- The paper introduces a decoupled three-stage framework that independently handles de-occlusion, object generation, and pose estimation for open-set 3D scenes.
- The method leverages extensive, task-specific datasets and specialized attention mechanisms to overcome occlusion challenges and enhance generalization.
- Experimental results demonstrate significant gains in Chamfer Distance, F-Score, and robustness across indoor and open-set benchmarks.
SceneMaker: Open-set 3D Scene Generation with Decoupled De-occlusion and Pose Estimation
Introduction
Single-image open-set 3D scene generation requires synthesis of arbitrary 3D scenes from unconstrained images, encompassing diverse object geometries, occlusion patterns, and pose arrangements. Existing approaches are fundamentally limited by insufficient open-set priors, particularly for de-occlusion and pose estimation, resulting in failure modes under severe occlusion, with poor generalization outside of constrained domains (e.g., indoor datasets). "SceneMaker: Open-set 3D Scene Generation with Decoupled De-occlusion and Pose Estimation Model" (2512.10957) addresses these limitations by introducing a decoupled three-stage framework: robust de-occlusion, open-set 3D object generation, and unified pose estimation, trained independently on large-scale image, object, and newly synthesized scene datasets. The approach leverages task-specific, extensive open-set priors, preventing failure modes of earlier monolithic solutions and supporting text-controllable de-occlusion.
Problem Analysis and Motivation
The central insight of SceneMaker is that 3D scene generation depends on three distinct open-set priors: de-occlusion, geometry, and pose estimation. The availability of these priors varies significantly depending on training data source, as illustrated in the comparative analysis of prior source coverage.
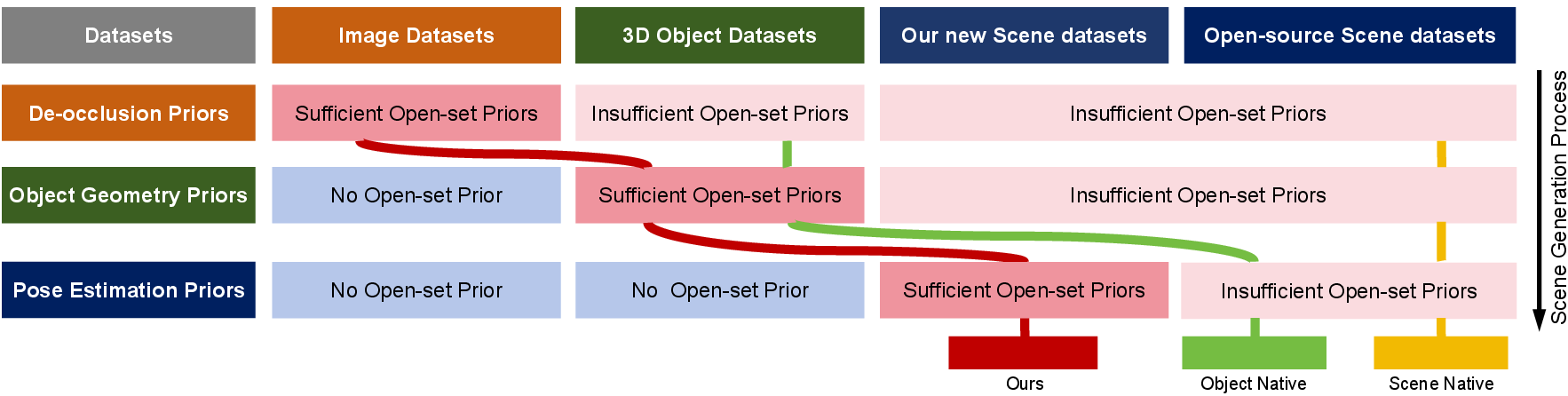
Figure 1: SceneMaker leverages the complementary strengths of image, object, and scene datasets to maximize open-set priors relevant for each subtask, compared to the constrained prior coverage in preceding methods.
