4C4D: 4 Camera 4D Gaussian Splatting
Abstract: This paper tackles the challenge of recovering 4D dynamic scenes from videos captured by as few as four portable cameras. Learning to model scene dynamics for temporally consistent novel-view rendering is a foundational task in computer graphics, where previous works often require dense multi-view captures using camera arrays of dozens or even hundreds of views. We propose \textbf{4C4D}, a novel framework that enables high-fidelity 4D Gaussian Splatting from video captures of extremely sparse cameras. Our key insight lies that the geometric learning under sparse settings is substantially more difficult than modeling appearance. Driven by this observation, we introduce a Neural Decaying Function on Gaussian opacities for enhancing the geometric modeling capability of 4D Gaussians. This design mitigates the inherent imbalance between geometry and appearance modeling in 4DGS by encouraging the 4DGS gradients to focus more on geometric learning. Extensive experiments across sparse-view datasets with varying camera overlaps show that 4C4D achieves superior performance over prior art. Project page at: https://junshengzhou.github.io/4C4D.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “4C4D: 4 Camera 4D Gaussian Splatting”
1) What is this paper about?
This paper is about recreating moving 3D scenes (think: a person dancing or a toy being moved) from videos, so you can look at the scene from any angle and at any moment in time. The twist: instead of needing lots of cameras (like 20–100), the authors show how to do this with just four portable cameras.
“4D” here means 3D space plus time. “Gaussian splatting” is a way to build a scene from lots of tiny, soft, see‑through blobs that together form shapes and colors you can render into images.
2) What questions are the authors trying to answer?
- Can we capture high‑quality, time‑changing 3D scenes (4D) using only four cameras?
- Why do existing methods struggle with so few cameras, and how can we fix that?
- Can we make the reconstructed scenes look good from new viewpoints and remain stable over time?
In simpler words: “How can we make good 3D‑plus‑time models from just a handful of videos, so anyone with a few phones or action cams can do it?”
3) How do they do it (in everyday terms)?
First, a quick idea of “Gaussian splatting”:
- Imagine building a 3D scene out of countless tiny, fuzzy dots (like spray‑paint speckles). Each dot has a position, size, direction, color, and see‑through‑ness (opacity).
- To make an image, you “splat” these dots onto the screen. Lots of dots together form shapes and textures.
- “4D Gaussian splatting” means those dots can move and change over time.
The problem with just four cameras:
- With only a few views, it’s easy for the computer to match how the scene looks (colors) in those views but get the actual shape (geometry) wrong. That can look fine from the training cameras but weird from new angles.
Their key idea: a “Neural Decaying Function” for opacity
- Opacity is how solid each dot is. If a dot’s opacity is too high in the wrong place, it can fake good colors but hide a bad shape.
- The authors add a small neural network that decides how much each dot’s opacity should “decay” (fade). This steers the learning to focus more on getting the shape right, not just the colors.
- Think of a teacher telling which dots should fade if they don’t fit a consistent shape across views and time, helping the model build a better 3D structure.
Visibility‑aware training
- Another clever bit: only adjust (decay) the dots the current camera can actually see at that moment in time. For dots that are invisible right now, they use a gentle, constant fade.
- This prevents the model from making random changes to parts it can’t currently observe, keeping training stable.
Put simply:
- Build the scene from soft dots that move over time.
- Use a smart “fade controller” to make the training care more about correct shape.
- Only actively adjust dots you can see; lightly fade the ones you can’t.
4) What did they find, and why does it matter?
Across several datasets (indoor and outdoor scenes, people dancing, self‑captured with four action cameras), their method:
- Produces cleaner shapes and fewer artifacts, especially when viewing the scene from new angles.
- Keeps the scene consistent over time (less flicker and “jitter”).
- Beats other top methods on standard quality measures (like PSNR and LPIPS), even though it uses only four cameras.
In short: better, more stable 4D results from fewer cameras.
5) Why is this important?
- More accessible 4D capture: This could let small studios—or even friends with a few phones—create VR scenes, game assets, or film effects without expensive camera rigs.
