- The paper presents a self-evolving training pipeline using a Calibrated Step Reward System that improves annotation accuracy (>90%) and reduces costs by 10–100×.
- It advances GUI automation with a dual-layer GUI-MCP protocol, enabling secure on-device execution and efficient task delegation across diverse operating systems.
- Experimental results on benchmarks like AndroidDaily and OSWorld confirm Step-GUI’s state-of-the-art performance in multi-step tasks and rapid capability improvements.
Step-GUI: Towards Efficient, Scalable, and Practical Multimodal GUI Agents
Introduction and Motivation
Modern LLMs, notably multimodal LLMs, have demonstrated notable improvements in processing natural language and visual information in tandem. However, enabling these models to perform robust GUI automation at scale encounters two primary bottlenecks: (i) acquisition of high-fidelity supervision at low cost, and (ii) deployment across heterogeneous device environments with stringent privacy constraints. The "Step-GUI Technical Report" (2512.15431) addresses these issues via a comprehensive approach: introducing a self-evolving training pipeline driven by a Calibrated Step Reward System (CSRS), deploying a family of compact, highly capable GUI specialist models (Step-GUI 4B/8B), architecting the first general Model Context Protocol (GUI-MCP) for secure and efficient device control, and proposing AndroidDaily, a benchmark that reflects real-world mobile usage.
Self-Evolving Training with Calibrated Step Reward System
Traditional GUI agent training relies heavily on costly manual step-level annotation and struggles with factuality and annotation drift, especially in the multi-step settings common in GUI automation. Step-GUI introduces CSRS, an LLM-powered pipeline that directly addresses these pain points by shifting the annotation paradigm from step-level supervision to trajectory-level calibration, leveraging both automated verifiers and human annotators for high-confidence binary success/failure signals. Not only does this achieve >90% annotation accuracy, but it also reduces the cost by 10–100× relative to prior annotation techniques.
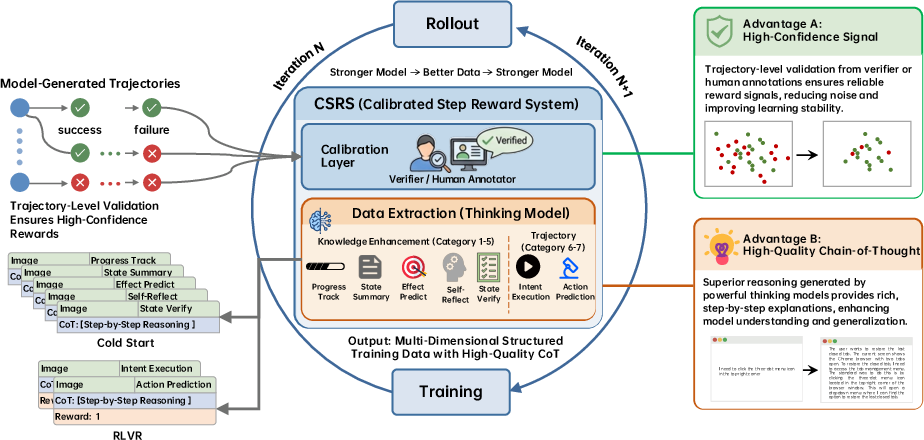
Figure 1: Architecture of CSRS showing the calibration layer, knowledge extraction, and the iterative data-improvement loop underpinning model training.
The architectural innovation of CSRS lies in its dual-path extraction: every successful trajectory produces a comprehensive suite of knowledge and action data, while failed trajectories are mined exclusively for knowledge to avoid propagating spurious action information. LLMs serve as data generators, yielding dense chain-of-thought rationales—far surpassing manual annotation in detail, coverage, and domain specificity.
This architecture synergizes with a closed-loop, self-evolving training pipeline, integrating three sequential stages (Mid-Train, Cold-Start, RLVR) and operating dual flows: one for generating new, verifier-anchored data from live rollouts, and another for strategic refinement and hard-case distillation from legacy data. This pipeline orchestrates continuous capability growth, evidenced by large, monotonic improvements in agent competence through several rounds of self-improvement.
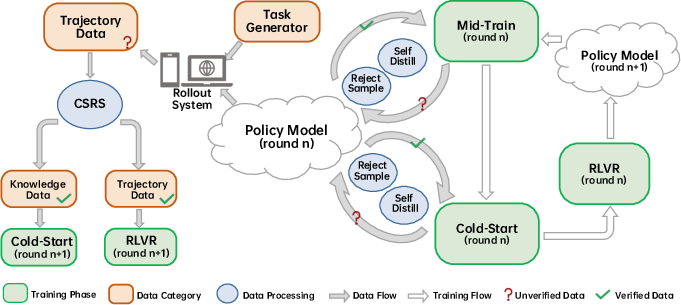
Figure 2: The progressive, closed-loop training framework that couples generation and refinement flows, continuously increasing both model and data quality.
GUI-MCP: Hierarchical, Privacy-Preserving Protocol for Deployment
Scaling GUI agents requires a robust, standardized interface for device interaction, spanning diverse OSes and supporting variable privacy guarantees. The GUI-MCP protocol, introduced here, adopts a hierarchical dual-layer design: a low-level MCP exposes atomic device operations (click, swipe, input, etc.), while a high-level MCP enables natural language-driven task delegation to local, specialist models (e.g., Step-GUI-4B).
