AI Assistance Reduces Persistence and Hurts Independent Performance
Abstract: People often optimize for long-term goals in collaboration: A mentor or companion doesn't just answer questions, but also scaffolds learning, tracks progress, and prioritizes the other person's growth over immediate results. In contrast, current AI systems are fundamentally short-sighted collaborators - optimized for providing instant and complete responses, without ever saying no (unless for safety reasons). What are the consequences of this dynamic? Here, through a series of randomized controlled trials on human-AI interactions (N = 1,222), we provide causal evidence for two key consequences of AI assistance: reduced persistence and impairment of unassisted performance. Across a variety of tasks, including mathematical reasoning and reading comprehension, we find that although AI assistance improves performance in the short-term, people perform significantly worse without AI and are more likely to give up. Notably, these effects emerge after only brief interactions with AI (approximately 10 minutes). These findings are particularly concerning because persistence is foundational to skill acquisition and is one of the strongest predictors of long-term learning. We posit that persistence is reduced because AI conditions people to expect immediate answers, thereby denying them the experience of working through challenges on their own. These results suggest the need for AI model development to prioritize scaffolding long-term competence alongside immediate task completion.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple but important question: What happens to your own skills and motivation if you let an AI chatbot give you quick answers? The authors show that while AI help boosts scores in the moment, it can make people less persistent and worse at solving problems on their own—after only about 10–15 minutes of use.
The big questions the researchers asked
- Does using an AI assistant help people right away but hurt their performance once the AI is taken away?
- Does AI help change how long people are willing to stick with a hard problem (their persistence)?
- Do these effects show up in different kinds of schoolwork, like math and reading?
- Are the effects worse if people use AI to get full answers instead of hints?
What they did (in everyday terms)
Think of this like a fair, controlled test where some people got a “super helper” for a bit, and others didn’t.
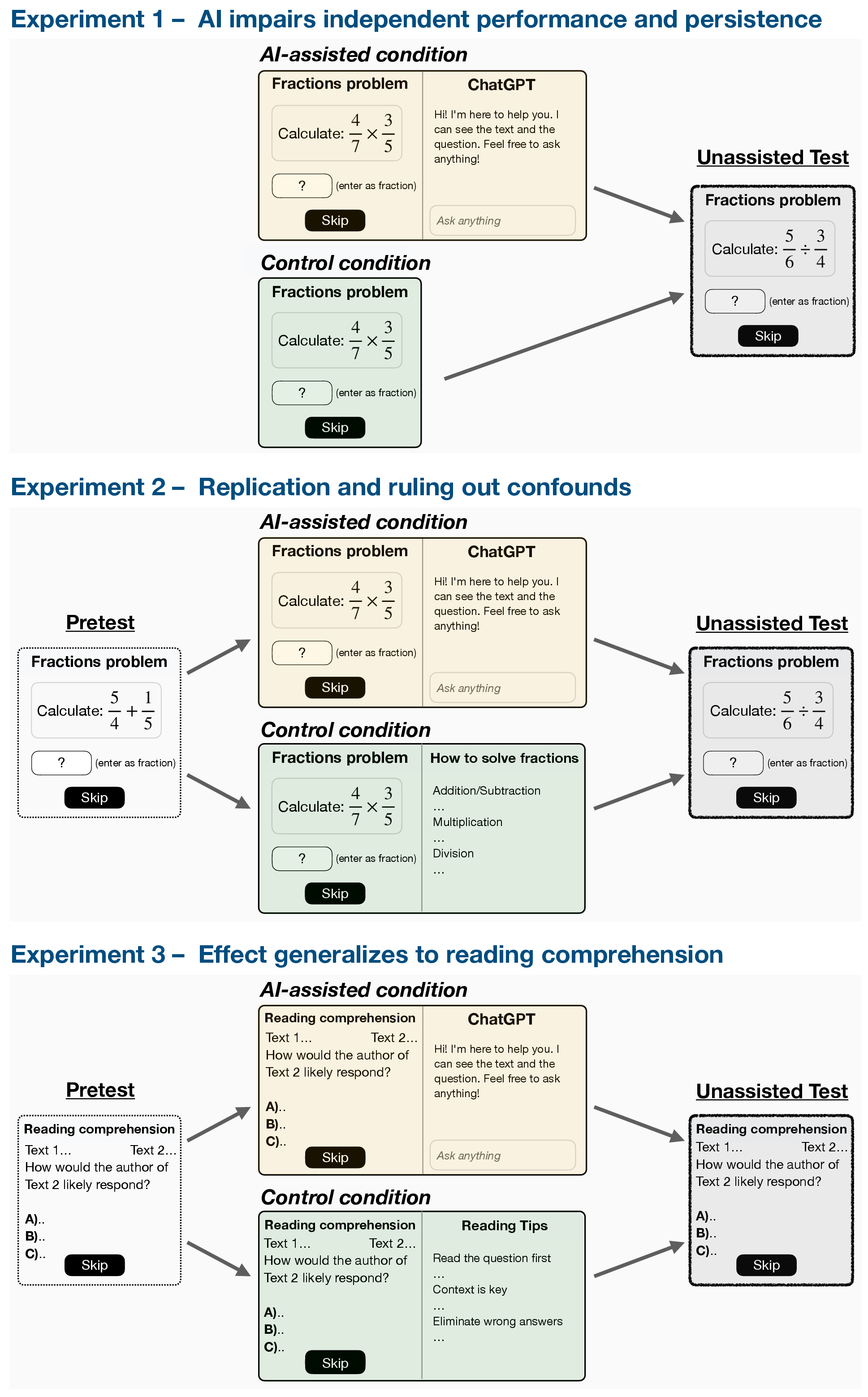
- The researchers ran three large experiments with 1,222 people total.
