Context Engineering 2.0: The Context of Context Engineering
Abstract: Karl Marx once wrote that ``the human essence is the ensemble of social relations'', suggesting that individuals are not isolated entities but are fundamentally shaped by their interactions with other entities, within which contexts play a constitutive and essential role. With the advent of computers and artificial intelligence, these contexts are no longer limited to purely human--human interactions: human--machine interactions are included as well. Then a central question emerges: How can machines better understand our situations and purposes? To address this challenge, researchers have recently introduced the concept of context engineering. Although it is often regarded as a recent innovation of the agent era, we argue that related practices can be traced back more than twenty years. Since the early 1990s, the field has evolved through distinct historical phases, each shaped by the intelligence level of machines: from early human--computer interaction frameworks built around primitive computers, to today's human--agent interaction paradigms driven by intelligent agents, and potentially to human--level or superhuman intelligence in the future. In this paper, we situate context engineering, provide a systematic definition, outline its historical and conceptual landscape, and examine key design considerations for practice. By addressing these questions, we aim to offer a conceptual foundation for context engineering and sketch its promising future. This paper is a stepping stone for a broader community effort toward systematic context engineering in AI systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about “context engineering,” which means designing the background information that helps AI understand what we want. Think of context as everything around a task that gives it meaning—who’s asking, what tools are available, what just happened, what the goal is, and what the situation looks like. The authors explain that context engineering isn’t brand-new. People have been doing versions of it for over 20 years, from early phone sensors and menus to today’s smart AI agents. The paper lays out a clear definition, a timeline of how it has evolved, and practical advice for building better AI systems that understand us with less effort.
