- The paper establishes that proper weight decay is crucial to transition from memorization to generalization in neural networks.
- It demonstrates that architectural depth and activation functions affect grokking delays primarily by influencing optimization stability.
- The study reveals that both MLPs and Transformers converge to a universal weight norm threshold during successful grokking.
A Systematic Empirical Study of Grokking: Depth, Architecture, Activation, and Regularization
Introduction
This work presents a rigorous empirical investigation of grokking—the delayed transition from memorization to generalization in neural networks—on modular arithmetic tasks. Previous studies have predominantly attributed grokking behaviors to architectural inductive biases or have confounded architectural effects with those arising from optimizer choices and regularization settings. This paper conducts a comprehensive dissection of depth, model architecture (MLP vs. Transformer), activation functions, and regularization, employing matched and systematically-tuned training protocols. The findings challenge prevailing narratives and establish the primacy of optimization stability and regularization in governing grokking dynamics.
Experimental Methodology
The primary testbed is modular addition modulo 97 (f(a,b)=(a+b)mod97) with a fixed 20%/80% train/test split, enforcing a regime in which the memorization-to-generalization transition is probeable. Model variants include vanilla and residual MLPs with variable depth, as well as single-layer Transformers, with GELU, ReLU, and Tanh activations. Training employs full-batch SGD (MLPs) or AdamW (Transformers), with explicit weight decay and extensive hyperparameter sweeps for regularization. Grokking delay (ΔT) is defined as the steps between attainment of 99% training and test accuracy.
Canonical Grokking and Depth Dependence
Baseline reproduction of grokking using a 2-layer GELU MLP demonstrates the classical memorization plateau, followed by an abrupt test accuracy transition after thousands of batch updates (Figure 1).
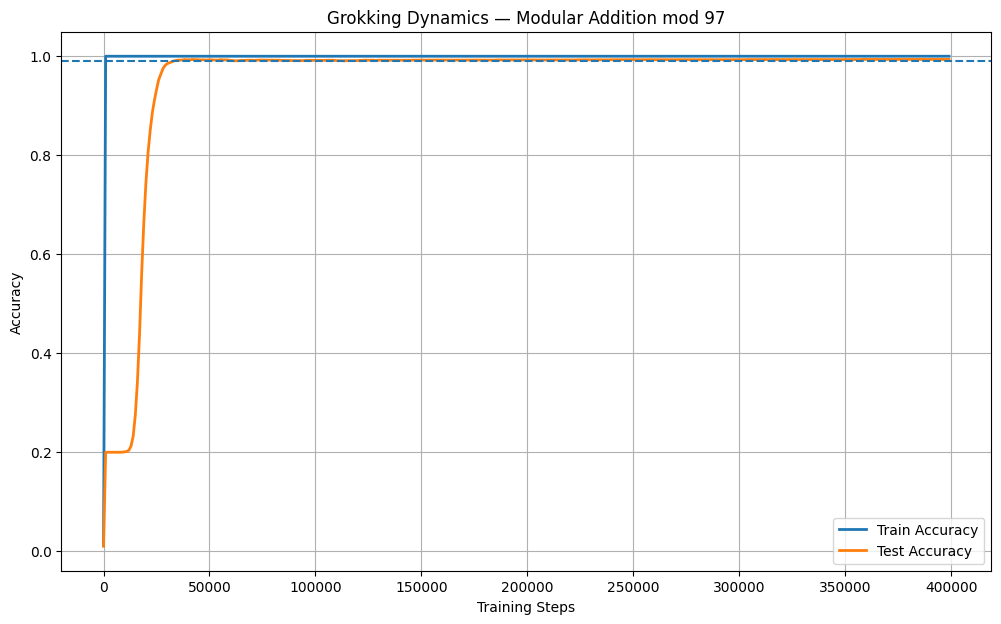
Figure 1: Canonical grokking on modular addition mod~97, displaying protracted stagnation in test accuracy followed by a sharp leap once the generalizing solution is found.
