- The paper introduces a framework combining retrieval augmentation and structured reasoning with lean LMs to perform domain-specific QA tasks.
- The methodology leverages synthetic query generation, document summarisation, and reasoning-aware fine-tuning to achieve performance comparable to frontier LLMs.
- Empirical evaluations show that even small models (as low as 1.5B parameters) deliver high accuracy in complex tasks while ensuring resource efficiency and data privacy.
Retrieval-Augmented Reasoning with Lean LLMs
Introduction
The paper "Retrieval-augmented reasoning with lean LLMs" (2508.11386) presents a comprehensive framework for integrating retrieval-augmented generation (RAG) and structured reasoning within small-scale, locally deployable LLMs. The work addresses the challenge of achieving high performance in complex, domain-specific question answering tasks under resource and privacy constraints, where reliance on large, cloud-hosted LLMs or external APIs is infeasible. The authors demonstrate that, through careful pipeline design, synthetic data generation, and reasoning-aware fine-tuning, lean models can approach the performance of frontier LLMs in specialized domains.
System Architecture and Pipeline
The proposed system consists of several tightly integrated components: a dense retriever, a lean reasoning model, synthetic query and reasoning trace generation, and a conversational interface. The pipeline is designed to be reproducible and adaptable to other domains.
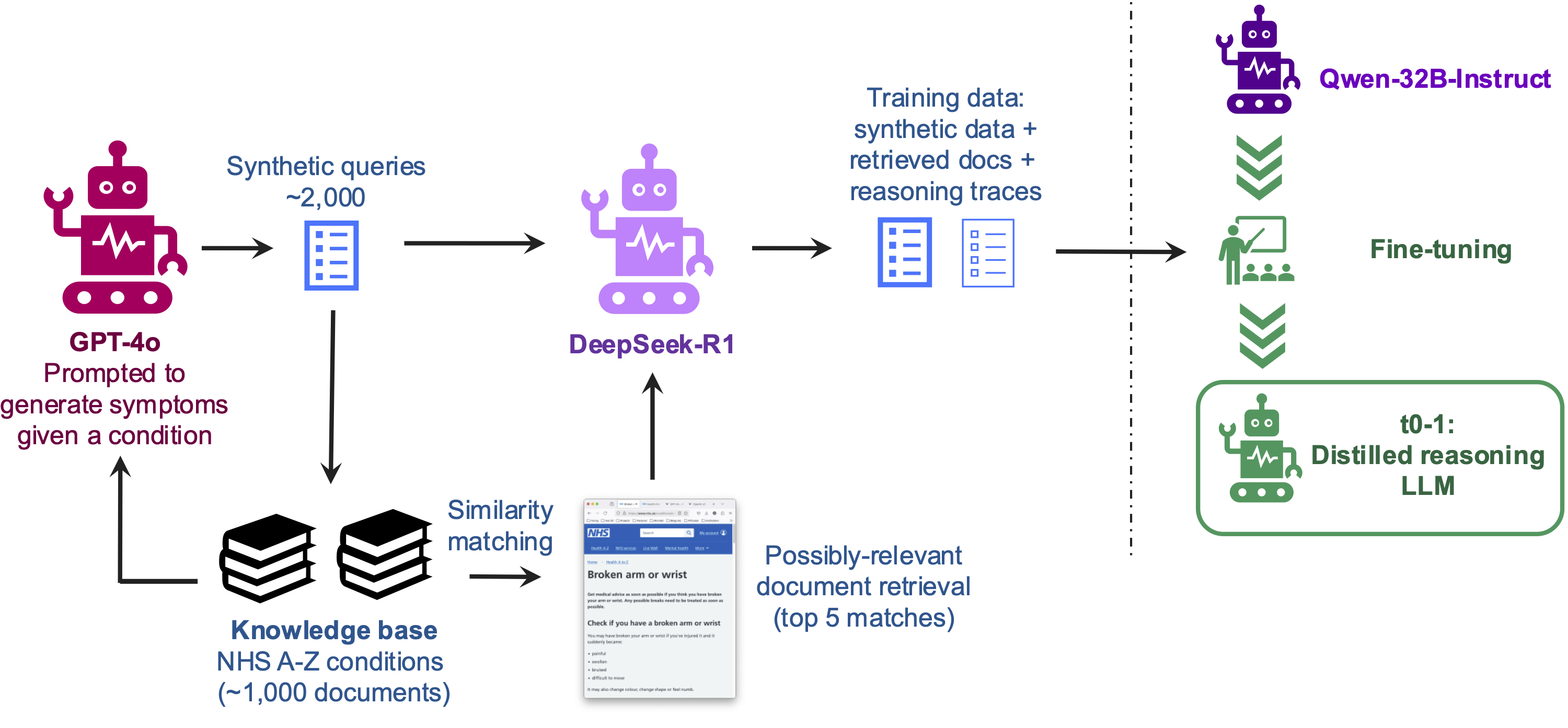
Figure 2: Overview of the pipeline, covering synthetic data creation, information retrieval, reasoning trace generation, and model fine-tuning.