Key questions the paper asks
- What exactly counts as “context” for computers and AI?
- What is “context engineering,” in simple terms?
- How has it changed from old computers (rigid and rule-based) to modern AI agents (flexible and language-based), and what might come next?
- What are the main parts of context engineering: collecting, storing, managing, and using context?
- What design rules should guide people who build AI systems?
How the authors approached the topic
Instead of running lab experiments, the authors build a big-picture framework:
- They give precise definitions (like writing a clear dictionary for terms such as “context,” “entity,” and “interaction”), so everyone talks about the same thing.
- They offer a simple idea to remember: context engineering is about reducing “entropy,” which is a fancy word for messiness or uncertainty. Imagine cleaning a messy room so your friend (the AI) can quickly find what it needs without guessing.
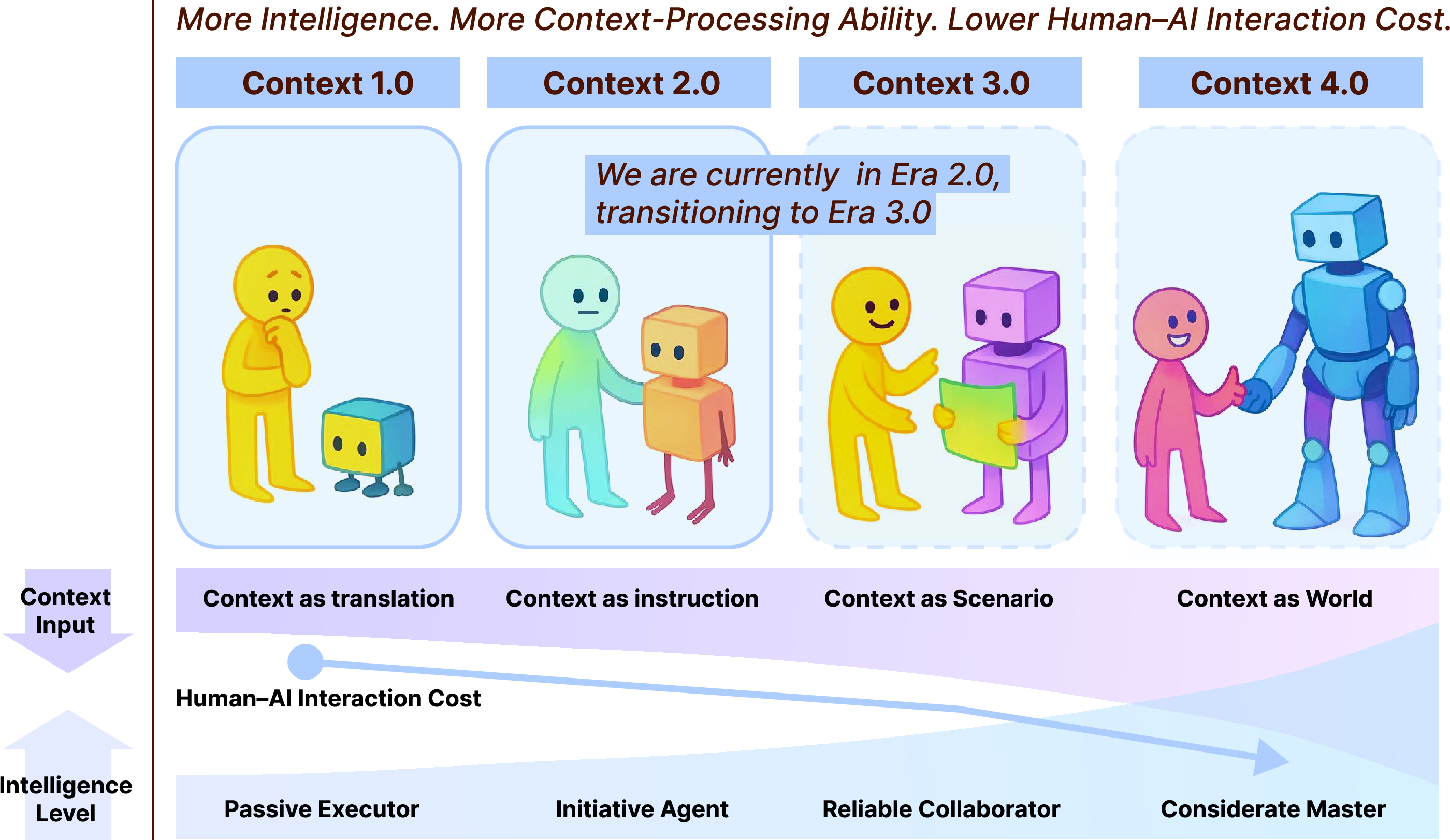
- They trace four stages (“eras”) of context engineering based on how smart machines are: 1) 1.0: Simple computers that need strict formats. 2) 2.0: Today’s agents/LLMs that can handle natural language. 3) 3.0: Future human-level understanding. 4) 4.0: Superhuman systems that can even set helpful context for us.
- They compare past and present practices and collect design ideas (how to gather context, how to store it, how to process it, and how to use it well), with examples from real tools.
To explain technical parts, they use everyday analogies:
- Reducing entropy = tidying information so a machine doesn’t get lost.
- Context operations (collect, store, manage, use) = what a librarian does to organize books so readers find the right ones fast.
Main findings and why they matter
1) The core idea: reduce “information messiness” so machines act correctly