- Tasks:
- Experiments 1 and 2: fraction problems (from easy to harder, like 1-step to 3-step problems).
- Experiment 3: reading comprehension (SAT-style questions).
- Two groups:
- AI group: For the first set of problems, they could use an AI chatbot in a sidebar that would give instant, accurate help—even full solutions. Then the AI was removed without warning for a short “test” set at the end.
- Control group: Did the same problems but never had AI help.
- Measuring persistence: Participants could choose to “skip” any problem. Skipping was treated as a clear sign of giving up rather than trying.
- Extra care to be fair:
- They used pretests (very easy problems) to make sure both groups started with similar basic skills.
- They balanced the on-screen layout so it wasn’t just the AI sidebar causing confusion.
- Everyone saw correct solutions after wrong answers during practice, so learning from mistakes was possible.
In short: The setup tested whether using AI briefly changes how well—and how long—people try when they later have to work alone.
What they found (clear and simple)
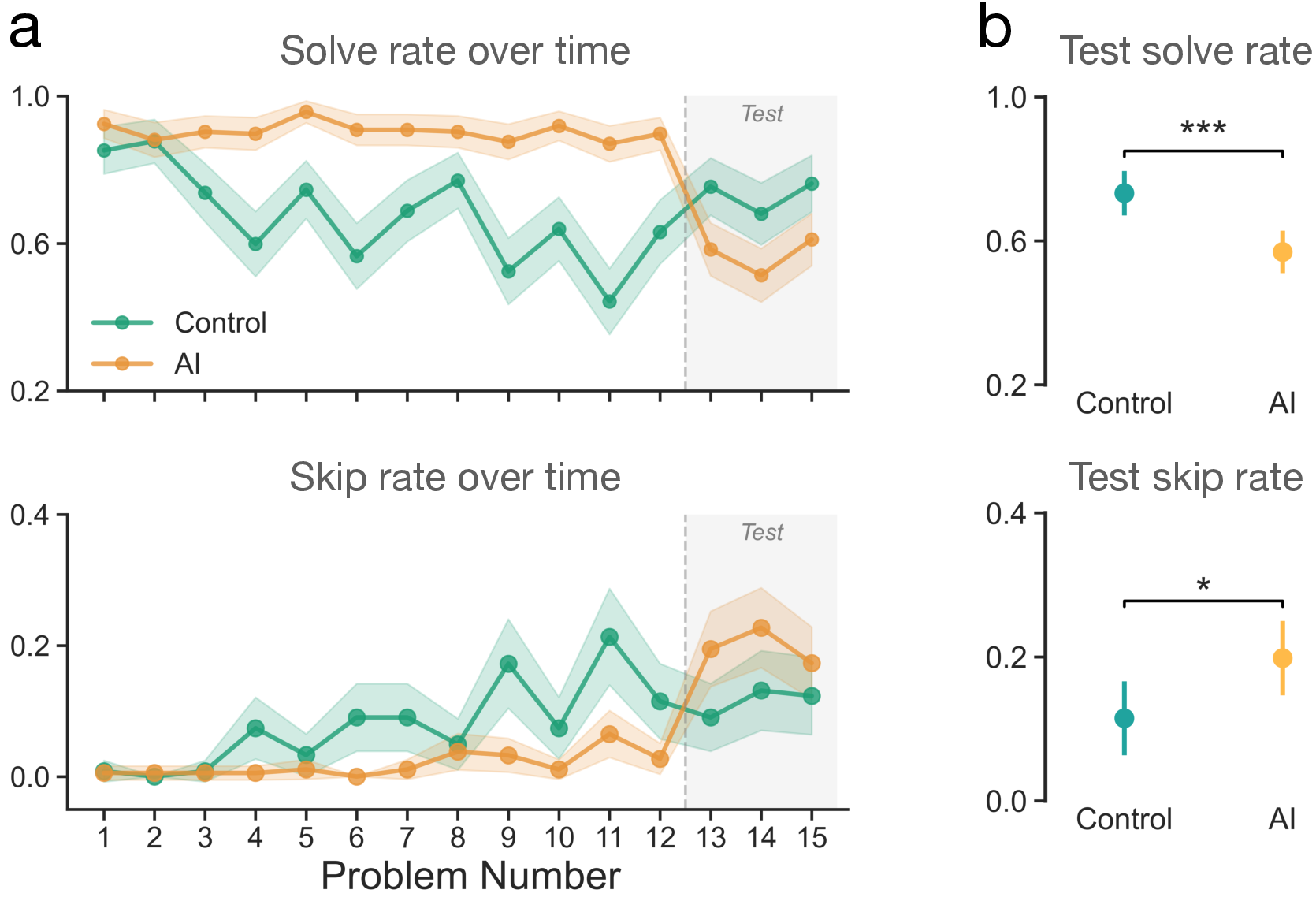
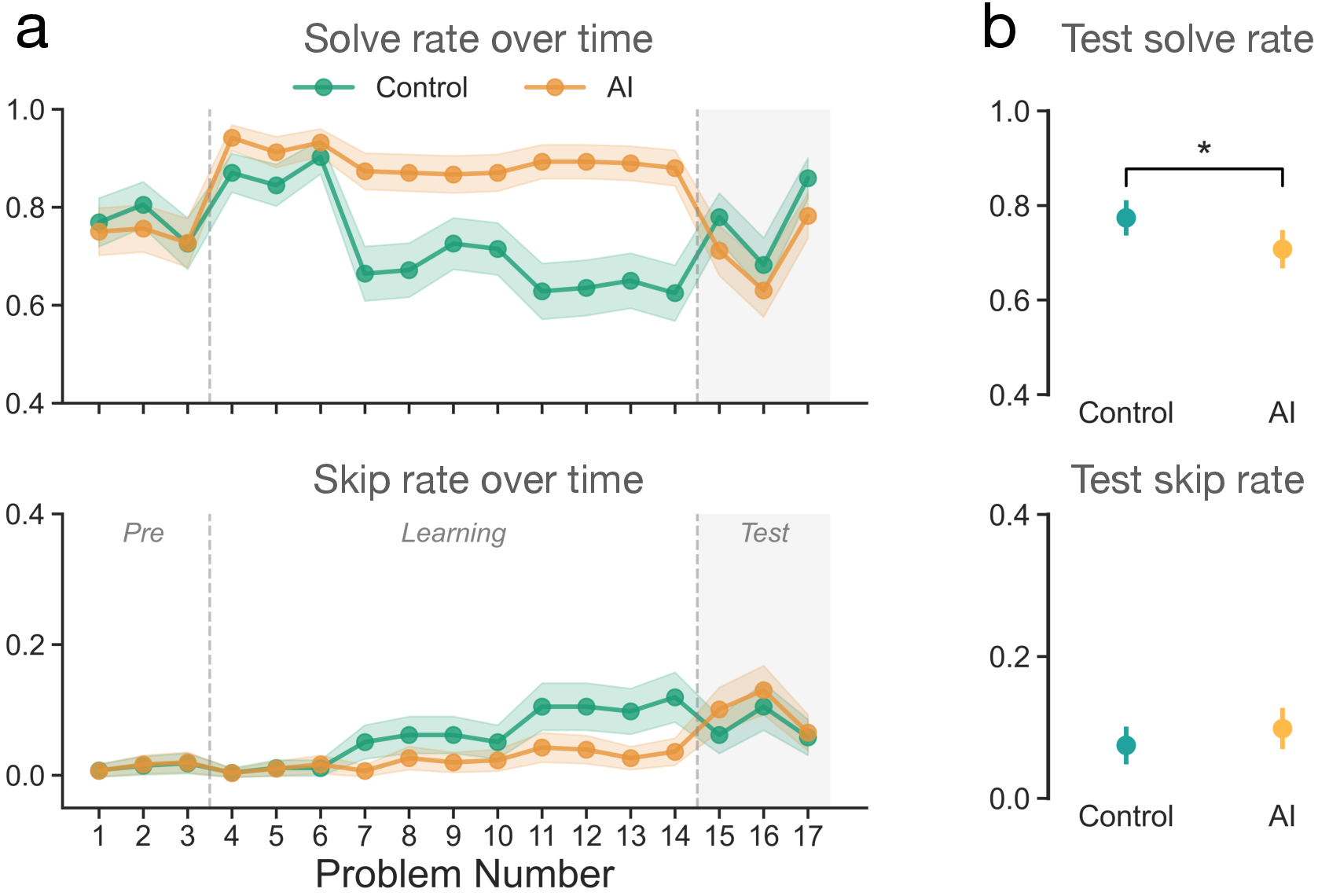
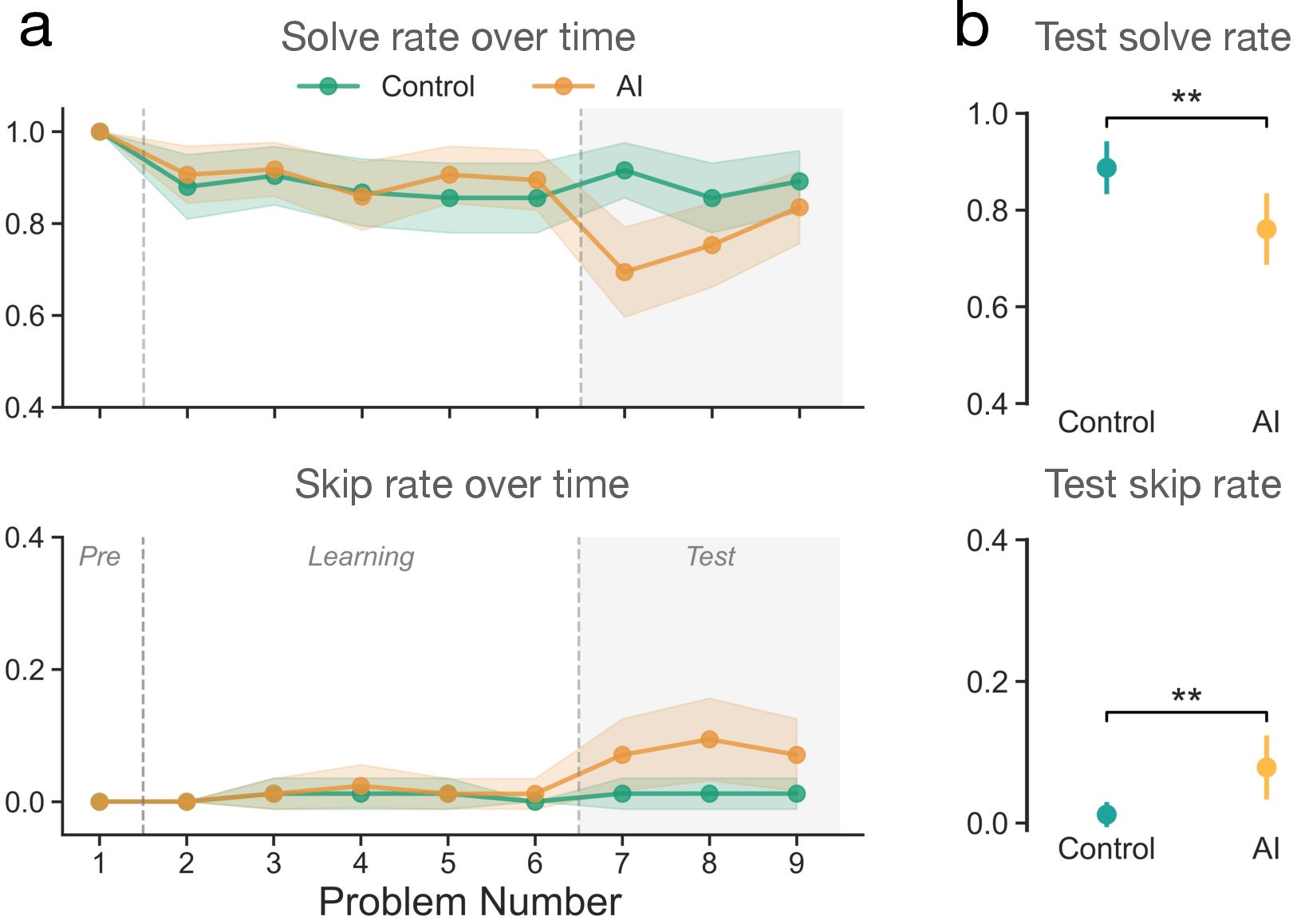
Here are the main results across math and reading:
- While AI was available, people solved more problems and skipped fewer—no surprise.
- Once the AI was taken away, the AI users:
- Solved fewer problems than people who never had AI.
