- The paper introduces a co-designed mixed-precision quantization algorithm with channel-wise adaptive precision assignment to minimize quantization error.
- It fuses reorder-and-quantize within GEMM kernels, leveraging FP4 Tensor Cores on NVIDIA Blackwell GPUs for significant acceleration.
- The method achieves competitive accuracy (over 95% of FP16 on zero-shot tasks) and scalability across diverse LLM applications and hardware platforms.
Introduction
MicroMix introduces a co-designed mixed-precision quantization algorithm and matrix multiplication kernel tailored for NVIDIA's Blackwell architecture, leveraging Microscaling (MX) data formats (MXFP4, MXFP6, MXFP8). The framework addresses the limitations of existing INT4-based quantization methods, which are unable to fully exploit the throughput of FP4 Tensor Cores due to format incompatibility. MicroMix achieves adaptive precision allocation at the channel level, guided by quantization error thresholds, and integrates a fused reorder-and-quantize operation to maximize kernel efficiency. The method demonstrates competitive or superior accuracy and significant speedups across diverse LLM tasks and hardware platforms.
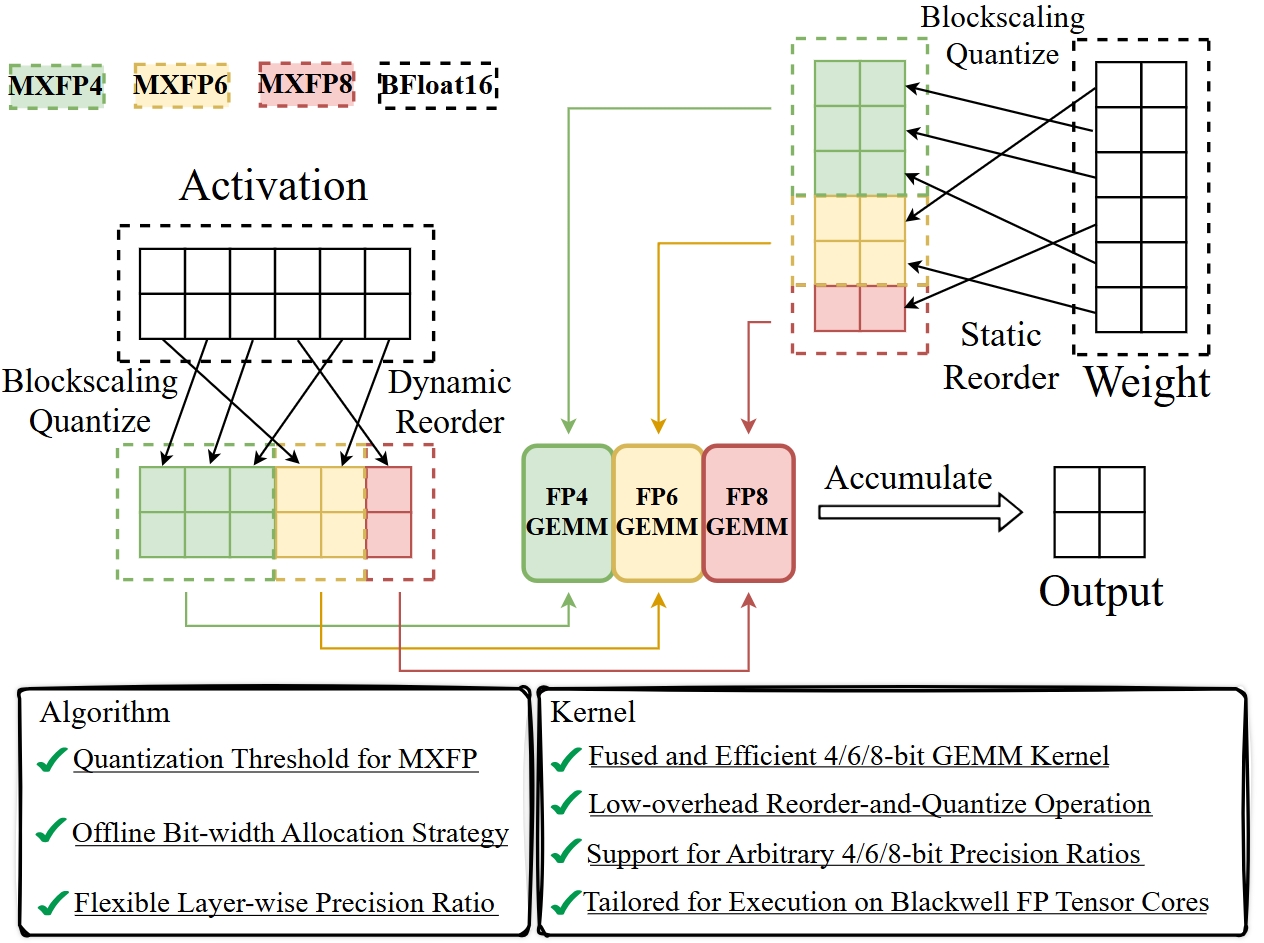
Figure 1: MicroMix assigns bit-widths to channels based on absolute mean values, with online channel reordering for activations and offline reordering for weights.