Humans are good at reading between the lines. Machines aren’t—unless we prepare the right context. Context engineering is the effort to turn unclear, high-entropy information (messy and ambiguous) into clear, low-entropy information that AI can use. The smarter the AI, the less we need to tidy up—but we still need a plan.
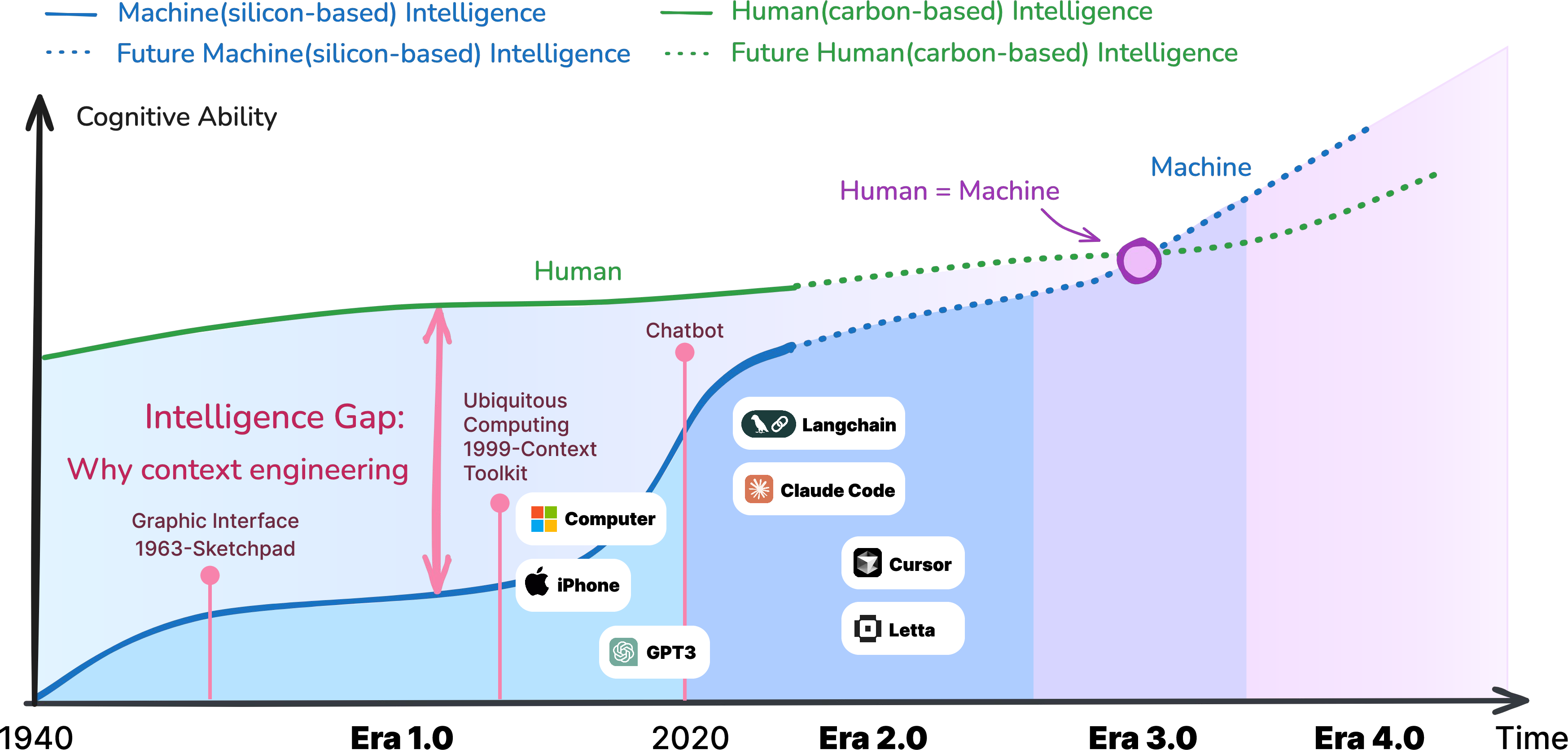
2) A four-stage roadmap of progress
- Era 1.0 (1990s–2020): Early context-aware systems. Inputs were structured and simple (like GPS location, time of day). Systems used “if this, then that” rules (“If phone is at the office, silence it”). People had to translate their intentions into the machine’s limited formats.
- Era 2.0 (2020–now): Agent-centric AI (like ChatGPT, Claude). These systems can understand natural language, images, and sometimes other signals. They tolerate ambiguity and can fill small gaps. We move from “context-aware” to “context-cooperative”—AI doesn’t just sense; it helps.
- Era 3.0 (future): Human-level AI that grasps subtle social cues, emotions, and long-term intentions like a real teammate.
- Era 4.0 (speculative): Superhuman AI that can even set or create helpful context, revealing needs we didn’t know we had.
Why this matters: As intelligence rises, the “cost” for humans to explain themselves drops. Interfaces get easier and more natural.
3) Three pillars of context engineering
- Context collection: How we gather context (from text, images, voice, sensors, devices, apps). In 2.0, we have many sources: phones, smartwatches, computers, smart speakers, even gaze or heart-rate sensors.
- Context management: How we clean, organize, tag, compress, and connect context so it stays meaningful over time. Two guiding rules:
- Minimal Sufficiency: collect just enough to do the job (value comes from relevance, not hoarding data).
- Semantic Continuity: preserve meaning across time, not just data logs.
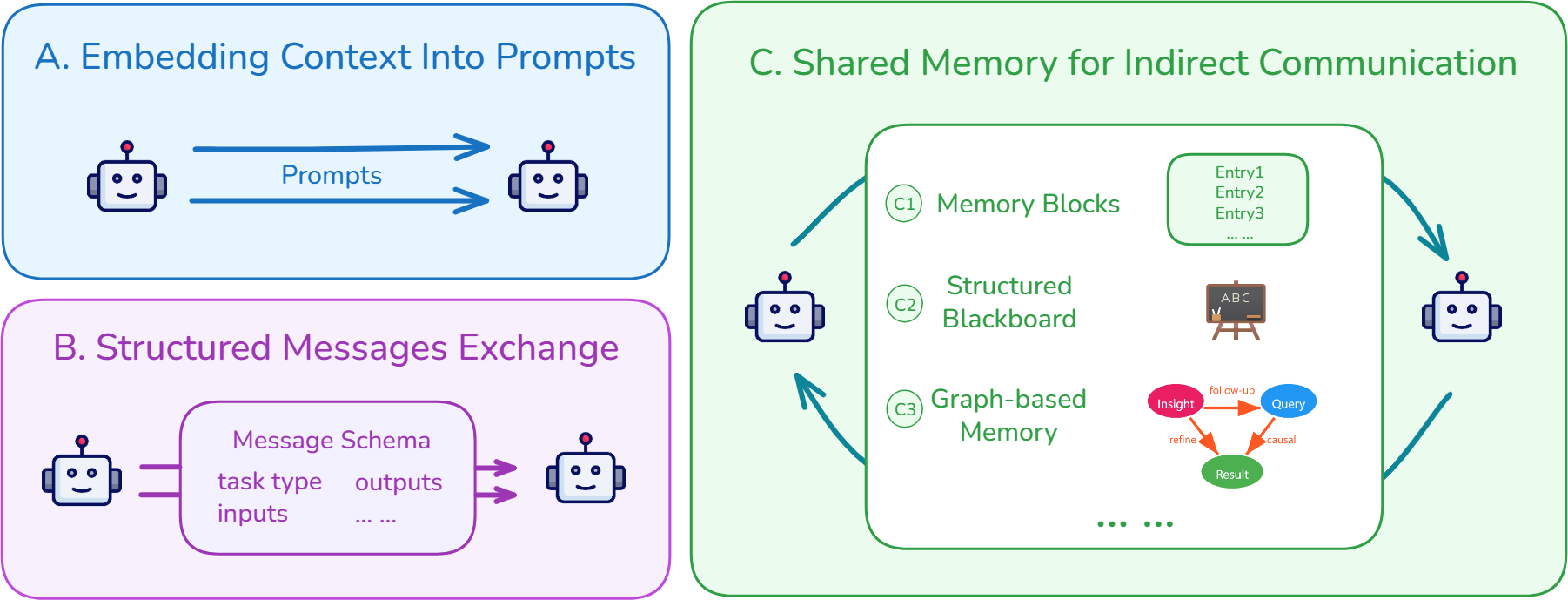
- Context usage: How we pick the right pieces at the right time, share context between agents, and keep long-term memory so tasks can pause and resume smoothly.
