- The paper reveals that state-of-the-art multimodal cancer survival models exhibit systematic probability miscalibration despite high discrimination (C-index).
- It employs fold-level 1-calibration testing using IPCW-weighted Hosmer-Lemeshow statistics to rigorously assess prediction reliability.
- Post-hoc Platt scaling significantly improves calibration without affecting ranking performance, underscoring the need for calibration-aware evaluation.
Calibration Deficits in Multimodal Cancer Survival Models: A Systematic Fold-Level Audit
Introduction
Multimodal deep learning architectures, leveraging the joint representation of whole-slide histopathology images (WSI) and genomic profiles, now demonstrate substantial gains in the concordance index (C-index) for cancer survival prediction across The Cancer Genome Atlas (TCGA) cohorts. However, C-index solely quantifies ranking capability without assessing the reliability of the assigned survival probabilities. This distinction epitomizes a fundamental risk for translational medicine, as decision-critical scenarios demand not only correct risk stratification but also well-calibrated event probabilities. The paper "Good Rankings, Wrong Probabilities: A Calibration Audit of Multimodal Cancer Survival Models" (2604.04239) executes a systematic fold-level 1-calibration audit across leading multimodal survival models, providing a formal evaluation of probability reliability and investigating post-hoc recalibration strategies.
Experimental Design and Audit Protocol
The work undertakes two major experimental protocols. Experiment A directly audits the native discrete-time survival outputs of SurvPath, MCAT, and MMP—representative multimodal models—trained on TCGA-BRCA. Model predictions are subjected to fold-level 1-calibration testing via the IPCW-weighted Hosmer-Lemeshow statistic at the median event time, with Benjamini-Hochberg FDR control to mitigate multiple testing. Experiment B analyzes 11 architectures across five TCGA cancer types, utilizing Breslow-reconstructed curves from models' scalar risk scores. While robust, this protocol aligns with standard evaluation but introduces a proportional-hazards assumption in survival curve reconstruction.
Both experiments emphasize discipline in per-fold analysis, avoiding pooled validation that can confound calibration results. Controls include a regularized Cox-PH model as a positive calibration reference and prediction permutation as a negative control.
Key Findings
Systematic Miscalibration of Modern Deep Survival Models
In Experiment A, all three evaluated models (SurvPath, MCAT, MMP) fail 1-calibration on the majority of cross-validation folds. The failures persist after correcting for multiple comparisons, establishing strong evidence of systematic probability miscalibration. Notably, Cox-PH, serving as a positive control, tracks the diagonal in calibration curves, while deep models deviate markedly—especially MCAT and SurvPath, which tend to overestimate risk in mid-range probability bins (Figure 1).
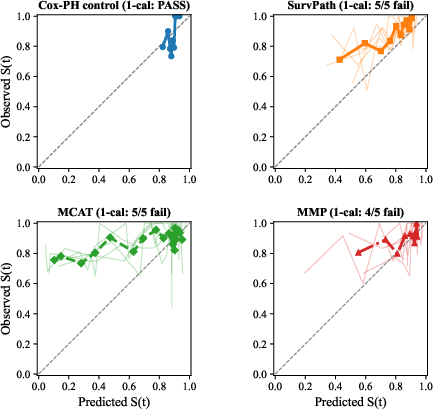
Figure 1: Calibration curves on TCGA-BRCA at median event time (∼42 months); Cox-PH is well-calibrated while deep models exhibit systematic deviation.
Discrimination and Calibration are Decoupled
The benchmarking in Experiment B validates and extends these observations to a diverse model and cancer type context. Out of 290 fold-level calibration tests, 166 reject the null of proper calibration after FDR correction. GBMLGG, for example, manifests the starkest miscalibration rates despite MCAT achieving a mean C-index of 0.817—the highest discrimination among all evaluated combinations (Figure 2). Thus, superior ranking does not imply probability accuracy.
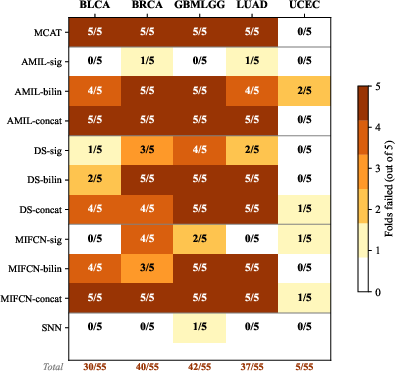
Figure 2: 1-calibration failure rates across models and cancer types; GBMLGG is highly miscalibrated despite best discrimination.
Moreover, fusion strategies exhibit pronounced impact: gating-based architectures demonstrate substantially improved calibration versus bilinear and concatenation alternatives, seen consistently within base architecture families. The genomics-only SNN baseline suffered minimal failures, localizing the problem squarely within complex multimodal fusion mechanisms.
