- The paper introduces CM-GLasso, a framework that disentangles shared and category-specific topologies via joint ADMM optimization.
- It employs unified feature extraction and cross-attention distillation to mitigate modality misalignment and high-dimensional noise.
- Empirical results show improved classification performance, achieving state-of-the-art accuracy on benchmarks like CUB-200-2011 and ADE20K.
Multimodal Structure Learning via Cross-Modal Graphical Lasso
Introduction
The paper "Multimodal Structure Learning: Disentangling Shared and Specific Topology via Cross-Modal Graphical Lasso" (2604.03953) presents a principled framework, CM-GLasso, for interpretable multimodal representation learning by jointly modeling conditional dependencies between heterogeneous features. Traditional sparse graph estimation methods, e.g., Graphical Lasso (GLasso), suffer from severe limitations when applied to visual-linguistic domains due to high-dimensional noise, modality misalignment, and confounding shared vs. category-specific topologies. CM-GLasso addresses these challenges through unified feature extraction, cross-attention distillation, adaptive prior utilization, and a joint ADMM optimization that disentangles invariant and class-specific precision matrices.
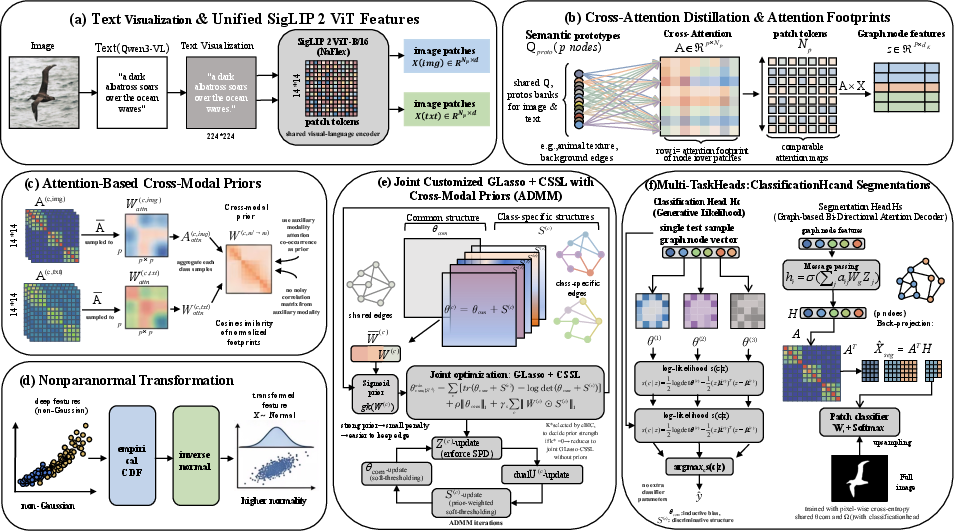
Figure 1: The CM-GLasso pipeline—feature extraction via SigLIP 2, cross-attention distillation, spatial-aware cross-modal priors, nonparanormal transformation, and joint ADMM optimization for disentangling shared and category-specific topologies.
Sparse precision matrix estimation via GLasso and its extensions has traditionally operated in unimodal settings, with advances relying on non-uniform penalty weighting and eBIC-guided structure selection. Recent vision-LLMs like SigLIP 2 and CLIP provide aligned cross-modal embedding spaces but do not directly exploit geometric pathways for conditional dependency modeling. Previous approaches such as Tailored GLasso leverage auxiliary priors but remain limited to unimodal domains and sequential topology decomposition, which accumulates numerical error and fails to exploit structural cross-modal priors.
CM-GLasso bridges the gap by integrating unified vision-language encoders and sophisticated cross-attention distillation to produce interpretable cross-modal structure priors, optimized in a single ADMM-based objective.
Methodology
Unified Multimodal Feature Alignment
A text visualization strategy renders textual descriptions as images, thereby enabling the use of a single vision-language encoder (SigLIP 2 ViT-B/16) for both modalities. This ensures feature consistency and aligned attention footprints, significantly reducing overhead and misalignment artifacts typical in multimodal pipelines.
Cross-Attention Distillation and Spatial Priors
Patch-level features (Np=196) are distilled into p semantic graph nodes via cross-attention using learnable prototypes. Attention co-occurrence matrices constructed from cross-attention footprints serve as spatially aware priors, leveraging auxiliary modal structure for graph estimation guidance. Cosine similarity is used to quantify node footprint overlap, thus encoding topological dependencies in a strictly aligned multimodal space.