4) Practical strategies (explained simply)
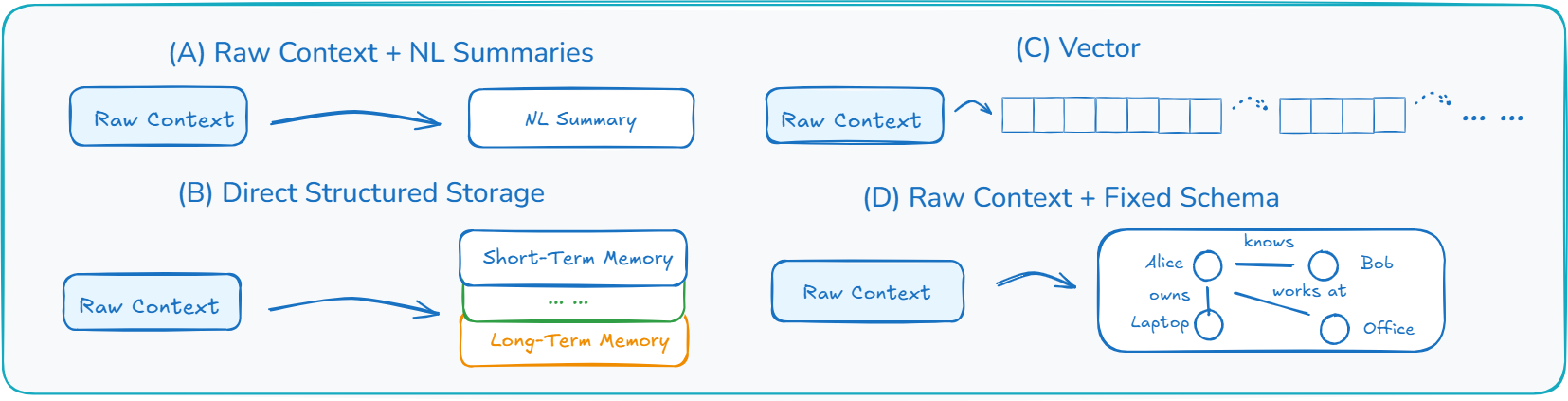
- Storage layers: quick caches for recent stuff, local databases for medium-term notes, cloud for long-term and cross-device sync—balanced with privacy and security.
- Long-term memory for agents: Since chat windows are short, agents periodically write down key facts and steps in external notes or databases, then retrieve them later (like keeping a project journal).
- Text processing approaches:
- Timestamps: keep items in time order—simple, but can get long and messy.
- Tagging: label items by role (goal, decision, action) to make retrieval smarter.
- QA compression: turn info into question–answer pairs for fast lookup (great for FAQs, not for storytelling).
- Hierarchical notes: structured summaries and outlines that keep the big picture and details connected.
5) The shift from rules to teamwork
Old systems reacted to simple signals. New agents read what you’re doing and assist, like noticing the topic of your draft and suggesting the next section. This moves from “if-then rules” to “collaboration.”
What this could mean in the real world
- Smarter helpers: AI assistants that truly follow your goals across days or weeks, remember what matters, and pick up where you left off.
- Less friction: You won’t have to “speak computer.” You can talk and work more naturally, and AI will do more of the organizing.
- Better design playbooks: Builders of AI tools can use these principles to choose what data to collect, how to store it safely, and how to make it useful without overwhelming users.