Retriever
The retriever indexes a corpus of domain-specific documents (e.g., NHS A-to-Z condition pages) using sentence-transformer embeddings and a vector database (Chroma or FAISS). Documents are chunked with overlap to preserve semantic continuity, and retrieval is performed via similarity search. Full-document retrieval is employed to ensure the LLM receives complete context, mitigating the risk of missing critical information due to chunk boundaries.
Synthetic Data and Reasoning Traces
Synthetic queries are generated using a large LLM (GPT-4o), with prompts designed to elicit realistic, varied, and challenging user requests. For each query, a set of relevant documents is retrieved, and a frontier reasoning model (DeepSeek-R1) is prompted to produce detailed reasoning traces and final answers. This process yields a dataset of (query, retrieved documents, reasoning trace, answer) tuples for supervised fine-tuning.
Document Summarisation
To address context window limitations and reduce computational overhead, retrieved documents are summarised using Qwen2.5-32B-Instruct, achieving an 85% reduction in length while retaining essential information. Summarisation is performed offline to avoid latency during inference.
Fine-Tuning
Lean Qwen2.5-Instruct models (1.5B–32B parameters) are fine-tuned on the synthetic reasoning trace dataset using next-token prediction. The training setup leverages long context windows (up to 32k tokens), gradient checkpointing, and FSDP sharding to accommodate large input sequences. The fine-tuned models learn to emulate the structured reasoning process of the teacher model, including explicit intermediate steps before producing final answers.
Empirical Evaluation
The authors replicate the s1.1 fine-tuning protocol and evaluate model performance on the AIME24 mathematical reasoning benchmark. Results indicate that reasoning-aware fine-tuning yields substantial gains for models ≥14B parameters, while smaller models may experience degradation due to insufficient capacity.
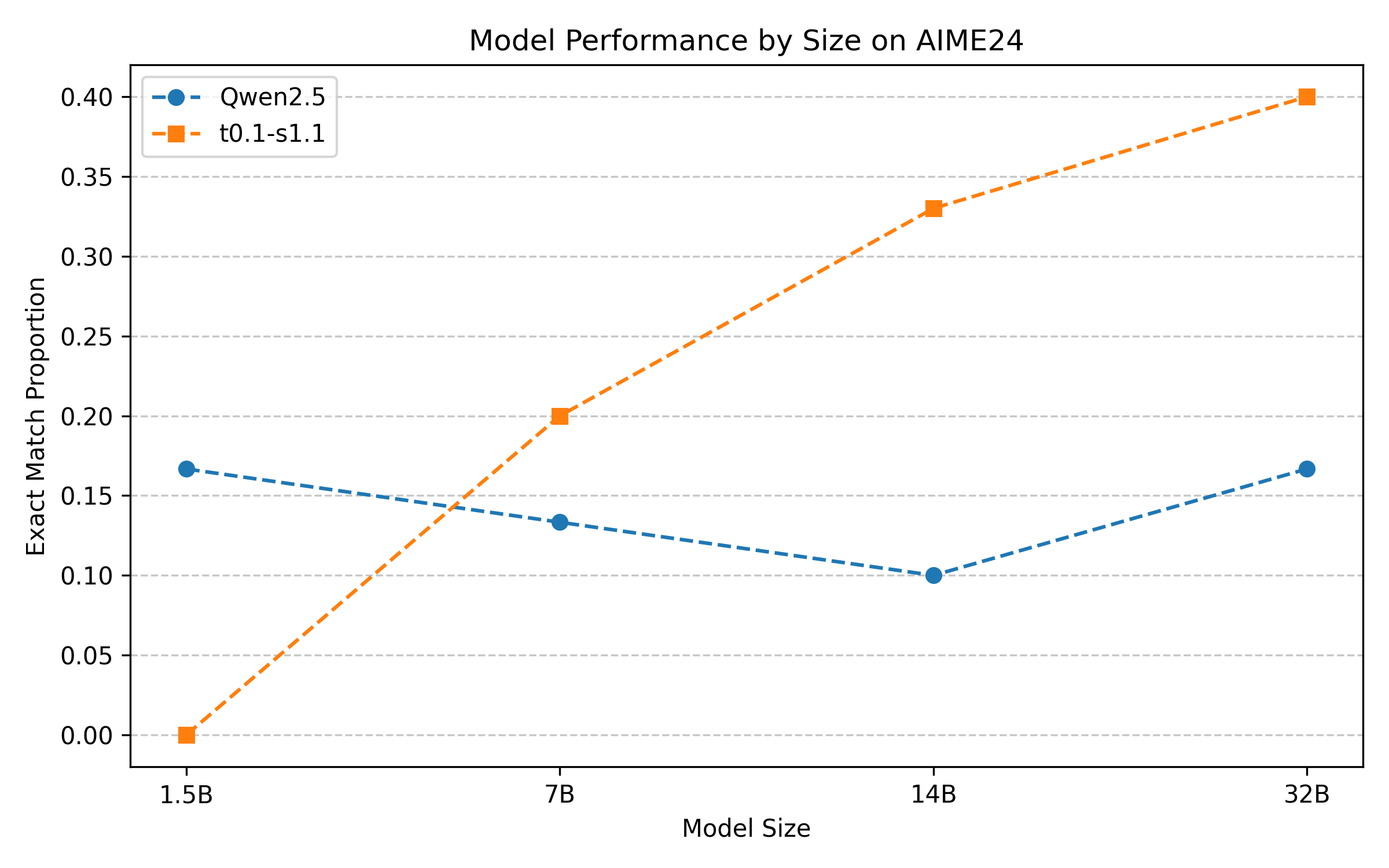
Figure 3: Performance on AIME24 of Qwen2.5-Instruct models and their post-trained versions fine-tuned on DeepSeek-R1 reasoning traces.
Retrieval and Reasoning Synergy
The system is evaluated on a synthetic medical QA task using the NHS A-to-Z corpus. Retrieval accuracy is maximized by indexing summarised documents, with p@5 reaching 76%. Condition and disposition prediction tasks show that the fine-tuned 32B model (t0-1.1-k5-32B) achieves 56% condition accuracy and 51% disposition accuracy, matching or exceeding several frontier models (GPT-4o, DeepSeek-R1) when provided with retrieved context. Notably, the lean model outperforms general-purpose reasoning models (s1.1-32B, Qwen3-32B) in domain-specific tasks.
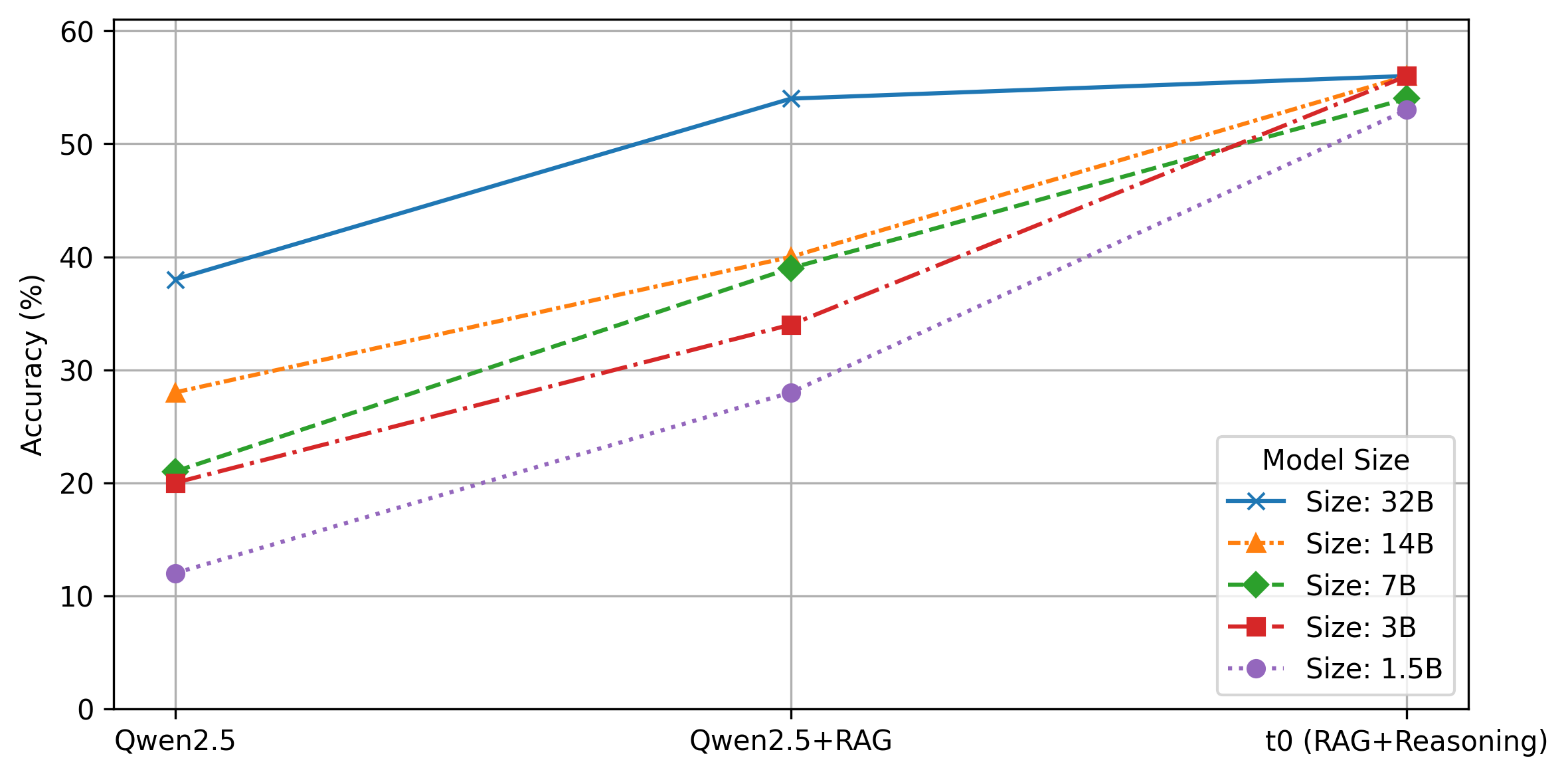
Figure 5: Performance on condition prediction of Qwen2.5-Instruct models alone, with RAG, and with post-trained t0 versions combining RAG and reasoning.
Model Size Trade-offs
Distillation enables strong performance even in models as small as 1.5B parameters, with condition prediction accuracy comparable to much larger non-reasoning baselines. The primary performance boost for small models arises from reasoning-aware fine-tuning, which imparts the ability to interpret and synthesize retrieved evidence.
Conversational Interface and Deployment
A Svelte-based web frontend is provided, supporting multi-turn chat interactions and dynamic retrieval. The backend orchestrates retrieval, reasoning, and response generation, with tool-calling and prompt templates tailored for Qwen2.5-Instruct. The interface is designed for extensibility and secure deployment, with all state managed server-side to ensure consistency.