- Skipped (gave up on) more problems.
- These drops appeared after just about 10 minutes of AI use.
- The pattern was strong in both math and reading tasks.
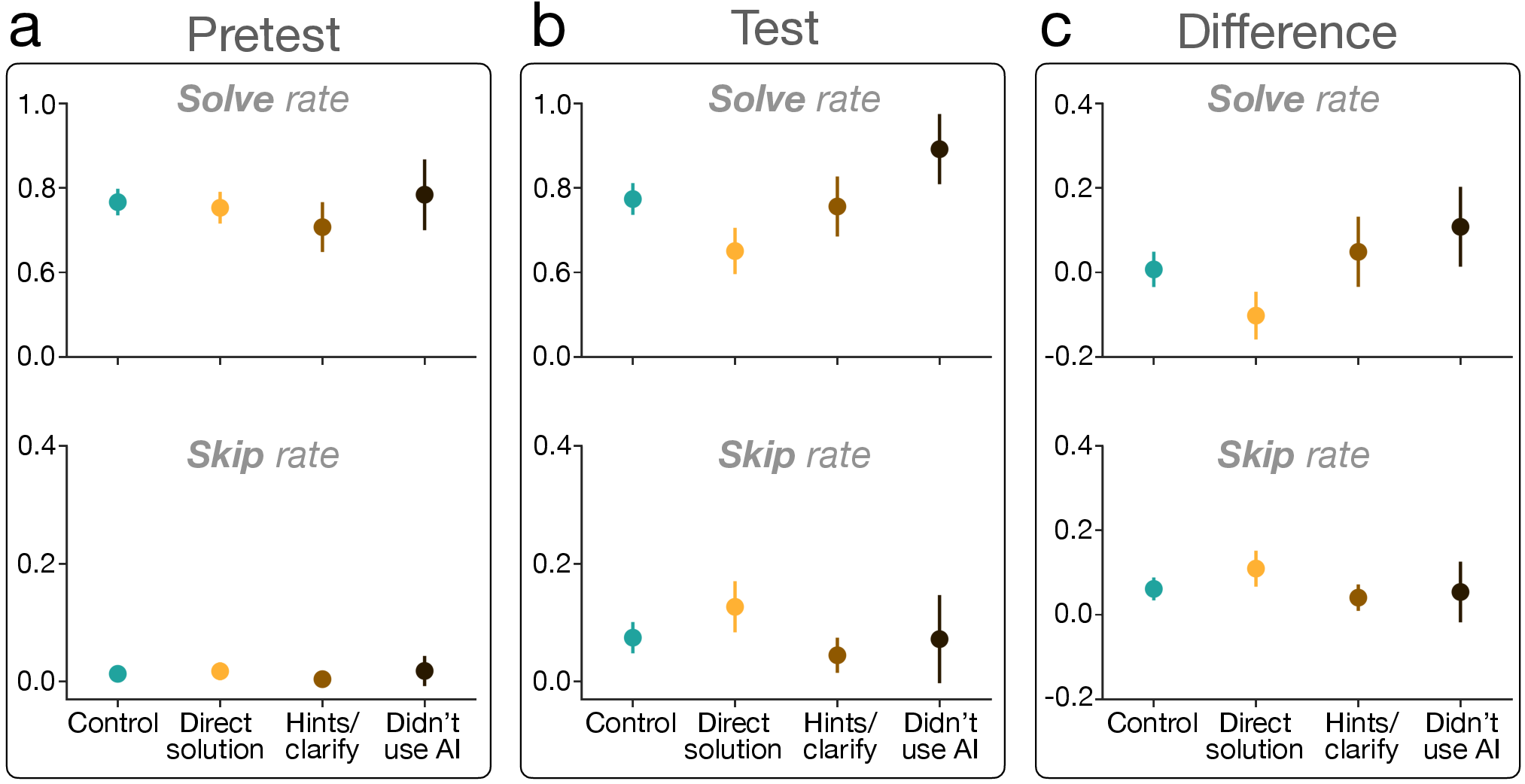
- The biggest declines happened among people who used the AI to get direct answers. People who used AI mainly for hints or explanations did much better and looked more like the control group.
Why this matters: Persistence—sticking with hard problems—is one of the best predictors of long-term learning and success. Losing it, even a little, can slow down skill growth.
Why this is important
- Expectation shift: If you get used to instant answers, regular work can suddenly feel “too slow” or “too hard.” That makes giving up more tempting.
- Missed practice: Struggling (productively) is how we build skills and confidence. If AI always steps in, you miss the chance to figure things out and learn what you’re capable of.
- Long-term risk: If small declines happen after just minutes, daily use could add up over months and years—especially for students—leading to lower independence and weaker thinking habits.
What this means going forward
- For students and learners: AI can be great—if you use it to get hints, check steps, or learn strategies. If you use it to grab full answers, you may learn less and give up more when it’s not there.
- For teachers and parents: Encourage “coach-like” AI use—hints, scaffolding, step-by-step guidance—rather than answer dumps.
