- The paper’s main contribution is a query execution pipeline that transforms natural language prompts into executable structured queries using a compact LLM.
- It leverages a synthetic data pipeline with automated paraphrasing and 44,849 question–answer pairs to robustly capture diverse querying intentions.
- The system utilizes 4-bit quantization and QLoRA fine-tuning on commodity hardware, achieving competitive accuracy with models like GPT-4.
Structured Data Querying via Natural Language with Small LLMs
Model Motivation and System Architecture
The paper addresses a critical challenge in deploying LLM-based querying systems for structured, non-textual datasets: the inadequacy of RAG techniques for numerical and tabular data. The proposed open-source methodology uses a compact LLM—specifically DeepSeek R1-Distill-8B—fine-tuned via QLoRA with 4-bit quantization, to generate executable queries in response to natural language prompts. The architecture is designed to operate with commodity hardware, enabling practical deployment in resource-limited environments while eschewing large, closed-source models.
A key architectural innovation is the shift from direct answer generation or text retrieval to an explicit query execution pipeline. Upon receiving a user question, the model generates a structured query reflecting both the intent and the semantics of the relevant dataset fragment. The query is then executed, and the returned data is incorporated into the final natural language output, ensuring robust and precise access to complex, structured information.
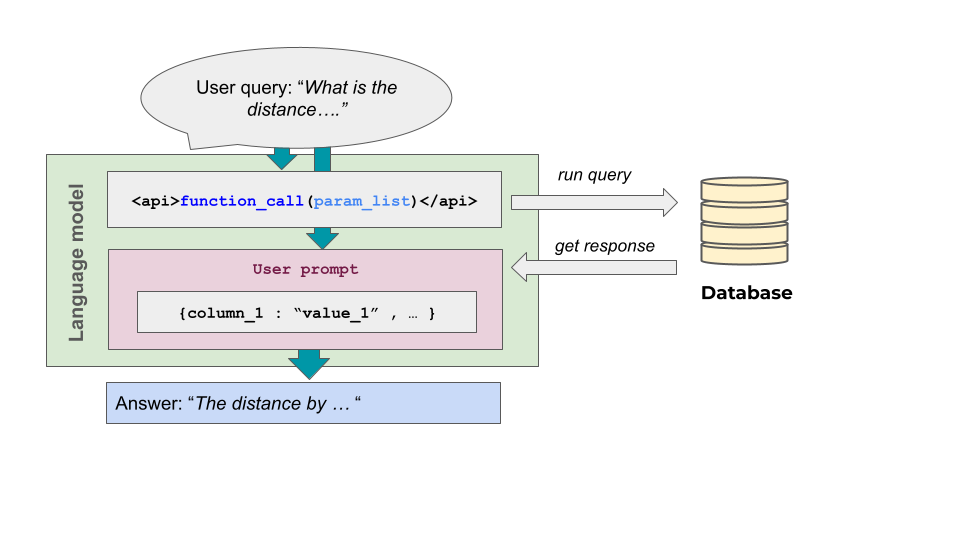
Figure 1: Overview of the model inference and query generation process.
Synthetic Training Pipeline and Dataset Construction
Sufficient, high-quality training data for query generation is typically unavailable for specialized domains. The paper presents a systematic pipeline for synthetic dataset creation:
- All semantically meaningful projections over the dataset are identified.
- For each projection, question templates are constructed, capturing diverse querying intentions and linguistic expressions.
- Instantiation is performed over a representative sample of locations from the Durangaldea region using the Overpass API, producing 44,849 question–answer pairs.
- Answers are paired with corresponding executable queries.
- Paraphrasing is automated using LLMs (Gemini 2.5 Pro and DeepSeek R1) to induce robust generalization to linguistic variability.
The dataset covers a range of spatial and access-related queries, ensuring strong coverage for downstream query generation.
Fine-tuning with QLoRA and Model Evaluation
The DeepSeek R1-Distill-8B model was fine-tuned under strong memory constraints using QLoRA. The approach updates approximately 10M adapter parameters (out of 8B model parameters) while leveraging 4-bit quantization to limit GPU memory footprint. Training employed early stopping to prevent overfitting and used standard metrics (BLEU-4, ROUGE-L, and Exact Match) to track convergence over a held-out validation set.
