- The paper introduces DiagEval, a trajectory-conditioned diagnostic protocol that reuses failed execution traces to distinguish agent execution failures from genuine software defects.
- The paper develops targeted diagnostic probes (Type A, B, and C) guided by Expected Information Gain, significantly improving false-negative recovery rates and overall accuracy.
- The paper demonstrates cross-framework transfer and cost efficiency, achieving absolute accuracy gains of 6–16 points while reducing API costs compared to naive retry strategies.
DiagEval: Trajectory-Conditioned Diagnosis for Reliable Evaluation of LLM-Generated Interactive Software
LLM-generated interactive software increasingly demands robust evaluation protocols capable of handling complex, stateful UIs where correctness is a reachability property over latent UI state-transition graphs. GUI-agent frameworks provide execution-based evaluation, but they fundamentally suffer from a single-trajectory identifiability gap: a single failed rollout eliminates only the observed path but cannot distinguish between agent execution failures (AgentFail) and genuine software defects (EnvFail). This ambiguity is acute in negative verdicts, as identical observable failures may arise from agent misperception, incomplete exploration, reasoning errors, or non-deterministic runtime instability. Prior evaluation protocols, often employing naive retry or static scoring, do not resolve this structural confound, leading to broad misattribution of failures.
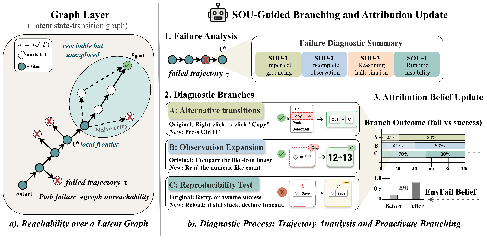
Figure 1: Overview of DiagEval. Given a failed rollout, DiagEval parses a Failure Diagnostic Summary (FDS), dispatches SOU-guided diagnostic branches, and integrates evidence across multiple branch trajectories to refine an internal attribution score over Z∈{AgentFail,EnvFail}.
DiagEval Protocol: Trajectory-Conditioned Diagnosis
DiagEval introduces a sequential, post-failure diagnostic protocol that actively reuses failed execution traces to systematically reduce attribution uncertainty. Upon failure, DiagEval constructs a structured Failure Diagnostic Summary (FDS), localizes a diagnosis-relevant fork node within the trajectory, and identifies the dominant source(s) of uncertainty (SOU) — e.g., imperfect grounding, incomplete observation, hallucinated reasoning, or runtime instability.
