- The paper introduces a four-stage pipeline with role-based context packaging to govern structured human-AI interactions.
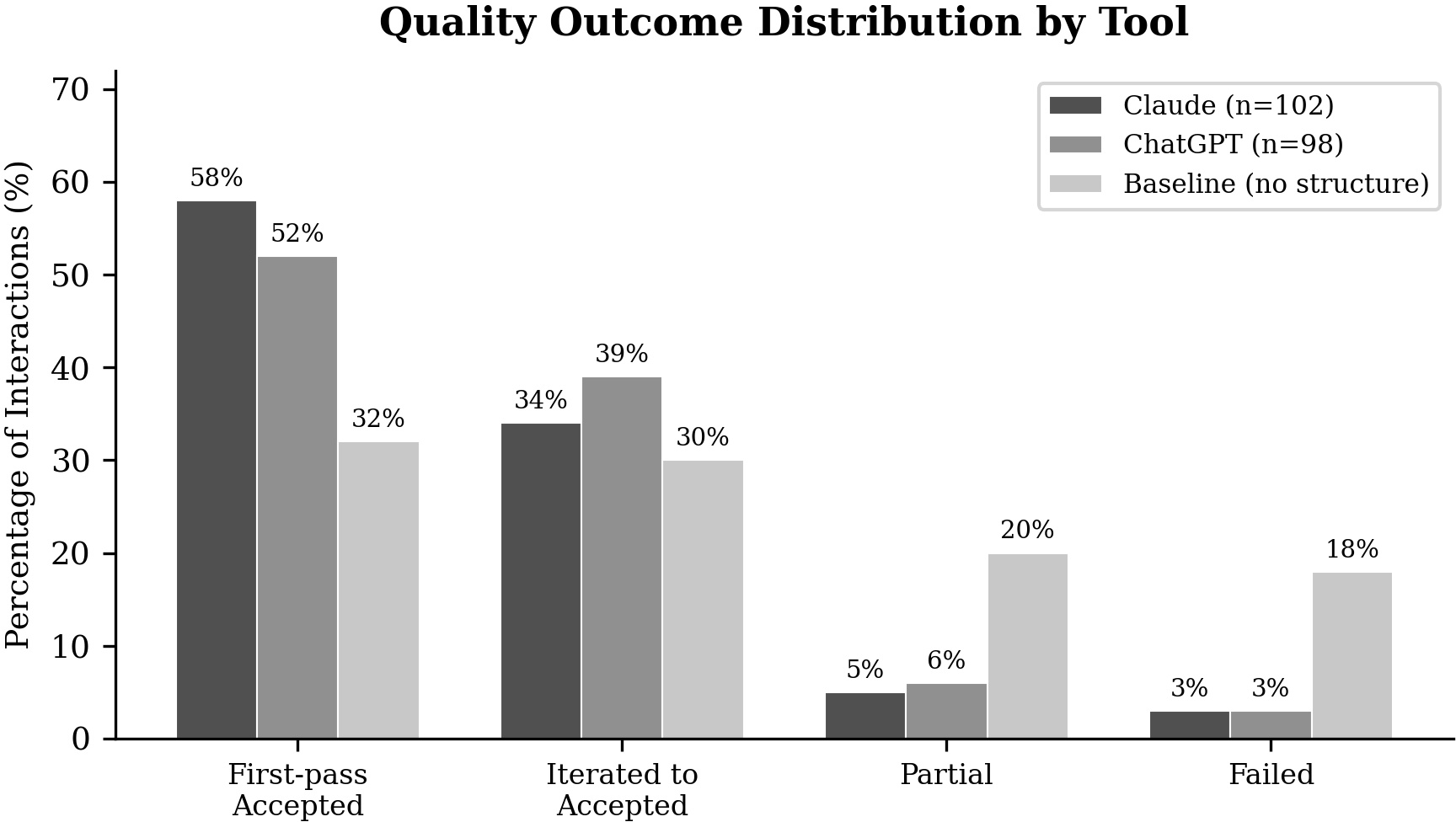
- It presents empirical evidence showing improved first-pass success, reduced iteration cycles, and higher final acceptance rates.
- The methodology emphasizes structured context over prompt engineering, employing cross-tool audits and priority-based conflict resolution.