- Real‑time friendly: Because Gaussian splatting is efficient, these reconstructions can be rendered quickly, which is great for interactive uses like VR/AR.
- Stronger geometry from sparse views: Their idea (focus learning on shape by controlling opacity) could help other 3D/4D methods that struggle with limited camera angles.
Overall, 4C4D shows a practical path to bringing high‑quality 4D scene capture out of research labs and into everyday creative projects.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what the paper does not address, remains uncertain about, or leaves unexplored, phrased to guide actionable future research.
- Camera requirements and robustness
- Assumes accurate intrinsics/extrinsics and frame-level synchronization; robustness to pose errors, rolling shutter, time desynchronization, and exposure/white-balance differences is not evaluated.
- Generalization to moving/handheld cameras (vs. fixed rigs) is not discussed; it is unclear whether 4C4D supports jointly optimizing unknown, time-varying camera poses.
- Data assumptions and evaluation protocol
- For Dyn4Cam (true 4-camera capture), only qualitative results are shown; no quantitative protocol (e.g., leave-one-camera-out, temporal holdout) is provided to objectively measure performance in real sparse capture.
- Minimal camera count is not characterized; it is unknown how performance degrades with 3, 2, or single-view inputs, or the minimum overlap needed for stable reconstruction.
- The impact of camera overlap is claimed but not systematically analyzed (no controlled study relating overlap/baseline to accuracy and stability).
- Visibility detection and occlusion handling
- Visibility detection uses frustum/center tests and temporal duration; it does not model occlusions or depth ordering. The consequences on misclassification (e.g., self-occlusions) and potential remedies (e.g., rasterization-based occlusion queries) are not studied.
- The constant decay for “invisible” Gaussians (β=0.999) is fixed a priori; no sensitivity analysis, learning-based alternative, or scene-adaptive strategy is provided.
- Neural Decaying Function (design and scope)
- The decay factor τ is predicted from static Gaussian attributes (x, y, z, o, r) and is not conditioned on time, view, or local photometric/visibility evidence; thus it cannot adapt per-timestep, per-view, or per-occlusion state.
- Architectural details (capacity, normalization, regularization) and training stability of the decay network are under-specified; potential overfitting or degenerate solutions (e.g., excessive opacity suppression) are not analyzed.
- No theoretical analysis or gradient-level diagnostics are provided to substantiate the claim that opacity decay “redistributes” gradients toward geometry; an explicit derivation or controlled gradient study is missing.
- Losses, priors, and supervision
- Optimization relies on photometric losses only; no explicit geometric priors (e.g., depth/surface smoothness, normal/flow consistency, Eikonal constraints) are incorporated or evaluated for sparse-view stabilization.
- Temporal consistency is asserted qualitatively but not quantified (e.g., via warping errors, tOF/tLPIPS, flicker metrics); trade-offs between per-frame PSNR and temporal stability remain unclear.
- No robustness study to illumination changes (auto-exposure, specularities, cast shadows) is presented; photometric calibration or reflectance/lighting disentanglement is not addressed.
- Representation and modeling capacity
- The 4D appearance model (Fourier-in-time SH) may bias toward periodic signals; limitations for strongly aperiodic or abrupt appearance changes (e.g., flashing lights) are not examined.
- Handling of topology changes, thin structures, and extreme non-rigid motions (fluids, deformable cloth) is not evaluated; failure cases and limits of the opacity-decay strategy are not documented.
- Static/dynamic background separation is not modeled; how the method behaves with dynamic backgrounds (e.g., trees in wind, crowds) is unclear.
- Scalability and efficiency
- Training/inference time, memory footprint, and Gaussian count scaling with sequence length are not reported; feasibility for long sequences or high-resolution captures is unknown.
- Real-time rendering performance with the added decay module and visibility logic is not benchmarked; overhead vs. vanilla 4DGS remains unquantified.
- Initialization and pipeline dependencies
- Initialization strategy for Gaussians (e.g., SfM points, depth priors) under sparse views is not detailed; sensitivity to poor/barely convergent initialization is untested.
