- The paper presents a unified framework that automates skill segmentation and symbolic abstraction from very few unannotated demonstrations.
- It integrates vision-language models, ASP-driven PDDL induction, and diffusion-based policy learning to overcome the data bottlenecks of traditional approaches.
- Real-world evaluations on forklifts and robotic arms demonstrate strong generalization and near-classical control success rates with minimal manual intervention.
Vision-Language-Guided Neuro-Symbolic Imitation Learning for Data-Efficient Real-World Robot Manipulation
Introduction
"Build on Priors: Vision–Language–Guided Neuro-Symbolic Imitation Learning for Data-Efficient Real-World Robot Manipulation" (2604.03759) presents a unified neuro-symbolic imitation learning (IL) framework that addresses the fundamental challenges of long-horizon robotic manipulation with extreme data efficiency and minimal manual engineering. Unlike prior approaches, which require large labeled datasets, hand-engineered symbolic abstractions, or heavy human supervision, the proposed system fully automates annotation, skill discovery, domain abstraction, and control policy learning from as few as one to thirty unannotated demonstrations per skill. The approach leverages recent advances in vision-LLMs (VLMs), answer set programming (ASP) for symbolic induction, PDDL-based planning, and diffusion-based policy learning, yielding a pipeline that is expert-free, interpretable, generalizable, and deployable on heterogeneous robot platforms.
Framework Overview
The framework processes raw manipulation demonstrations and outputs a complete neuro-symbolic manipulation system Φ=(σ,{πi}) consisting of a symbolic planning domain σ and a library of control-level neural skill policies. The architecture comprises three core learning pipelines: (1) open-vocabulary visual object detection and pose estimation, (2) VLM-driven trajectory annotation and state abstraction, and (3) control policy learning via diffusion models, with data augmentation and minimal observation filtering.
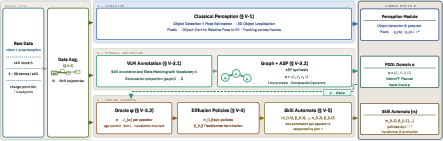
Figure 1: The training pipeline shares input demonstrations and feeds three processing lanes for object detection, symbolic abstraction, and control policy learning, integrating VLM annotations and ASP-based PDDL induction.
VLMs (specifically, Gemini 3 Flash) are used to automate both skill segmentation and the identification of visually/equivalently abstracted high-level states, eliminating the need for handcrafted symbolic predicates. The resulting state-transition graph is passed to an ASP solver that synthesizes parameterized PDDL domain models, capturing both relational and temporal operator structure. Domain-driven oracles further filter observation and action spaces, projecting each control policy onto a minimal, task-relevant, and ego-centric reference frame. Controls operate at the reference level, not on hardware-specific actuators, providing smooth, transferable action spaces. Trajectory augmentation multiplies data efficiency by leveraging classical controllers to project demonstrations onto unvisited object configurations, crucial under minimal data regimes.
Symbolic Abstraction via VLM and ASP
The VLM-annotation pipeline forms the cornerstone for scalable abstraction. It takes unsegmented, unlabelled demonstration sequences, segments them into skill instances, and annotates both state nodes (equivalence classes of before/after images) and edges (skills) using open-vocabulary natural language prompts. Task-relevant differences are isolated by injecting domain hints, and bisimulation-based graph compression merges semantically equivalent visual states.








Figure 2: Gemini 3 Flash merges visually diverse observations into abstract nodes, guided by semantic cues on key task factors (e.g., pallet status, forklift location), sharply reducing node duplication.
