimal for fine-grained recognition, while end-to-end frameworks excel in holistic context understanding. UniRec-0.1B bridges these trajectories by enforcing hierarchical structure and modality separation, eroding the boundary between block- and page-level recognition and closing the gap between compactness and generality.
Remaining limitations (e.g., subscript/superscript errors in ambiguous contexts, as seen in Figure 9) indicate data extraction and representation challenges—suggesting research in hybrid semantics/layout models or improved data annotation for minority cases.

Figure 9: Failure case—subscript/superscript confusion outside mathematical contexts reveals training data extraction limitations.
Conclusion
UniRec-0.1B advances unified text and formula recognition by integrating hierarchical supervision and semantic decoupling in a scalable architecture, redefined for efficiency and versatility. Large-scale training on UniRec40M enables robust generalization across languages, content types, and domains. Experimental results substantiate accuracy and speed benefits, enabling direct deployment in modern document parsing pipelines. These contributions have strong implications for the future of document intelligence, lowering resource barriers for broad, multimodal information extraction.
Reference: "UniRec-0.1B: Unified Text and Formula Recognition with 0.1B Parameters" (2512.21095)