Motivation and Design Principles
Adaptive Mixed-Precision Allocation
Existing mixed-precision quantization methods (e.g., Atom, QuaRot) employ a fixed number of high-precision channels per layer, failing to account for the heterogeneity in activation distributions across layers. MicroMix introduces a layer-wise adaptive allocation strategy, assigning higher precision to channels with larger absolute mean values, thereby minimizing quantization error and preserving model accuracy.
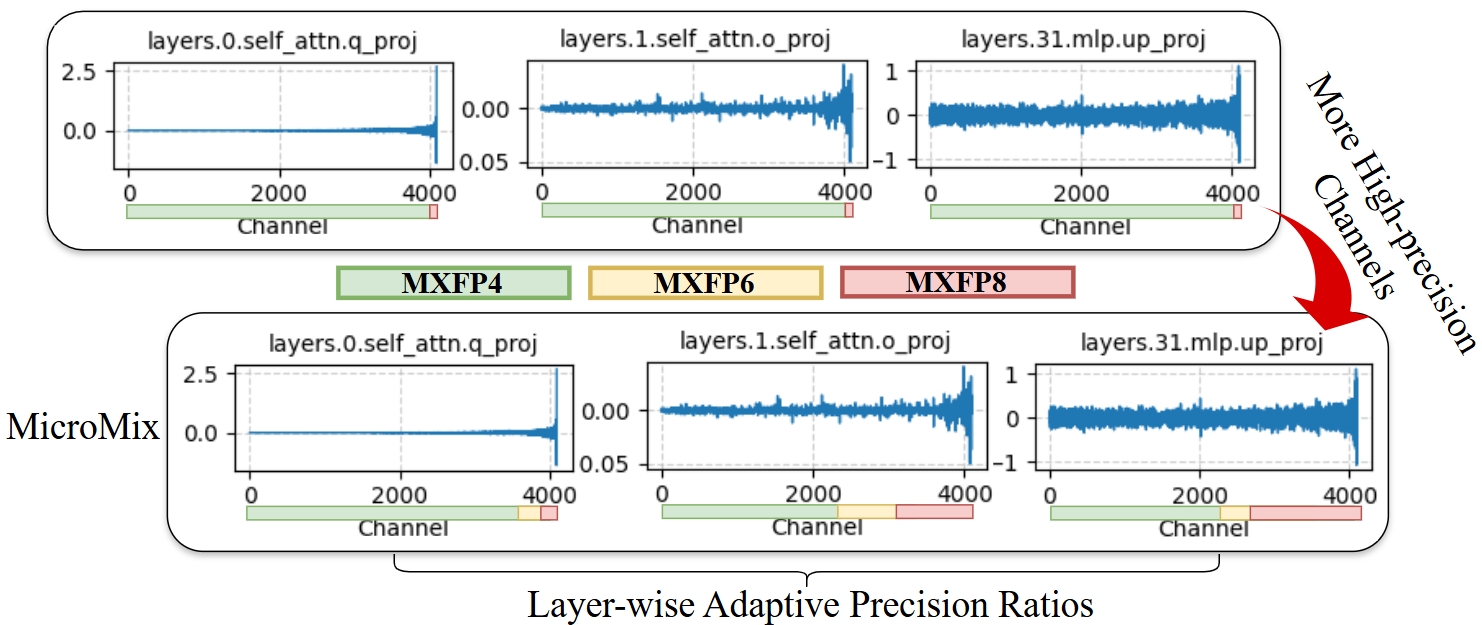
Figure 2: Channel-wise mean values of Llama3.1-8B activations, with outlier channels reordered; MicroMix adaptively assigns higher precision to outlier channels.