- The pipeline appears to depend on precomputed, reliable camera calibrations; end-to-end joint calibration and 4D reconstruction is not explored.
- Generalization and transfer
- Cross-dataset generalization of the learned Neural Decaying Function (e.g., training on one scene and applying to another) is not studied; it is unclear whether τ captures reusable priors or remains scene-specific.
- Adaptation to multi-spectral or event cameras, or fusion with auxiliary sensors (IMU, depth, LiDAR) to further aid geometry under sparse views is not investigated.
- Hyperparameters and reproducibility
- Critical hyperparameters (network size for fθ, learning rates, decay schedules, pruning/splitting policies, β sensitivity) are not fully specified; ablations cover only a subset (constant/power/exp decay), leaving many knobs uncharacterized.
- Broader failure and stress testing
- No stress tests on severe occlusions, extremely unbalanced exposure across views, or heavy motion blur are reported; robustness envelopes and failure modes remain unknown.
Practical Applications
Overview
Based on the paper’s contributions—enabling high‑fidelity 4D dynamic scene reconstruction from as few as four cameras via a Neural Decaying Function on Gaussian opacities and a visibility‑aware decay strategy—below are concrete, real‑world applications, organized by deployment horizon. Each item notes relevant sectors, potential tools/workflows/products, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed now using existing cameras (e.g., GoPros, smartphones), standard multi‑view calibration/synchronization pipelines, GPU compute, and the 4C4D training workflow (offline).
- Low‑cost volumetric capture for indie film, commercials, and short‑form media
- Sectors: Media/entertainment, advertising
- What: Record actors or props with four portable cameras to produce dynamic 3D sequences for free‑camera shots, relighting, or post‑production composites.
- Tools/workflows: “4C4D Capture Kit” (four cameras + checkerboard/AprilTag calibration + time sync via timecode/clap/light flash) → 4C4D training → export splats/meshes to Unreal/Unity via a “Splat2Engine” plugin.
- Assumptions/dependencies: Accurate intrinsics/extrinsics and time sync; sufficient camera overlap; adequate GPU for training; offline processing time.
- VR/AR asset creation from sparse rigs
- Sectors: XR (VR/AR), game development
- What: Capture dynamic characters or set pieces for interactive experiences and real‑time playback in engines.
- Tools/workflows: 4C4D → rasterized splat playback in‑engine or mesh extraction (Poisson/screened Poisson) → material baking.
- Assumptions/dependencies: Engine support for splats or mesh conversion; texture richness; quality may drop with fast motions or severe occlusions.
- Sports coaching and biomechanics analysis (offline)
- Sectors: Sports, human performance, research
- What: Four‑camera capture of athletes for 3D replay and qualitative motion assessment from arbitrary angles.
- Tools/workflows: 4C4D → depth/geometry → optional skeleton fitting or surface tracking → kinematic insights for coaching.
- Assumptions/dependencies: Indoor/outdoor calibration; controlled capture volume; downstream pose estimation tools; privacy/consent.
- Dance/choreography rehearsal review
- Sectors: Performing arts, education
- What: Multi‑dancer sequences captured with four cameras for spatially aware review and staging from any viewpoint.
- Tools/workflows: Portable rig + 4C4D → tablet/desktop viewer with time‑synced multi‑angle playback.
- Assumptions/dependencies: Space for rig placement and overlap; offline compute.
- Cultural heritage performance digitization
- Sectors: Museums, archives, cultural documentation
- What: Capture dynamic performances for preservation and VR exhibits without large camera arrays.
- Tools/workflows: Field‑deployable four‑camera rig + 4C4D → archival formats (splat or mesh).
- Assumptions/dependencies: Controlled lighting improves quality; consent and rights management.
- Robotics and simulation dataset generation (dynamic scenes)
- Sectors: Robotics, autonomous systems, simulation
- What: Create realistic 4D assets of moving humans/objects for sim testbeds (e.g., ROS/Isaac).
- Tools/workflows: 4C4D → export textured splats/meshes → import into simulators for perception/control validation.
- Assumptions/dependencies: Sufficiently clean geometry; conversion tools to simulator formats; compute resources.
