- The paper presents a synthetic neuro-symbolic supervision approach that leverages VLMs to generate structured, interpretable robot policies as behavior trees.
- It employs a 10,000 scene synthetic dataset and fine-tunes Pixtral-12B with LoRA adaptation to achieve robust, hardware-agnostic execution.
- Achieving 100% task success and JSON validity, the method demonstrates strong zero-shot sim-to-real transfer across diverse robotic platforms.
Neuro-Symbolic Policy Synthesis with VLMs: Structured Robot Policies from Synthetic Multimodal Supervision
Introduction
The synthesis of interpretable and robust robot policies remains an open challenge at the intersection of perception, reasoning, and control. Recent work with vision-LLMs (VLMs) has demonstrated strong performance in mapping multimodal observations to robot behaviors, yet most approaches instantiate opaque, end-to-end visuomotor policies with limited interpretability or formal guarantees—constraints that remain untenable in safety-critical robotic applications. The paper "Learning Structured Robot Policies from Vision-LLMs via Synthetic Neuro-Symbolic Supervision" (2604.02812) addresses this by leveraging large vision-language foundation models to generate structured, symbolic policies as Behavior Trees (BTs). Through a fully synthetic pipeline, the approach bridges high-dimensional, multimodal perception and structured, symbolic task representations, supporting reliable, hardware-agnostic robotic execution.
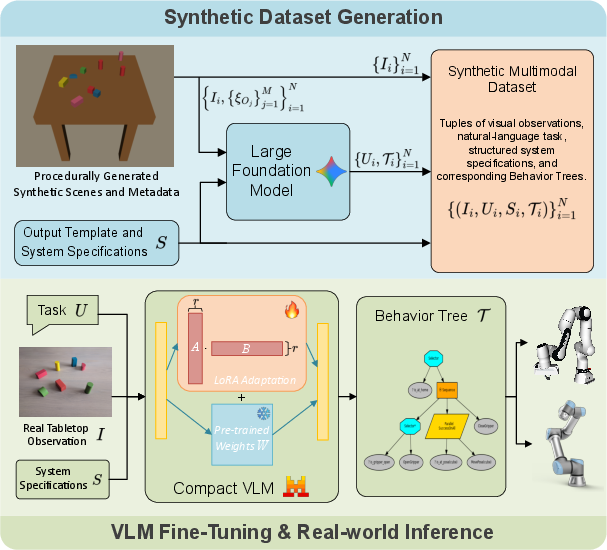
Figure 1: Overview of the system: synthetic observations and structured metadata are used to auto-generate instruction–policy pairs, which fine-tune a VLM; at inference, real images and specs are mapped to executable Behavior Trees.
Synthetic Neuro-Symbolic Supervision Pipeline
The pipeline encompasses the following key elements:
- Synthetic Data Generation: 10,000 tabletop scenes with randomized objects, properties, and spatial layouts created via MuJoCo physics simulation form the core visual supervision for the system.








Figure 2: Examples of procedurally generated, domain-randomized synthetic tabletop scenes in the training dataset.
- Automated Annotation via Foundation Models: For each synthetic scene, a foundation model (Gemini 3 Flash) generates a paired natural language instruction and a structured BT in a constrained JSON schema, encoding the task logic, atomic primitives, and system metadata.
- Structured Prompting and System Specification: Training data includes not only RGB images and linguistic instructions but explicit system specifications (action libraries, safety constraints, symbolic object metadata). The enforced BT schema includes structural priors—such as atomic primitive decomposition, reactive guarding, flat hierarchy, and spatial offsetting.
This approach enables data-efficient, scalable dataset construction for supervised fine-tuning while avoiding the bias and labor overhead associated with manual real-world annotation and demonstration.
Model Architecture and Fine-Tuning
The core model is Pixtral-12B (Agrawal et al., 2024), incorporating a 400M-parameter vision encoder and a 12B-parameter multimodal autoregressive decoder. The model is fine-tuned using LoRA with heavy adaptation (all attention and MLP modules) for the SFT objective of mapping visual, instruction, and system specification inputs to BT-structured JSON outputs.
Training is conducted under strict VRAM constraints (4,400 tokens context window) on a single NVIDIA A40 GPU, leveraging 8-bit AdamW optimization, Bfloat16 precision, and aggressive memory management.
Ablations reveal:
- Heavy LoRA adaptation is essential for learning symbolic reasoning and robust tree generation.
- Underfitting (low rank, light module adaptation) or over-regularization (excessive dropout) substantially degrade syntactic and logical validity.
- Training set scale directly impacts compositional and referential generalization; ~10,000 diverse synthetic samples are necessary for robust multi-object and ambiguous instruction handling.
- Learning rate tuning is critical; too high leads to catastrophic forgetting, while too low precludes adaptation to the BT grammar.
Synthesized policies are hardware-agnostic at the level of action abstraction, with atomic primitives explicitly represented in the BT structure. The emergent behavior demonstrates strong logical consistency and robustness in mapping visual cues and language instructions into formally valid, reactive symbolic plans.
Evaluation: Structural Policy Generation and Sim-to-Real Transfer
Inference and Robustness
Inference is deterministic via greedy decoding, using real-world RGB images. Despite exclusive synthetic training, the model exhibits invariance to domain shifts, maintaining referential and spatial grounding in the presence of real-world artifacts (lighting, shadows, texture).