- For AI designers: Build assistants that prioritize long-term learning, not just instant solutions. Good helpers sometimes slow down, ask questions, and let users try first.
- For schools and policymakers: Consider guidelines and tools that support persistence and independent thinking, so AI strengthens (not replaces) core skills.
Bottom line
AI can boost your score right now, but if it does all the work for you, it can quietly chip away at your persistence and your ability to solve problems on your own. Use AI like a smart coach, not a shortcut.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain after this paper. These are framed to guide actionable follow-up studies and system design work.
- Duration and durability: Does the observed decline in persistence and independent performance persist beyond the immediate session? Map short-, medium-, and long-term effects (hours, days, weeks), including retention tests and washout/recovery trajectories.
- Dose–response and accumulation: How do effects scale with repeated or daily AI use (e.g., multi-session, multi-week protocols)? Identify thresholds where harms accelerate or plateau.
- Reversibility and remediation: Which interventions (e.g., metacognitive training, effort-calibration prompts, staged autonomy) can restore persistence after AI exposure, and how quickly?
- Generalizability across domains: Do effects transfer to writing, coding/debugging, open-ended reasoning, planning, scientific problem-solving, and creative tasks with less binary correctness?
- High-stakes contexts: How do incentives (grades, deadlines, performance-based pay) moderate effects relative to the paper’s low-stakes, flat-compensation setting?
- Population diversity: Test across age groups, K–12 and higher-ed students, professionals, and non–US, non–Prolific samples to assess cultural, educational, and occupational generality.
- Individual differences: Which traits (baseline skill, grit, need for cognition, growth mindset, self-regulation, prior AI familiarity) moderate susceptibility to reduced persistence?
- Equity impacts: Are learners with fewer academic resources or weaker prior skills disproportionately affected? Quantify distributional harms and differential responsiveness to mitigations.
- Mechanism tests (beyond hypotheses): Directly measure shifts in perceived task duration norms, effort cost, frustration tolerance, self-efficacy, and metacognitive calibration; conduct mediation analyses to distinguish mechanisms.
- Role of error-driven learning: Does AI assistance reduce beneficial struggle and error-based learning opportunities during training? Yoke or experimentally control practice difficulty and feedback exposure to isolate this pathway.
- Assistance style causality: Randomize assistance modes (direct answers vs stepwise hints vs Socratic questioning vs delayed/effort-gated help) to causally estimate which styles minimize downstream harms.