GLasso assumes feature normality, but transformer outputs are often non-Gaussian. A nonparanormal transformation maps node features to a standardized Gaussian space, elevating Shapiro-Wilk normality rates from 23% to 88%, which substantially improves the reliability of subsequent covariance estimation.
Joint Optimization: Tailored GLasso + CSSL via ADMM
The framework unifies tailored GLasso and common-specific structure learning (CSSL) in a single objective, optimized via ADMM. Class-wise precision matrices are decomposed into a shared structure ($\boldsymbol{\Theta}_{\text{com}$) and category-specific components (S(c)), with adaptive weight matrices controlled by cross-modal priors and eBIC-guided sigmoid sharpness. This avoids multi-step error accumulation and preserves positive definiteness via eigenvalue updates at each iteration.
Task-Specific Heads and Proxy Supervision
CM-GLasso leverages the disentangled topologies for downstream generative classification and topology-aware segmentation. The decoupled proxy supervision paradigm stabilizes optimization, separating neural parameter training from graph estimation, minimizing suboptimality by maintaining distributional consistency after nonparanormal transformation.
Empirical Results
CM-GLasso is empirically validated across eight benchmarks, spanning both natural and medical domains. In fine-grained classification (e.g., CUB-200-2011), CM-GLasso achieves 92.83% accuracy—outperforming all recent competitive approaches and establishing a new state-of-the-art for multimodal graph-structured discrimination. On segmentation tasks (e.g., ADE20K, VOC-2012, Kvasir-SEG), CM-GLasso consistently surpasses prior methods with respect to mIoU, demonstrating robust topology guidance for pixel-level classification.
Strong numerical results include:
- CUB-200-2011 Classification: 92.83% accuracy, +1.13% over previous SOTA.
- ADE20K Segmentation: 64.01% mIoU, +1.2% over InternImage-H.
- Kvasir-SEG Segmentation: 89.03% mIoU, outperforming PolypMixNet and MedFoundX.
Ablation studies confirm key architectural choices:
- Rendered text with SigLIP 2 outperforms separate BERT/ViT by >7% mIoU.
- Cross-attention distillation reduces spurious edge ratio to 11.4% (vs. 68.7% for PCA).
- Nonparanormal transformation raises Gaussianity pass rate to 88%.
- Joint ADMM optimization reduces generalization gap to 1.93%.
Interpretability and Visualization
Visualizations reveal that CM-GLasso’s cross-attention mapping produces spatially interpretable heatmaps, with node activations corresponding to semantically meaningful regions (e.g., animal heads, background separation). Graph-structured topology enables robust segmentation, accurately capturing long-range semantic dependencies and boundary precision.
(Figure 2)
Figure 2: GAM heatmaps—classification head focus on spatially discriminative semantics (e.g., bird wings, vehicle contours) evidencing improved interpretability.
(Figure 3)
Figure 3: Segmentation results—precise boundaries and long-range semantic context achieved across ADE20K, Kvasir, VOC-2012, and COCO; CM-GLasso preserves authentic semantic pathways.
Theoretical and Practical Implications
CM-GLasso establishes a rigorous bridge between deep representation learning and statistical graphical models, facilitating explicit disentanglement of shared and specific multimodal topologies. Practically, this enables improved discriminative and dense prediction performance, interpretable semantic structures, and robust domain adaptation. The joint ADMM optimization imbues mathematical guarantees of convergence and positive-definiteness, critical for deployment in high-reliability and real-time applications.
Scalability remains constrained by offline eigenvalue computations, suggesting future directions in low-rank matrix approximations and hierarchical clustering for extremely large category sets. The spatially-aware prior mechanism also promises potential impact in temporal graph domains, such as video understanding.
Conclusion
CM-GLasso delivers a topology-aware multimodal learning framework that unifies aligned feature extraction, interpretable spatial priors, and mathematically principled graph estimation. Extensive empirical evidence demonstrates its capacity to improve both classification and segmentation performance, while preserving interpretability, robustness, and adaptability. The method’s joint optimization paradigm sets a solid foundation for further advances in statistical structure learning and multimodal AI.