- Responsible use: Because context can be personal (location, habits, history), systems must protect privacy, ask for consent, and store only what’s needed.
- Long-term teamwork: As AI approaches human-level understanding, it could become a reliable teammate—planning, remembering, and adapting across projects and environments. In the far future, superhuman AI might even suggest contexts we hadn’t thought of, helping us learn new strategies (as seen in games like Go).
In short, the paper gives a clear map and toolset for making AI understand us better by managing the information around our tasks. It connects past lessons to today’s agents and points the way toward safer, smarter, and more helpful systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what the paper leaves missing, uncertain, or unexplored, framed to be concrete and actionable for future research.
- Quantifying “entropy reduction”: No formal, measurable definition connects the paper’s entropy-reduction perspective to Shannon information or task performance; methods to estimate context entropy, redundancy, and utility are absent.
- Context relevance function: The formal definition of context relies on a relevance set without a principled mechanism to compute or learn relevance across entities, modalities, and time.
- Transition criteria across eras: The four-stage evolution (1.0–4.0) lacks operational criteria, capability thresholds, or empirical milestones to determine when a system or ecosystem transitions between stages.
- Metrics for “context tolerance” and human-likeness: No concrete metrics quantify a system’s tolerance for raw, high-entropy context or its human-likeness; benchmarkable definitions and measurement protocols are missing.
- Evaluation benchmarks: The paper does not propose standardized datasets, tasks, or metrics to evaluate context engineering across long-horizon, multi-modal, multi-agent, and real-world scenarios.
- Minimal Sufficiency Principle: No algorithmic method is provided to decide which contextual elements are sufficient for a task; actionable selection criteria and trade-off models (accuracy vs. cost/privacy) are missing.
- Semantic Continuity Principle: The concept is introduced without formal semantics, constraints, or techniques to preserve meaning continuity across storage, compression, and retrieval pipelines.
- Formal composition of context operations: The operator is defined abstractly; guidelines for composing operations (ordering, control flow, policies) and verifying correctness are not specified.
- Context selection and routing policies: How to select, rank, route, and prune context for specific subtasks (e.g., planning vs. execution vs. reflection) is not operationalized or empirically compared.
- Long-term memory design: Concrete algorithms for hierarchical memory (layered caches, TTLs, summarization cadence, recall fidelity, conflict resolution) and their trade-offs are not provided.
- Memory reliability and drift: The paper does not address hallucination propagation, memory drift, interference, or catastrophic forgetting in agent memories, nor mitigation strategies.
- Provenance and auditability: There’s no framework for tracking where context came from, how it was transformed, and what was actually used in decisions (provenance, audit trails, and explainability).
- Robustness and security: Threat models and defenses (prompt injection, RAG poisoning, tool-call abuse, multimodal adversarial inputs, cross-agent attacks) are not analyzed.
- Privacy, consent, and governance: Ethical and legal mechanisms for collecting, storing, sharing, and forgetting sensitive context (differential privacy, consent flows, access control, retention policies) are not specified.
- Cross-agent context sharing: Standards for inter-agent context exchange (schemas, protocols, trust boundaries, consistency guarantees, conflict resolution) are missing.
- System interoperability: No shared representation, ontologies, or adapters are proposed to enable cross-system context exchange beyond isolated examples.
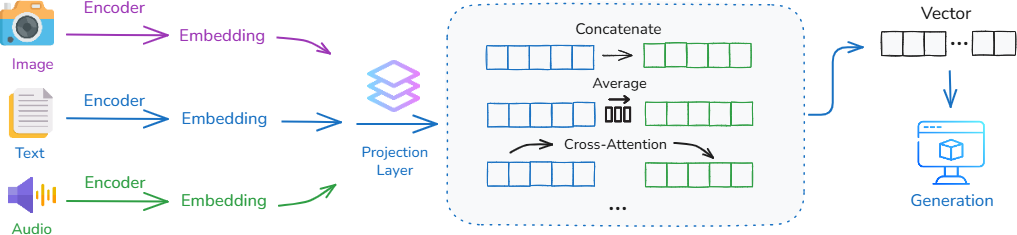
- Multimodal fusion specifics: The paper describes high-level fusion patterns (shared embedding space, cross-attention) but lacks guidance on alignment, temporal synchronization, uncertainty modeling, and modality dominance.
- Resource-cost modeling: There is no model for latency, computational cost, storage footprint, and energy usage of context pipelines, nor for optimizing them under constraints.
- Error handling and recovery: Strategies for partial context failure (missing sensors, stale data, conflicting signals) and graceful degradation are not described.
- User studies and HCI validation: The paper lacks empirical user studies to validate the claimed reduction in human-AI interaction cost and improvements in collaboration quality.
- Adaptive personalization: Concrete approaches to on-device personalization, continual learning, and balancing global vs. local context preferences are not explored.