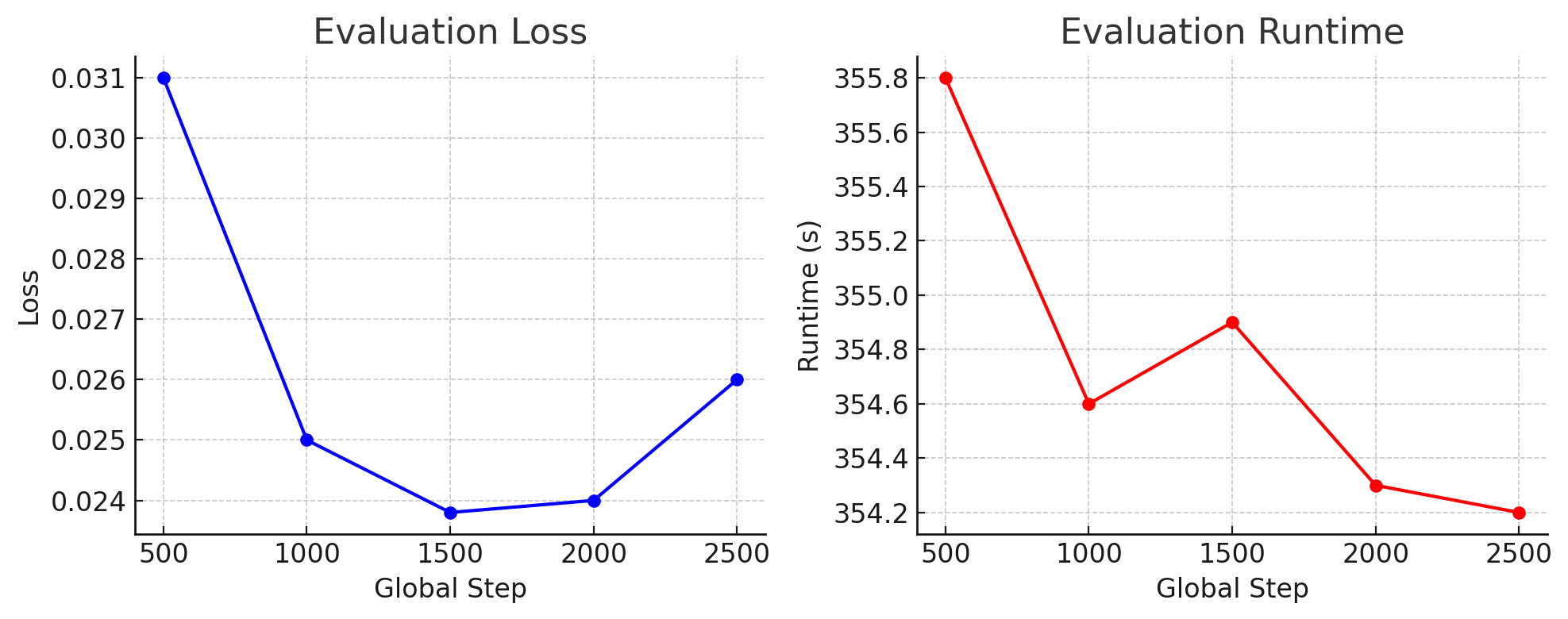
Figure 2: Evaluation metrics during fine-tuning; loss decreases and stabilizes early, indicative of task structure acquisition and minimal overfitting.
Evaluation on monolingual, multilingual, and unseen-location test sets demonstrates:
- High syntactic precision and structural alignment: BLEU-4 and ROUGE-L often near 0.97–0.99.
- Strong generalization to new locations (Exact Match 89%) and paraphrased queries (94.2%).
- Multilingual performance is uneven: strong in major European languages (e.g., Spanish, Catalan, Galician), but severely degraded for Basque—reflecting foundation model pre-training composition.
- Competitive accuracy against SOTA LLMs (GPT-4, Gemini, Grok) despite model scale and hardware constraints.
The fine-tuned model is instantiated within a web application supporting both free-form and template-based querying. UX incorporates geolocation (Google Maps) and automatic mapping of street-level queries to dataset coordinates. Guardrails are implemented to ensure safety and enforce query validity, contributing negligibly to latency.