- E‑commerce and fashion motion showcases
- Sectors: Retail/fashion, marketing
- What: Dynamic 3D product demos (e.g., garments in motion) for web/AR viewers.
- Tools/workflows: Four‑camera capture + 4C4D → web‑ready splat/mesh streaming; optional 2D renders for conventional platforms.
- Assumptions/dependencies: Web viewer support; privacy for models; lighting control.
- Academic teaching and research in graphics/vision
- Sectors: Academia
- What: Low‑cost labs and coursework on dynamic novel view synthesis and 4D reconstruction.
- Tools/workflows: Student kits (phones/GoPros), open‑source 4C4D pipeline, curriculum modules on calibration and splatting.
- Assumptions/dependencies: Access to GPUs; reproducible datasets (e.g., Dyn4Cam‑style captures).
- Security and retail analytics in controlled spaces (post‑event)
- Sectors: Security/public safety, retail operations
- What: Post‑hoc 3D reconstructions of incidents in stores or facilities with four planned, calibrated cameras.
- Tools/workflows: Pre‑installed four‑camera layout with known extrinsics → 4C4D reconstruction for internal review.
- Assumptions/dependencies: Pre‑calibrated cameras and sync; consent/compliance; limited to controlled environments.
- Content moderation and quality control for 4D assets
- Sectors: Media platforms, tool vendors
- What: Visibility‑aware QA tools to diagnose geometry vs. appearance imbalance, leveraging the paper’s visibility detection.
- Tools/workflows: “Visibility Heatmap” diagnostics during training; flags areas with low gradient signal or overfitting.
- Assumptions/dependencies: Integration into training UI; access to training metadata.
Long‑Term Applications
These require further research (e.g., real‑time/online optimization), broader tooling, standardization, or integration into products and ecosystems.
- Near‑real‑time volumetric telepresence with sparse rigs
- Sectors: Communications, XR collaboration
- What: Live 3D streaming of people with four cameras for meetings/events.
- Tools/workflows: Online/streaming 4C4D with incremental updates; edge compute; network streaming of splats.
- Assumptions/dependencies: Fast online training/updates (beyond current offline); bandwidth‑efficient splat codecs; latency constraints.
- Consumer multi‑phone capture app for 4D memories
- Sectors: Consumer apps, social media
- What: Ad‑hoc phone swarm captures family events; cloud processes into shareable 4D posts.
- Tools/workflows: App to auto‑sync via audio/Wi‑Fi/UWB, auto‑calibrate with AR markers, cloud 4C4D, viewer for interactive playback.
- Assumptions/dependencies: Robust auto‑sync and self‑calibration; easy UX; privacy/consent flows; server costs.
- Markerless motion capture alternative in studios
- Sectors: Film/VFX, game dev, sports science
- What: Replace large MoCap arrays with four‑camera volumetric recon + learned motion priors for skeleton extraction.
- Tools/workflows: 4C4D + human motion priors for tracking; export to FBX for DCC tools.
- Assumptions/dependencies: Strong priors for occlusion/fast motion; accuracy validation vs. Vicon; lighting and wardrobe constraints.
- Broadcast‑grade volumetric replays with sparse cameras
- Sectors: Sports broadcasting, live events
- What: Near‑live free‑viewpoint replays from only a few broadcast cameras around the field/stage.
- Tools/workflows: Low‑latency 4C4D pipeline; edge GPUs at venue; editorial tools for camera path authoring.
- Assumptions/dependencies: Tight sync/timecode; fast processing; robust outdoors performance under variable lighting.
- Tele‑rehabilitation and remote gait/mobility assessment
- Sectors: Healthcare
- What: Four‑camera home or clinic setup for clinicians to examine patient movement in 3D remotely.
- Tools/workflows: Patient capture kit + encrypted cloud 4D processing + clinician 3D viewer; optional automatic metrics.
- Assumptions/dependencies: Clinical validation; HIPAA/GDPR compliance; reliability and safety; integration with EHR.