Investigating the effect of depth reveals a non-monotonic relationship. Flat depth-4 MLPs fail to grok at all under the allocated training budget. In contrast, depth-8 residual MLPs (equipped with LayerNorm and skip connections) rekindle grokking, albeit with stochastic failures in some seeds (Figure 2). This underscores that architectural stabilization—not raw depth—is essential for enabling the transition to generalization at greater depths.
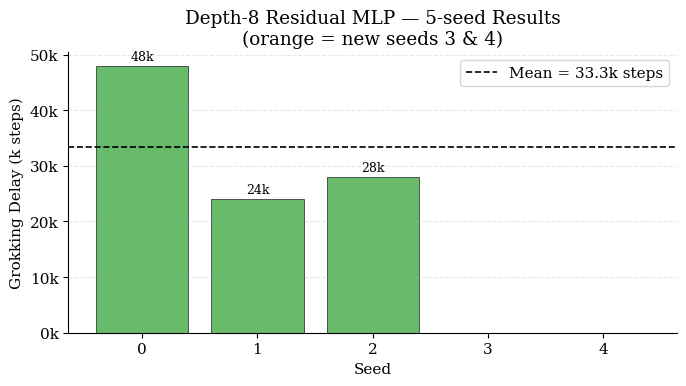
Figure 2: Grokking delay for depth-8 residual MLPs; absence of grokking in some seeds reflects heightened optimization sensitivity with increased depth.
Architecture and Activation Function Analysis
Carefully matched training regimes for MLPs and Transformers reveal that architecture contributes only modestly to grokking delay. Under individually optimized weight decay (MLP: λ=10−3; Transformer: λ=5.0), MLPs grok 1.90× faster on modular addition and 1.42× faster on multiplication. The previously reported larger gaps are largely attributable to hyperparameter mismatches rather than inherent architectural limitations (Figure 3).
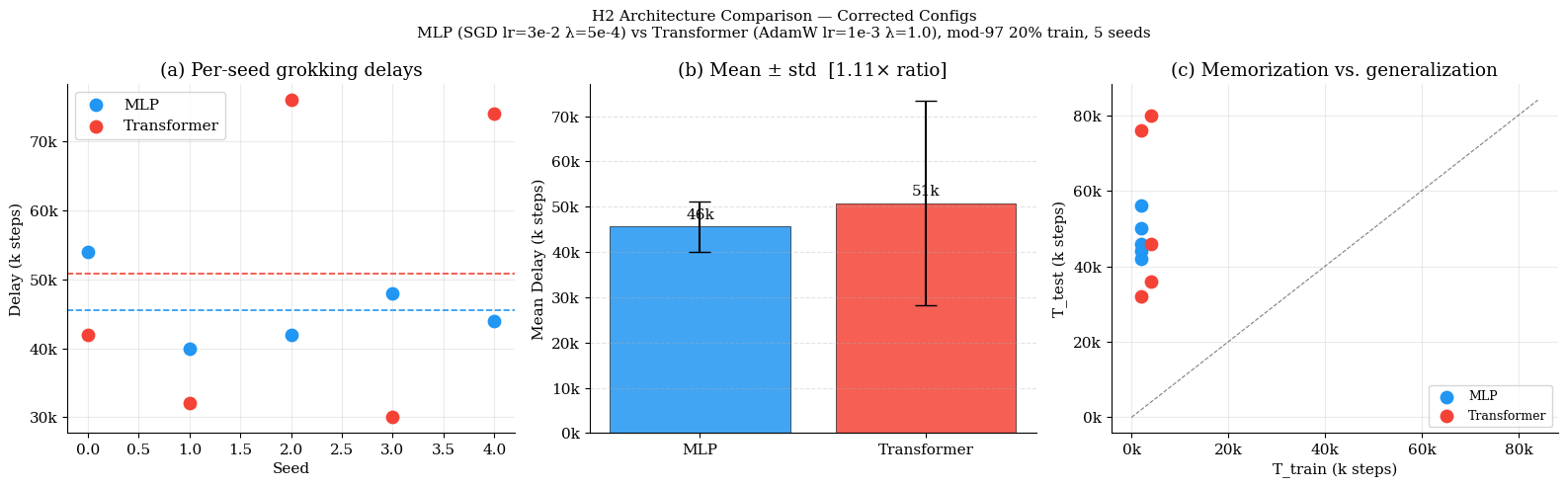
Figure 3: Transformer vs. MLP comparison; controlling for optimization and regularization drastically reduces the perceived architectural gap in grokking delay.