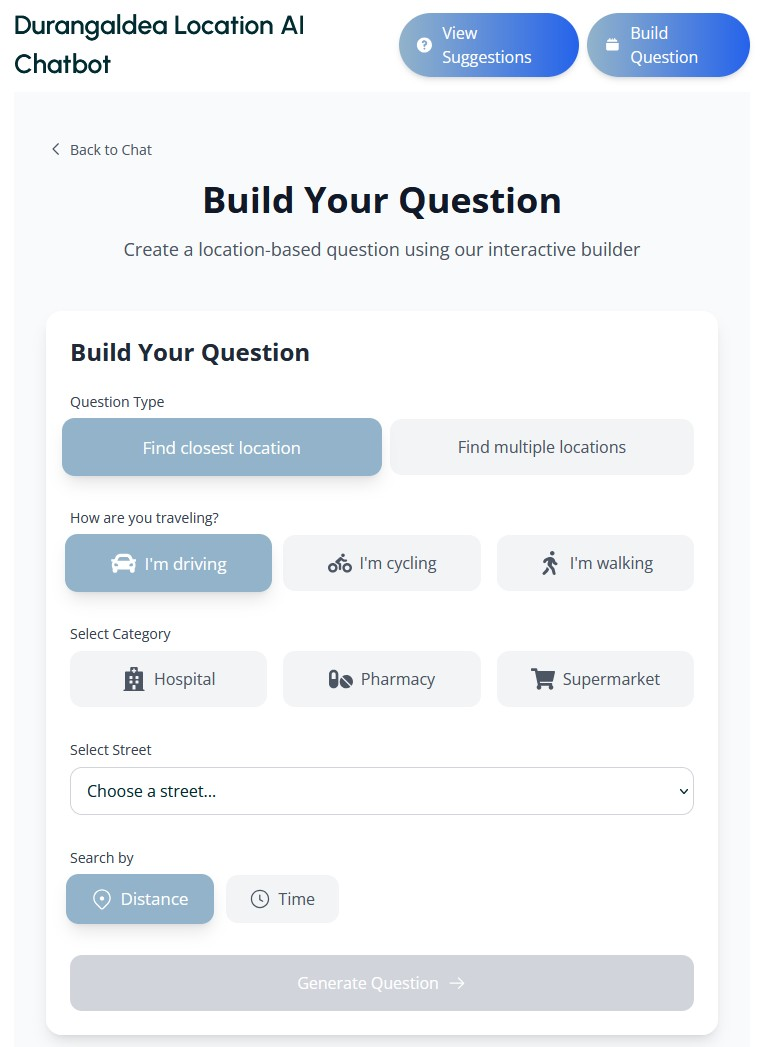
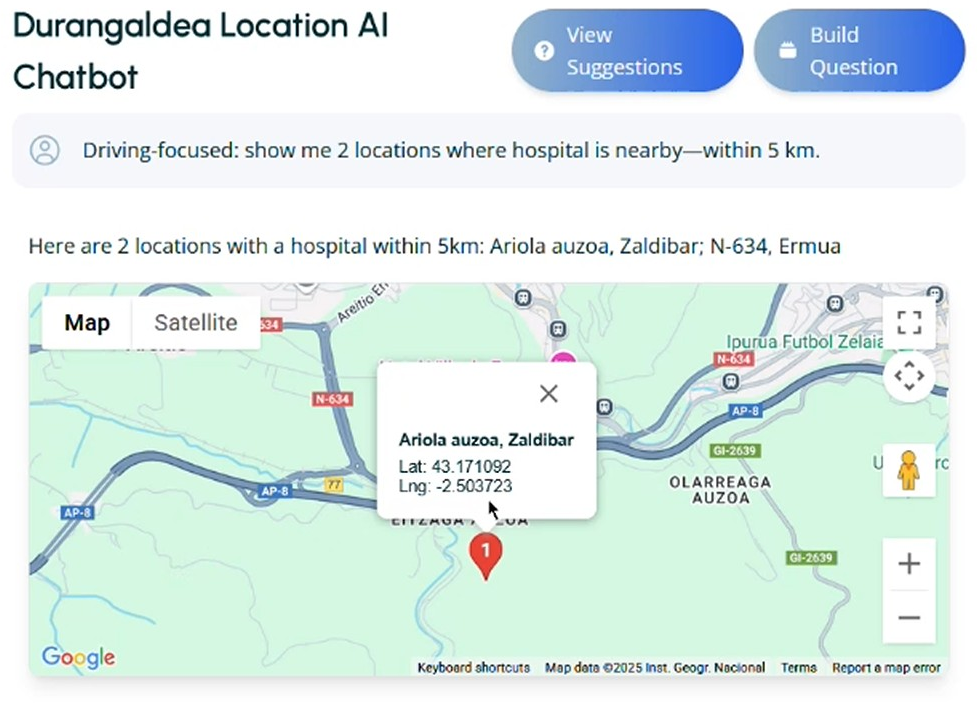
Figure 3: Web application for model queries provides a practical interface for accessibility data exploration.