- Dynamic digital twins and training data for autonomous systems
- Sectors: Mobility, smart cities, robotics
- What: Capture real pedestrians/objects to populate simulation and digital twins with realistic dynamics.
- Tools/workflows: Outdoor four‑camera nodes deployed at intersections → 4C4D → assets for AV/robotics sim.
- Assumptions/dependencies: Outdoor calibration at scale; privacy and anonymization; weather/lighting robustness.
- On‑device or edge‑accelerated 4D capture
- Sectors: Mobile hardware, edge computing
- What: Hardware acceleration for splat rendering/training to enable portable, low‑power 4D capture.
- Tools/workflows: Dedicated GPU/NPUs; optimized splat rasterization and gradient pipelines; compressed 4D representations.
- Assumptions/dependencies: Vendor support; standard APIs; research into memory/bandwidth‑efficient updates.
- Standards and policy for volumetric capture and consent
- Sectors: Policy/regulation, industry consortia
- What: Guidelines for consent, privacy, watermarking, storage, and distribution of 4D assets captured in public/consumer contexts.
- Tools/workflows: Opt‑in signage and digital consent, dataset governance frameworks, interoperable 4D formats for rights management.
- Assumptions/dependencies: Multi‑stakeholder coordination; legal harmonization across regions.
- Real‑time environment modeling for robots with minimal cameras
- Sectors: Robotics, industrial automation
- What: On‑the‑fly 4D recon of dynamic workcells for safety and planning using only a handful of cameras.
- Tools/workflows: Online 4C4D updates; fusion with depth/LiDAR; planners consuming splat‑derived geometry.
- Assumptions/dependencies: Low‑latency gradients and updates; sensor fusion; strict safety certification.
- Scalable 4D educational content platforms
- Sectors: Education, EdTech
- What: Teachers capture lab demos/experiments in 4D for remote classes; students explore from any angle.
- Tools/workflows: Classroom four‑camera kits, guided capture app, LMS integration with interactive viewers.
- Assumptions/dependencies: Simplified workflows; content hosting/CDN for 4D media; accessibility features.
Cross‑cutting Assumptions and Dependencies
- Capture prerequisites: At least four cameras with sufficient field‑of‑view overlap; accurate calibration (intrinsics/extrinsics) and time synchronization; stable camera placement to reduce motion blur and rolling shutter artifacts.
- Compute and latency: Offline training on modern GPUs is currently expected; live/interactive use cases need further advances in online optimization and hardware acceleration.
- Scene/lighting conditions: Texture‑rich surfaces and moderate motion yield best results; very fast motion, severe occlusion, and extremely low overlap remain challenging.
- Toolchain integration: Exporters to standard engines (Unreal/Unity), simulators (ROS/Isaac), and DCC tools (Maya/Blender) improve adoption.
- Legal/ethical: Consent, privacy, and rights management for volumetric data (especially in public or healthcare scenarios) must be addressed before deployment at scale.
These applications leverage the paper’s core innovation—opacity‑focused, visibility‑aware optimization that improves geometry learning in sparse‑view 4D Gaussian Splatting—reducing hardware costs and broadening where dynamic 3D capture can be used.
Glossary
- 3D Gaussian Splatting (3DGS): A real-time view-synthesis representation that models scenes with explicit 3D Gaussian primitives and renders them via rasterization. "3D Gaussian Splatting (3DGS) \cite{kerbl20233dgs} represents scenes with explicit graphic primitives, enabling real-time photorealistic rendering through rasterization."
- 4C4D: The proposed framework for high-fidelity 4D Gaussian Splatting from as few as four cameras in sparse setups. "We propose 4C4D, a novel framework that enables high-fidelity 4D Gaussian Splatting from video captures of extremely sparse cameras."
- 4D covariance matrix: The covariance describing a Gaussian’s spatial-temporal shape, factored into scale and rotation matrices. "4DGS formulates the 4D covariance matrix as , which can be factored in to a scale matrix and a rotation matrix ."