Hardware-Aware Kernel Efficiency
INT-based quantization kernels are bottlenecked by dequantization operations on CUDA Cores, which consume up to 85% of execution time on Blackwell GPUs. MicroMix leverages FP4 Tensor Cores, enabling direct dequantization and fused GEMM operations, resulting in substantial computational efficiency gains.
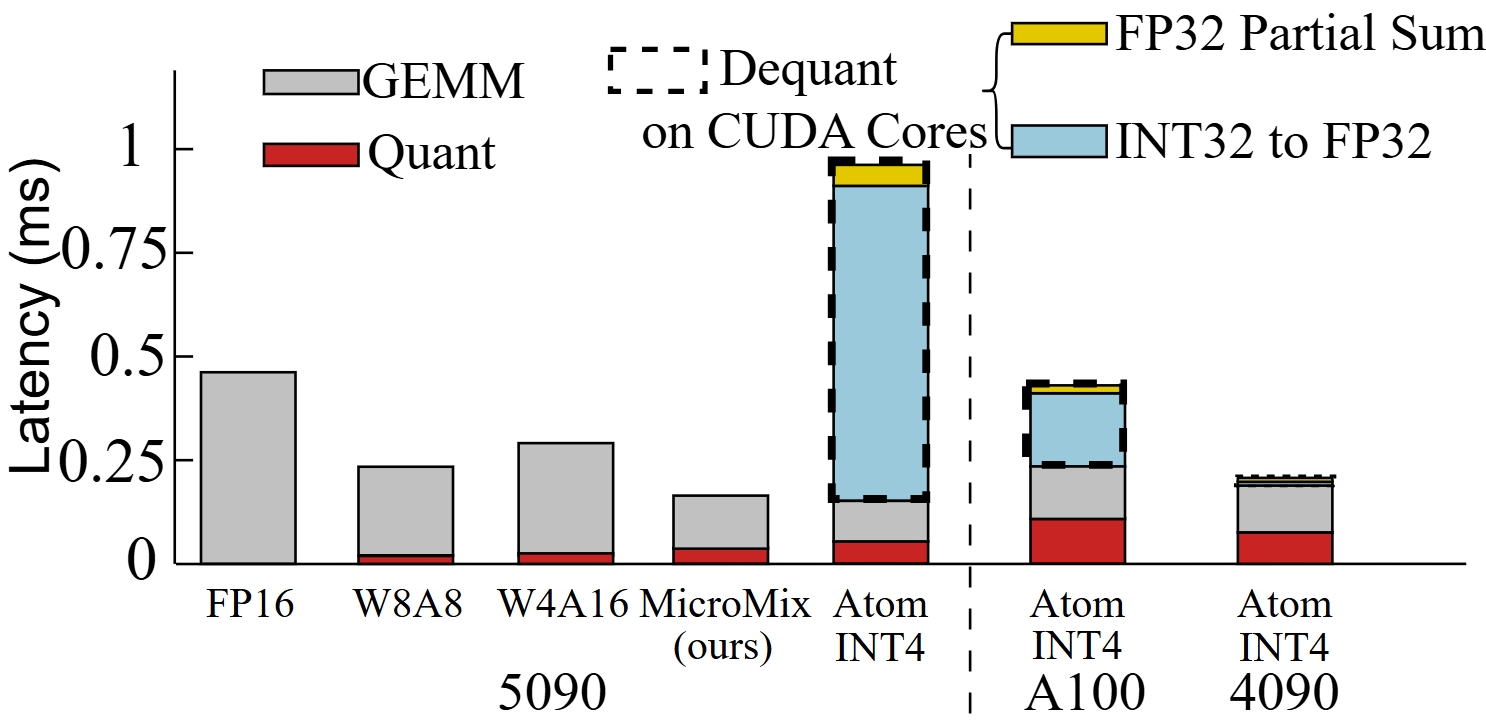
Figure 3: Runtime breakdown of matrix multiplication kernels on RTX 5090, A100, and RTX 4090; MicroMix fuses dequantization within GEMM, outperforming INT-based kernels.