Activation functions exhibit a regime-sensitive impact: where weight decay is permissive of memorization, GELU produces a 3.8×–4.3× acceleration in grokking relative to ReLU; conversely, aggressive weight decay regimes can abrogate GELU's advantage or even preclude grokking entirely (Figure 4).
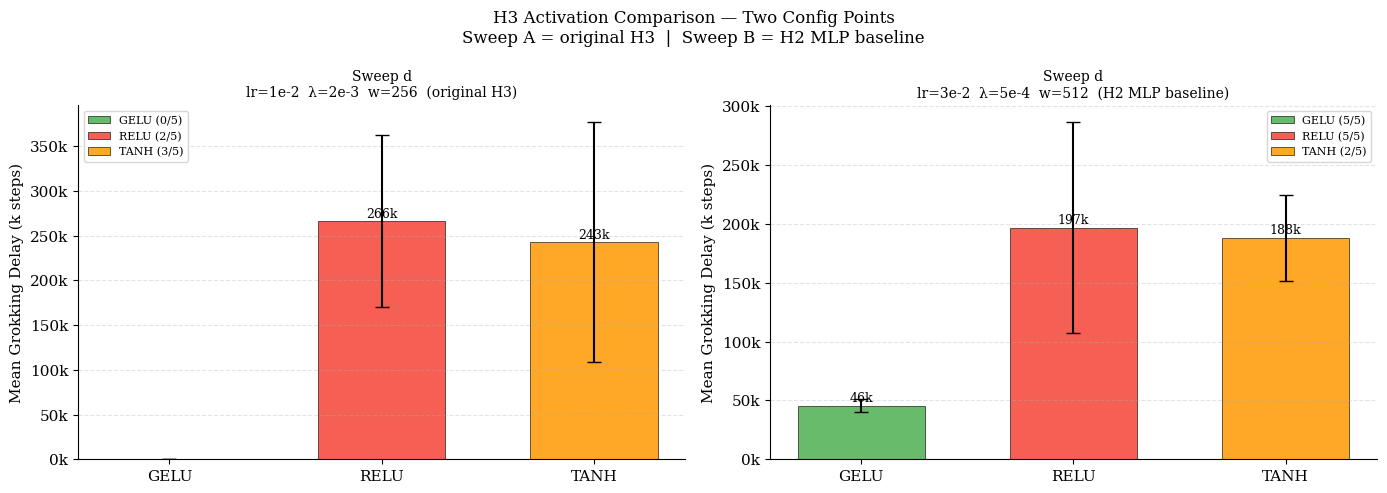
Figure 4: Activation effects are strictly dependent on regularization. GELU's characteristic advantage only emerges under light regularization permitting memorization.
Weight Decay as the Dominant Control Parameter
Weight decay exerts categorical control over grokking. For both architectures, there exists a narrow "Goldilocks" zone of regularization: too little (or too aggressive) weight decay leads either to indefinite memorization or catastrophic training failure, sometimes with small changes in λ (Figure 5). Notably, AdamW-based Transformers require orders of magnitude higher optimal λ compared to SGD-based MLPs, consistent with optimizer-specific norm dynamics.
