- The paper introduces TongSearch-QR, a model that enhances query reasoning in retrieval tasks through reinforcement learning.
- It employs a novel Group Relative Policy Optimization strategy with semi-rule-based rewards to efficiently rewrite queries.
- Experimental results demonstrate cost-effective performance with an NDCG@10 of 27.9, outperforming some larger models including GPT-4.
TongSearch-QR: Reinforced Query Reasoning for Retrieval
Introduction
The paper "TongSearch-QR: Reinforced Query Reasoning for Retrieval" introduces a novel approach to enhance retrieval systems, particularly in scenarios requiring reasoning-intensive tasks. Traditional information retrieval (IR) systems, well-versed in textual and semantic matching, falter in complex multi-hop inference tasks. This work proposes the TongSearch-QR model family, leveraging reinforced learning to use smaller LLMs effectively, achieving reasoning performance comparable to larger, more resource-intensive models like GPT-4 and LLaMA3-70B.
Methodology
Query Reasoning Enhancement
The key innovation of TongSearch-QR lies in its ability to perform query reasoning efficiently using smaller LLMs. Traditional models face challenges like prohibitive inference costs and security concerns, making deployment in real-world systems difficult. TongSearch-QR utilizes models such as Qwen2.5-7B-Instruct and Qwen2.5-1.5B-Instruct to rewrite queries, achieving high reasoning performance without the significant computational demands typical of larger models.
Reinforcement Learning with Semi-Rule-Based Rewards
A critical component of the TongSearch-QR approach is its semi-rule-based reward function. Drawing from reinforcement learning paradigms, it employs a Group Relative Policy Optimization (GRPO) strategy. This involves novel reward functions, which account for the reasoning gaps between queries and documents, offering robustness and computational efficiency. By focusing on the improvement in relevance scores from original to reasoned queries, the method ensures reward robustness, avoiding potential hacking scenarios typical in model-based reward functions.
Experimental Results and Analysis
TongSearch-QR models were tested on the BRIGHT benchmark, a rigorous platform for assessing reasoning-intensive retrieval efficacy. Experimental results revealed that the TongSearch-QR-7B variant outperformed conventional baselines as well as some large-scale models, achieving an NDCG@10 score of 27.9, surpassing GPT-4o's 26.5. Notably, the 1.5B model also showed competitive performance, making it a viable option for resource-limited applications.
Cost Efficiency
One of the standout aspects of TongSearch-QR is its cost-effectiveness. The cost-performance analysis demonstrated that TongSearch-QR models provide significant savings in inference costs compared to larger models, offering a high efficiency ratio. The performance versus cost metrics clearly favor TongSearch-QR in practical deployment scenarios, reflecting an optimal balance of performance and financial viability.
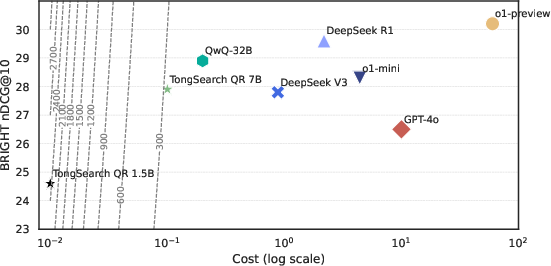
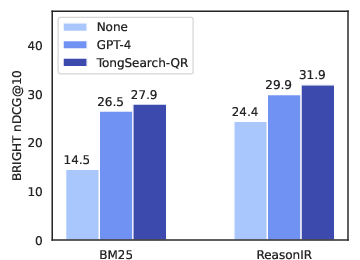
Figure 1: Cost vs. Performance comparison of different models.
Implications and Future Direction
The implications of this research are manifold. Practically, TongSearch-QR offers a viable solution for enterprises needing efficient yet powerful retrieval systems that can handle reasoning-intensive tasks without incurring high inference costs. Theoretically, it opens new avenues for leveraging small-scale models in sophisticated IR tasks traditionally dominated by large-scale setups.
Future work could explore deeper integrations with reasoning-intensive retrievers to further enhance performance. The adaptability of the TongSearch-QR models suggests potential for widespread application across varying retrieval contexts, potentially incorporating broader knowledge bases and more diverse datasets.
Conclusion
TongSearch-QR represents a significant step forward in the domain of information retrieval, bridging the gap between computational efficiency and reasoning capability. By employing novel reinforcement learning strategies and reward functions, it delivers robust performance and adaptability, highlighting its potential in both theoretical explorations and practical applications. As the landscape of AI retrieval systems evolves, TongSearch-QR sets a precedent for future innovations in the field.