Guided by the FDS, DiagEval generates targeted diagnostic probes organized into Type A (alternative execution routes), Type B (observation expansion/visibility), and Type C (reproducibility checks), each designed to generate counterfactual evidence informative for distinguishing AgentFail from EnvFail. Probe selection is prioritized by an Expected Information Gain (EIG) criterion over a branch-typed internal attribution score, which is iteratively updated via an explicit Bayes-like rule (not a calibrated posterior). This structure yields information-theoretic efficiency: branches most likely to disambiguate failure attribution are prioritized, subject to per-case execution budgets.
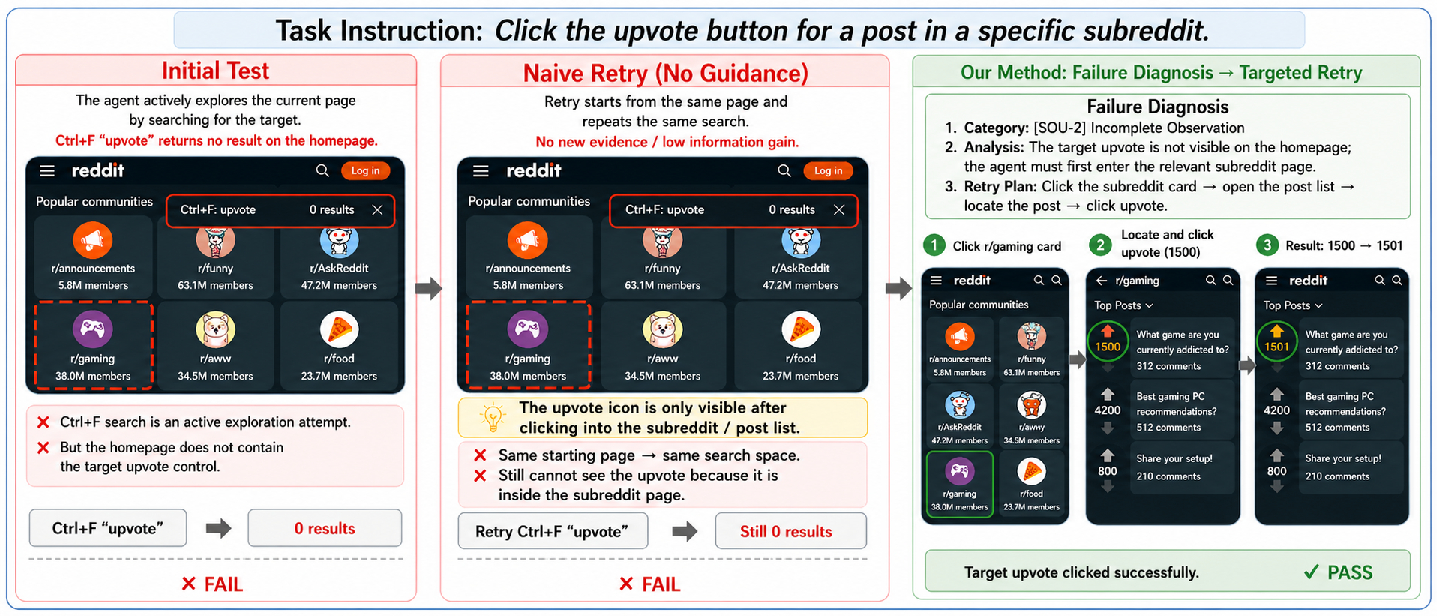
Figure 2: DiagEval uses FDS to locate incomplete observation (SOU-2), producing a targeted retry that achieves success where initial and naive retries fail.
Experimental Results: Reliability and Efficiency
Empirical evaluation across the WebDevJudge-Unit (WDJ-U) and RealDevBench (RDB) web development benchmarks demonstrates pronounced gains from trajectory-conditioned diagnosis. DiagEval outperforms naive retry strategies and strong GUI-agent baselines (e.g., AppEvalPilot, UI-TARS, WebVoyager) in both false-negative (FN) recovery and overall accuracy, with improvements robust to different GUI-agent backbones, including Gemini 3 Flash Preview and Claude Opus 4.6.
DiagEval recovers 45.6–62.1% of FNs, significantly exceeding the best retry-based baselines (17.5–46.2% recovery), with absolute accuracy improvements of 6–16 points and relative gains of 34–161%. On the full evaluation sets, one and two diagnostic rounds lift accuracy from 69.9% to 78.3% (WDJ-U) and from 65.0% to 81.6% (RDB). By exploiting SOUs, DiagEval demonstrates that structured diagnostic evidence, not just repeated attempts, is critical: SOU-2 (incomplete observation) dominates successful recoveries through specialized visibility probes.
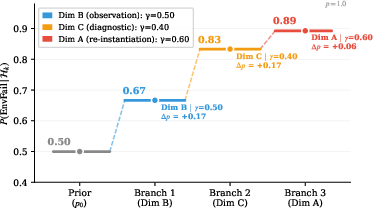
Figure 3: Attribution-score update across diagnostic branches: branch-typed likelihoods yield differential evidence strengths for identical observed outcomes, driving the internal attribution signal.
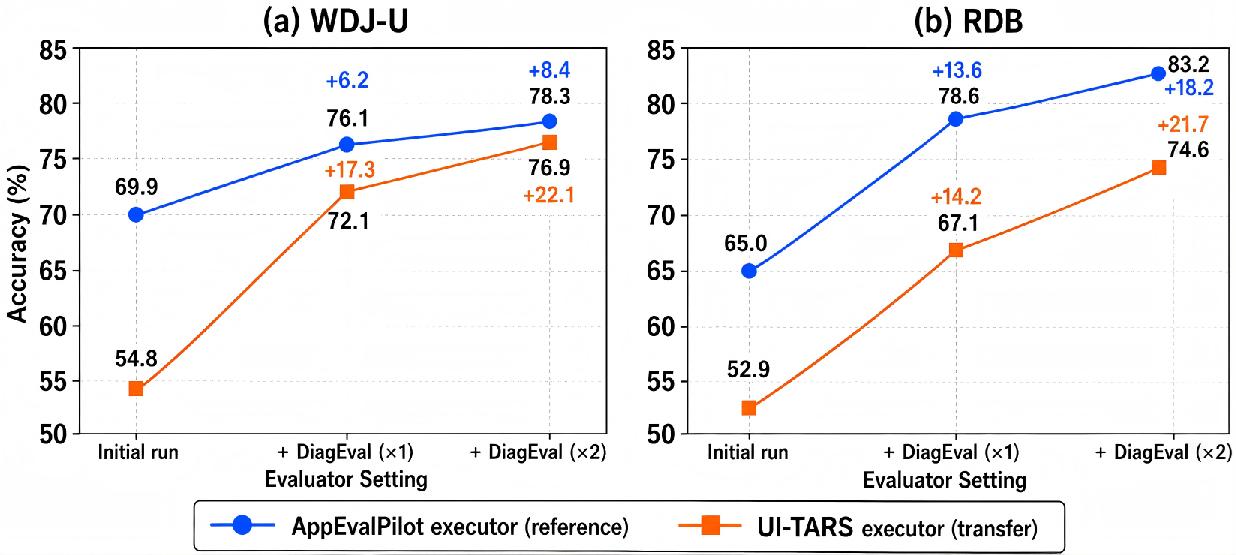
Figure 4: Cross-framework transfer results—DiagEval provides substantial accuracy gains when ported to a different GUI-agent framework, demonstrating generality.