Context Engineering: A Practitioner Methodology for Structured Human-AI Collaboration
Motivation and Positioning
The paper "Context Engineering: A Practitioner Methodology for Structured Human-AI Collaboration" (2604.04258) asserts that the effectiveness of LLM-augmented workflows is determined less by prompting strategies and more by the structure and completeness of the context provided. Contrary to the prevailing focus on prompt engineering, this work systematizes the assembly and governance of the entire informational payload delivered to AI systems. Citing the professional consensus articulated by Karpathy, Lütke, and Willison, the paper foregrounds context engineering as the operational core of advanced AI usage, responding to the absence of a formal, repeatable methodology for context structuring in professional environments.
The methodology is situated within the landscape of AI agent frameworks and practitioner toolkits, filling a demonstrated gap: existing systems (e.g., LangChain, AutoGPT, CrewAI) excel at machine-to-machine context transfer but do not address the structured, role-declared context packages that professionals must assemble for human-to-AI collaboration. The paper positions its contribution as the first to formalize a five-role context taxonomy, integrate priority-based conflict resolution, and empirically relate context structure to output quality across domains.
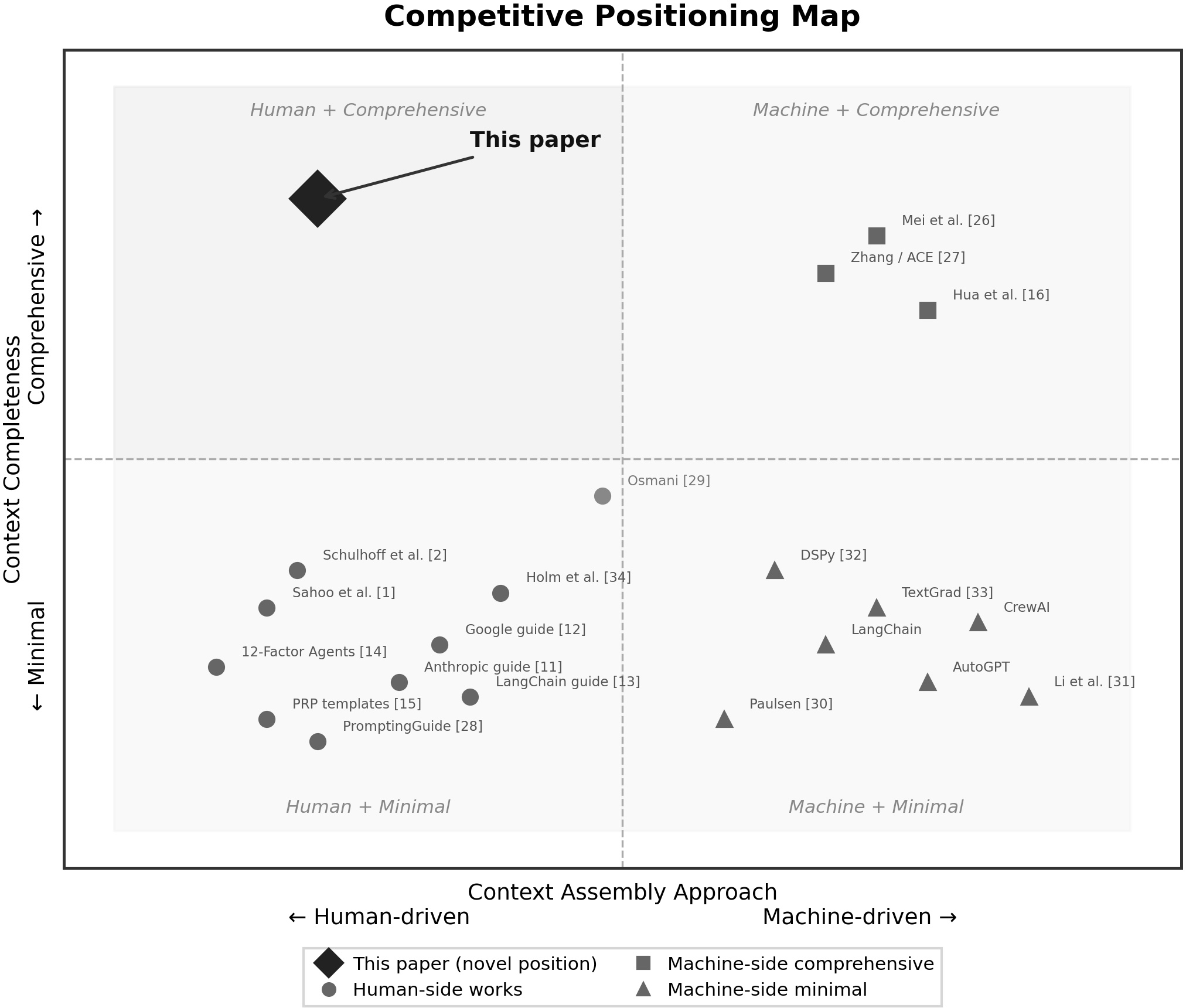
Figure 1: The competitive positioning map delineates the novel human-side comprehensive quadrant staked out by Context Engineering, distinguished from machine-side context automation and ad-hoc human prompting.