Most prior scene-native methods are trained solely on full scene datasets, which only provide limited open-set priors, particularly for occlusion configurations and out-of-domain objects. Object-native approaches leverage larger object collections for geometry, but are still bottlenecked by occlusion and pose priors. SceneMaker resolves this by strict modularization and dataset expansion, compelling each module to specialize and generalize.
SceneMaker Framework
The pipeline receives a single scene image and proceeds through the following modules: (1) segmentation and depth estimation for object/information extraction; (2) de-occlusion of masked object crops; (3) high-fidelity open-set 3D object synthesis; (4) unified pose estimation leveraging global and local attention mechanisms.
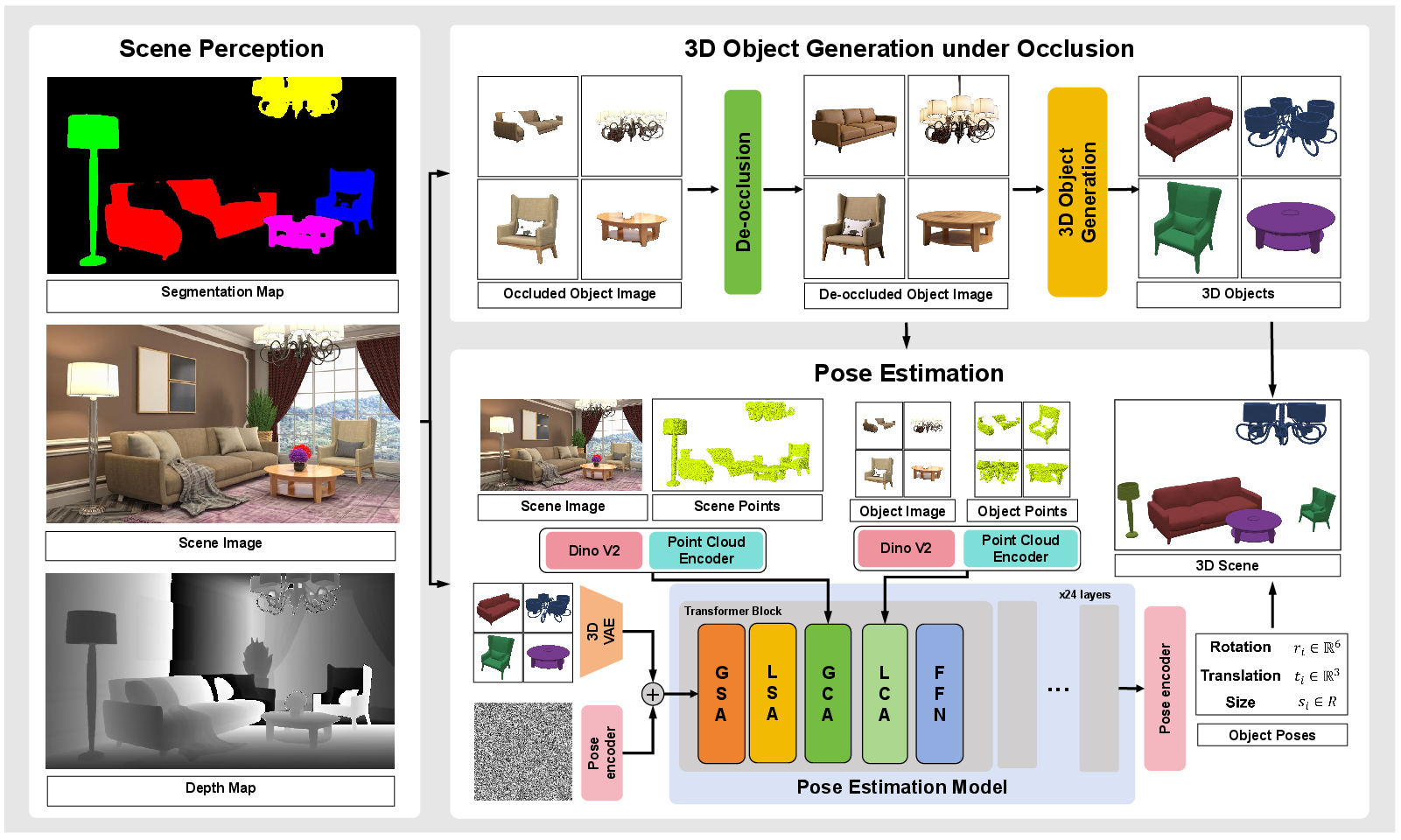
Figure 2: SceneMaker’s architecture, with decoupled de-occlusion (trained on constructed image datasets), robust geometry generation, and a unified pose estimation diffusion model with specialized attention modules for improved accuracy and consistency.