Quantization Error Management
MicroMix defines explicit quantization thresholds for MXFP4 and MXFP6 formats, ensuring that channels assigned to lower precision do not exceed the quantization error upper bound of INT8. Channels violating these thresholds are reassigned to higher precision formats, effectively suppressing outlier-induced degradation.
Algorithmic Framework
Channel Partitioning and Precision Assignment
Activations are partitioned into three groups (P4, P6, P8), quantized to MXFP4, MXFP6, and MXFP8, respectively. The assignment is determined by sorting channels according to their absolute mean values, computed from a calibration dataset. The quantization error for each channel is constrained by:
E(Xj){MXFP4,MXFP6}≤E(Xj)INT8
where E(Xj)INT8 is the INT8 quantization error upper bound. The quantization threshold T(n) for n-bit formats is derived to ensure this constraint.
Offline Calibration and Online Reordering
Channel indices for each precision group are determined offline using calibration data, exploiting the observed stability of channel statistics across datasets and batch sizes. During inference, activations are reordered online to match the precomputed indices, while weights are reordered and quantized offline.
Fused Kernel Implementation
MicroMix integrates a fused reorder-and-quantize operation within the GEMM kernel, minimizing memory access irregularities and overhead. The kernel suite, built on CUTLASS, supports arbitrary mixing ratios of MXFP4, MXFP6, and MXFP8, with dequantization deeply fused into MMA instructions for maximal throughput.
Experimental Results
Accuracy and Robustness
MicroMix retains over 95% of FP16 accuracy on zero-shot tasks and over 90% on five-shot MMLU, with perplexity degradation within 20%. On code generation (Human-Eval) and mathematical reasoning (GSM8K, MMLU-STEM, CMATH), MicroMix incurs less than 3% accuracy drop compared to FP16, and in some cases surpasses FP16 and FP8 baselines.
Efficiency and Scalability
MicroMix achieves 8–46% kernel-level acceleration over TensorRT-FP8 on RTX 5070Ti and 16–46% on RTX 5090. Transformer block execution speed increases by 6–29%, and end-to-end throughput improves by 3.5–9.7%, with peak memory usage reduced by ~20%. The fused reorder-and-quantize operation accounts for 7–17% of runtime, with FP4 GEMM dominating the compute profile.
Variants of MXFP6 and MXFP8 (E3M2, E4M3, E5M2) were evaluated, with E3M2 (MXFP6) yielding up to 5% higher accuracy than E2M3. Calibration dataset choice (WikiText2, Pile, Human-Eval) had negligible impact on performance, with fluctuations within 1%.
Implementation Considerations
- Hardware Requirements: MicroMix is optimized for NVIDIA Blackwell architecture, requiring FP4 Tensor Core support. The kernel suite is built on CUTLASS and TensorRT-LLM.
- Memory Efficiency: Average bit-width per element is 5.2–5.5 across tested models, with significant memory savings over FP16.
- Deployment: Offline calibration and weight quantization are one-time costs; online activation reordering is efficiently fused with quantization.
- Scalability: The method generalizes across Llama and Qwen model families, batch sizes, and sequence lengths.
Implications and Future Directions
MicroMix demonstrates that hardware-algorithm co-design, leveraging MX data formats and adaptive precision allocation, can substantially improve both accuracy and efficiency of LLM inference. The explicit management of quantization error via thresholding and channel-wise adaptivity sets a new standard for mixed-precision quantization. Future work may explore dynamic online calibration, integration with training pipelines, and extension to other hardware platforms supporting flexible precision formats. The approach is also amenable to further granularity in precision assignment and could be combined with pruning or low-rank compression for additional gains.
Conclusion
MicroMix provides an efficient, adaptive mixed-precision quantization framework for LLMs, co-designed with hardware capabilities of modern GPUs. By integrating quantization error management, offline calibration, and fused kernel operations, MicroMix achieves state-of-the-art accuracy and significant speedups over existing baselines. The method is robust across tasks, models, and datasets, and sets a foundation for future research in hardware-aware quantization and efficient LLM deployment.