Methodology: Pipeline Architecture and Role-Based Context Packaging
The central proposition is a four-stage pipeline (Reviewer → Design → Builder → Auditor) governing every substantive AI interaction. Each stage is decoupled via strict separation of concerns and enforced by architectural gates. The Reviewer extracts and formalizes requirements; the Designer outputs structural specifications (the Authority); the Builder executes against those specs; the Auditor independently verifies conformance and correctness, feeding back precise findings.
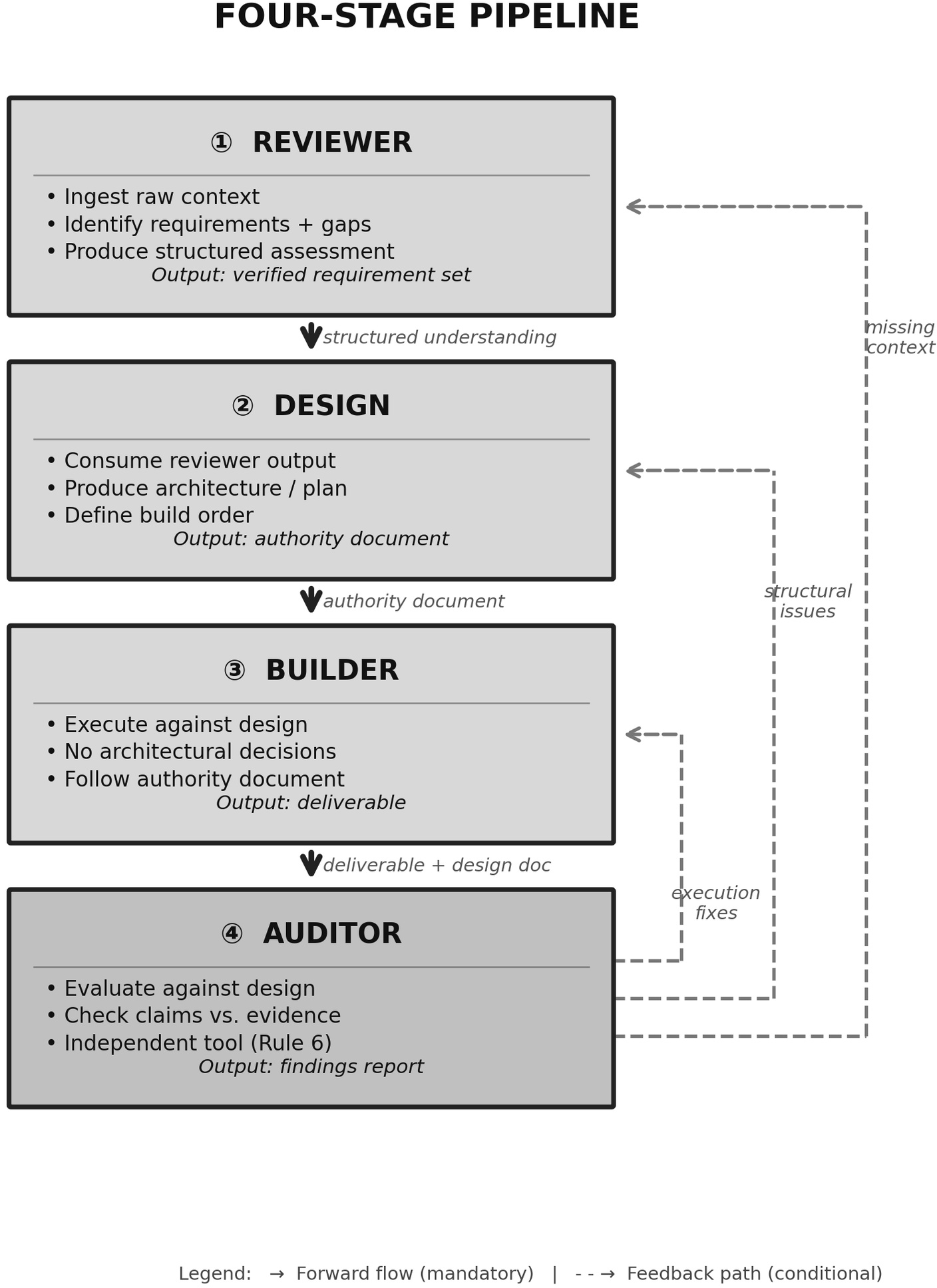
Figure 2: The four-stage pipeline with iteration paths exposes mandatory data dependencies, feedback loops, and revision gates ensuring controlled quality evolution.