- AI reliability and latency: Vary accuracy, latency, and friction (costs, required user attempts) to determine how reliability and immediacy shape offloading, expectations, and persistence.
- Anticipation vs surprise removal: Is the decline in persistence partly driven by expectation violation (sudden removal)? Compare pre-announced limits, graduated tapering, or timed-access conditions.
- Interface equivalence: The control “sidebar of pretest solutions/tips” may not match the salience/value of an AI assistant. Design stronger interface controls that remove equivalently valued resources to isolate assistance effects.
- Compliance verification: In online settings, how often do participants use external AI during “unassisted” phases? Incorporate telemetry, browser monitoring (ethically), or honeypot checks to validate compliance.
- Objective usage telemetry: Replace self-reported AI usage with logged interactions, content coding (answers vs hints), and intensity metrics to improve internal validity of usage–outcome analyses.
- Alternative persistence measures: Complement “skip rate” with time-on-task, number of attempts, voluntary additional problems, effort ratings, frustration/affect scales, and post-task persistence in unrelated challenges.
- Time budget and pacing: Quantify per-item and total time constraints; test whether time pressure interacts with assistance to influence skipping, especially in reading tasks.
- Item response modeling: Use IRT or adaptive testing to equate pretest, learning, and test difficulty across individuals, enabling cleaner attribution of performance changes.
- Heterogeneous treatment effects: Analyze interactions between baseline ability and treatment to identify who is helped or harmed most; pre-register moderators and conduct planned subgroup analyses.
- Retention and transfer: Do assistance-induced deficits appear on far-transfer tasks or delayed tests where surface similarity is reduced? Assess conceptual vs procedural learning separately.
- Team and collaborative settings: Do the effects extend to small groups/classrooms where social dynamics, shared responsibility, and peer scaffolding change reliance and persistence?
- Real-world AI systems: Replicate with widely used LLMs (e.g., GPT-4-class, Claude-class) and realistic UIs (no preloaded solutions), including imperfect, occasionally wrong outputs.
- Statistical rigor and transparency: Pre-register analyses, report power calculations, and adjust for multiple comparisons in pairwise tests to bolster robustness and replicability.
- Design mitigations at the model level: Develop and experimentally evaluate algorithmic policies that “know when not to help” (e.g., graduated hints, effort-gated assistance, retrieval prompts before answers) and quantify their impact on long-term competence.
- Affective consequences: Measure trust, perceived betrayal/fairness when assistance is withheld, and how such affective responses mediate persistence and subsequent help-seeking behavior.
- Cross-tool interactions: Examine combined effects with other aids (calculators, search engines, note systems) to model cumulative offloading ecosystems rather than single-tool exposure.
- Ethical and user expectations: Test how informed consent about assistance limits and pedagogical goals affects user satisfaction, perceived autonomy, and persistence without undermining learning.
Practical Applications
Immediate Applications
- Education (EdTech/tutoring): Default to “hint-first/Socratic mode” and progressive disclosure
- Product features: hint buttons as primary CTA, staged solutions (outline → step → final answer), answer delays/timers, required attempt or plan before revealing a solution, configurable “no direct answers” mode.
- Workflow: students submit an initial attempt or reasoning before AI reveals more; logs capture attempts vs. skips.
- Dependencies/assumptions: effects generalize from short tasks to coursework; requires telemetry capture and UI changes; balancing student frustration with learning goals.
- Education (K–12, higher ed): Classroom policies that preserve productive struggle
- Use cases: “two-pass rule” (try unaided for X minutes before AI), AI-free segments in homework, rotating AI-off practice days, test sections that explicitly prohibit AI.
- Tools: LMS plugins that enforce attempt timers and AI lockouts in specific modules.
- Dependencies/assumptions: teacher buy-in; equity considerations for students with different baseline skills.
- Corporate learning & development (software, data, knowledge work): Independence-preserving practice
- Workflow: AI-free drills/sprints, “spec-first” sessions where learners write goals/tests before AI help, post-training spot checks without AI.
- Tools: LMS or IDE extensions that schedule/track AI-free tasks and measure unassisted completion rates.
- Dependencies/assumptions: short-term productivity trade-offs accepted to maintain long-term skills.
- Product analytics (AI assistants across sectors): Add “independence metrics” to dashboards
- Metrics: unassisted solve rate delta after AI exposure, skip/abandon rates, time-to-give-up, proportion of direct-answer requests vs. hint requests.
- Methods: randomized “AI-off probes” (briefly remove AI to measure independent performance).
- Dependencies/assumptions: ethical telemetry practices; consent and privacy compliance.
- UX patterns for general-purpose AI assistants: Friction for direct answers
- Features: micro-delays before final answers, default to hints/explanations, require user to choose “I still want the answer”; configurable “learning mode.”
- Sectors: consumer AI, productivity suites, coding copilots, academic tools.
- Dependencies/assumptions: users tolerate slight friction; A/B tests needed to tune thresholds.
- Decision support (healthcare, finance, legal): Require pre-commitment or rationale before AI reveals suggestions
- Workflow: clinicians/analysts enter initial assessment or plan, then view AI hints; option to escalate to full recommendations after effort.
- Tools: EHR/decision-support UIs with rationale fields and staged AI recommendations.