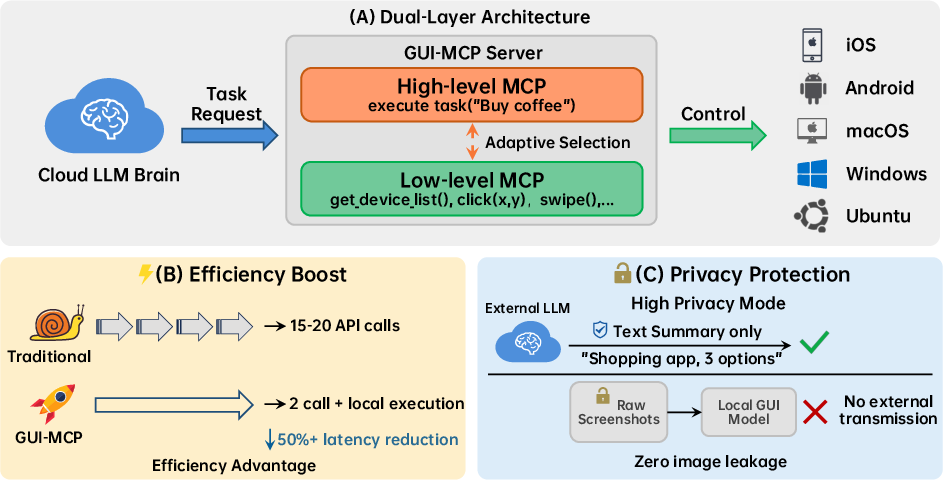
Figure 3: GUI-MCP architecture with dual-layer hierarchy, balancing fine-grained control and high-level delegation—enabling privacy-centric on-device computation.
This arrangement unlocks several practical advantages. Execution efficiency is maximized by routing simple tasks to on-device models for low latency, while offloading complex reasoning to centralized LLMs as necessary. Critically, the protocol supports a high-privacy mode in which raw screenshots are never transmitted off-device; instead, only semantic summaries are exported, thus strictly limiting user exposure and satisfying strong privacy requirements.
AndroidDaily: Closing the Evaluation-Usage Gap
Evaluating GUI agents on synthetic or narrow benchmarks does not establish practical readiness. AndroidDaily fills this gap as the first benchmark grounded in empirical mobile usage statistics, focusing primarily on five dominant daily-life scenarios. The benchmark’s static component features 3146 annotated actions across eight primary action types, and the end-to-end component covers 235 multi-step tasks across Transportation, Shopping, Social Media, Entertainment, and Local Services.
Figure 4: The action taxonomy underpinning AndroidDaily’s static benchmark, covering the full spectrum of practical Android interaction primitives.
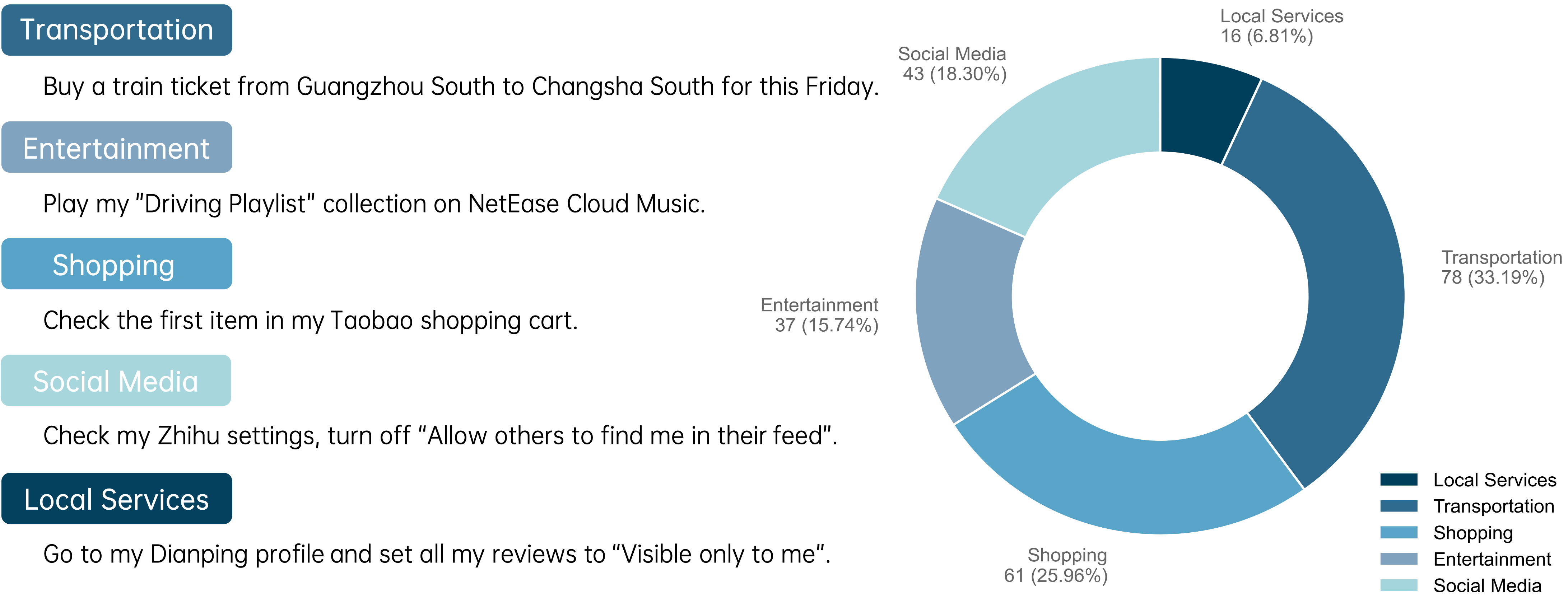
Figure 5: Scenario distribution and representative examples for AndroidDaily’s end-to-end benchmark—emphasizing real-world relevance and scenario diversity.
This design delivers not only a robust test for action execution accuracy but also for agent robustness in complex, ambiguous, multi-step workflows—areas where current agents often falter.