This modularization ensures that each learning stage is insulated from cross-task domain gaps and data-confounding, which previously caused geometry collapse or incoherent pose estimation, especially for small or occluded objects.
De-occlusion Modeling
The de-occlusion model is initialized from large-scale image editing architectures (Flux Kontext) and fine-tuned on a newly constructed 10K open-set de-occlusion dataset, generated with multi-pattern occlusions (object cutouts, right-angle crops, random brush-stroke masks), capturing a much broader diversity of occlusion than previous 3D-based datasets.
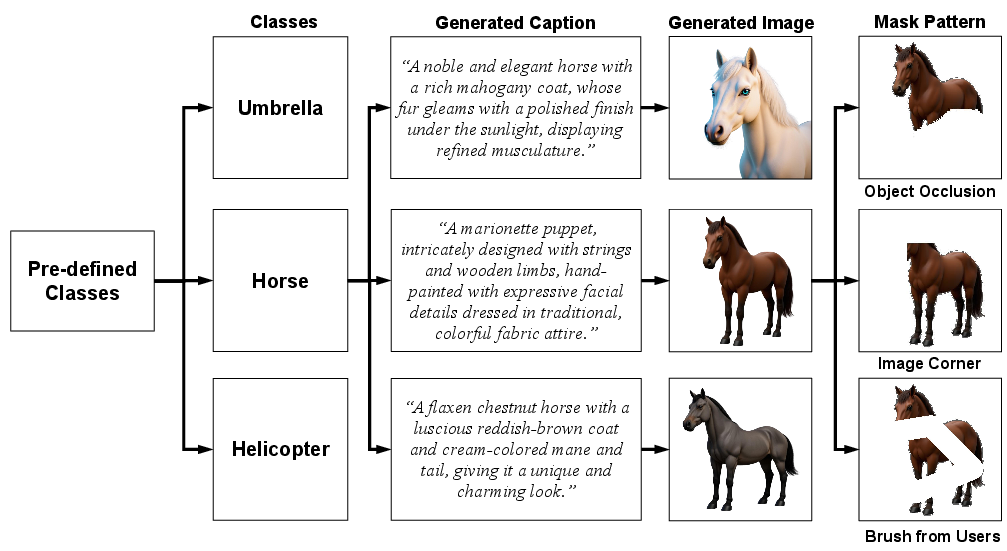
Figure 3: The curation pipeline for the de-occlusion dataset, supporting high-diversity occlusion pattern coverage.

Figure 4: Representative occlusion patterns synthesized for robust de-occlusion learning.
Quantitative and qualitative evaluations demonstrate strong gains over prior inpainting and editing models, particularly on severe occlusion and open-set scenarios. PSNR and SSIM metrics are consistently improved.

Figure 5: Qualitative superiority of SceneMaker’s de-occlusion model on both open-set and indoor objects under challenging occlusions.
3D Object Generation under Occlusion
Decoupling de-occlusion enables the use of state-of-the-art open-set object generation backbones (e.g., Step1X-3D, Hunyuan3D) for shape synthesis, unconfounded by occlusion pattern scarcity. SceneMaker outperforms MIDI and Amodal3R by a notable margin in Chamfer Distance and F-Score, reflecting higher-quality geometry under realistic scene occlusions.

