- The paper introduces the Agent-as-a-Judge paradigm by integrating tool use and live environment interaction for robust agent behavior evaluation.
- It constructs a benchmark across Search, DS, and GUI domains with 155 tasks and detailed trajectory annotations to ensure reproducibility and unbiased assessments.
- Experimental results reveal an average F1 score improvement from 0.59 to 0.72, underscoring the necessity of iterative evidence collection in agent evaluation.
Authoritative Analysis of "AJ-Bench: Benchmarking Agent-as-a-Judge for Environment-Aware Evaluation" (2604.18240)
Motivation and Framework
AJ-Bench addresses the fundamental challenge in RL and LLM agent development: robust verification of agent behaviors within complex, interactive environments. Traditional approaches utilize rule-based verification or LLM-as-a-Judge, systems that rely primarily on static textual cues and lack adaptability across open-ended contexts. The paper proposes the Agent-as-a-Judge paradigm, wherein verification agents interact with live environments and invoke external tools to actively gather evidence, thus enabling more principled and environment-aware evaluation.
The benchmark is instantiated across three domains—Search, Data Systems (DS), and Graphical User Interfaces (GUI)—covering 155 tasks and 516 annotated trajectories sampled from prominent agent benchmarks. AJ-Bench systematically interrogates agentic judge performance across information acquisition, state verification, and process verification, establishing a foundation for quantitative evaluation of agentic judgers.

Figure 1: Agent-as-a-Judge outperforms LLM-as-a-Judge by using tools and environment access to verify the correct release date.
Benchmark Methodology
AJ-Bench construction encompasses rigorous task curation, trajectory collection, and ground-truth annotation. Tasks are sourced and refined from Mind2Web2, WideSearch, MCPMark, and OSWorld to ensure reproducibility, interactivity, and sufficiency for agentic evaluation. Trajectories are both collected directly and regenerated by multiple LLMs, followed by thorough human and tool-based validation. Label annotation is domain-tailored: item-level in Search, trajectory-level in DS and GUI, using both automated scripts and manual passes to maximize label reliability.
The environment initialization protocol ensures that agents can interact with reconstructed states derived from executed trajectories, supporting reproducible and unbiased evaluation workflows.
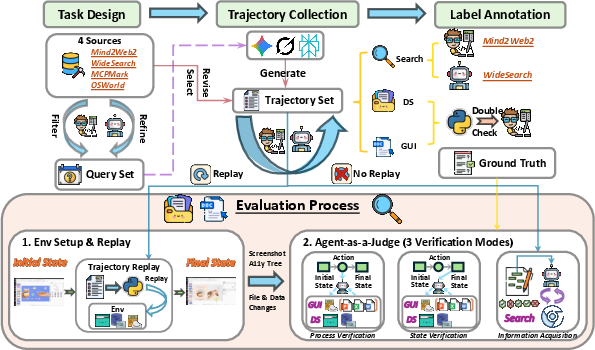
Figure 2: Overview of the benchmark and evaluation pipeline, showing both task construction and agentic evaluation.
A detailed analysis of domain distribution reveals balanced coverage across information-seeking, state manipulation, and multimodal GUI tasks.
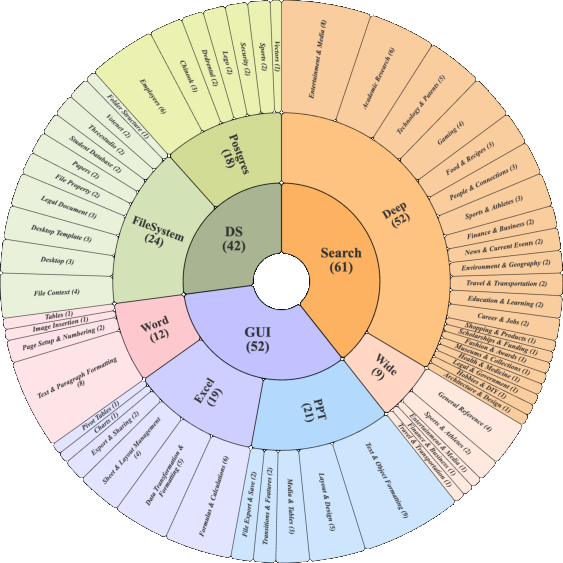
Figure 3: Task distribution across AJ-Bench domains.
Experimental Results
Extensive experiments compare LLM-as-a-Judge and Agent-as-a-Judge configurations across leading LLMs (Gemini, GPT-5, Grok, Claude, Kimi, Qwen, GLM, Longcat, DeepSeek). The core finding is that enabling agentic interaction consistently outperforms static judgment, offering an average improvement of 0.13 in F1 score and reaching a peak mean F1 of 0.77 in some settings.
A strong numerical result is the average F1 score of 0.72 for Agent-as-a-Judge implementations, compared to 0.59 for LLM-as-a-Judge baselines. Furthermore, even with relatively weaker base models, agentic judging surpasses the LLM-as-a-Judge performance of state-of-the-art closed-source LLMs, demonstrating the critical importance of environment access and tool integration.