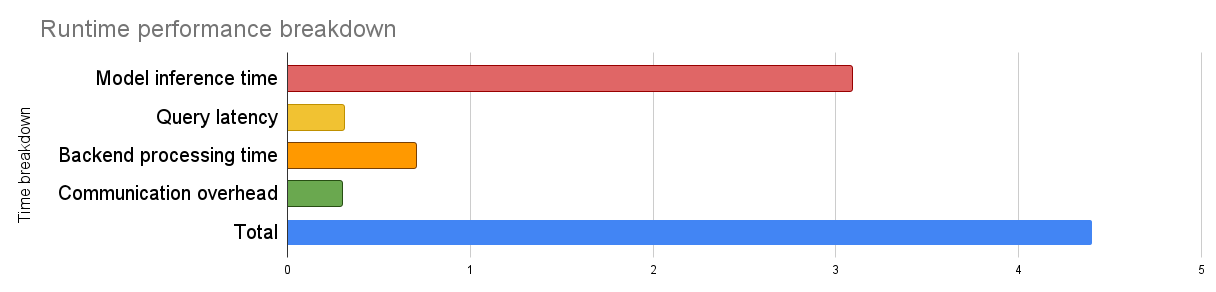
Performance profiling reveals:
The system demonstrates that high-fidelity querying over specialized datasets can be realized with low-cost hardware by focusing on model compactness and task-specific fine-tuning.
The proposed methodology is situated relative to prior work:
- Toolformer and Gorilla enable LLMs to interface with diverse external tools or APIs, but require massive models and extensive, often unavailable, annotated corpora, or rely on retrieval-augmented grounding for API selection.
- The presented pipeline optimizes for high precision within a narrow domain, and leverages a lightweight, dataset-specific synthetic corpus, enabling efficient tuning without large-scale retrieval, context injection, or multi-tool complexity.
- ReAct and similar iterative tool-use paradigms impose additional reasoning and computational overhead for multi-step tool invocation; the presented work circumvents this by restricting to single call, single-dataset workflows with minimal context loading.
The approach thus addresses the complexity, context window, and resource bottlenecks of more general tool-using LLM architectures.
Limitations and Future Directions
Key limitations arise primarily in scalability to multi-dataset or strongly multi-domain deployments:
- Manual template and projection enumeration will not scale for exponentially expanding query spaces across combined datasets.
- The current application does not address high-concurrency workload scaling; batch inference, aggressive quantization, pruning, and response caching are identified as practical system-level mitigations.
- Error recovery mechanisms are rudimentary; future iterations could leverage iterative prompt-error feedback for self-correction.
Potential generalizations include the use of ontology-based abstraction, LLM-driven topic space enumeration, and more comprehensive multilingual adaptation protocols.
Conclusion
This work establishes that high-accuracy, low-latency natural language querying of structured data is achievable using compact open-source LLMs fine-tuned with minimal specialized hardware. By introducing a principled, synthetic data generation and fine-tuning pipeline, the approach bridges a critical deployment gap between proprietary high-resource LLMs and practical, domain-targeted question-answering systems. Extension to larger-scale, heterogeneous, or dynamic dataset environments remains a promising area for ongoing research, with implications for democratizing access to data-driven analytics and decision support across a wider variety of real-world contexts.
Reference: "Querying Structured Data Through Natural Language Using LLMs" (2604.03057)