- The paper introduces an RL framework that generates dynamic, image-grounded questions to systematically expose failure modes in vision-language models.
- RL-driven questioners achieve high failure discovery rates (up to 49.5%) and cover 123 distinct skills, outperforming static adversarial approaches.
- The taxonomy pipeline categorizes universal and model-specific failures, offering actionable insights for enhancing VLM robustness and evaluation.
Systematic Discovery of Failure Modes in Vision-LLMs Using Reinforcement Learning
Introduction
This work introduces a reinforcement learning (RL) framework for systematically discovering failure modes in state-of-the-art vision-LLMs (VLMs). By leveraging RL-driven questioners, the paper goes beyond static adversarial or random question generation—adapting dynamic query synthesis in response to VLM behavior. The proposed pipeline identifies, validates, and taxonomizes failure modes with unprecedented skill coverage, compositionality, and detail, culminating in the construction of a hierarchical failure taxonomy.
Methodology
The central innovation is an RL-based agent that generates maximally challenging, image-grounded questions designed to reveal VLM blind spots. The setup comprises three separately parameterized modules: questioner, answerer, and verifier. The answerer (VLM under test) and the automated verifier remain frozen, while the questioner is trained via the GRPO algorithm. The overall pipeline proceeds in several stages:
- Question Generation: The questioner produces batches of challenging, semantically diverse queries conditioned on input images. Prompts explicitly enforce requirements for single, objective, image-grounded questions.