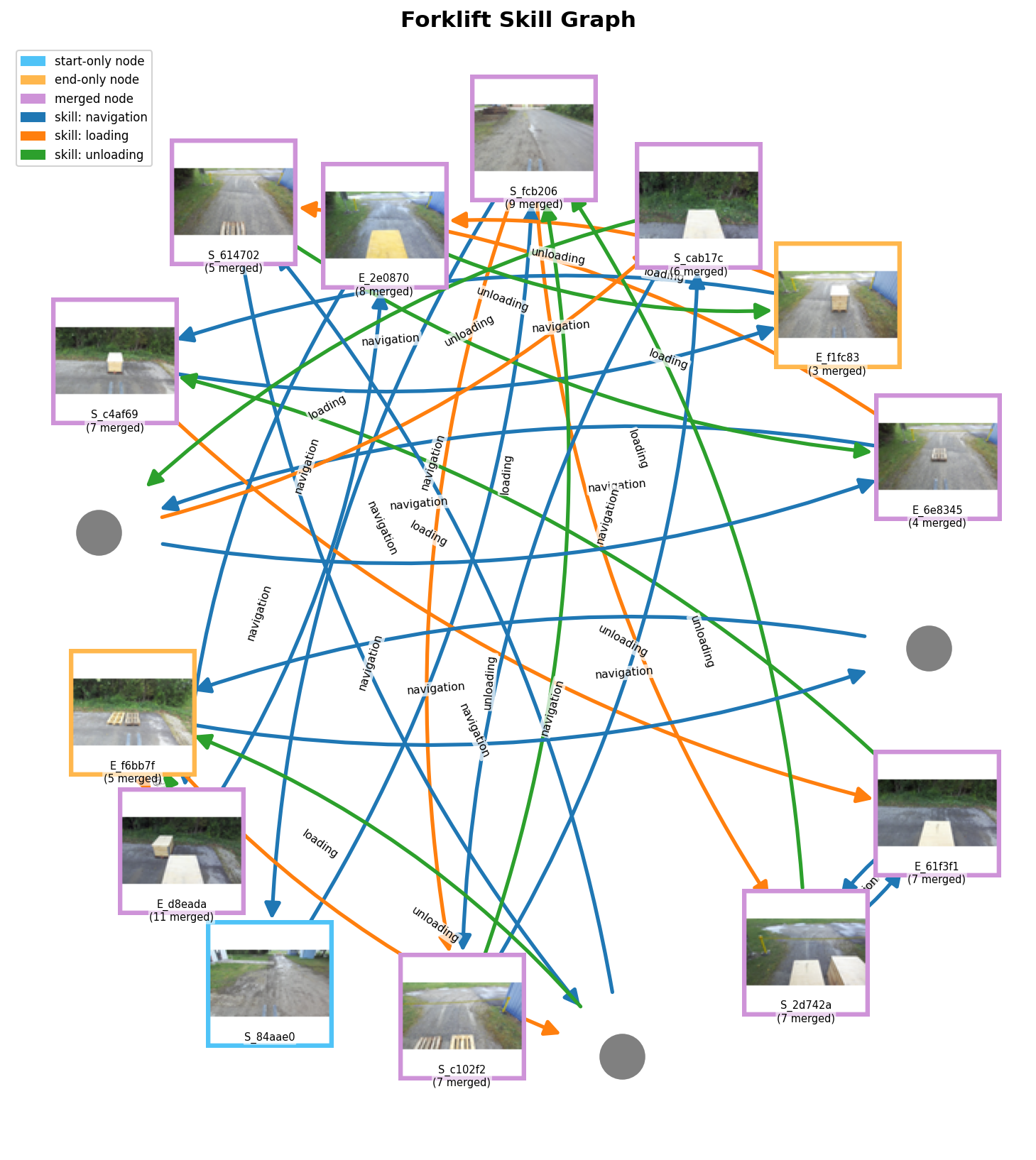
Figure 3: The VLM-constructed state transition graph annotates edges with skill labels, supporting compact operator induction.
This graph is then consumed by an ASP solver, which generates symbolic operator models (in PDDL) capturing the preconditions and effects observed across all annotated paths. The solver naturally infers relational, temporal, and even process-level dependencies, which methods driven purely by clustering cannot uncover. The resulting learned domain supports generalized, interpretable task planning and is directly inspectable.
Data-Efficient Control Policy Learning and Augmentation
Skill policies are not trained end-to-end for the entire task; instead, the symbolic domain decomposes the large-horizon task into modular operator-level sub-policies. Each operator is learned using a multi-phase, changepoint-segmented, diffusion-based imitation learner. The oracle function isolates only the minimal observation dimensions required for each operator, typically the relative pose between the agent's effector and the relevant object(s), which ensures translation-invariant policy learning and strong intra-task generalization.