Step-GUI models set a new standard across both grounding and agentic benchmarks. On AndroidWorld, Step-GUI-8B achieves 80.2% (pass@3), significantly outperforming most existing open-source and proprietary baselines of comparable or even larger size. On OSWorld, it reaches 48.5% (pass@3), and on the static AndroidDaily benchmark, achieves 89.91% average accuracy, making it the clear leader. The 4B variant, despite its compactness, remains competitive and is uniquely deployable on consumer hardware without cloud dependency.
Step-GUI’s closed-loop self-refinement is validated by performance "phase transition" phenomena (rapid jumps in ability after critical self-discovery of high-reward trajectories) and by steady advances in challenging environments.
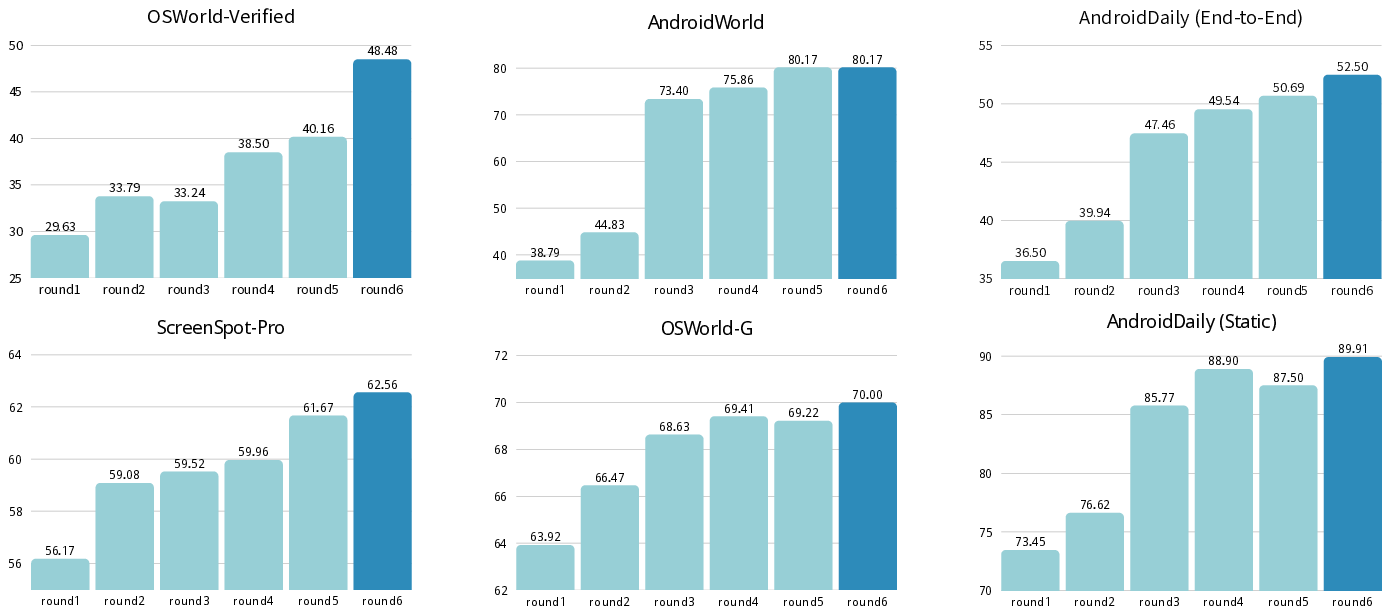
Figure 6: Evolution of Step-GUI-8B performance over six self-evolving training rounds—demonstrating compounding capability improvements.
Convergence analysis during RLVR highlights the crucial stability of the Step-GUI training process. All reward curves—including LLM-as-a-Judge and sub-tasks—rise smoothly without mode collapse, and off-policy diagnostics indicate strong trust-region adherence.
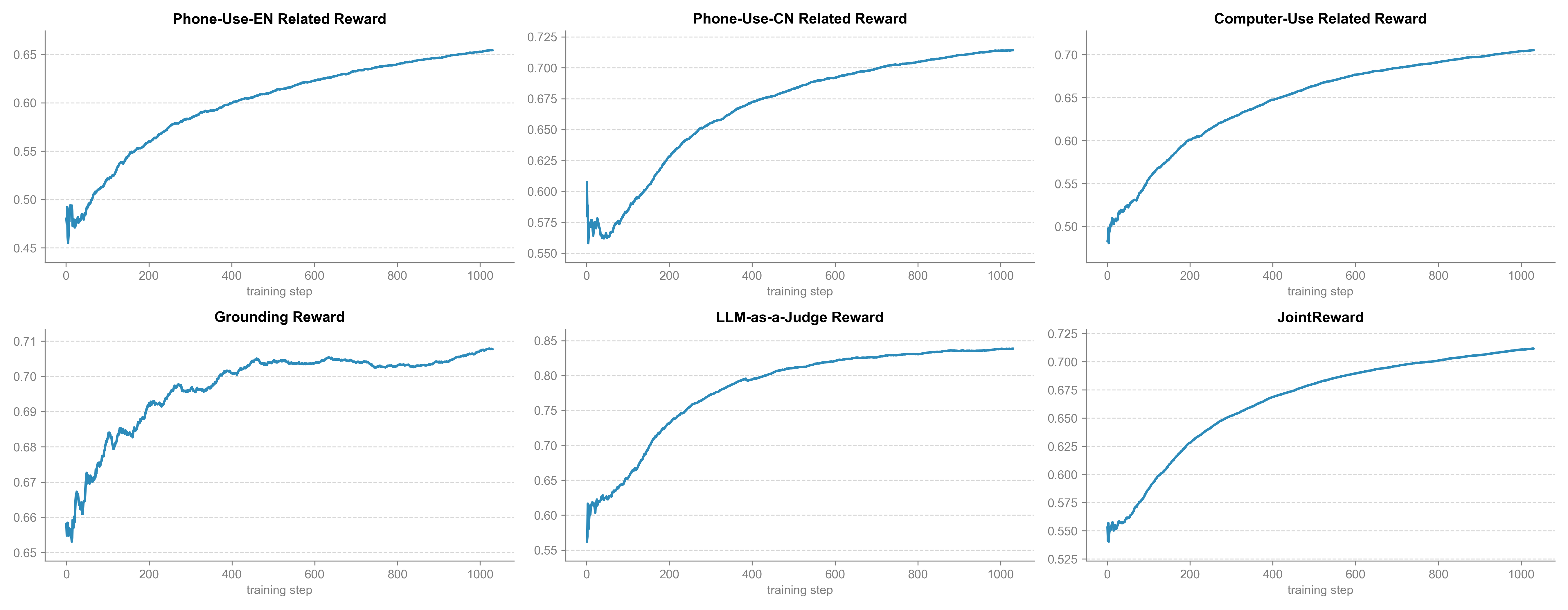
Figure 7: Reward dynamics during RLVR—highlighting monotonic, stable improvement and tight correlation to human metrics.