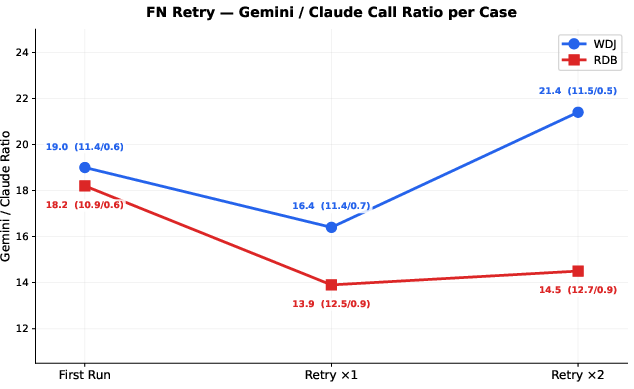
Figure 5: Analysis of model-call composition—Gemini (execution) and Claude (diagnosis) calls remain balanced, with cost variation mainly introduced by supervisor-side diagnostic calls.
Ablation Analysis
Ablation studies isolate the contribution of DiagEval’s components. The recovery and attribution entropy reduction (ΔH) are maximized only when SOU-guided branching and attribution score updating are present. Diagnosis quality, rather than increased rollouts, is responsible for gains: even with budget-matched Best-of-3 retries, DiagEval achieves over double the FN recovery rate. The attribution score serves as a bilateral signal, with significant ROC-AUC for ranking agent vs. environment failures, despite not being a calibrated probability.
Efficiency analysis shows EIG-based branch ordering reduces probe costs and increases first-branch success compared to prompt-based or random strategies.
Cross-Framework Transfer and Cost
DiagEval’s mechanism is framework-agnostic, as demonstrated by transferring the diagnostic protocol to UI-TARS, yielding up to 22.1 percentage point absolute accuracy gain. These gains are not attributable to increased sampling but to targeted diagnostic evidence acquisition. DiagEval delivers these benefits at substantial cost efficiency, exceeding the reliability of more expensive GUI-agent executions (e.g., AppEvalPilot on Claude Opus 4.6) at ~30-50% of the API cost.
Practical and Theoretical Implications
This work establishes that trajectory-conditioned, active diagnosis is necessary for reliable interactive software evaluation. The error mode taxonomies and evidence aggregation scheme introduced by DiagEval enable failure-aware evaluators to correctly partition responsibility between agent and environment—a prerequisite for scalable, trustworthy LLM-generated software verification.
Practically, integration of DiagEval into GUI-agent evaluation pipelines will markedly reduce false defect reporting and facilitate automated evaluation in benchmarks, CI systems, and autonomous agent deployments. Theoretically, the approach motivates future research on calibrated likelihood learning, generalization to richer attribution spaces, and robustness to supervisor (LLM) biases. Importantly, DiagEval’s framework is compatible with advances in GUI agents or LLM architectures, focusing diagnostic gains orthogonally to the underlying executor’s capacity.
Limitations and Future Directions
DiagEval's current protocol depends on empirical, hand-tuned likelihoods, prompt-driven branch generation, and binary attribution. The result is an informative, but uncalibrated, internal score. Dependence on an external LLM supervisor for diagnosis and intervention planning introduces sources of bias and failure propagation. Scaling DiagEval toward learned, probabilistic attribution models and expanding beyond binary failure modes are natural next steps. Improvements in prompt design, diagnostic interpretability, and cost reduction also represent important research directions.
Conclusion
DiagEval redefines post-failure interactive software evaluation as an active, trajectory-conditioned diagnosis problem, not passive execution or blind retry. Its structured evidence acquisition and integration mechanisms produce robust, generalizable improvements in evaluation accuracy and reliability. These results indicate that as LLM-generated systems scale in interactivity and complexity, evaluator-side diagnosis will be a central requirement for correct automated judgment.