- The paper introduces G2F-RAG, a training-free method that integrates structured graph knowledge with video content using a visually rendered reasoning frame.
- It employs a two-stage, multi-agent pipeline that constructs a global knowledge graph offline and renders minimal subgraphs online to optimize attention concentration.
- Empirical results show up to +7.4% accuracy gains on complex video reasoning benchmarks, emphasizing improved focus and auditability over traditional methods.
Graph-to-Frame RAG: Visual-Space Knowledge Fusion for Training-Free and Auditable Video Reasoning
Retrieval-augmented video reasoning is consistently limited by cross-modal competition and token inefficiency when external knowledge is appended as text or heterogeneous visual fragments. Traditional paradigms confound low-level visual and high-level textual signals within a shared attention space, causing diluted attention, increased cognitive load, and degraded performance, especially in compositional or knowledge-intensive tasks. The "Graph-to-Frame Retrieval-Augmented Generation" (G2F-RAG) paradigm eliminates this bottleneck by projecting retrieved structured knowledge as a compact, visually rendered frame appended to the video. This strategy grounds all evidence in the visual domain, ensuring alignment with the inductive bias of large multimodal model (LMM) backbones, reducing attention diffusion, and yielding more auditable, causal answers.
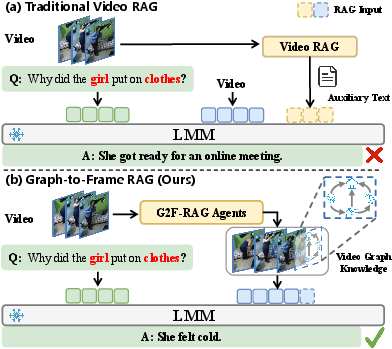
Figure 1: Traditional Video RAG disrupts attention with appended text; G2F-RAG delivers external knowledge as a single, visually grounded reasoning frame.
Architectural Framework
G2F-RAG employs a two-stage, training-free, multi-agent pipeline. Offline, a graph-construction agent generates a global, problem-agnostic video knowledge graph encoding entities, events, spatial relationships, and external world knowledge. This reusable graph supports efficient online operations. Online, a hierarchical orchestration agent dynamically classifies the query by difficulty, invoking a retrieval agent when multi-step, compositional, or knowledge-based reasoning is necessary. A minimal, relevant subgraph is identified, which is then rendered by a lightweight frame renderer into a graphical "reasoning frame." The rendered frame is appended to the video, constituting a modality-aligned, low-token-burden input for the LMM backbone.
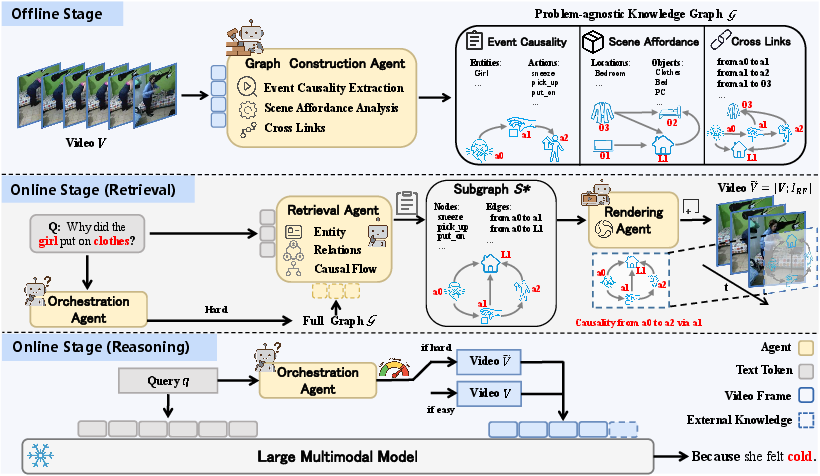
Figure 3: The method overview—graph construction, query routing, minimal subgraph retrieval and rendering, and visual-space fusion with the LMM.
The pipeline is fully plug-and-play, requiring no backbone tuning and providing explicit, inspectable evidence—advantageous for auditability and compliance in sensitive applications.
Empirical and Analytical Results
Attention analysis confirms that, under baseline text-augmented RAG, attention is fragmented across visual content and heterogeneous contextual tokens, diluting relevant focus. In contrast, G2F-RAG concentrates attention tightly on salient video frames and the appended reasoning frame, as visualized through aggregated attention maps. This architectural bias delivers consistent performance gains across all evaluated LMMs and datasets.
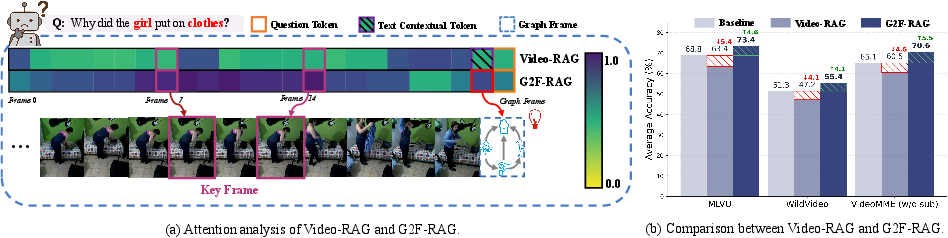
Figure 2: (a) Attention maps: text-append RAG diffuses focus versus G2F-RAG’s concentrated attention; (b) G2F-RAG improves accuracy on all benchmarks compared to performance drops with baseline Video-RAG.
