- The paper introduces HopChain, a novel multi-hop framework that constructs logically dependent visual queries to counter compounding reasoning errors.
- The methodology integrates explicit perception-level hops with systematic instance segmentation to ensure precise visual grounding across logical steps.
- Empirical validation shows significant gains on 20 out of 24 benchmarks, demonstrating enhanced generalization in extended chain-of-thought tasks.
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Motivation and Problem Analysis
Despite improving VLMs using RLVR, fine-grained and robust vision-language reasoning remains a significant challenge, especially under long chain-of-thought (CoT) prompting. When forced to perform multi-step visuo-linguistic chains, models frequently exhibit compounded failure types—including fine-grained perception errors, mishandled reasoning, knowledge gaps, and hallucinated intermediate steps. Standard vision-language RLVR training data typically lack such complex, dependency-structured chains, thus failing to sufficiently expose or correct these systemic weaknesses.
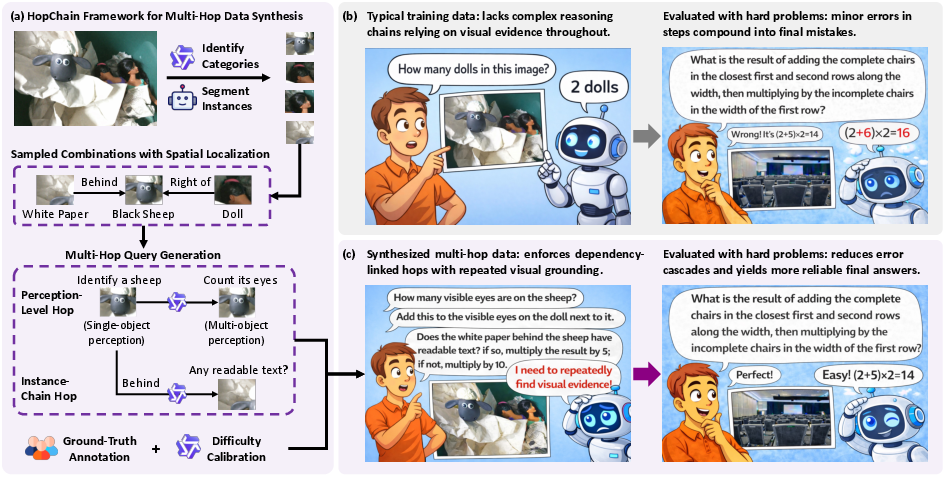
Figure 1: Overview of the HopChain paradigm, highlighting how synthesized, visually grounded multi-hop questions address long-CoT compounding error failure modes prevalent in standard datasets.
Analysis of model failures demonstrates that mistakes in early intermediate steps—such as misidentifying an object—cascade, corrupting all downstream reasoning and answer synthesis. Empirical annotation of errors shows a broad distribution spanning perception and reasoning as dominant categories, with knowledge and hallucination errors also significantly represented.
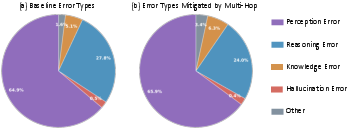
Figure 2: Distribution of error types before and after inclusion of multi-hop data, illustrating the dominance of perception and reasoning failures and the broad effect of multi-hop augmentation.

Figure 3: Qualitative examples where models without multi-hop training exhibit unreliable perception in extended reasoning chains, with highlighted corrections from multi-hop-augmented models.
The HopChain Framework
HopChain presents a scalable, systematic pipeline for generating structurally rich, multi-hop vision-language RLVR queries. Each synthesized example forms a chain where each hop is logically tied to entities, sets, or predicates resolved in prior hops—enforcing repeated visual regrounding and preventing language-only shortcutting.
HopChain's tasks are structurally enforced along two orthogonal dimensions:
- Perception-level hops: Alternation between single-object (attribute reading, text recognition, localization) and multi-object (counting, relational judgment, comparison) operations.
