- The paper identifies grokking as a dimensional phase transition, marking a shift from sub-diffusive to super-diffusive gradient dynamics.
- It employs finite-size scaling of gradient avalanche dynamics to extract an effective dimensionality D that signals the onset of generalization.
- Results show that the transition is architecture-independent and linked to self-organized criticality, with synchronized peaks in weight concentration.
Grokking as a Dimensional Phase Transition in Neural Networks
Introduction
The analysis centers on a quantitative investigation of grokking phenomena in neural networks, employing finite-size scaling (FSS) of gradient avalanche dynamics to elucidate the underlying transition from memorization to generalization. Unlike prior qualitative accounts, this work establishes that grokking in overparameterized settings is characterized by a measurable dimensional phase transition in the geometry of the gradient field. The study associates this transition with self-organized criticality (SOC), extracting an effective dimensionality D through avalanche extent scaling. Remarkably, this transition is robust to network topology and revealed to be a function solely of gradient field structure, decoupling architectural choices from the key determinant of criticality.
Experimental Protocol and Methodology
The analysis utilizes the XOR boolean function task as a minimal, transparent testbed free from confounds associated with large datasets, with multilayer perceptrons spanning hidden dimensions h=20–$500$ (parameters N=81–$2001$). Gradient snapshots are sampled at regular intervals across training. To probe the degree of parameter coupling, a threshold-driven diffusion update (TDU-OFC)—inspired by SOC in earthquake models—injects training gradients as initial conditions and observes the induced avalanches on a Barabási-Albert graph.
Avalanche size statistics are collected, and the effective dimensionality D is extracted via FSS using the scaling smax∼ND. Real training runs are compared to synthetic controls with i.i.d. Gaussian gradients, validating that any dimensional excess is attributable to structured correlations imposed by backpropagation. This enables precise temporal tracking of the geometric evolution of gradient dynamics throughout training.
Main Results
Grokking as a Dimensional Phase Transition
The central finding is the identification of a continuous evolution in D during training. Pre-grokking, the system displays sub-diffusive dynamics (D≈0.90), reflecting spatially localized cascades. As training proceeds, D increases, crossing the random-diffusion baseline (h=200 for i.i.d. Gaussian gradients) at the grokking epoch, and subsequently enters the super-diffusive regime (h=201), indicative of highly coordinated, large-scale avalanches aligned with successful generalization.
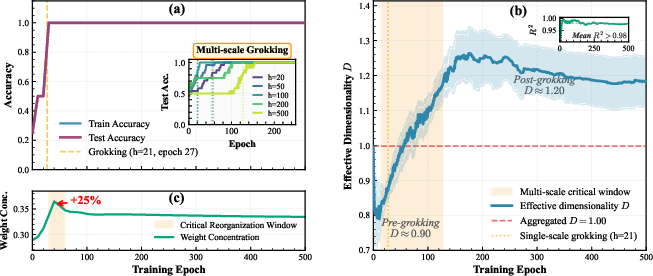
Figure 1: Training and evaluation accuracies for a representative XOR network show a synchronized abrupt transition; contemporaneous evolution in h=202 reveals a continuous sub-diffusive to super-diffusive transition, validated across model scales; the Gini coefficient of weight norms exhibits a transient peak synchronizing with grokking.
The transition in h=203 is corroborated by multi-seed statistics and is mirrored by a transient peak in weight concentration (Gini coefficient), offering an independent signature of the underlying structural reorganization. Notably, the timing of these phenomena is precisely synchronized across seeds and system sizes, tightly localizing the critical window.
Scale-Invariant Avalanche Dynamics and Data Collapse
Finite-size avalanche statistics exhibit heavy-tailed, scale-dependent distributions with systematically growing cutoffs (h=204) as system size increases. Data collapse is achieved when plotting avalanche size distributions as a function of h=205, consolidating all model scales to a common critical curve, a signature of SOC.