Experimental evaluation is conducted on leading open-source and proprietary LMMs—including InternVL3.5, Qwen2.5-VL, LLaVA-Video, VideoLLaMA 3, and Gemini 1.5 Pro—across a broad suite of 8 video reasoning benchmarks (e.g., MLVU, WildVideo, VideoMME, TempCompass, VSIBench, VideoMMMU). G2F-RAG is strictly training-free, operationalized with public checkpoints using official inference configurations.
Key findings:
- G2F-RAG consistently outperforms both unaugmented and state-of-the-art RAG competitors (Video-RAG, Vgent) across all evaluated backbones and tasks.
- On knowledge-intensive and compositional benchmarks, G2F-RAG delivers absolute accuracy gains of up to +7.4% over the underlying model, with the most pronounced improvements observed in 4B–8B scale LMMs.
- Ablation studies demonstrate that appending a single reasoning frame at the video’s end is optimal. Alternative delivery as textual JSON (G2J-RAG), multi-frame rendering, or text-heavy graphical styles underperform, sometimes even degrading accuracy.
- The hierarchical routing component, which only invokes G2F-RAG for non-easy queries, preserves calibration and performance on data for which the video evidence alone is sufficient.
Case Analysis and Interpretability
In representative case studies, the offline graph captures nuanced video semantics: actions, object affordances, spatial topology, external world facts. The orchestrator routes complex queries to the retrieval path, with the subgraph reflecting relevant causal chains and contextual relations. The rendered frame, appended to the video, provides a concise, low-noise representation of this knowledge, supporting accurate grounded reasoning by the LMM. Attention visualization highlights the model’s increased focus on both key video evidence and reasoning frame under G2F-RAG.
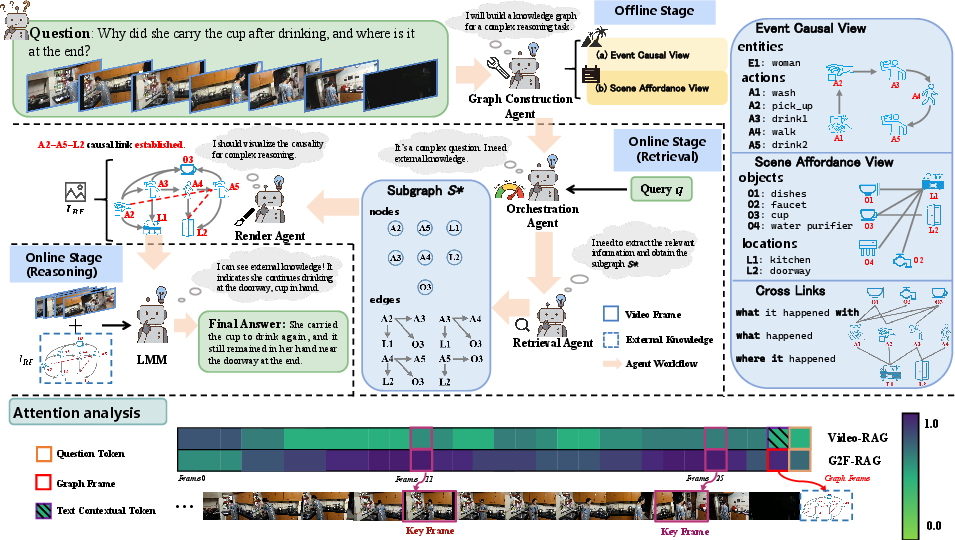
Figure 5: The pipeline in case study—offline graph construction, online subgraph retrieval, reasoning frame rendering and concatenation, with clear attention on essential evidence.
Theoretical Implications and Future Outlook
G2F-RAG’s reframing of knowledge fusion as a purely visual-space operation directly leverages the strengths and architectural biases of video LMMs. This paradigm shifts the research focus from context length and retrieval precision to representational alignment and cognitive load minimization. The explicit evidence trail provided by the visual reasoning frame augments the interpretability and debuggability of LMM decisions, supporting practical needs in regulated or safety-critical domains.
The approach suggests broader implications:
- Visual compression of structured knowledge can generalize to other modal retrieval tasks (e.g., medical imaging, robotics, diagram reasoning).
- Training-free, auditable augmentation pathways facilitate rapid deployment and evaluation, avoiding extensive re-training or backbone modification.
- Future developments may focus on more sophisticated graph-to-frame rendering pipelines, hierarchical multi-frame composition for extremely complex tasks, and integration with in-context learning or agentic tool use.
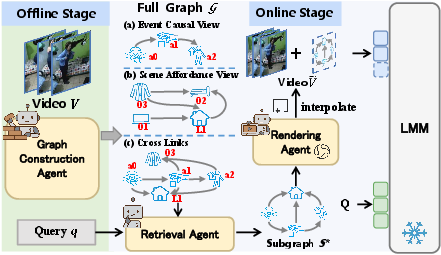
Figure 4: The entire G2F-RAG pipeline—global graph construction, query-dependent minimal retrieval, single-frame rendering, and video-visual fusion for model input.
Conclusion
G2F-RAG introduces a robust, training-free, and inspectable paradigm for video reasoning that fundamentally resolves the bottleneck of knowledge fusion in multimodal LMMs. By aligning all evidence, including retrieved structured knowledge, within the visual domain, G2F-RAG increases model focus, improves generalization and accuracy—especially in knowledge-intensive scenarios—and sets a new standard for auditability and interpretability in video RAG. The methodology’s modular nature further points to its extensibility across future AI systems requiring compositional, causal, and evidence-grounded multimodal reasoning.