- Instance-chain hops: Explicit dependency chains where identification of the next entity/set requires resolving all prior hops (e.g., A→B→C), tightly coupling each query step to cumulative visual evidence.
Each synthesized query terminates in an unambiguous numerical answer compatible with RLVR verifiability, ensuring that correct final output requires persistent accuracy at every hop.

Figure 4: Examples of multi-hop data synthesized by HopChain, showing explicit instance chains and perception-level transitions grounded in visual attributes across image regions.
Scalable Synthesis Pipeline
The HopChain pipeline comprises:
- Category Identification: Semantic parsing of image-level entities using a high-capacity VLM to enumerate target categories.
- Instance Segmentation: Localization of individual object instances via SAM3 to generate meaningful referents for subsequent hops.
- Multi-Hop Query Generation: Automated and constrained construction of logical chains using a strong VLM with explicit dependence on visual evidence, ensuring query answerability only from real image content and preventing auxiliary signal leakage.
- Human-in-the-loop Annotation & Calibration: Multiple annotators independently solve each candidate query-labeled image, retaining only consensus-verified cases, after which overly easy queries are filtered using weaker models to maintain a challenging, informative training set.
Empirical Validation
Broad-Benchmark Generalization
Augmenting standard RLVR data with HopChain's multi-hop dataset yields robust, benchmark-agnostic improvements. Neither Qwen3.5-35B-A3B nor Qwen3.5-397B-A17B are tuned to any specific benchmark, yet multi-hop augmentation yields improvement on 20 out of 24 benchmarks across STEM, puzzle, general VQA, document understanding, and video understanding domains.
Ablation confirms that preservation of full query chains is critical: truncation to only single-hop or late-hop variants reduces mean benchmark scores substantially (from 70.4 to 66.7 and 64.3). Gains are most emphatic in long-response (ultra-long-CoT) regimes, with improvements exceeding 50 accuracy points in the longest bin.
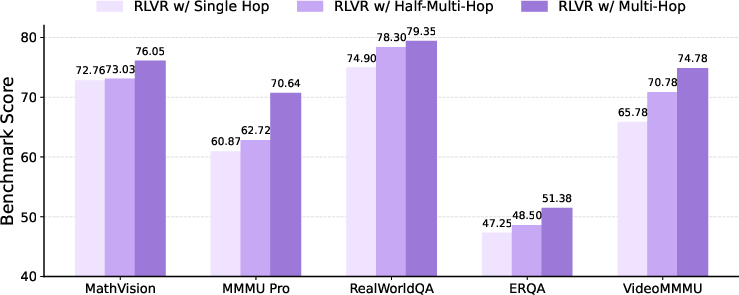
Figure 5: Comparative benchmark results under single-hop, half-multi-hop, and full multi-hop training; showing consistent advantage for full multi-hop across diverse tasks.
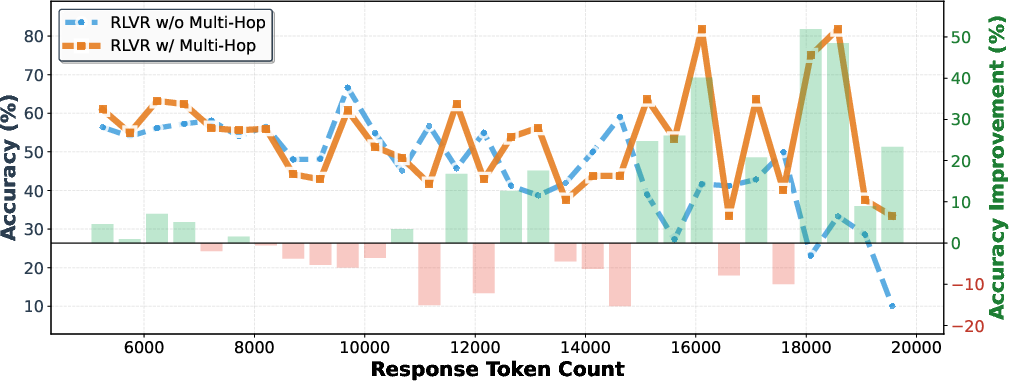
Figure 6: Accuracy as a function of response length, demonstrating that improvements from multi-hop data are especially pronounced for longer, more compound reasoning chains.