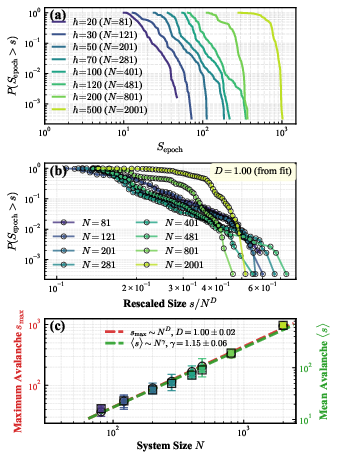
Figure 2: Complementary cumulative distributions of avalanche sizes reveal heavy-tailed, scale-dependent behavior with systematic cutoff growth; data collapse using the exponent h=206 demonstrates scale-invariance; FSS confirms h=207 and h=208 across all scales.
The scaling exponents extracted from aggregate statistics (h=209, $500$0) confirm quasi-1D cascade geometry, distinct from the higher-dimensional avalanche propagation seen in classical SOC systems, consistent with the notion that learning dynamics are constrained to low-dimensional solution manifolds.
Gradient Geometry and Topology Invariance
Bootstrap analysis across 10,000 resamples phase-split at the grokking epoch yields three non-overlapping distributions for $500$1: ($500$2 pre-grokking, $500$3 post-grokking, $500$4 for synthetic gradients). Both leave-one-out and cross-topology validations demonstrate that this dimensional transition is robust to system size and graph topology—the effective dimensionality is determined by correlations in the gradient field, not by architectural microstructure.
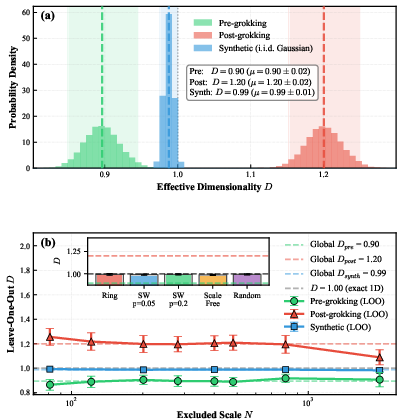
Figure 3: Bootstrap distributions of $500$5 for pre-grokking, post-grokking, and synthetic gradients show phase-specific non-overlapping regimes; leave-one-out and cross-topology analyses establish that $500$6 is topology-invariant for synthetic gradients.
This finding rigorously decouples the source of dimensional dynamics from network architecture, placing the focus squarely on gradient geometry as the central regulating factor of criticality and, by extension, trainability.
Implications and Theoretical Significance
By locating the grokking event as a dimensional phase transition in gradient-space, the work strongly connects abrupt generalization to universal mechanisms of critical phenomena in complex systems. The identification of $500$7 as an order parameter for this transition creates a diagnostic candidate for study in broader architectures/tasks. The work suggests that SOC—previously observed in low-level neural activity—also governs macroscopic deep learning phenomena such as generalization transitions.
Importantly, the fact that $500$8 is geometry-driven and not architecture-dependent has major ramifications: optimizer design and preprocessing may exert more direct control over trainability than changes in network topology. This reframes several open questions in deep learning generalization theory and points toward new lines of inquiry in both theory and practice.
Future directions include extending dynamic measurements of $500$9 to large-scale settings, diverse tasks, and architecture families, testing for universal transitions or problem-adaptive critical behavior. A rigorous classification of universality classes for gradient dynamics in deep learning remains open.
Conclusion
The paper systematically establishes that grokking in neural networks is a dimensional phase transition in the gradient field, best interpreted through the lens of self-organized criticality. The effective dimensionality N=810 serves as a precise, architecture-agnostic order parameter, revealing a continuous sub-diffusive to super-diffusive transition synchronizing with abrupt generalization. These insights both clarify the mechanistic underpinnings of grokking and lay groundwork for geometric controls on trainability. Universal patterns in gradient geometry, rather than architectural specifics, may ultimately govern generalization in overparameterized systems.