Visualizing Calibration: Heterogenous Cancer Cohorts
Calibration curves contrasted across cancer types and architectures further highlight the heterogeneity induced by model choice and underlying censored event structure. UCEC, a cohort underpowered by low event counts, clusters models near perfect calibration not by performance, but due to reduced statistical power to detect deviations (Figure 3).
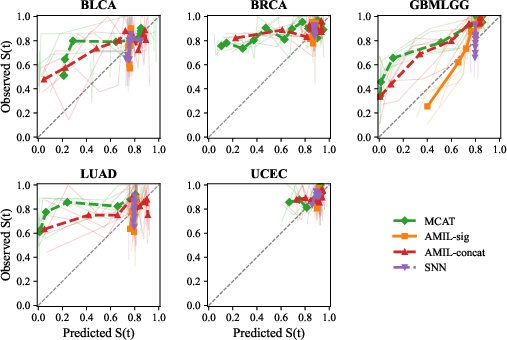
Figure 3: Calibration curves across five TCGA cancer types; GBMLGG shows dramatic deviation while UCEC appears deceptively well-calibrated due to limited events.
Post-hoc Recalibration and Corrective Strategies
Post-hoc Platt scaling demonstrably mitigates fold-level calibration failures in Experiment A, reducing the number of failed folds from 5/5 to as low as 1/5 for SurvPath and MCAT without measurable impact on discrimination (C-index) or rankings (Figure 4). This confirms that much of the miscalibration at the median event horizon is correctable via modest, monotonic probability transformation post-training.
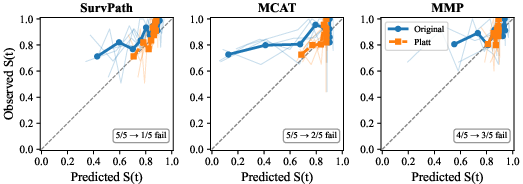
Figure 4: Calibration curves before (blue) and after (orange) Platt scaling; clear fold-level improvement is annotated, especially for MCAT.
Attempts at isotonic regression provided no substantive benefit, likely due to sample restrictions. These results collectively suggest that systematic errors in the probability mapping, rather than stochastic or representation-level flaws, dominate miscalibration at the evaluated time points.
Theoretical and Practical Implications
- Separation of discrimination and calibration: High C-index can coexist with poor probability calibration in multimodal survival models. Exclusive optimization and reporting of ranking metrics has fostered a blind spot, misaligning with regulatory and clinical expectations for trustworthy probability estimates.
- Architectural tradeoffs: Fusion mechanisms play a pivotal, underappreciated role in calibration. Gating-based fusion moderates probability distortion relative to more expressive fusion schemes (bilinear, concatenation), possibly due to their restricted parameterization, though causal mechanisms remain to be elucidated.
- Auditing and clinical deployment: The findings argue convincingly for systematic calibration auditing using per-fold, horizon-specific tests before deploying any survival model in a clinical setting. Post-hoc recalibration offers a practical, computationally lightweight remediation step, though it should be horizon-aware and its efficacy across time intervals needs further validation.
- Recommendations for future models: Three practical recommendations follow—report calibration metrics routinely, apply horizon-specific post-hoc recalibration prior to clinical use, and develop/optimize models using calibration-aware loss functions.
- Alignment with regulatory trends: The study’s emphasis aligns with recent regulatory guidance (e.g., FDA AI/ML draft recommendations), indicating calibration and uncertainty as critical dimensions for performance validation in higher-risk AI-enabled devices.
Limitations and Future Directions
The Breslow reconstruction used in Experiment B may confound model- and method-induced miscalibration, given possible proportional hazards violations by deep nonlinear models. Calibration analysis, focused on a single event horizon, may mask time-dependent artifacts, warranting interval-wise calibration auditing. The reliance on hypothesis testing obscures granular calibration error magnitude, and the high-censoring, low-event nature of biomedical cohorts constrains statistical power. Further integration of continuous calibration error metrics, cross-institutional generalization analysis, and prospective application of calibration-aware penalties (e.g., X-CAL) are natural extensions.
Conclusion
Across 290 fold-level calibration tests on state-of-the-art multimodal WSI-genomics survival architectures, systematic miscalibration is the norm, not the exception. This miscalibration persists irrespective of strong patient-level ranking and manifests robustly across models, fusion architectures, and cancer types. Gating-based fusion schemes confer notable calibration advantages, and post-hoc Platt scaling consistently ameliorates probability deficits at clinically relevant horizons. These outcomes underscore critical gaps in current evaluation norms and illuminate a roadmap toward trustworthy clinical AI: calibration must join discrimination as a first-class evaluation objective for survival prediction models, particularly in high-stakes domains such as oncology.