Figure 6: SceneMaker reconstructs more complete and faithful 3D object geometries under both open-set and indoor occlusions.
Unified Pose Estimation: Diffusion with Attention
SceneMaker introduces a unified diffusion-based pose estimator, which predicts rotation, translation, and size for all objects simultaneously. Unlike prior approaches that treat each variable independently or lack scene-level constraints, this model uses both global self-attention (across objects) and local cross-attention (token-wise conditioning), along with decoupled conditioning: rotation attends to features in canonical object space, whereas translation and size tokens use the global scene context.

Figure 7: Specialized attention mechanisms: global self-attention models object-to-object relationships, local cross-attention allows variable-specific conditioning, maximizing pose accuracy and scene coherence.
The pose estimator’s performance and generalization are further improved via a massive synthetic open-set scene dataset (200k scenes, 8M images), curated from filtered Objaverse models with strict quality and diversity criteria.

Figure 8: Example samples from the curated open-set scene dataset, used for high-fidelity pose estimation pretraining.
Experimental Results
SceneMaker establishes SOTA results on both indoor and open-set benchmarks, yielding lower Chamfer Distances and higher F-Scores at both scene and object level, with robust improvement on highly occluded scenes. The system also performs strongly on real-world and in-the-wild image benchmarks, demonstrating generalization across domains.
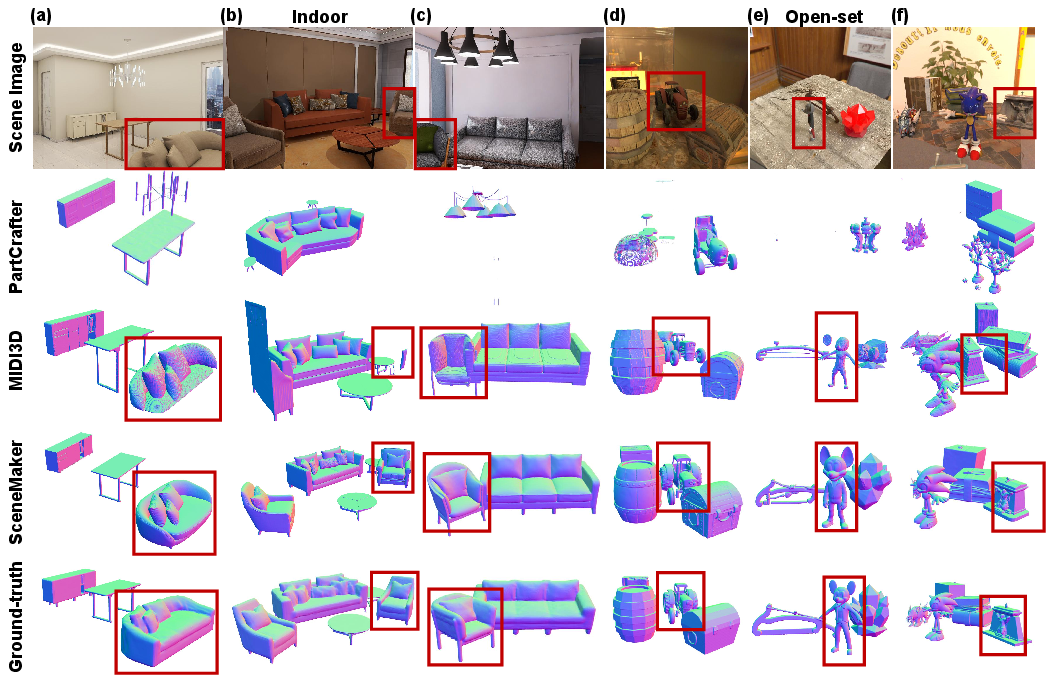
Figure 9: Comparative qualitative scene synthesis on challenging real and synthetic inputs: SceneMaker produces highly plausible, richly detailed, and geometrically accurate scenes under severe occlusion.