Key to this pipeline is the context package formalism, wherein every element is explicitly assigned one of five roles with a fixed, strict priority:
- Authority (highest) – definitive requirements/specs
- Exemplar – paradigms or reference outputs
- Constraint – explicit limitations
- Rubric – evaluation/acceptance criteria
- Metadata (lowest) – ancillary information, e.g., the human's prompt
Priority-based conflict resolution is enforced: the output is governed by the highest-priority relevant input, mitigating ambiguities and overruling lower-priority directives. Notably, Metadata—the usual prompt—is always subordinate, challenging standard practices where last-in instructions dominate LLM behavior.
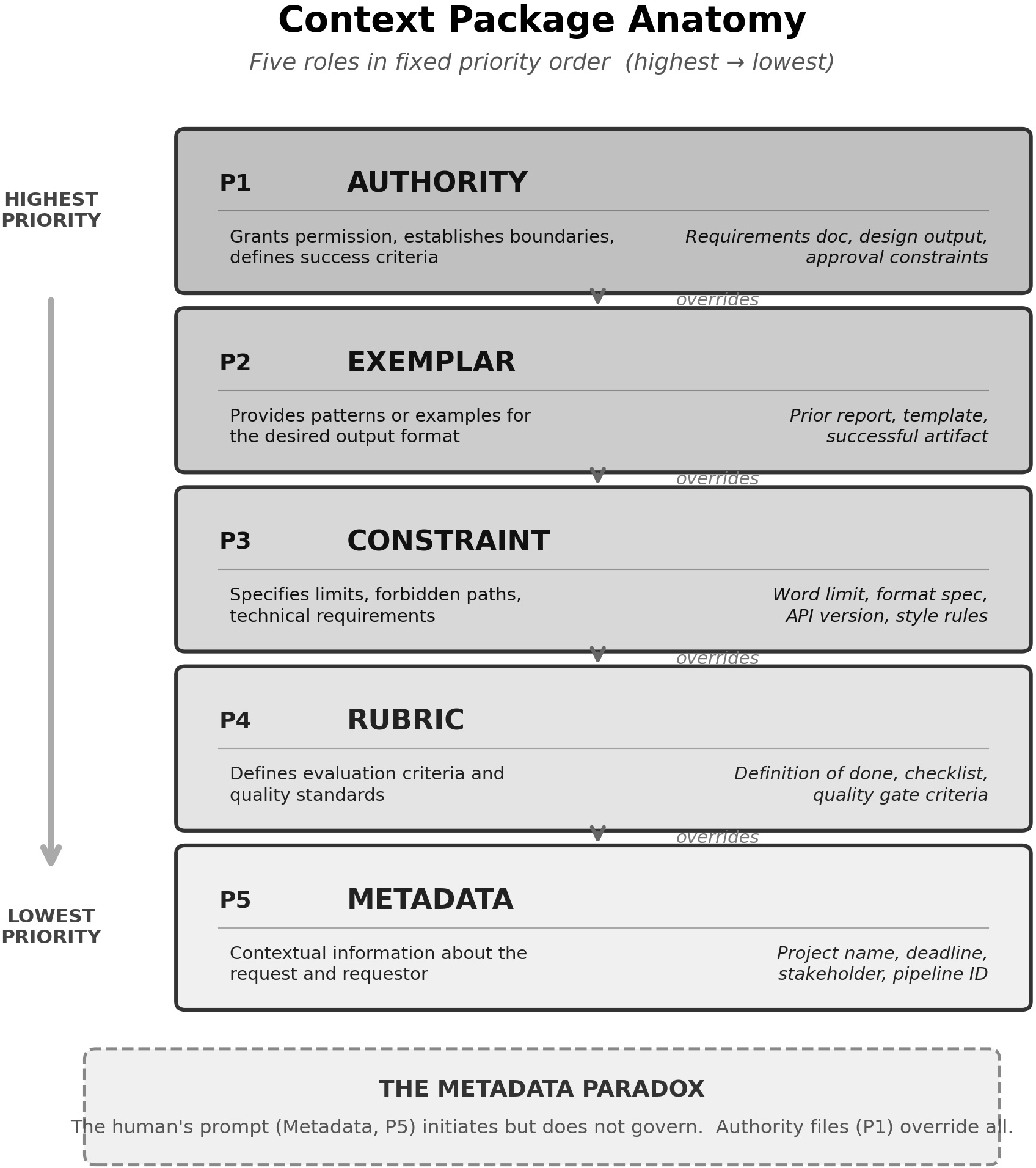
Figure 3: The anatomy of the context package visualizes hierarchical embedding of Authority through Metadata, detailing canonical content and demonstrating contextual role nesting.