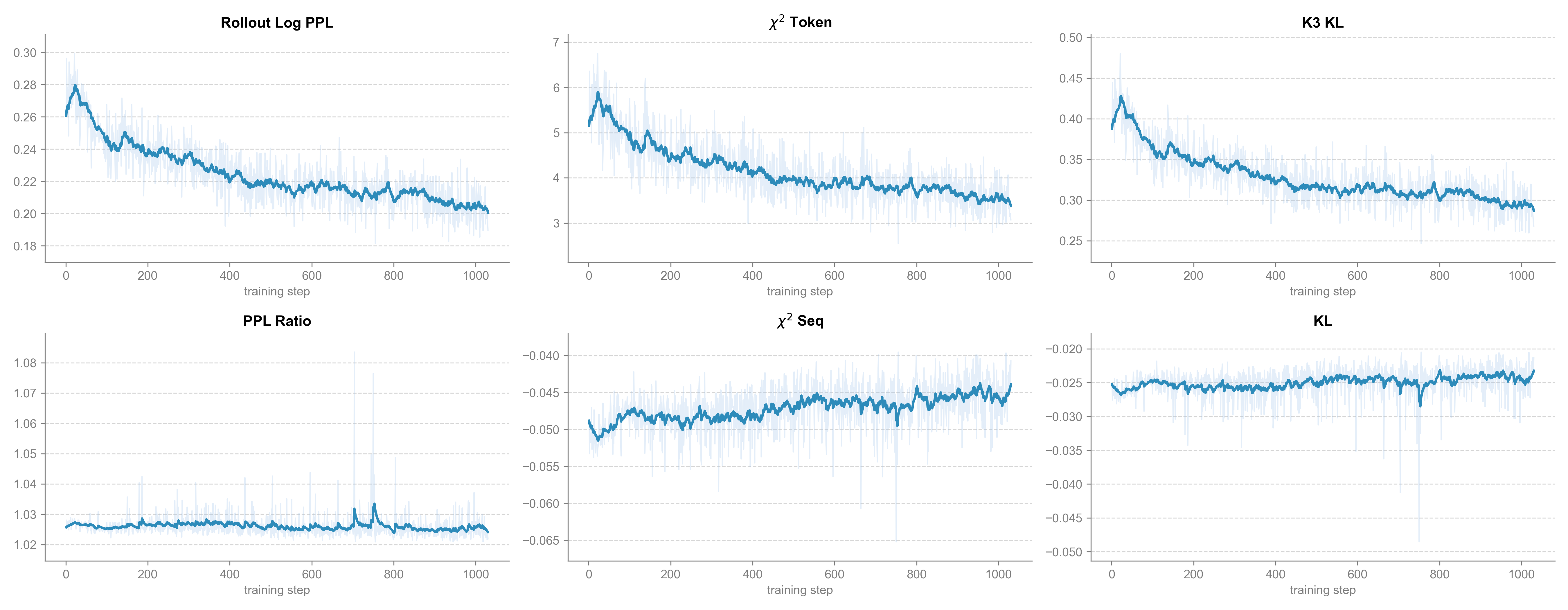
Figure 8: Off-policy correction metrics, showing low divergence and variance, supporting stable and aligned policy updates.
Policy entropy trajectories further reveal that the semi-online feedback and gradient preservation strategies in RLVR are instrumental in preventing premature convergence and maintaining mode diversity—essential for robust agentic behavior.
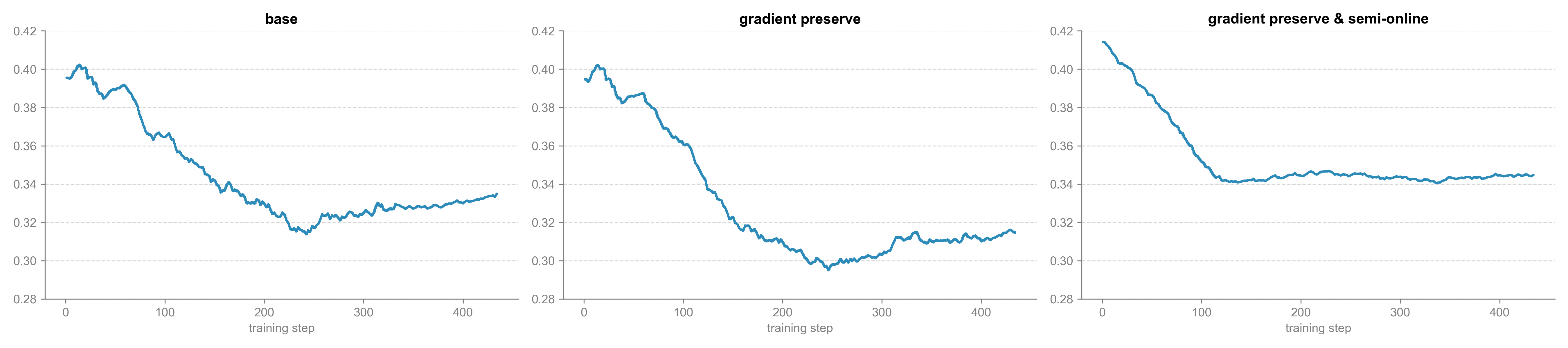
Figure 9: Policy entropy under different RLVR strategies—showing that semi-online training sustains exploration and mitigates collapse.