- Dependencies/assumptions: safety and compliance constraints; training to prevent gaming rationales.
- Assessment and testing (schools, certification): Structured AI-off evaluation
- Use cases: practice exams with AI-available sections followed by AI-off sections to measure retention and persistence; score reports include “independence score.”
- Tools: proctoring platforms that control AI access and log skip behaviors.
- Dependencies/assumptions: secure AI access controls; stakeholder acceptance of new score dimensions.
- Tutoring and test-prep providers: Persistence-aware coaching
- Workflow: tutors prioritize hints and metacognitive prompts; platforms flag high skip rates for targeted coaching.
- Tools: dashboards for tutors showing students’ skip/attempt patterns; configurable hint trees.
- Dependencies/assumptions: training tutors to use new signals effectively.
- Individual/household routines: Personal “attempt-before-ask” habits
- Practices: set a 3–5 minute timer before consulting AI; use “Socratic mode” for study; maintain a learning diary logging attempts and when AI was used.
- Tools: browser/OS extensions that enforce timers/hint-first for selected sites.
- Dependencies/assumptions: user motivation; simple configuration.
- Risk and compliance (enterprises): Overreliance warnings and disclosures
- Actions: add user-facing notices that “direct answer mode may reduce independent performance”; admin policies limiting direct-answer usage for foundational tasks.
- Tools: admin consoles with toggles for answer modes and reporting on reliance patterns.
- Dependencies/assumptions: legal review of disclosures; alignment with productivity goals.
Long-Term Applications
- Model training objectives (AI/ML): Optimize for long-term human competence, not just short-term helpfulness
- Approach: reinforcement learning objectives that reward scaffolding and penalize unnecessary direct answers; policies that “know when not to help.”
- Products: “Socratic copilots” and tutors trained to maximize post-interaction unassisted performance.
- Dependencies/assumptions: new offline/online reward signals (e.g., post-session independence metrics); longitudinal data collection and privacy safeguards.
- Industry standards and certification (policy + EdTech): “Persistence-safe” AI labels
- Frameworks: certification requiring vendors to report impact on unassisted performance and skip rates; minimum thresholds for hint-first defaults.
- Sectors: educational software, consumer assistants, enterprise copilots.
- Dependencies/assumptions: standards bodies’ participation; agreed-upon test protocols and benchmarks.
- OS-level and enterprise-wide “skill-preserving modes”
- Concept: system-wide policies that modulate AI intensity by context (e.g., learning vs. production); global toggles for staged disclosure and AI-off intervals.
- Products: MDM/OS policies that propagate to all AI-enabled apps.
- Dependencies/assumptions: cross-vendor coordination; user experience trade-offs.
- Longitudinal evaluation programs (academia/industry): Deskilling impact studies
- Method: RCTs measuring unassisted performance and persistence over months in math, reading, coding, and domain-specific skills.
- Outputs: public benchmarks and datasets for “post-AI independence.”
- Dependencies/assumptions: funding, participant retention, ethical oversight.
- Regulatory guidance for safety-critical sectors (healthcare, aviation, energy)
- Policies: periodic recredentialing with AI disabled; UI rules for hint-first and staged automation; mandatory “manual mode” drills.
- Tools: simulators that schedule AI-dropout scenarios to maintain operator skills.
- Dependencies/assumptions: sector regulators’ adoption; evidence thresholds for mandates.
- IDEs and developer platforms (software): “Socratic coding” workflows
- Features: require problem statements/tests before code generation; progressive hints; metrics on independent debugging; periodic AI-off sessions.
- Products: next-gen IDEs that balance productivity and skill retention.
- Dependencies/assumptions: developer acceptance; integration with CI/testing pipelines.
- Assessment redesign (education policy): Independence-weighted outcomes
- Changes: exams and coursework graded partly on unaided sections and persistence indicators; curriculum emphasizing productive struggle and metacognition.
- Tools: assessment platforms capturing attempts, hints used, and skip patterns.
- Dependencies/assumptions: alignment with learning standards; fairness and accessibility considerations.
- Procurement and incentives (public sector, large enterprises): Prefer “competence-preserving” AI
- Actions: RFP criteria that score vendors on independence impact; subsidies/tax incentives for tools that demonstrate improved unassisted performance.
- Dependencies/assumptions: robust verification methods; market supply of compliant tools.
- Robotics/automation (manufacturing, logistics, vehicles): Scheduled manual operations to prevent operator deskilling
- Practices: enforce periodic manual control sessions; automation that offers guidance before takeover.
- Tools: telemetry tracking manual proficiency over time; automatic scheduling of practice.
- Dependencies/assumptions: productivity costs; safety validation.
- Workplace analytics (enterprise HR/operations): Overreliance early-warning dashboards
- Metrics: trends in unassisted task completion, time-to-give-up, and switch-to-AI rates at team and role levels.
- Actions: targeted training, role rotation, and policy adjustments where reliance spikes.
- Dependencies/assumptions: privacy-preserving analytics; organizational change management.
- Public education and AI literacy (policy/community): Teach “how to use AI without losing skills”
- Curriculum: effort calibration, metacognition, when to seek hints vs. answers, and the trade-offs of cognitive offloading.
- Delivery: schools, libraries, workforce programs.