- Question/Answer Verification: Automated verifiers, using prompts and stepwise evaluation criteria, filter out vague or irrelevant questions and assess the correctness of the VLM's answers.
- Reinforcement Learning: The questioner maximizes a reward signal derived from verified failures (instances where the answerer fails). Regularization enforces question diversity and coverage over skills.
- Taxonomy Creation Pipeline: The pipeline dissects queries via a multi-stage taxonomy creation process: primitive skill labeling, topic modeling, label standardization, and meta-skill grouping. Each stage ensures cognitive mechanisms, not mere task labels, are foregrounded.
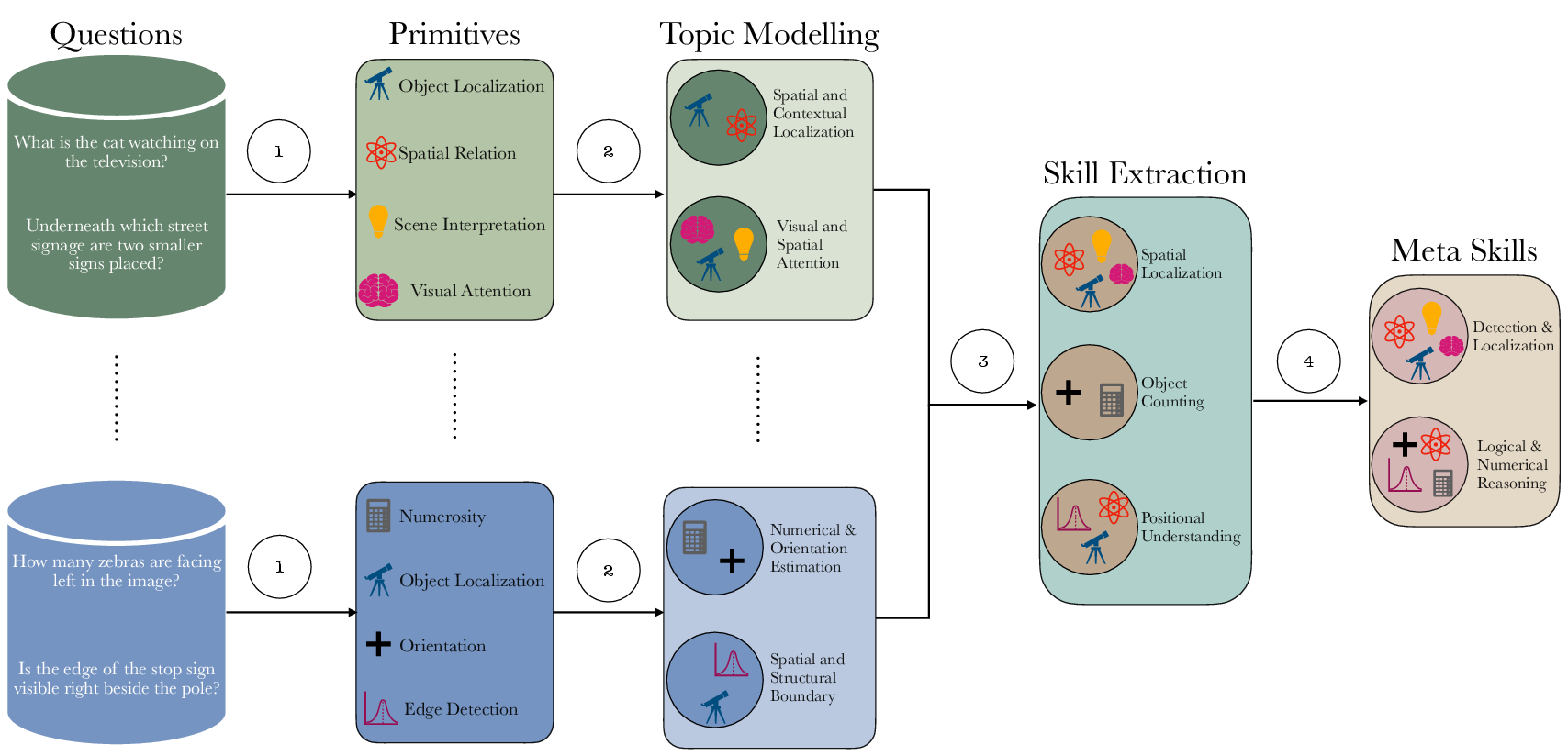
Figure 1: An illustrative workflow of the Failure Taxonomy Creation Pipeline.
Evolution of Question Complexity
A key finding is the progressive sophistication of RL-generated questions across training stages. Early-stage queries largely probe surface-level perceptions (object localization, color, counting), while later iterations elicit complex, compositional, and fine-grained reasoning, necessitating mastery of multiple intertwined skills (e.g., logical deduction, fine-grained categorization, spatiotemporal inference). The evolution of question content is empirically visualized as RL proceeds.
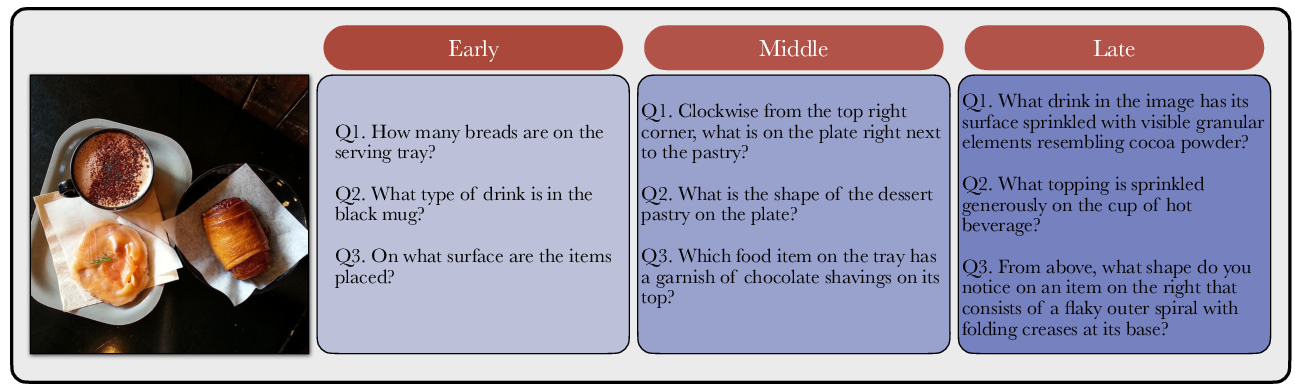
Figure 2: Evolution of RL-generated questions for a static image at different stages of training. The generated questions increase in complexity by probing fine-grained reasoning that requires proficiency in multiple skills.