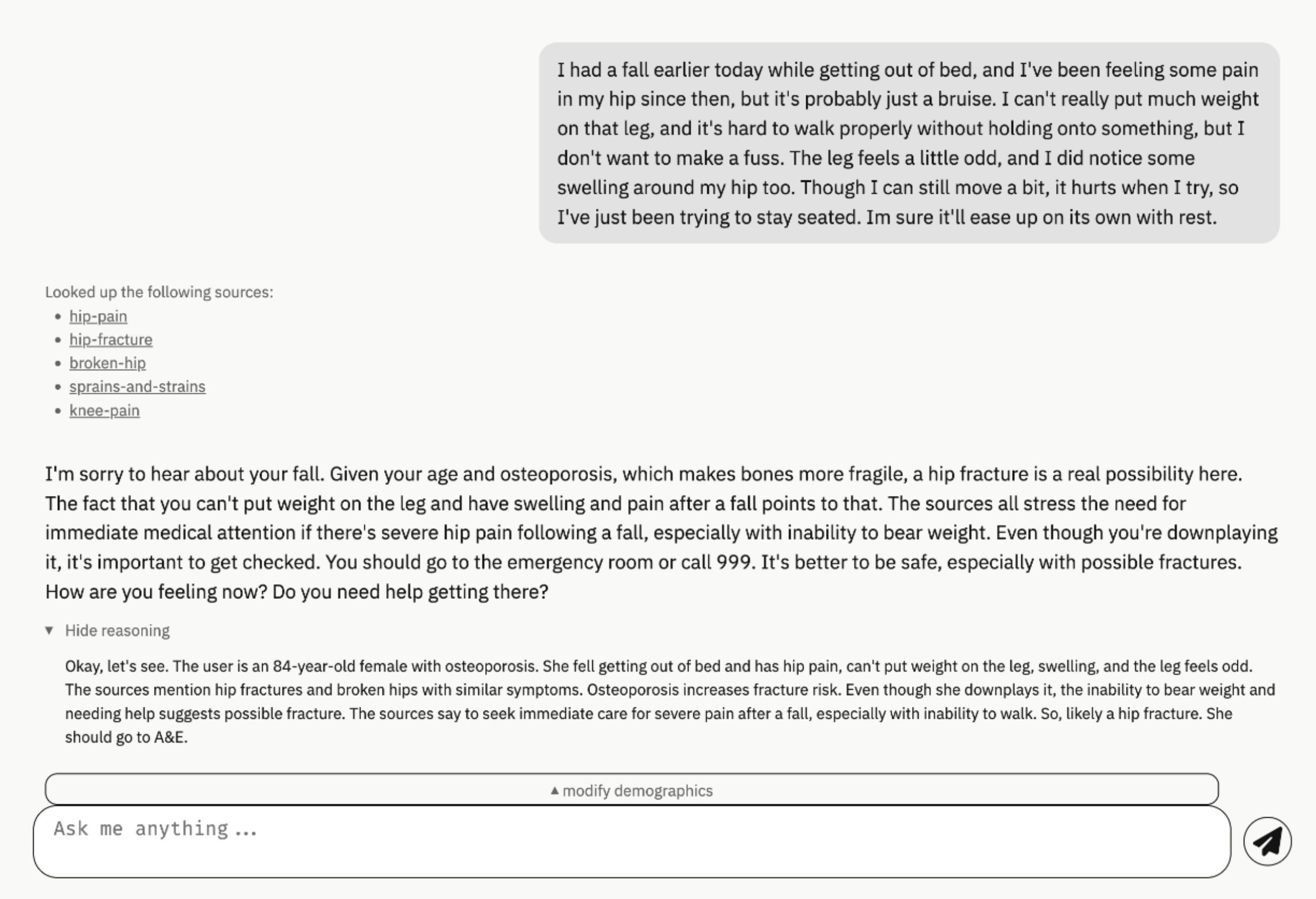
Figure 1: Snapshot of the chat interface, illustrating multi-turn interaction and reasoning trace display.
Discussion and Implications
Domain-Specific vs General Reasoning
Fine-tuning on in-domain reasoning traces confers a clear advantage over general-purpose reasoning models, particularly in tasks requiring nuanced interpretation of specialized evidence. The approach is robust to query complexity, with error analysis showing reduced underestimation and improved handling of ambiguous or challenging requests.
Resource Efficiency and Privacy
The framework enables deployment of high-performing QA agents in secure, resource-constrained environments, with model sizes and memory footprints suitable for on-premises or air-gapped infrastructure. This is critical for applications in healthcare, government, and other sectors where data privacy is paramount.
Future Directions
Potential enhancements include query-aware document summarisation, retriever-generator co-training, multi-hop retrieval, and integration of multimodal evidence. The methodology is extensible to other domains, provided suitable synthetic data and reasoning traces can be generated or curated.
Conclusion
This work demonstrates that retrieval-augmented reasoning can be effectively realized in lean LLMs through structured pipeline design, synthetic data generation, and reasoning-aware fine-tuning. The resulting models achieve performance comparable to frontier LLMs in domain-specific QA tasks, with significant implications for privacy-preserving, resource-efficient AI deployment. The open-source codebase and modular architecture facilitate adaptation to diverse applications requiring grounded, interpretable reasoning over private knowledge bases.