- Cultural and linguistic variation: There is no discussion of context engineering across languages, cultures, or socio-technical environments, and its impact on relevance, tagging, and interpretation.
- Context lifecycle management: Policies and algorithms for “human-like” forgetting, retention scheduling, context aging, and archival are not formalized.
- Agent introspection and self-correction: Methods for agents to introspect on context use, detect misinterpretation, and self-correct (including uncertainty estimation) are missing.
- Safety in context construction (Era 4.0): The speculative notion that superhuman systems will proactively construct contexts lacks safety frameworks to prevent manipulation, undue influence, or value misalignment.
- Tooling and reproducibility: There is no blueprint for reproducible pipelines (data models, APIs, CI/CD for context, testing harnesses) to standardize engineering practice.
- Comparative analyses: Claims that 2.0 systems exceed 1.0 principles are not backed by systematic comparisons, ablations, or case studies across representative systems/tasks.
- Formal task-outcome linkage: The connection between context operations and downstream task outcomes (accuracy, efficiency, user satisfaction) is not modeled or validated.
- Open datasets: The paper does not propose or curate open datasets capturing realistic, multi-modal, long-horizon contexts to catalyze research and benchmarking.
Practical Applications
Immediate Applications
The following applications can be deployed today using components and workflows described in the paper (prompting, RAG, tool-calling, layered memory, context tagging, hierarchical notes, adapters, multimodal fusion). Each bullet names sectors, suggests tools/products/workflows, and notes assumptions or dependencies.
- Context-aware enterprise copilots for knowledge work (software, professional services, finance, operations)
- What: Deploy “context-cooperative” assistants that use layered memory, functional tagging (“goal/decision/action”), and hierarchical notes to keep long-horizon task context across sessions (e.g., proposal drafting, ticket triage, incident postmortems).
- Tools/Workflows: RAG pipelines (LangChain/LlamaIndex), local state in SQLite/LevelDB, structured notes outside the context window (Claude Code–style), role-based tagging (LLM4Tag-like), adapters to connect CRM/Docs/Chat (Langroid).
- Assumptions/Dependencies: Data governance and access controls; reliable tool-calling; organizational buy-in to “Minimal Sufficiency” and “Semantic Continuity” principles.
- Long-horizon code agents that can pause/resume work (software engineering)
- What: Agents maintain structured external memory of tasks, decisions, and progress to exceed short context-window limits; resume after interruptions (CI fixes, refactors, flaky test isolation).
- Tools/Workflows: Periodic write-out of key state to local DB; task schemas (ChatSchema-like); hierarchical summaries; deterministic tool execution.
- Assumptions/Dependencies: Repository access, safe execution environment, human-in-the-loop review, audit trails.
- Context-cooperative customer support systems (software, telecom, e-commerce)
- What: Bots and human agents share structured context (timeline, tickets, chat, multimodal attachments) to infer intent and next best action.
- Tools/Workflows: Time-stamping, functional tags, QA compression for FAQs, multimodal models (Qwen2-VL) for images/video; agent-to-agent structured messages (Letta/MemOS-like).
- Assumptions/Dependencies: Integration with ticketing/CRM logs; privacy and consent; prompt injection and safety controls.
- Clinician-in-the-loop note compression and patient timelines (healthcare)
- What: Convert fragmented EHR notes and wearable streams into hierarchical summaries and role-tagged timelines for rounds/discharge planning.
- Tools/Workflows: Hierarchical notes and retrieval, layered storage (local+secure cloud), multimodal fusion (text + vitals/waveforms).
- Assumptions/Dependencies: HIPAA compliance, on-device or VPC inference, clinical validation, explicit human oversight.
- Personal learning companions with durable memory (education, daily life)
- What: Assist learners by organizing notes into hierarchical summaries, tagging goals/skills, tracking progress across semesters/sessions.
- Tools/Workflows: Notebook integrations (Obsidian/Notion), external memory for long tasks, role tagging (goal/plan/action), retrieval across sessions.
- Assumptions/Dependencies: Content ingestion permissions, guardrails against hallucinations, alignment with course policies.
- Context-aware home and mobile automations (IoT, robotics, consumer tech)
- What: Use sensor-driven contexts (location, time, device state) and tolerance for raw signals to trigger useful behaviors (driving mode silences phone, home routines adapt to presence).
- Tools/Workflows: Smartphone/wearable sensors, Home Assistant automations, layered memory of preferences.
- Assumptions/Dependencies: Accurate sensing, user consent settings, fail-safe defaults.
- Compliance and audit trails via decision tagging (finance, regulated industries)
- What: Capture “decision/action/rationale” context as structured records for audits and postmortems; reduce entropy, improve traceability.
- Tools/Workflows: Functional tagging, timestamped logs, secure storage (RocksDB/SQLite/HSM-backed), retrieval dashboards.