Tool-aware patterns are introduced: different models (Claude, ChatGPT, Cowork, Codex) are leveraged according to their strengths (e.g., file-based Authority ingestion by Claude, evaluative feedback by ChatGPT). Cross-tool validation is formalized; Rule 6 prohibits the same agent from acting as both Builder and Auditor, empirically reducing conceptual blind spots.
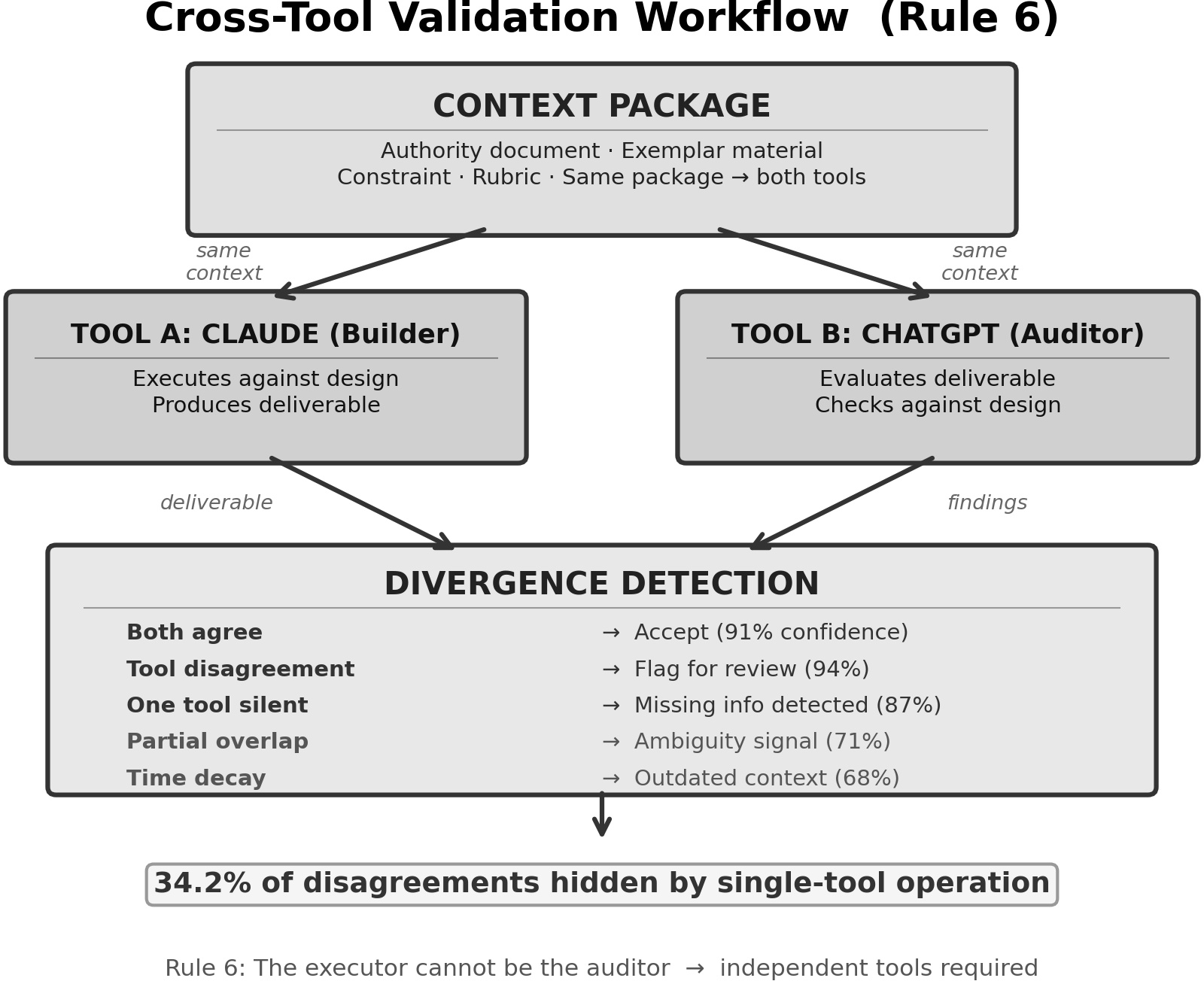
Figure 4: The cross-tool workflow diagram demonstrates context package reuse across multiple LLMs for disagreement detection and ambiguity surfacing.