Data scarcity is mitigated by projecting individual demonstrations onto alternative object targets using geometric controllers, producing synthetic but semantically valid augmentation even in the real world. This approach synergizes the reliability of model-based control with the flexibility of demonstration-driven distributional matching.
Real-World Robotic Evaluations
The framework is comprehensively validated:
- Forklift Manipulation: On the ADAPT outdoor industrial forklift (Fig. 5), the system achieves a strong success rate of 90% for complex load–navigate–unload cycles using 30 demonstrations per skill (versus 98% for an engineered classical controller) and maintains 86% at only 10 demonstrations. No manual domain engineering is required: all symbolic models and control policies are learned directly from data, even amidst substantial initial pose variance (see Fig. 7 and Fig. 9).

Figure 4: The primary real-world domain: ADAPT autonomous forklift performing pallet manipulation in variable outdoor settings.
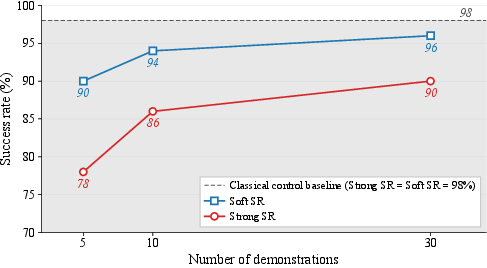
Figure 5: Success rate vs. number of demonstrations for the real forklift; soft success approaches classical-control upper bound with 30 demonstrations.
- Long-Horizon and Generalization: The planner composes tasks from learned operators and generalizes robustly to multi-object, multi-location goals (two-pallet/two-zone tasks requiring eight skill applications) even when no demonstration covers these compositions. New skills, such as truck-bed unloading at unseen height, can be composed from a single demonstration without disturbing existing models.
- Kinova Arm Cross-Domain Transfer: The entire abstraction and learning pipeline is deployed on a Kinova Gen3 arm for stacking and kitchen benchmarks (Fig. 6), requiring only perception adaptation. The system solves long-horizon, multi-object rearrangement from as little as a single demonstration per skill by leveraging geometric augmentation, again without any domain-specific programming or reward engineering.


Figure 6: Cross-platform transfer validated on Kinova Gen3 for tabletop stacking and kitchen tasks.
Analysis of Symbolic Induction and Robustness
Automated PDDL induction with partial or noisy graph structures remains tractable; the ASP solver degrades by adding action parameters or more conservative predicate coverage, not by failing catastrophically. This robustness reflects the expressiveness of the underlying symbolic machinery and the reliability of VLM-driven annotation for generating semantically meaningful abstractions, with human supervision required only as a backstop at current VLM performance levels (see Fig. 8).