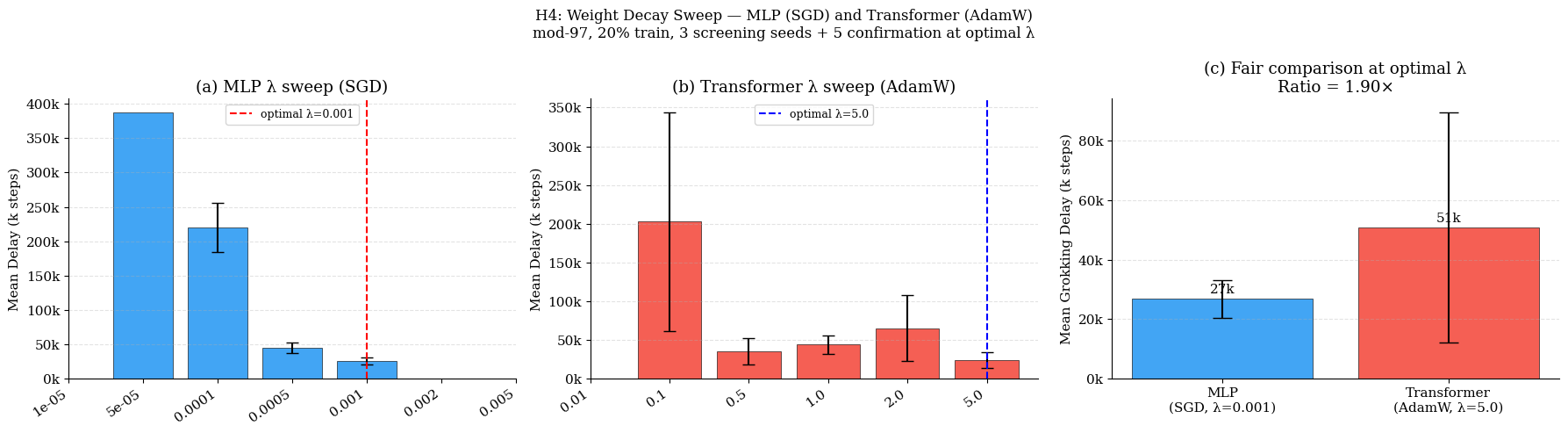
Figure 5: Sharply non-monotonic relationship between weight decay and grokking. Only a limited window supports both memorization and the delayed generalization transition.
Weight Norm Trajectories and Mechanistic Insights
All studied configurations (activations, architectures, optimizers) exhibit convergence to a common RMS weight norm threshold at the grokking step (ΔT0 for width 512), independent of rate of convergence. Activation functions modulate the rate at which this threshold is attained (with GELU accelerating the process), but the threshold itself is configuration-invariant (Figure 6).
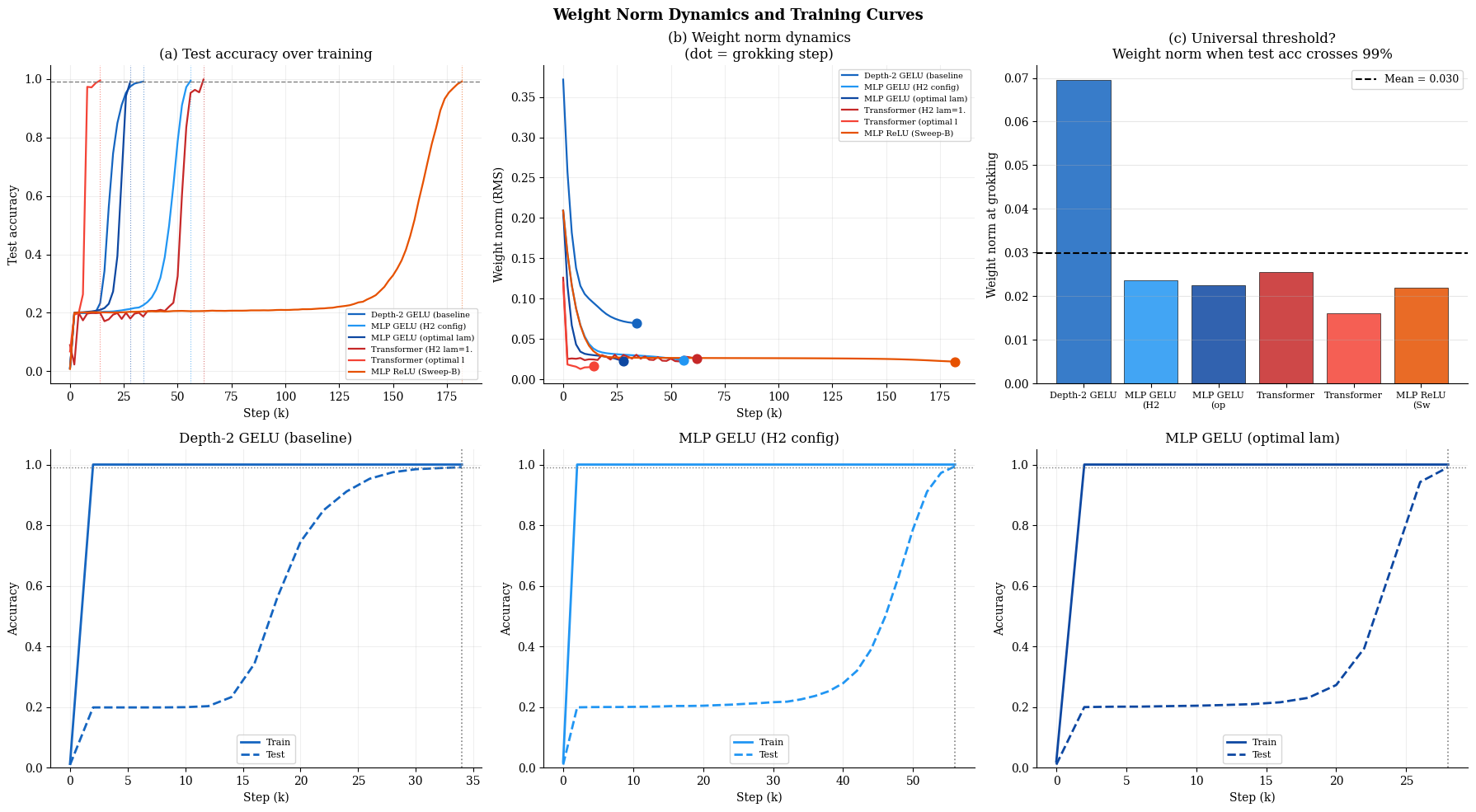
Figure 6: Across models and activations, grokking consistently coincides with convergence to a fixed weight norm threshold rather than any particular architecture-dependent solution.
Structured Solutions in Embedding Space
Post-grokking, both MLPs and Transformers encode modular arithmetic via highly sparse Fourier representations in their input embeddings, confirming a mechanistic connection to prior mechanistic interpretability results. Transformers achieve higher frequency concentration (98.5% in top-5 frequencies) than MLPs (~75%), but both model classes ultimately discover comparable algorithmic representations, and activation choice has negligible effect on solution sparsity (Figure 7).