Empirical Validation and Quantitative Results
The paper reports an observational study covering 200 professional interactions using Claude, ChatGPT, Codex, and Cowork, benchmarked against 50 baseline (unstructured, ad-hoc) interactions. Consistent and substantial improvements in output quality and iteration efficiency are documented:
Cross-tool auditing exhibited strong non-overlap in defect detection—builders systematically missed error classes (e.g., hallucinated citations, arithmetic errors) that auditors, especially when cross-tool, reliably caught. The empirical evidence supports Rule 6 (Executor ≠ Auditor) and the necessity of independent verification phases.
Practical Guidance and Type Specialization
Practitioner guidelines distilled from the 14 empirical findings direct users to:
- Prioritize explicit Authority creation over prompt elaboration.
- Rigorously instantiate all pipeline stages for complex deliverables.
- Assign context roles for all input files; avoid role ambiguity.
- Enforce cross-tool, independent auditing.
- Accumulate and leverage validated pipeline templates to exploit learning-curve effects (iteration counts diminish with template reuse).
The methodology is operationalized through domain-specialized pipeline types (academic papers, code builds, government proposals, curriculum) validated over multiple cycles. Context package reuse demonstrates cost and defect reduction consistent with formal learning curve models.
Theoretical Underpinnings
The observed improvements are mapped to established formalisms:
- Capture-recapture models mathematically support the necessity of independent audit stages: defect detection is maximized not by additional self-revision, but by diversity of review.
- N-version diversity enhances error detection probability, justifying parallel cross-tool builds/audits.
- Information Bottleneck theory explains why deliberate role-based compression outperforms indiscriminate context inclusion.
- Boehm's cost curve empirically contextualizes the extreme rework penalties of early-stage (Reviewer/Design) omission.
- Wright's law (learning curve) substantiates the efficiency gains from template accumulation.
Limitations and Threats to Validity
The findings are grounded in a single-operator, practitioner-as-extractor dataset, potentially subject to self-assessment bias and non-random sampling. The lack of randomization and small baseline size preclude definitive claims of generalizability. Tool-specific behaviors (Claude vs. ChatGPT) may evolve. Nonetheless, the methodology is published with extraction protocols and rubrics to facilitate independent replication and cross-domain testing.
Implications and Future Directions
Practically, this methodology underpins scalable, auditable, and transferable AI-augmented workflows in high-assurance domains, including regulated industries with compliance and evidentiary requirements. Theoretically, the results implicate context completeness, structural authority, and rigorous role separation—not mere prompt sophistication—as the dominant factors in LLM-mediated task performance.
Prospective directions include controlled, multi-operator trials, automation of context packaging and pipeline routing (connecting to frameworks such as ACE (Zhang et al., 6 Oct 2025)), native tooling support for context role declaration, and deeper quantification of context window structure effects. Integrating this methodology with machine-side governance architectures (e.g., LATTICE/MANDATE/TRACE) promises end-to-end verifiability across human-AI systems.
Conclusion
This paper provides the first comprehensive, empirical, and formalized methodology for context engineering at the practitioner level. The architecture—structured pipelines, prioritized context roles, cross-tool validation, and template-driven scaling—delivers measurable improvements in output quality and iteration efficiency. The data strongly support the claim that context completeness and structure, not prompt ingenuity, are the principal levers for high-quality human-AI collaboration.