Ablation studies verify the critical contribution of decoupled attention mechanisms, particularly the local cross-attention used for rotation, and show that performance scales well with increasing scene object count owing to architectural choices such as RoPE embeddings.
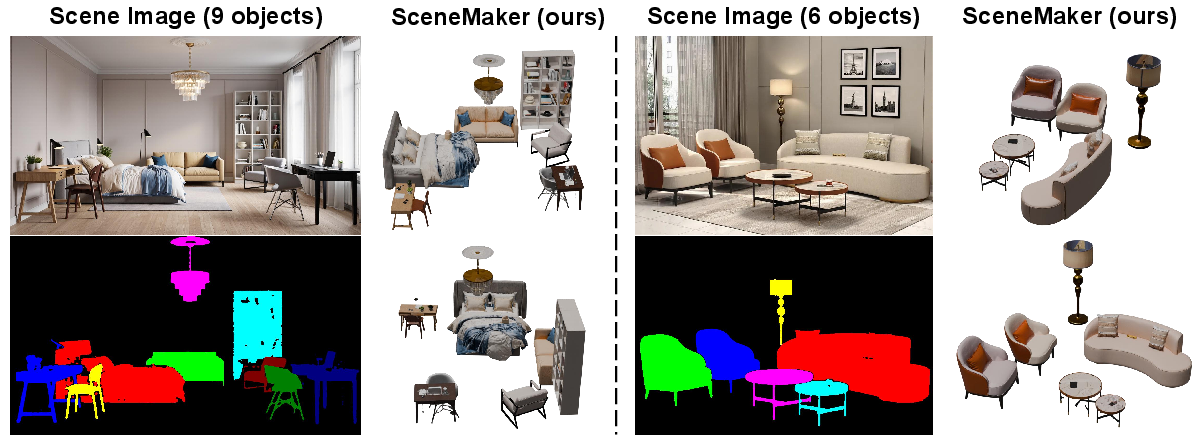
Figure 10: SceneMaker’s ability to handle increasing object counts without geometric or pose degradation.
The de-occlusion model is also text-controllable, enabling specification of object attributes in occluded regions via prompt engineering—a feature unattainable in prior integrated pipelines.

Figure 11: Text-controllable de-occlusion allows precise manipulation of object attributes even under mask.
Additional experiments on both indoor and open-set scenes (Figures 12–13) further highlight generalization and fidelity advantages compared to MIDI and other open-set baselines.
Theoretical and Practical Implications
By decoupling the representation and learning of de-occlusion, geometry, and pose, and by maximizing priors through targeted dataset curation, SceneMaker overcomes foundational bottlenecks in open-set 3D generation. This enables not only high-fidelity asset creation for AIGC and simulation but also advances embodied AI, where robust spatial reasoning and object-centric understanding are essential. The modular architecture allows for scalable integration of future advances in each submodule (e.g., text-to-3D, video-based perception).
The text-controllable de-occlusion module denotes a significant advance towards fine-grained and interactive 3D content control, potentially informing future work in text-driven scene reasoning.
Remaining limitations include the simplified treatment of force interaction and physical plausibility, as the constructed synthetic scenes avoid intersection and leverage random arrangements. True physical scene understanding and manipulation—incorporating contact dynamics and compliance—remain open problems. Further work will also be needed to extend scene generation controllability beyond coarse image/caption prompts to more nuanced and compositional inputs.
Conclusion
SceneMaker (2512.10957) presents a rigorously modular framework for open-set 3D scene generation, achieving substantial advances in robustness, generalization, and controllability. Decoupling de-occlusion, geometry, and pose, and deploying specialized architectures and dataset curation for each, enables significant gains on occluded and open-set input scenarios. The paradigm set by SceneMaker offers a clear blueprint for future research in scalable 3D scene synthesis, scene-mediated embodied intelligence, and controllable AIGC systems.