The strong performance of Step-GUI on mainstream multimodal benchmarks (e.g., MMStar, MathVista, OCRBench) also establishes that agentic specialization does not come at the cost of eroding general-purpose capability—a common trade-off for domain-specialized models.
Real-World Capabilities: OSWorld and Mobile Trajectories
Step-GUI’s practical impact is showcased via successful, multi-step task executions in live OS environments.
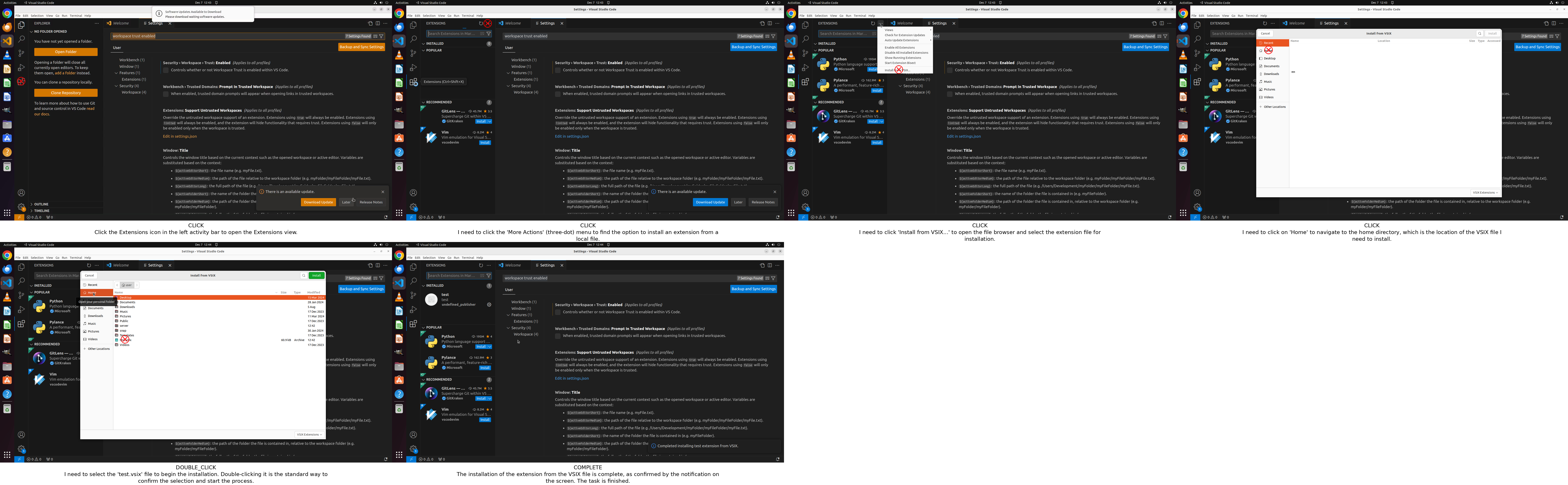
Figure 10: Example OSWorld trajectory—automated VS Code extension installation.

Figure 11: OSWorld: Automated tab restoration.
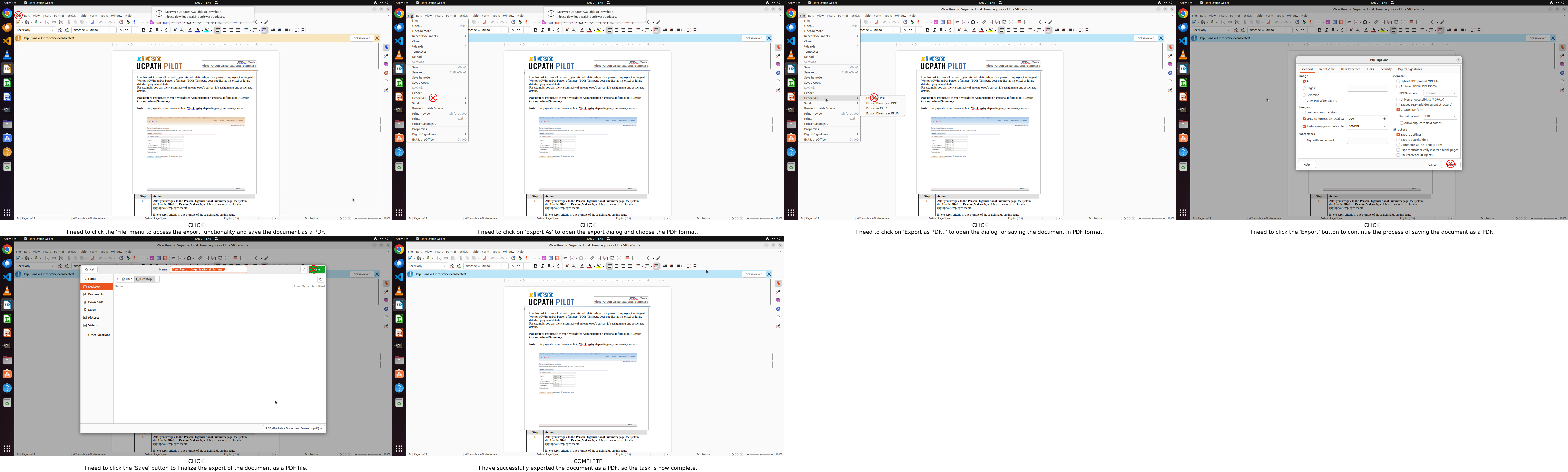
Figure 12: OSWorld: Automating export to PDF.