- Assumptions/Dependencies: Retention policies, explainability requirements, regulator acceptance.
- Research writing co-pilots that reason over evolving drafts (academia, publishing)
- What: Assist with section planning, related work retrieval, and consistency checks by maintaining hierarchical summaries and functional tags across a manuscript’s evolution.
- Tools/Workflows: RAG over local bibliography/corpus, hierarchical note compression, QA pairs for reviewer response generation.
- Assumptions/Dependencies: Citation correctness, disclosure policies, reproducibility standards.
- Multimodal troubleshooting assistants (manufacturing, field service)
- What: Users submit images/audio/video; the system fuses modalities to infer context and guide resolution steps.
- Tools/Workflows: Cross-attention (Qwen2-VL), tool-calling for diagnostics, structured checklists, layered memory of equipment history.
- Assumptions/Dependencies: Availability of multimodal models, robust device capture, safety and liability management.
- Cross-system context adapters (enterprise integration)
- What: Convert and share context objects between heterogeneous agent platforms and applications to reduce lock-in.
- Tools/Workflows: Adapter frameworks (Langroid), shared schemas, message exchange standards, API governance.
- Assumptions/Dependencies: Vendor cooperation, schema versioning, interoperability testing.
Long-Term Applications
These applications require further research, scaling, standardization, and/or technological maturation (e.g., human-level context assimilation, embodied sensing, proactive context construction, governance frameworks).
- Unified personal digital memory with semantic continuity (consumer, OS-level platforms)
- What: A persistent, privacy-preserving cognitive layer that autonomously organizes, refines, “forgets,” and recalls context across devices and time, enabling continuous reasoning and collaboration.
- Tools/Products: OS memory manager, on-device vector stores, secure cloud sync, adaptive compression (meaning vectors, hierarchical notes).
- Assumptions/Dependencies: Standards for consent/portability, secure enclaves, robust long-horizon evaluation, user control UX.
- Proactive needs discovery by superhuman agents (healthcare, finance, productivity)
- What: Agents construct contexts and uncover latent needs (e.g., early health-risk signals, budget vulnerabilities) and guide decisions.
- Tools/Products: Long-horizon planners, causal modeling + context pipelines, safety alignment layers, counterfactual simulators.
- Assumptions/Dependencies: Trust, value alignment, rigorous safety testing, liability frameworks.
- Embodied multimodal perception beyond vision/audio (robotics, industrial safety, food quality)
- What: Integrate touch, smell, taste sensors with cross-modal fusion to detect hazards, assess product quality, and enable fine manipulation.
- Tools/Products: New sensor stacks, cross-attention fusion models, calibration procedures, domain-specific datasets.
- Assumptions/Dependencies: Sensor maturity and reliability, standardized multimodal training, environmental robustness.
- Emotion- and intent-aware interfaces via BCI and physiological sensing (healthcare, accessibility, automotive)
- What: Context-cooperative systems adjust interaction based on neural and physiological cues to reduce cognitive load and improve safety (driver monitoring, adaptive interfaces).
- Tools/Products: Wearables/EEG integrations, privacy-preserving on-device inference, affect detection pipelines.
- Assumptions/Dependencies: Medical-grade validation, regulatory clearance, consent management, bias mitigation.
- Enterprise context fabric and governance (software, compliance, knowledge management)
- What: Shared, governed context layers across teams and tools with provenance, retention, access control, and inter-agent communication norms.
- Tools/Products: Context layer platforms, shared representations (Sharedrop-like), policy engines, audit dashboards.
- Assumptions/Dependencies: Interoperability standards, vendor-neutral schemas, organizational change management.
- Memory embedded into model parameters for durable adaptation (ML systems)
- What: Store selected long-term context directly in model weights to improve continuity and reduce external retrieval reliance while avoiding catastrophic forgetting.
- Tools/Products: Continual learning pipelines, parameter-efficient fine-tuning, memory consolidation algorithms.
- Assumptions/Dependencies: New training recipes, safety and drift monitoring, IP and data governance for embedded memories.
- Verified context-cooperative multi-agent teams (software, operations, research)
- What: Subagents with functional isolation share structured messages and shared memory to deliver complex outputs with formal reliability guarantees.
- Tools/Products: Orchestrators, formal verification layers, simulation/eval harnesses, context-sharing protocols.
- Assumptions/Dependencies: Benchmarks for long-horizon reliability, runtime governance, standardized agent messaging.
- Lifelong learning records integrated with AI tutors (education policy and platforms)
- What: Portable, semantically structured learning histories that enable personalized curricula and fair assessment across institutions.
- Tools/Products: Standardized context schemas, trusted storage, interoperability APIs, self-baking notes for progression.