Figure 3: Real-world images resembling the synthetic dataset, successfully used in zero-shot inference.
Syntactic and Task Performance Metrics
Task Success Rate (TSR), JSON Validity Rate (JVR), Key Error Rate (KER), and schema compliance are tracked. The best model (A1) achieves 100% TSR/JVR/KER (Tab. 2), outperforming base Pixtral-12B, GPT-5, and Gemini 3 Flash in zero-shot settings. Even in one-shot settings, those larger models often hallucinate unsupported schema elements, while the fine-tuned model internalizes the execution grammar intrinsically.
Ablation and Generalization
Ablations validate that both logical complexity and referential/spatial grounding require sufficient training capacity and dataset diversity. However, when deploying on out-of-vocabulary primitive sets or unseen semantic tasks (e.g., "Switch the positions of two cylinders"), the model maintains syntactic and lexical flexibility yet may lack causal logic for multistage operations, highlighting limitations in generalization without broader semantic task coverage during training.
Real-World Robotic Deployment
Hardware-agnostic execution is demonstrated on both a 7-DOF Franka Emika Panda and a 6-DOF UR5e, using a shared primitive library. Real-world images and tasks are completed with reactive policy execution and no modification or real-world training data.


Figure 4: The two physical experimental platforms—Franka Emika Panda and UR5e—demonstrating hardware-agnostic BT execution.
A sequence for "stack all yellow objects" shows that the synthesized policy is interpretable and robust across platforms, dynamically referencing updated object metadata for pose and avoiding hard-coded spatial parameters.




Figure 5: UR5e performing the "stack all yellow objects" task, executing the generated Behavior Tree policy.
Implications and Future Directions
This approach establishes fully synthetic, neuro-symbolic supervision as a powerful methodology for specializing foundation models toward structured, interpretable robot policies. Key implications include:
- Interpretability and Safety: Structured BTs provide a clear execution trace amenable to pre-execution verification, formal reasoning, and runtime monitoring—unlike opaque end-to-end policies.
- Scalability and Hardware-Agnosticism: Synthetic data alleviates annotation bottlenecks and enables transfer across diverse robot morphologies.
- Limitations: Current limits arise in the ability to generalize to new primitives and complex multi-stage operations not explicitly presented in supervision. Therefore, policy compositionality and tool generalization will require expanded datasets and possibly hybrid neural-symbolic reasoning frameworks.
Theoretically, the work demonstrates the capacity of large-scale VLMs, under well-designed synthetic supervision, to internalize both the syntax and semantics of symbolic policy representations, bridging the gap between high-dimensional visual grounding and structured task logic. Practically, it points toward more robust, verifiable, open-source robotic reasoning engines deployable across platforms and domains.
Conclusion
"Learning Structured Robot Policies from Vision-LLMs via Synthetic Neuro-Symbolic Supervision" (2604.02812) offers a robust framework for bridging neural multimodal perception and interpretable, executable symbolic policies. Through a synthetic, scalable pipeline and fine-tuned open-source VLMs, the method achieves platform-agnostic zero-shot transfer and strong structural guarantees. Future advances will likely extend this paradigm toward richer symbolic generalization, tighter integration with low-level control, and the synthesis of more complex and adaptive multi-agent task hierarchies.