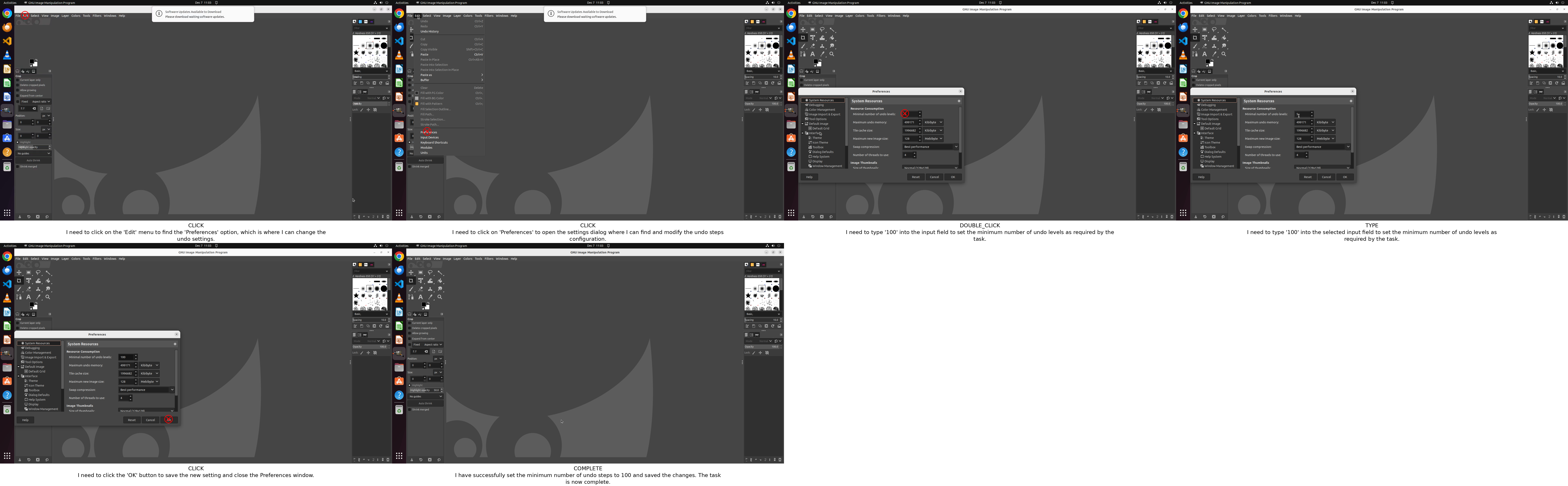
Figure 13: OSWorld: Task-specific configuration (setting undo steps).
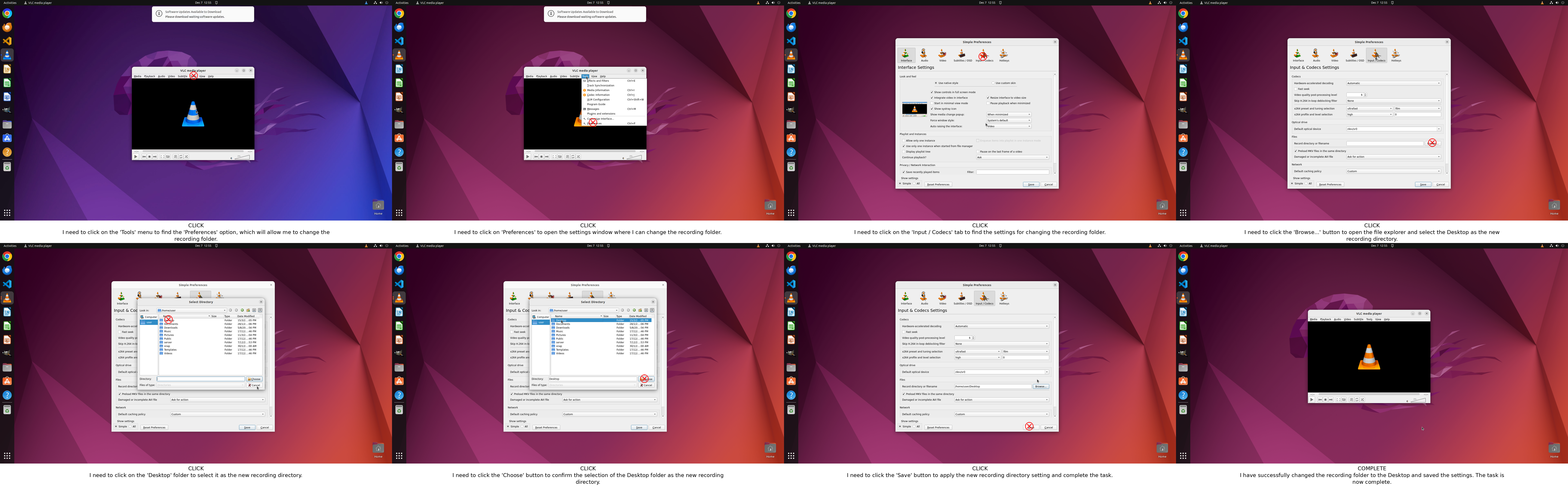
Figure 14: OSWorld: Automated file directory reconfiguration.