- Assumptions/Dependencies: Policy harmonization, equity safeguards, cross-institution adoption.
- Continuous, contextualized patient monitoring ecosystems (healthcare)
- What: Fuse home IoT, wearables, EHR, and environmental context for early warnings, care pathway optimization, and patient-specific guidance.
- Tools/Products: Federated learning, clinical-grade context fusion, layered memory of care decisions, explainability UIs.
- Assumptions/Dependencies: Device reliability, interoperability (FHIR extensions), clinical trials, reimbursement models.
- Transportation safety systems with richer driver/passenger context (mobility)
- What: Integrate gaze, behavior, ambient context to prevent fatigue or distraction, and coordinate with in-vehicle agents.
- Tools/Products: Sensor fusion, edge inference, shared memory across sub-systems, policy engines for interventions.
- Assumptions/Dependencies: Automotive-grade hardware, legal frameworks for monitoring, human factors research.
- Context governance and transparency standards (policy, regulation)
- What: Codify “Minimal Sufficiency” and “Semantic Continuity” into data minimization, retention, portability, and disclosure requirements for AI systems.
- Tools/Products: Certification programs, compliance toolkits, audit templates, transparency reporting formats.
- Assumptions/Dependencies: Multilateral regulatory alignment, sector-specific adaptations, enforcement mechanisms.
Notes on Cross-cutting Assumptions and Dependencies
- Model capabilities: Effective deployment depends on LLMs with robust tool-calling, RAG, multimodal inputs, and safe long-horizon reasoning.
- Data quality and integration: Reliable sensors, clean APIs, and unified schemas are essential for low-entropy context transformation.
- Privacy, security, and consent: Many applications hinge on secure storage (local + cloud), OS-backed enclaves, and user-centric controls.
- Evaluation and safety: Long-horizon tasks require new metrics, simulators, and governance to prevent drift, hallucinations, or unsafe actions.
- Interoperability: Adapters and shared representations need open standards to prevent vendor lock-in and ensure agent-to-agent collaboration.
Glossary
- Agent-Centric Intelligence: A stage of machine intelligence characterized by agents that can interpret natural language and handle ambiguity to collaborate with humans. "Agent-Centric Intelligence"
- CoT (Chain-of-Thought prompting): A prompting technique that elicits step-by-step reasoning from models to improve problem solving. "CoT"
- Context-Aware Computing: A computing paradigm where systems sense and adapt to user states, environments, and tasks to adjust behavior dynamically. "Context-Aware Computing"
- context-aware systems: Systems that utilize contextual information (e.g., location, time, activity) to tailor their behavior to the situation. "context-aware systems"
- context-cooperative: An approach where systems not only sense context but actively collaborate with users to achieve shared goals. "context-cooperative"
- context window: The bounded amount of information (tokens/history) a model can attend to at once. "context window"
- cross-attention: A neural attention mechanism where one modality or sequence attends to another to integrate information across inputs. "cross-attention"
- Entropy reduction: Framing context engineering as transforming high-entropy, ambiguous information into lower-entropy representations machines can use. "process of entropy reduction"
- foundation models: Large, general-purpose models trained on broad data that can be adapted to many downstream tasks. "foundation models"
- Human–Agent Interaction (HAI): Interaction paradigms focused on collaboration between humans and intelligent agents. "human-agent interaction (HAI) paradigms"
- Human–Computer Interaction (HCI): The study and design of interfaces and interactions between people and computing systems. "human-computer interaction (HCI) frameworks"
- in-context learning: The ability of models to infer tasks and patterns from examples in the prompt without gradient updates. "in-context learning"
- LLM: A transformer-based model trained on large text corpora to perform diverse language tasks. "LLMs"
- long-horizon tasks: Tasks that require planning, reasoning, or operation over extended time spans or many steps. "long-horizon tasks"
- memory agents: Agents that maintain and utilize external or structured memory to support long-term reasoning and continuity. "memory agents"
- multimodal perception: The capability to process and integrate information from multiple input modalities (e.g., text, image, audio). "multimodal perception"
- prompt engineering: The practice of designing and structuring prompts to guide model behavior and improve outputs. "prompt engineering"
- Retrieval-Augmented Generation (RAG): A method that combines retrieval of relevant documents with generative models to ground responses. "retrieval-augmented generation (RAG)"
- self-attention: A mechanism where a model attends to different positions within the same sequence to capture dependencies. "self-attention"
- Sensor fusion: The integration of data from multiple sensors to produce more reliable or comprehensive context signals. "Sensor fusion"
- tool calling: Allowing agents/models to invoke external tools or APIs to extend capabilities beyond pure text generation. "tool calling"
- Ubiquitous Computing: A vision where computation is embedded seamlessly into everyday environments and activities. "Ubiquitous Computing"
Collections
Sign up for free to add this paper to one or more collections.