Difficulty Spectrum and Error-Mode Correction
Analysis reveals the synthesized multi-hop data exhibits substantial difficulty range, as evidenced by the distribution of partially, sparsely, and fully solved queries by both mid- and large-scale models.
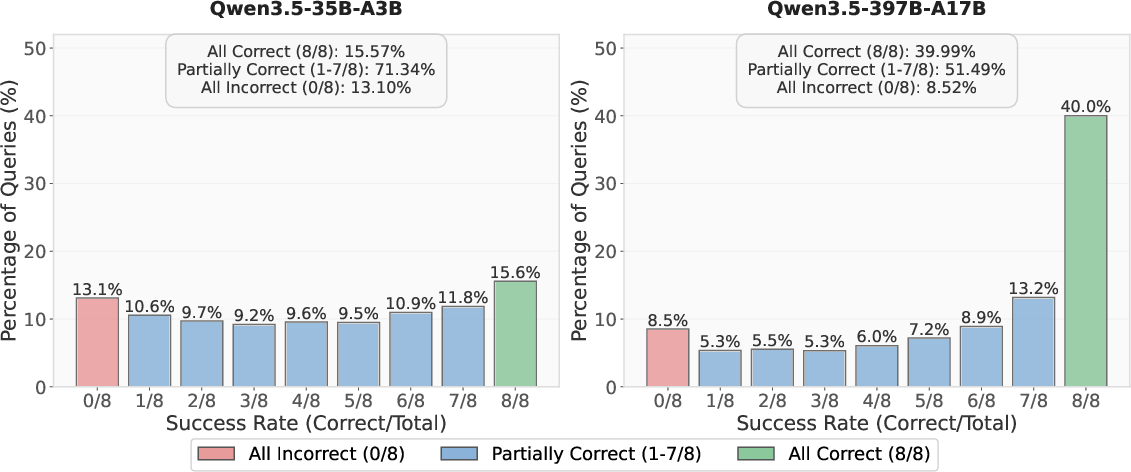
Figure 7: Success-rate distribution of multi-hop data, confirming a broad difficulty profile appropriate for driving model improvements across parameter scales.
Additional error breakdown confirms that corrections are broadly distributed across all major error classes, indicating that HopChain does not merely patch narrow failure slices but strengthens robustness over diverse reasoning challenges.

Figure 8: Error distribution among cases improved by multi-hop data, demonstrating substantial correction across perception, reasoning, logic, and object-level failures.
Theoretical and Practical Implications
HopChain's data-centric perspective on vision-language RLVR provides a scalable means to close the gap between multi-step, perceptually grounded reasoning required by real-world tasks and the surrogates typically emphasized in existing training corpora. The induction of explicit, instance-coupled chains typeset for RL training directly mitigates both shallow shortcut exploitation and compounding error propagation. This architecture- and model-agnostic signal is shown to be composable, yielding gains not only in image-based but also video-based tasks, highlighting its transfer properties.
Scalability is bounded by segmentation capability; thus, further extensions could augment the instance-anchoring strategy to handle non-segmentable or abstract images. This would permit generalized deployment in less structured or more abstract visual domains.
Conclusion
HopChain operationalizes multi-hop visual reasoning as a generative training paradigm that structurally targets compounding errors in long-CoT vision-LLMs. By synthesizing logically dependent, instance-anchored chains and integrating them through RLVR with verifiable reward supervision, it enables generalizable improvement—spanning domains, model scales, and error types—without reliance on benchmark overfitting. Its data-driven induction strategy offers a template for further advances in robust, scalable, and highly generalizable multimodal reasoning systems.