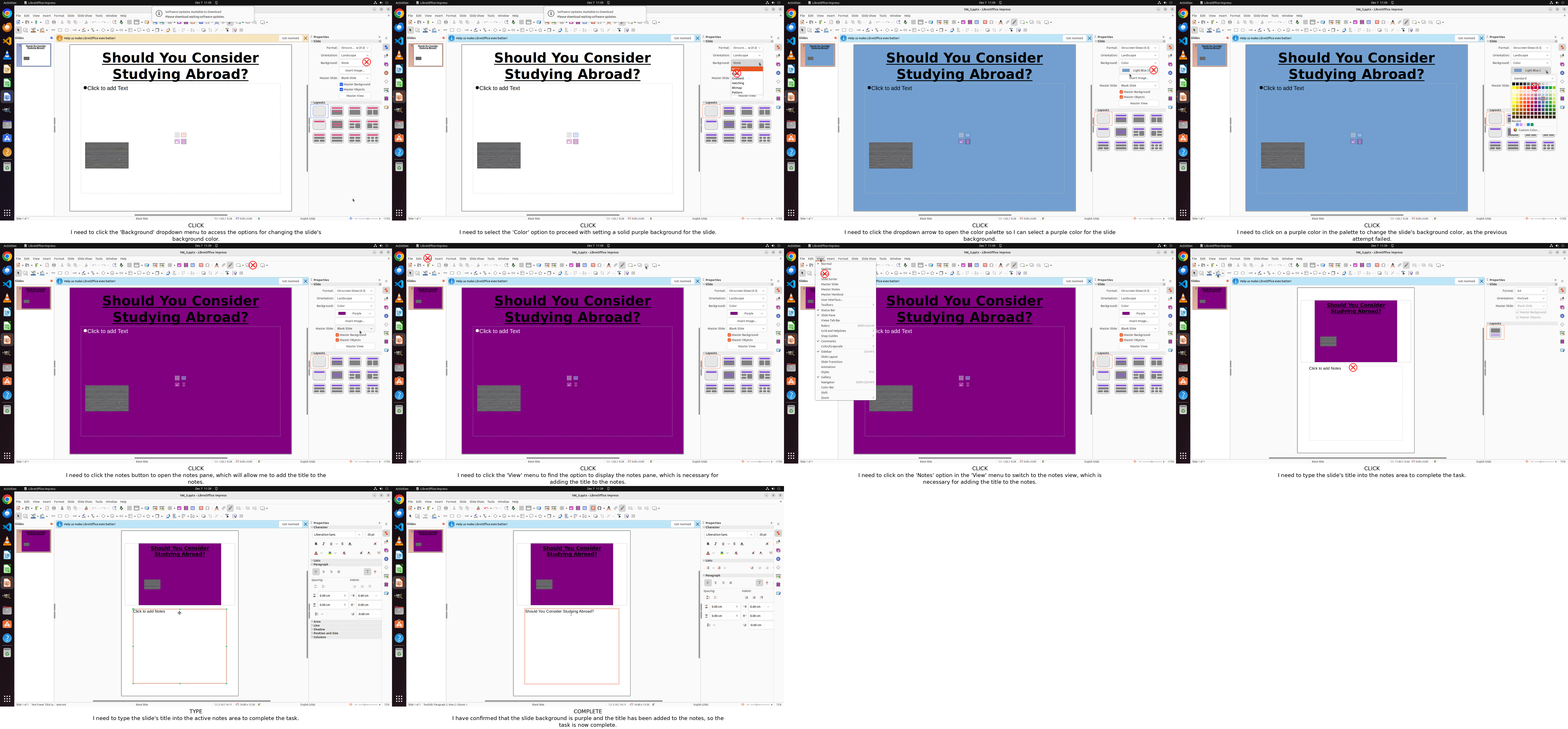
Figure 15: OSWorld: Slide formatting and annotation.
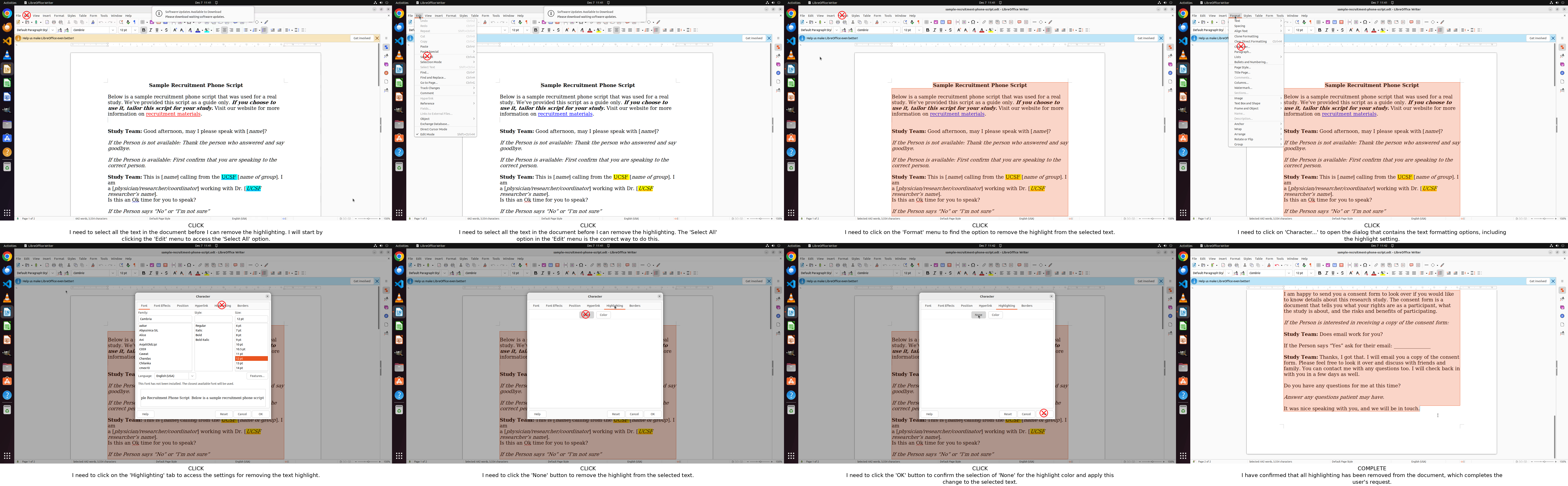
Figure 16: OSWorld: Fine-grained highlight removal post-editing.