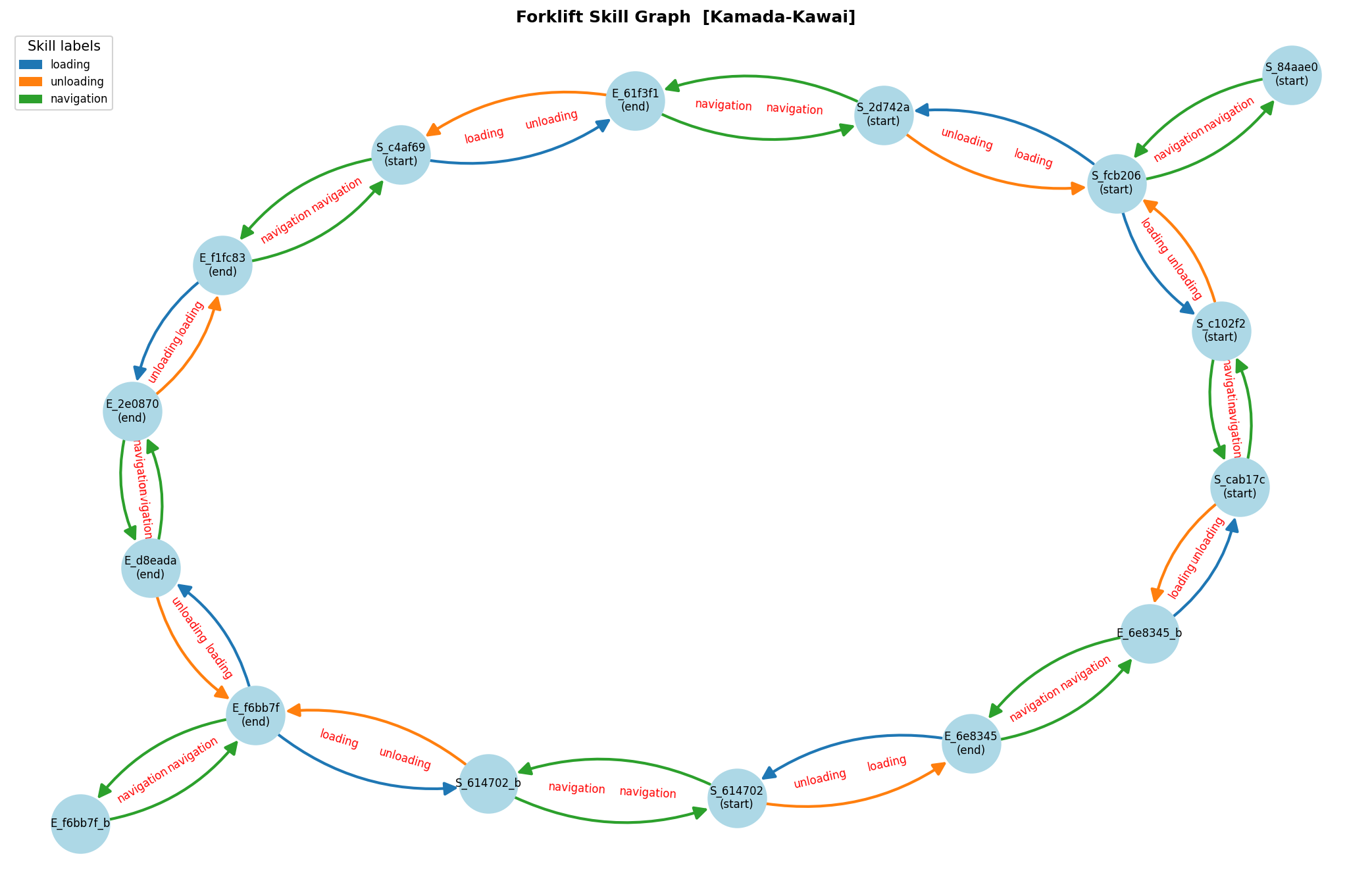
Figure 7: VLM graph construction is accurate for edge annotation (>98%), with human fallback for state equivalence failures—already sufficient for practical synthesis of executable planning domains.
Implications and Future Directions
This work empirically demonstrates that scalable, interpretable, and minimally supervised neuro-symbolic manipulation is feasible in real-world domains. By recasting VLMs as first-class annotators, ASP solvers as structure inducers, and control references as data-efficient policy carriers, the authors eliminate the major deployment bottlenecks of prior art. The strong numerical results—approaching classical-control baselines with orders of magnitude less data and zero domain hand-engineering—validate the effectiveness of their integrated symbolic-subsymbolic hierarchy.
Theoretically, the framework supports compositional, combinatorial generalization: learned operators can be sequenced into plans not present in any demonstration. Practically, the use of modular, oracle-driven observation filtering and ego-centric reference frames produces policies that transfer robustly across scene perturbations and new object configurations. Remaining limitations involve scaling ASP domain induction to very large skill libraries and developing reliable, closed-loop failure recovery via robust symbolic state estimation—active directions for future research.
Integrations with large-scale, foundation model-based VLA policies at the skill level remain an open and promising avenue, offering the prospect of blending task-level symbolic planning and rich, low-level visual reasoning for further scalability.
Conclusion
The proposed framework delivers data-efficient, interpretable, and generalizable neuro-symbolic robot learning, validated on challenging real-world tasks. By integrating VLM-driven annotation, ASP-based symbolic induction, oracle-based filtering, and reference-level policy learning, this system stands as a practical template for future expert-free robotics pipelines. The theoretical and empirical results support cross-domain deployment, strong compositional generalization, and a real solution to the longstanding problem of scalable skills and plans from demonstration in robotics.