- The paper introduces DMA, integrating diagonal-tiled mixed-precision quantization with a fused kernel to optimize LLM attention inference.
- It demonstrates that allocating high-precision on diagonal tiles preserves key attention scores while low-precision elsewhere cuts latency by up to 80×.
- Experimental results on LLaMA benchmarks confirm DMA maintains or improves accuracy, offering significant hardware-software co-design insights.
Diagonal-Tiled Mixed-Precision Attention for Efficient Low-Bit MXFP Inference
Introduction and Problem Context
Transformer-based LLMs are hindered by the quadratic complexity and high memory bandwidth demands of attention computation during inference. While quantization and sparsity have reduced costs, hardware advances such as NVIDIA Blackwell's support for low-precision MXFP formats (MXFP8, MXFP4, NVFP4) provide unprecedented theoretical throughput for low-bit inference. However, deploying attention in these formats incurs severe quantization error, particularly at 4-bit precision, and software support for fused low-precision pipelines is lacking. The core technical obstacles are: (1) accuracy loss due to low-bit quantization, and (2) inefficiency from non-fused kernel operations that dominate runtime and under-utilize available hardware parallelism.
Methodology and Architecture
This work introduces the Diagonal-Tiled Mixed-Precision Attention (DMA) workflow, designed for efficient low-bit MXFP inference in LLMs. DMA employs two central strategies:
- Diagonal-Tiled Mixed-Precision: Attention matrices are partitioned tile-wise, with high-precision (e.g., MXFP8) used in a diagonal band, corresponding to the regions most critical for accurate predictions, and low-precision (e.g., MXFP4 or NVFP4) applied elsewhere. This diagonal partitioning targets the empirical observation that salient attention scores cluster near the diagonal, while peripheral scores can tolerate aggressive quantization without significant degradation.
- Fused Mixed-Precision Quantization Kernel: The quantization, packing, and format transformation process is integrated into a single, memory-optimal Triton kernel, which emits both low- and high-precision representations. The kernel supports efficient data movement, reduced synchronization, and minimal memory bandwidth consumption by not materializing unnecessary intermediates.
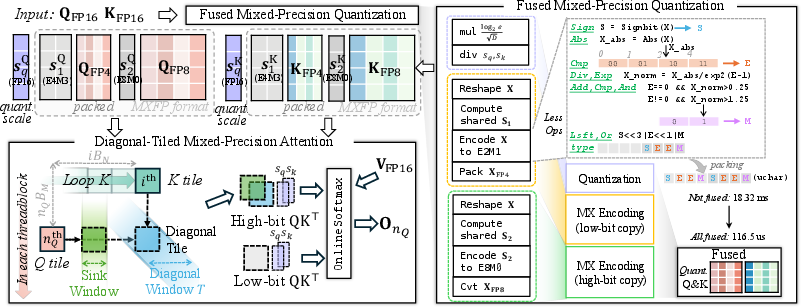
Figure 1: The DMA pipeline first generates both low- and high-precision Q/K representations in a fused fashion, then processes diagonal tiles with high precision and peripheral tiles with low precision.
The fused quantization kernel processes incoming FP16 tensors to yield both MXFP4 and MXFP8 representations. For each attention head, OnlineSoftmax is fused into the core kernel, maintaining the equivalence of the resulting softmax normalization during tiled blockwise execution. Algorithmic details directly address block-specific scale computation (E8M0 for MXFP, E4M3 for NVFP4), unique bit packing schemes, and specific rounding mechanisms (e.g., round-ties-to-even in mantissa selection for E2M1).
Quantization Error Analysis
DMA provides in-depth analysis on the error induced by various MXFP quantization schemes. Empirically, MXFP4 (4-bit) produces substantial degradation in attention score similarity relative to FP16/FP32, while NVFP4, with finer-grained scale and block size, produces notably lower error.
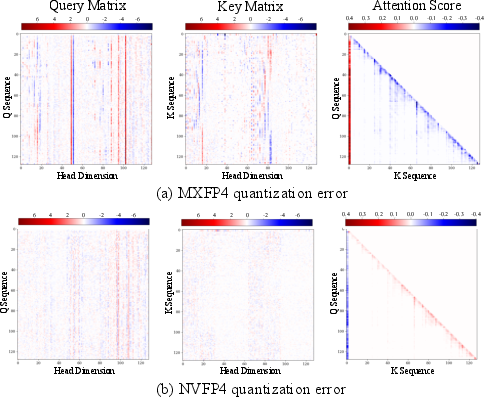
Figure 2: MXFP4 format exhibits larger quantization error in Q, K, and attention scores compared to NVFP4, as visualized by elementwise differences from reference outputs.
Detailed results using cosine similarity, peak SNR, and L1 error metrics reveal that straightforward low-bit quantization, especially at 4-bit, is not viable for the entire matrix. The channel-sensitive structure of quantization error motivates the diagonal-mixed approach, given that attention computation is a reduction over the channel axis, making channel-wise scaling infeasible in a fused kernel.
Experimental Results
On the LongBench benchmark for long-context inference, DMA achieves equal or higher accuracy compared to FP16 SDPA baselines, with substantial improvements in mean task score (44.11 to 46.43 on LLaMA3.1-8B; 35.84 to 37.20 on LLaMA3.2-3B). Notably, accuracy is robust across a wide range of comprehension and retrieval tasks, demonstrating that concentrating high precision on diagonal submatrices is sufficient to preserve generation quality.
Efficiency and Ablation
DMA attains strong throughput and latency reductions versus both unfused and naively fused baselines. With optimal block sizes (128), total end-to-end attention latency reaches 7.776 ms, outperforming all compared MXFP and NVFP baselines by 39–53%. Kernel fusion brings an 74–80× speedup over the fully unfused workflow for typical batch sizes and sequence lengths.
Ablation results on block size, quantization granularity, and fuse-level configuration demonstrate that:
- Increasing the diagonal block window size yields marginal gains in output fidelity but degrades throughput.
- Per-token quantization yields the best numerical fidelity at the cost of minor latency increases.
- Full kernel integration (quantization, packing, scale conversion, mixed-precision output) is critical for minimizing preprocessing overhead.
Theoretical and Practical Implications
DMA offers a practical path to harnessing new low-precision hardware features for LLM inference. By localizing high-precision computation and fusing all quantization and projection steps, hardware utilization and memory bandwidth can be dramatically improved with negligible regression or even gains in accuracy. This validates hardware-software co-design approaches, where hybrid precision and tight kernel integration are essential for next-generation AI deployment.
Theoretically, DMA substantiates that the diagonal region of attention matrices disproportionately influences model output, justifying fine-grained allocation of precision and computation along the diagonal. This provides an empirical foundation for future exploration of structured attention sparsification and dynamic tiling policies.
Future Developments
DMA currently targets Nvidia Blackwell hardware and is evaluated on textual LLMs with sequence lengths up to 30k. Future advances will require adaptation to even longer contexts, alternative model architectures, and attention mechanisms in non-text modalities (e.g., vision, vision-language). Expanding DMA-like strategies to operate on hierarchical mixed-precision tiling or adaptive block assignment can further optimize the trade-off between hardware utilization and model fidelity.
Conclusion
DMA defines a fused, diagonal-tiled attention methodology for low-bit inference, leveraging hybrid MXFP formats to deliver superior efficiency/accuracy trade-offs for LLM inference. The approach establishes the technical viability of hardware-centric, kernel-fused mixed-precision computation, with direct empirical benefits in latency and output fidelity, and sets a concrete foundation for extending similar strategies to other high-throughput Transformer-based workloads.