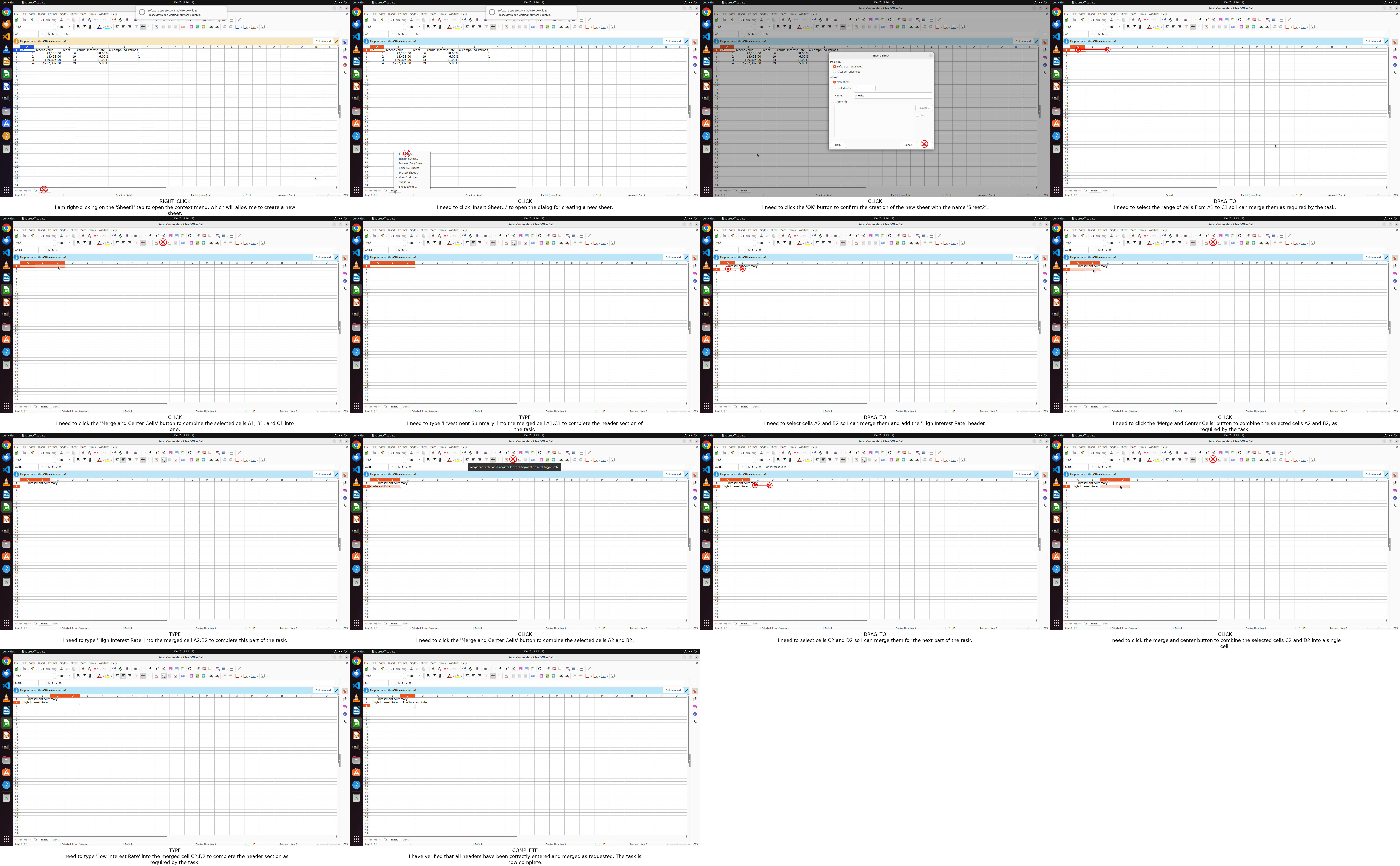
Figure 17: OSWorld: Creating and formatting sheets with header merging.
These qualitative results strongly support the architectural and training innovations, demonstrating that Step-GUI agents can robustly sequence actions, interpret diverse UI layouts, and reason through ambiguous instructions.
Implications and Future Prospects
Practically, Step-GUI systems deliver a compelling solution for privacy-sensitive GUI automation on both desktop and mobile devices, lowering annotation and operational costs, and providing unmatched capability at compact scale. Theoretically, the CSRS data flywheel introduces a robust blueprint for self-improving agents in other domains—especially where verification is more reliable at sequence or task level than at the fine-grained action level.
The protocol-level abstraction of GUI-MCP is likely to accelerate both integration and safe deployment of agentic LLMs by decoupling model reasoning from device specifics and providing explicit privacy hooks.
Future directions include broadening supported device classes, strengthening robustness to dynamic and rare UI states, and generalizing the CSRS-based pipeline to domains beyond GUI automation where similar challenges in data collection and privacy arise. Further advances could examine endogenously generated reward verifiers (e.g., using different models as cross-verifiers) to further reduce reliance on human calibration.
Conclusion
Step-GUI (2512.15431) establishes new methodologies and practical standards for GUI agents: a scalable, cost-efficient data improvement pipeline using trajectory-level calibration, expert compact models competitive with much larger baselines, a privacy-preserving and standardized deployment protocol, and a usage-grounded benchmark to measure real-world utility. These contributions provide both a robust blueprint and a practical toolkit for next-generation agentic systems, setting new benchmarks for robust, secure, and scalable GUI automation.