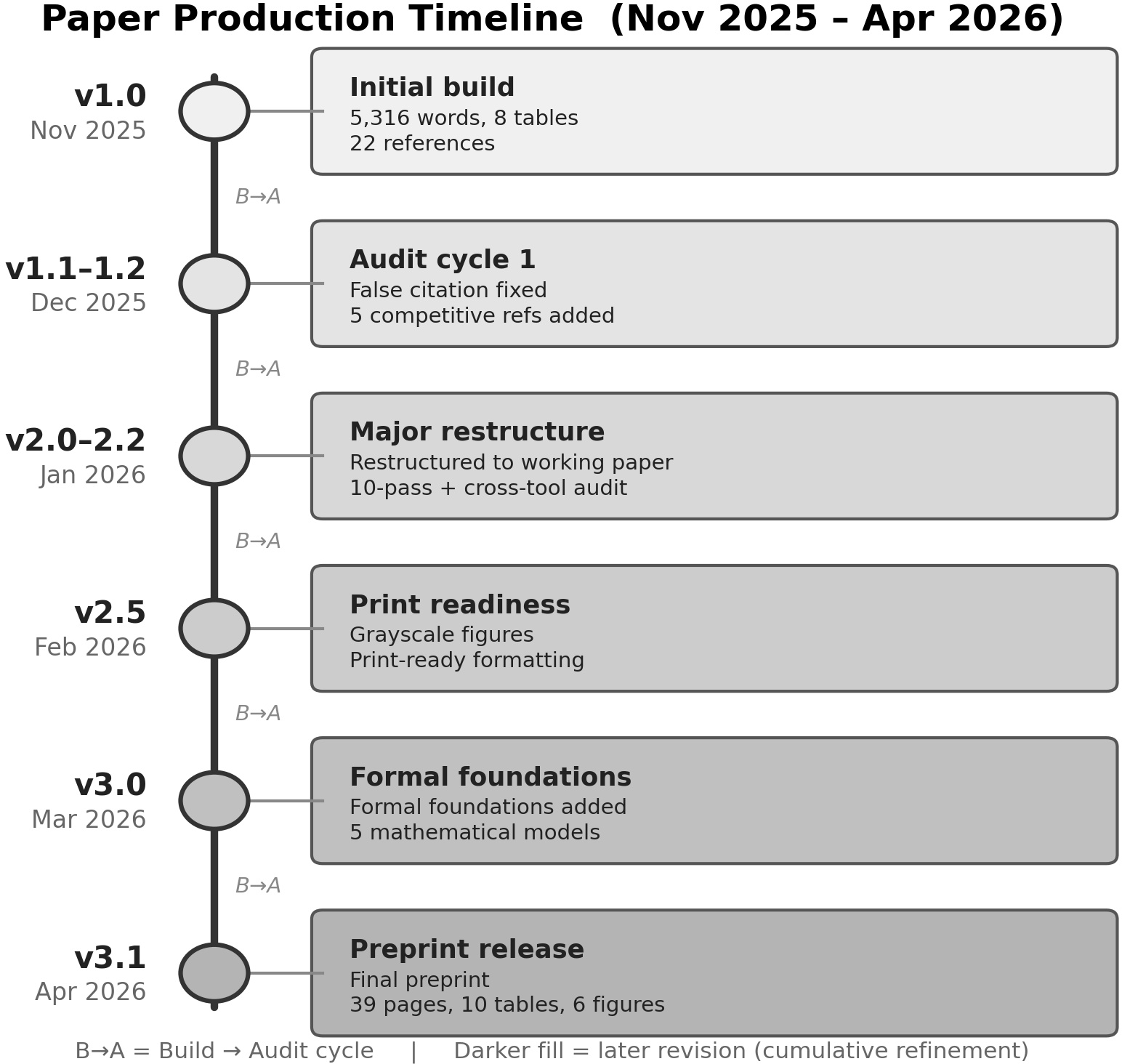
Figure 6: The production timeline visualizes multi-stage pipeline execution, audit cycles, and iterative structural improvements underlying the paper itself.
The work constitutes a reproducible and extensible reference for organizations seeking to institutionalize robust, auditable, and high-yield AI practices.
Reference: "Context Engineering: A Practitioner Methodology for Structured Human-AI Collaboration" (2604.04258)