Analysis of interaction turns shows a monotonic increase in evaluation accuracy with higher interaction budgets, underscoring the necessity of iterative evidence gathering in complex scenarios.
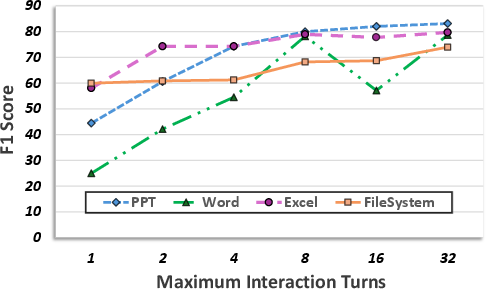
Figure 4: Performance improvement as agent is allowed more interaction turns during evaluation.
Multimodal ablation studies in GUI domain indicate that combining accessibility tree and screenshot inputs improves agent performance in some subdomains but can introduce noise and degrade accuracy in others. The optimal modality configuration is task-dependent, suggesting avenues for adaptive input selection strategies.
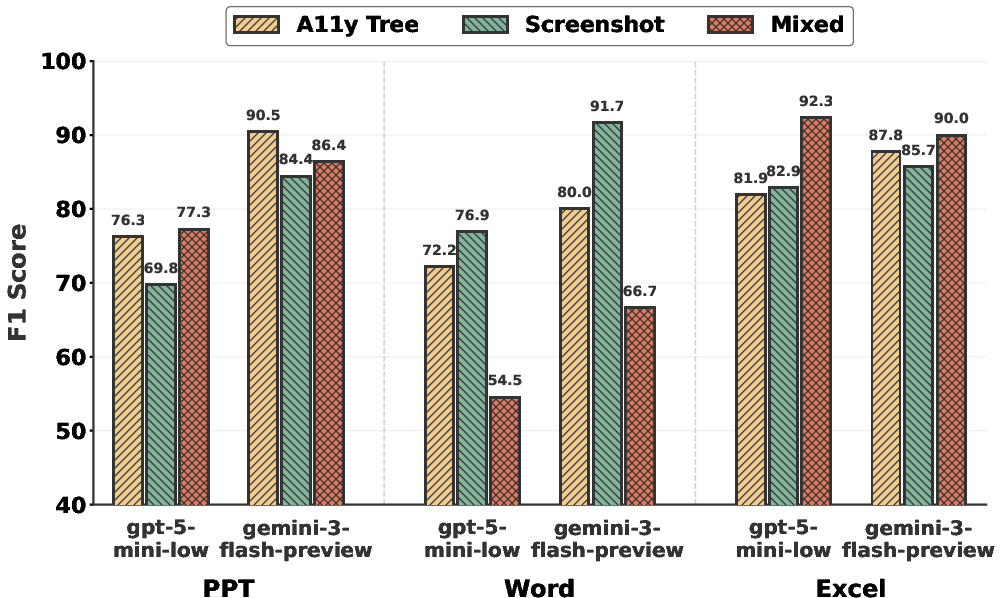
Figure 5: Effect of different input modalities on agentic judge performance for GUI tasks.
Ablation and Failure Analysis
Ablation studies demonstrate that increasing internal reasoning effort does not guarantee better agentic judge performance; tool invocation precision, output interpretation, and interaction frequency are more significant contributors. Failure mode taxonomy reveals four main categories: tool invocation omission, incorrect tool calls, misinterpretation of tool outputs, and incorrect reasoning despite correct evidence. Across domains and models, the predominant sources of error are misinterpretation and erroneous reasoning, reflecting both agentic limitations and the inherent complexity of environment-driven tasks.
Implications and Future Directions
AJ-Bench formally positions environment-aware, agentic evaluation as a necessary capability for advancing RL and LLM-based agent development. Practically, the benchmark provides a scalable pipeline for training and validating agentic judges, offering insights into systematic weaknesses in current verification methods and informing the design of more robust evaluator architectures.
Theoretically, the results challenge the assumption that improved LLM capacity alone suffices for reliable evaluation; instead, tool use and interaction with real environments are indispensable for verifying multi-step and non-trivial agent trajectories. The persistent headroom (absolute F1 remains below 0.8) highlights unresolved open challenges—such as adaptive tool sequencing, scalable evidence synthesis, and hybrid human-agent oversight—that warrant further exploration.
Future developments will likely focus on automatic task generation, scaling live environment infrastructure, extension to novel domains (e.g., scientific hypothesis testing, code execution environments), and integration of agentic judges within RL reward modeling pipelines.
Conclusion
AJ-Bench establishes a rigorous paradigm for environment-aware agentic evaluation, empirically validates the superiority of Agent-as-a-Judge over static LLM-based judges, and identifies practical and theoretical limitations in current approaches. The benchmark and findings inform the next generation of agent evaluation, emphasizing the indispensability of interaction capabilities and tool access in verifying complex behaviors. AJ-Bench is positioned to become a foundational resource for research on robust agentic evaluation and scalable RL retraining protocols.