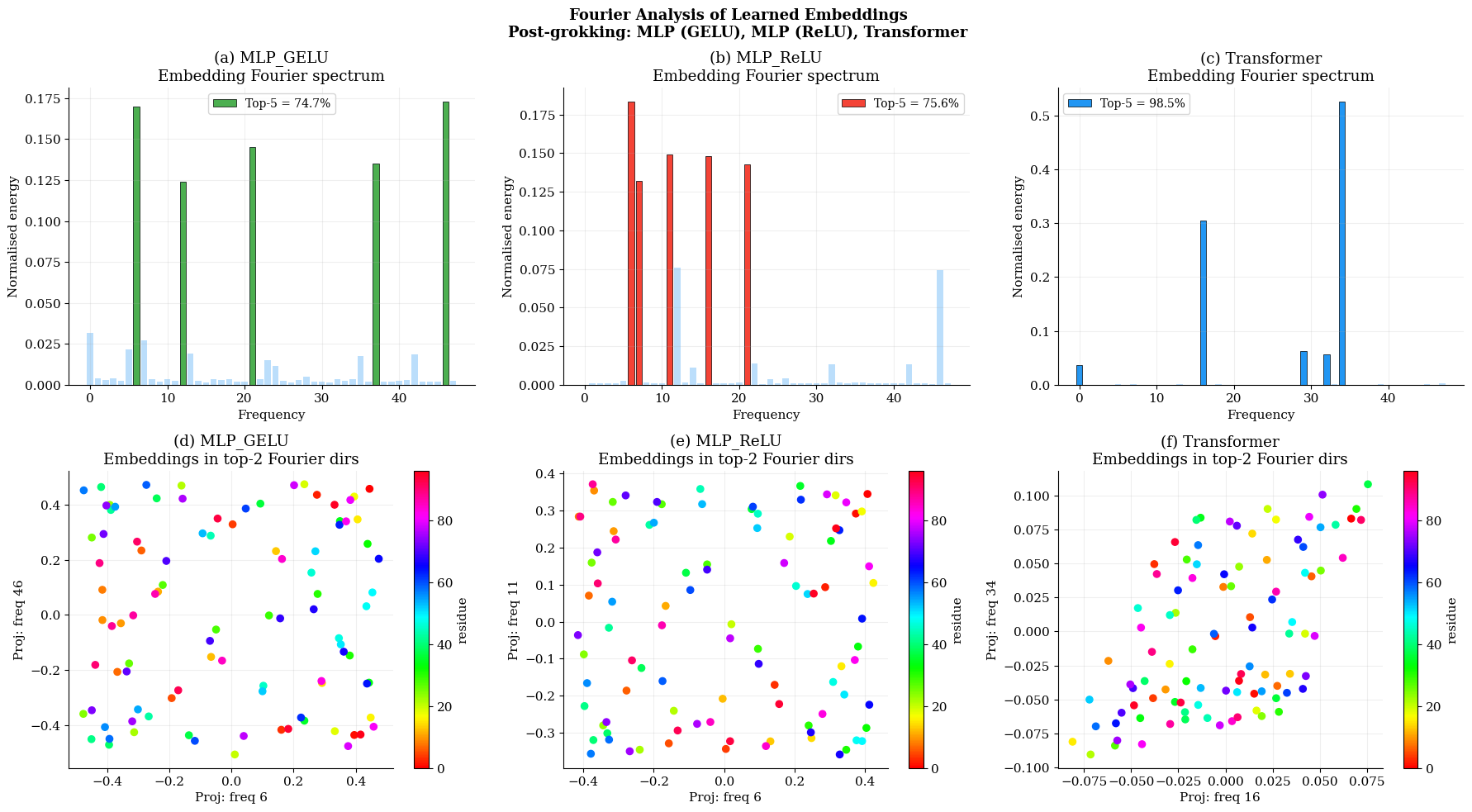
Figure 7: All models ultimately encode modular structure through a compact Fourier basis; degree of spectral concentration is highest for Transformers.
Task Generalization: Modular Multiplication
Replication of architecture and activation findings on modular multiplication demonstrates that the core observations persist across related algorithmic tasks (Figure 8). Both MLP advantage and GELU acceleration are replicated, with both models grokking faster on multiplication than addition.