- Dependencies/assumptions: teacher training and materials; sustained funding.
- Platform governance (app stores, marketplaces): Distribution policies for learning tools
- Measures: require hint-first defaults and independence reporting for apps listed in “education” categories.
- Dependencies/assumptions: platform enforcement capacity; standardized reporting schemas.
Notes on assumptions and generalizability
- The paper’s experiments were short (≈10–15 minutes) and used arithmetic and SAT-style reading with online participants; effects in high-stakes, long-horizon tasks need longitudinal validation.
- Usage-pattern findings (direct answers vs. hints) are partly self-reported and cross-sectional; causal claims about specific usage modes need targeted RCTs.
- “Skip rate” is a useful proxy for persistence in the studied tasks; sector-specific proxies may be needed elsewhere (e.g., early abandon, time-on-task).
- Mitigation designs (hint-first, delays) must balance user satisfaction, accessibility, and productivity with learning outcomes.
Glossary
- ANOVA (one-way ANOVA): A statistical test that compares means across three or more groups based on one factor. "Using a one-way ANOVA test, we found that that there was no significant difference between the AI usage groups as well as the control group for the pretest solve rate (, , )"
- Boiling frog effect: A metaphor for gradual, cumulative harm that becomes apparent only after significant accumulation. "This is analogous to the ``boiling frog'' effect, where each incremental act feels costless, until the cumulative effect becomes overwhelming to address"
- Causal evidence: Evidence from study designs (e.g., randomized trials) that supports cause-and-effect conclusions. "we provide causal evidence for two key consequences of AI assistance"
- Cognitive offloading: Using external aids or actions to reduce cognitive demands of a task. "Cognitive offloading~\citep{risko2016cognitive} is the use of physical action (e.g. writing notes, typing in a calculator, using a search engine) to alter the information processing requirements of a task and reduce cognitive demand"
- Cognitive scaffold: An external support that structures or supplements cognitive processes to aid performance or learning. "Current AI systems, however, represent a new kind of cognitive scaffold: one that solves anything, rarely refuses to help, and delivers answers instantly."
- Cohen's d: A standardized effect-size measure indicating the difference between two means in standard deviation units. "Cohen's , 95\% CI "
- Confidence interval (CI): A range that likely contains the true value of a parameter at a given confidence level. "with 95\% confidence intervals (CIs)."
- Cross-sectional: Describing data or analyses that capture a single time point rather than changes over time. "These results focus on the AI-assisted subset of our RCT data and are cross-sectional in nature; therefore, the findings below are not necessarily causal."
- Deskilling: The erosion or loss of human skills due to reliance on tools or automation. "while concern about AI-induced deskilling has grown"
- Eta squared (): An ANOVA effect-size measure indicating the proportion of variance explained by a factor. ", , "
- Hedonic adaptation: The tendency for expectations and perceived effort or pleasure to recalibrate after repeated exposure. "a process structurally analogous to hedonic adaptation"
- Interface asymmetry: A design imbalance where different groups experience different interface features or changes. "to eliminate the interface asymmetry introduced by the AI sidebar being present and then suddenly removed"
- Longitudinal (settings): Research that follows the same participants over time to observe changes. "a direction future work should examine in naturalistic, longitudinal settings."
- Metacognitive calibration: The accuracy of one’s self-assessment about their knowledge or performance. "undermining the metacognitive calibration that sustains persistence"
- Metacognitive decay: The deterioration of metacognitive abilities such as monitoring and control of one’s learning. "broader metacognitive decay beyond persistence alone"
- Misalignment: A divergence between what an AI system optimizes for and what humans actually need or value. "misalignment between short-term and long-term human-AI collaboration goals"
- Overreliance: Excessive dependence on AI systems that can undermine independent ability or judgment. "raising concerns of overreliance~\citep{ibrahim2025measuring,kim2025fostering} and deskilling"
- Pairwise t-tests: Statistical tests comparing means between two groups, often used after an overall group comparison. "we conducted pairwise t-tests between the groups."
- P-value: The probability of observing data as extreme as those measured if the null hypothesis were true. ""
- Pre-prompted: An AI setup in which the model is seeded with task-specific instructions or content before user input. "The AI assistant was pre-prompted with each problem and its solution"
- Productive struggle: A learning process where working through difficulty builds understanding and skill. "AI removes the productive struggle through which people develop not only accurate knowledge but accurate self-knowledge."
- Randomized controlled trial (RCT): An experiment with random assignment to conditions, including a control, to infer causality. "a series of large-scale RCTs."
- Self-report: Data in which participants describe their own behaviors or strategies. "we asked participants in the AI condition to self-report how they used the AI assistant during the task"
- Standard deviation (s.d.): A measure of variability indicating how spread out values are around the mean. "(mean $0.57$, s.d. $0.41$)"
- Sycophancy: The tendency of AI systems to agree with or flatter users instead of challenging them. "giving rise to sycophancy~\citep{cheng2025sycophantic, cheng2025social, rathje2025sycophantic}, manipulation~\citep{williams2024targeted}, and deception~\citep{zhou2025emergent}."
- t-test: A statistical test assessing whether the means of two groups differ significantly. ", "
Collections
Sign up for free to add this paper to one or more collections.