Experimental Results
Quantitative evaluation addresses the failure discovery rate (FDR), question validity rate (QVR), semantic/lexical diversity, per-skill coverage, skill exclusivity, and evaluation generality across multiple base methods (Zero-Shot, ConMe, SFT, Expert Iteration, RL, RL+SFT) and VLM architectures (Qwen 3B, 7B, 8B, 30B). Key empirical findings include:
- RL-driven questioners achieve the highest FDR (up to 49.5%) and skill coverage (up to 123 distinct skills), outperforming static expert and other adversarial baselines in both breadth and depth of failure elicitation.
- RL-generated questions are not only more challenging, but also more diverse—uncovering exclusive failure modes with significantly higher FDR (e.g., >50% for RL-exclusive skills).
- Cross-model evaluation confirms that a stronger answerer reduces overall FDR, but a stronger questioner consistently exposes more nuanced and compositional failures in even the largest VLMs.
- Universal “hard” skills (e.g., brand recognition, OCR, symbol recognition) yield high failure rates across all tested models, while model-specific failures diminish as answerer capacity increases. Conversely, some skill failures remain resistant to scaling, indicating architectural or representation-level limits.
- RL synthesizes questions outside the reach of other methods. Taxonomy-driven analyses reveal that many discovered skills are both novel and persistent even with increased model size or dataset diversity.
Human Oversight and Validation
Human evaluation corroborates the reliability of automated judgments. Instance-level agreement for question validity with the Gemini-3.0-Flash auto-verifier exceeds 80%, while answer verification agreement averages 74.8%, with identical ranking of methods by humans and the auto-verifier. Notably, human annotators confirm that RL-synthesized failures are genuinely challenging, with RL+SFT and RL methods leading in both difficulty and coverage.
Failure Taxonomy & Skill Analysis
The paper’s taxonomy pipeline systematically abstracts failure-inducing queries from raw question text through to atomic skills and meta-skills. This process highlights persistent weaknesses (e.g., OCR, spatial relations, compositional reasoning, brand recognition, multilingual text interpretation) that resist scaling and training modifications. Exclusive failure skills discovered solely by RL methods underline the necessity of dynamic, model-adaptive test-time querying for comprehensive evaluation.
Practical and Theoretical Implications
Practically, the RL-driven approach provides a scalable, model-agnostic toolchain for rigorous VLM validation—enabling granular auditing, skill coverage mapping, and regression testing for both current and emerging architectures. The taxonomy allows stakeholders to discriminate between universal and model-specific failures, essential for safety-critical adoption of VLMs in real-world applications (e.g., autonomous systems, medical imaging, legal analysis).
Theoretically, the findings question the sufficiency of static benchmarks and suggest that dataset curation alone cannot guarantee skill generalization. Persistent universal failures indicate inductive biases and architectural weaknesses not easily overcome by scale, pointing to the need for architectural innovations, curriculum-oriented training, and robust evaluation pipelines.
Future Directions
Prospective work should address:
- Autonomous, continual co-evolution of questioners and answerers, closing the loop for adversarial self-improvement.
- Broader spectrum of multimodal failures (e.g., video, audio-visual reasoning), compositional inductive biases, and extended reasoning chains.
- Application to model interpretability: mapping failures to internal representations and computational motifs.
- Taxonomy-driven, curriculum-based training targeting persistent universal failures.
- Integration with robust certification pipelines for real-world, safety-critical VLM deployments.
Conclusion
This research formalizes and operationalizes the systematic discovery of vision-LLM failure modes using RL-driven, skill-diverse question synthesis. The dynamic, taxonomy-based pipeline reveals substantial new failure modes—many universal and previously undetected—offering both a diagnostic lens on current models and a blueprint for future VLM development and evaluation.