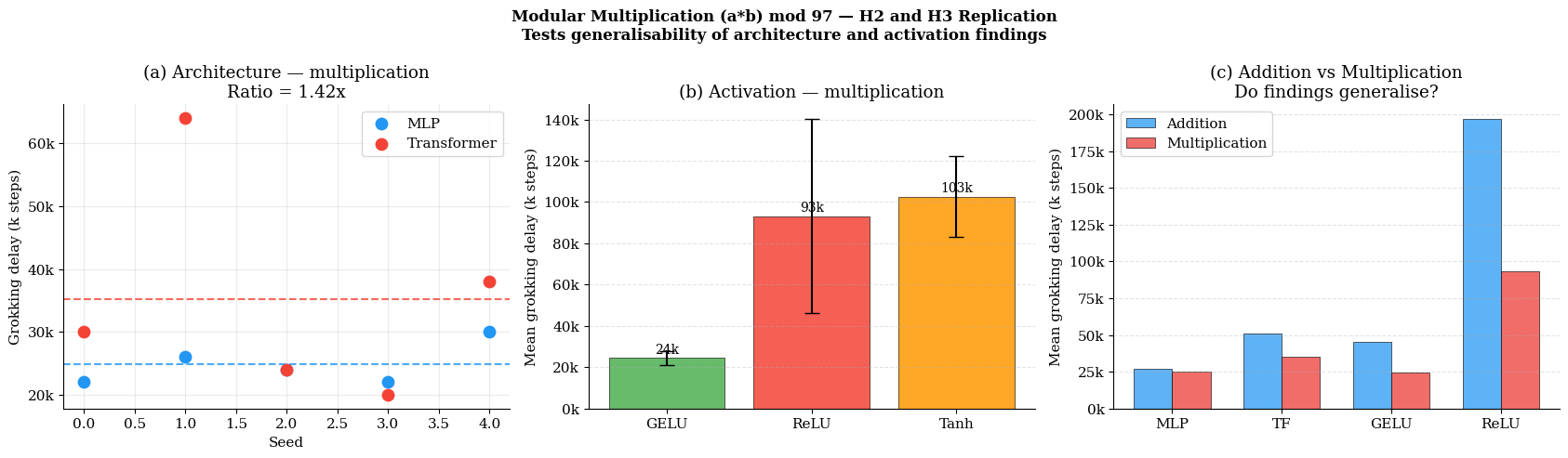
Figure 8: Architecture and activation effects generalize to modular multiplication; both model types grok faster relative to addition.
Implications and Theoretical Impact
These results provide strong evidence that the phenomenology of grokking is not fundamentally architecture-dependent but rather emerges from the interaction of optimizer dynamics and regularization. Architectural variations (depth, residual connections, attention) matter primarily in their effect on stability and the accessible weight norm trajectory. The existence of a consistent critical weight norm threshold for generalization highlights the primacy of norm-based implicit bias in learning dynamics, consistent with theoretical accounts linking generalization to loss landscape structure and gradient flow.
For practice, this suggests that to induce or accelerate grokking (and by extension, algorithmic generalization in neural networks), tuning weight decay and ensuring architectural stability should take precedence over architectural innovation. For theory, the results point to the necessity of frameworks that explicitly account for the optimizer–regularization–architecture triad, rather than focusing on architecture in isolation.
Future Directions
Several promising directions emerge:
- Extending these systematic studies to more complex and realistic datasets (beyond modular arithmetic) to probe the universality of the observed regularization-optimality regime.
- Deeper mechanistic interpretability of the weight norm threshold and its link to loss landscape topology or margin-based generalization.
- Detailed analysis of the slingshot dynamics and the higher seed variance observed in Transformers, elucidating the interplay between self-attention and implicit regularization mechanisms.
- Further probing the non-monotonicity in depth dependence and the systematics of optimization-induced barriers to generalization in larger/deeper models.
Conclusion
This systematic empirical study demonstrates that the onset and timing of grokking in neural networks are dominated by regularization and optimization stability, not architectural idiosyncrasies. Critical insights include the existence of a universal weight norm threshold for generalization, a sharply regularization-dependent regime for successful grokking, and the conditional nature of activation function advantages. These findings recalibrate the interpretation of prior architecture-centric conclusions, reinforce the mechanistic link between weight norms and generalization, and offer practical guidance for inducing and investigating grokking in algorithmic and potentially broader learning settings.