- 4D Gaussian Splatting (4DGS): A dynamic scene representation that attaches time-aware attributes to Gaussian primitives for 4D view synthesis. "4D Gaussian Splatting (4DGS) represents a dynamic 4D scene using a set of Gaussians, each parameterized by attributes that model the time-varying geometry and appearance of the scene."
- 4D spherical harmonics coefficients: Time-aware spherical harmonics parameters used to model view- and time-dependent appearance. "In addition to the above geometric attributes, 4DGS models the appearances of each Gaussian using 4D spherical harmonics coefficients ."
- Ablation study: An experimental analysis that removes or alters components to assess their impact on performance. "we conduct a series of ablation studies on the representative data in Neural3DV dataset"
- Appearance decoding: Neural processing that decodes visual appearance from learned features. "ST-GS~\cite{li2024spacetime} employs a hybrid scheme that combines temporally aware Gaussian representations with neural network-based appearance decoding."
- Compact feature planes: Low-dimensional plane-based feature representations for efficient dynamic scene modeling. "HexPlane~\cite{cao2023hexplane} and K-Planes~\cite{fridovich2023k} advance volumetric representations with compact feature planes, achieving faster dynamic NeRF training."
- Deformation fields: Learned fields that map static Gaussians to dynamic positions over time. "Works such as Deformable-3DGS~\cite{yang2024deformable} and 4DGaussians~\cite{wu20244d} adopt plane-featureâbased architectures similar to dynamic NeRFs to model Gaussian deformation fields."
- Diffusion-based priors: Generative priors learned via diffusion models used to regularize or guide reconstruction. "Diffuman4D~\cite{jin2025diffuman4d} leverages diffusion-based priors for improved human motion modeling."
- Dynamic scene modeling: The task of representing and reconstructing scenes that evolve over time. "a series of works~\cite{pumarola2021d,park2021nerfies,park2021hypernerf,li2022neural,fridovich2023k} extend Neural Radiance Fields to dynamic scene modeling by incorporating time awareness into the network."
- Fourier series: A periodic function expansion used here to parameterize time-varying appearance. "and donates the order of the Fourier series."
- Gaussian primitives: Explicit anisotropic Gaussian elements that represent scene content for splatting-based rendering. "Recently, 3D Gaussian Splatting (3DGS)~\cite{kerbl20233dgs} has been proposed, advancing novel view synthesis by enabling real-time rendering through rasterization of explicit Gaussian primitives."
- Gradient backpropagation: The optimization mechanism for training neural components and Gaussian parameters with differentiable losses. "During training, both the Neural Decaying Function and the 4D Gaussians are jointly optimized via gradient backpropagation under a photometric rendering loss."
- LPIPS: A learned perceptual metric for image similarity that correlates with human judgment. "LPIPS measures perceptual similarity between images, and lower values indicate better perceptual quality."
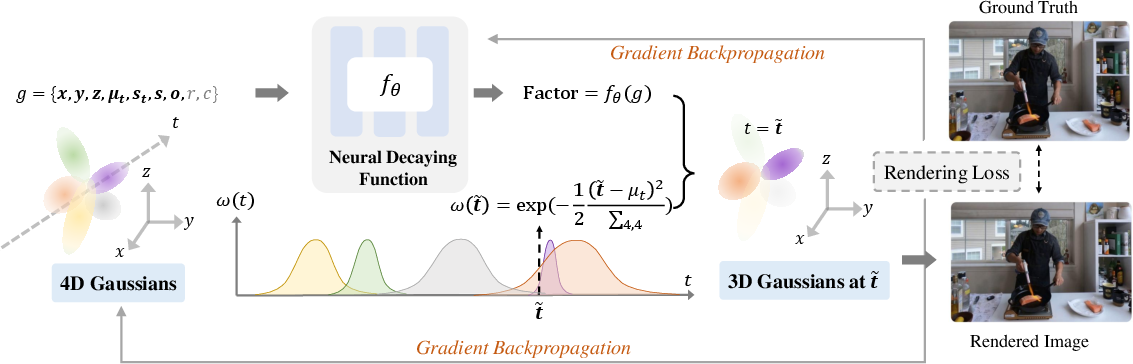
- Neural Decaying Function: A learnable module that adaptively modulates Gaussian opacities to rebalance geometry vs. appearance learning. "we propose the Neural Decaying Function, a novel mechanism implemented with neural networks that adaptively controls the decay of Gaussian opacities."
- Neural Radiance Fields (NeRF): A neural volumetric representation that performs view synthesis by volume rendering a learned radiance field. "NeRF achieves high-quality novel view synthesis by performing volume rendering over view-dependent attributes predicted by a neural networkâbased function."
- Novel view synthesis: Generating images from viewpoints not seen during training. "Novel view synthesis of dynamic scenes is a vital task towards achieving 4D intelligence in various applications"
- Photometric rendering loss: An image-space error used to supervise reconstruction by comparing rendered and ground-truth images. "jointly optimized via gradient backpropagation under a photometric rendering loss."
- Plane-feature–based architectures: Representations that store features on planes and query them for efficient dynamic modeling. "Works such as Deformable-3DGS~\cite{yang2024deformable} and 4DGaussians~\cite{wu20244d} adopt plane-featureâbased architectures similar to dynamic NeRFs"
- PSNR: A pixel-wise signal-to-noise metric used to evaluate rendering fidelity. "PSNR is the most commonly used pixel-wise metric that measures the per-pixel difference between the rendered image and the ground-truth image."
- Rasterization: A graphics pipeline operation to project and render primitives efficiently on the image plane. "enabling real-time photorealistic rendering through rasterization."
- Separate decay strategy: A visibility-aware scheme that applies different opacity decays to visible and invisible Gaussians to stabilize training. "We then apply only to the visible regions while adopting a separate decay strategy for invisible 4D Gaussians."
- Temporal attributes: Time parameters (e.g., center time and duration) controlling when a 4D Gaussian is active and how it evolves. "and the temporal attributes and , which define the timestep and duration of the 4D Gaussian, respectively."
- Temporal conditioning: Injecting time as a conditioning signal into representations to model dynamics. "DyNeRF~\cite{li2022neural} introduces temporal conditioning into NeRF representations, enabling dynamic scene synthesis with radiance fields."
- Temporal opacity factor: A time-dependent scalar that modulates a Gaussian’s opacity across frames. "where represents a temporal opacity factor that controls the impact of each 4D Gaussian over time."
- Temporal span: The duration over which a Gaussian contributes to the scene. " considers the temporal span of each Gaussian and filters out those Gaussians whose duration does not include ."
- Time-aware attributes: Gaussian parameters that explicitly encode temporal behavior for dynamic representation. "4D Gaussian Splatting (4DGS)~\cite{yang2023real} introduces a more direct dynamic representation by embedding time-aware attributes into Gaussian primitives."
- Time intersection: The temporal criterion used to determine if a Gaussian is active at a given time. "visibility detection based on view intersection and time intersection"
- View-dependent attributes: Appearance features that vary with viewing direction, enabling specular and anisotropic effects. "performing volume rendering over view-dependent attributes predicted by a neural networkâbased function."
- View intersection: The geometric criterion to test if a Gaussian is within a camera’s view frustum or contributes to the current image. "visibility detection based on view intersection and time intersection"
- Visibility-aware masking: A training mechanism that masks or separates Gaussians by visibility status for stability. "by disabling the visibility-aware masking and applying the same decay function uniformly to all regions"
- Visibility detection: Identifying which Gaussians are visible in a given view and time to guide training and decay application. "we introduce a visibility detection strategy that operates in both spatial and temporal domains to identify visible 4D Gaussians at the current view and timestep."
- Volumetric representations: 3D (or 4D) scene encodings that model density/radiance throughout space for rendering. "HexPlane~\cite{cao2023hexplane} and K-Planes~\cite{fridovich2023k} advance volumetric representations with compact feature planes"
- Volume rendering: Integrating color and density along camera rays through the volume to synthesize images. "NeRF achieves high-quality novel view synthesis by performing volume rendering over view-dependent attributes predicted by a neural networkâbased function."
Collections
Sign up for free to add this paper to one or more collections.