- The paper demonstrates that LoRA-based supervised fine-tuning can effectively eliminate extrapolation and overreaction biases in large language models.
- The methodology employs controlled, out-of-sample experiments in AR(1) forecasting and S&P 500 asset predictions to validate the debiasing approach.
- The framework maintains general language understanding while aligning forecasts with rational, empirically optimal benchmarks in financial contexts.
Debiasing LLMs via Parameter-Efficient Fine-Tuning
Overview
The paper "Debiasing LLMs by Fine-tuning" (2604.02921) rigorously investigates systematic behavioral biases in LLMs, particularly extrapolation and overreaction tendencies, and presents a formal methodology to correct these biases through supervised fine-tuning (SFT) using Low-Rank Adaptation (LoRA). The approach targets LLMs' tendency to overweight recent information when forecasting—an empirically robust bias paralleling human behavior observed in both experimental and asset-pricing domains. Through controlled experimental replications and cross-sectional asset return prediction exercises, the paper establishes that SFT can substantially weaken or entirely eliminate these biases without sacrificing general language understanding or tractability.
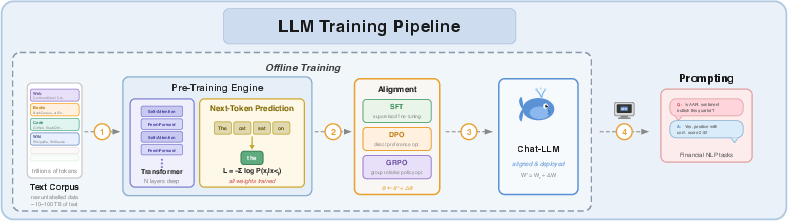
Figure 1: The modern LLM pipeline combines pre-training on broad text corpora and instructional fine-tuning, with the proposed debiasing step introduced post-alignment.
Parameter-Level Intervention versus Prompt Engineering
Evidence from recent literature demonstrates the persistence of extrapolation bias in aligned LLMs, even under sophisticated prompting regimes, suggesting the bias is encoded in the model’s parameterization rather than surface-level instruction adherence. The authors formalize this through diagnostic tests in controlled AR(1) environments and equity return forecasting, showing that prompt-based techniques yield negligible attenuation of bias. Since the knowledge and inductive biases absorbed during pre-training and alignment persist at inference unless directly intervened upon at the parameter level, the paper motivates the necessity of supervised fine-tuning on rational forecasts.
Debiasing Framework: Dataset Design and LoRA-based SFT
To surgically correct the bias, the methodology employs an out-of-sample evaluation discipline:
- Bias Identification: The base LLM is probed using standard forecasting prompts, producing forecasts that are benchmarked against rational-expectations or realized outcomes, quantifying the extent and direction of extrapolative bias.
- Instructional Dataset: A separate, non-overlapping dataset is constructed. Each prompt is paired with a target response reflecting optimal, bias-free forecasts.
- LoRA-Driven Fine-Tuning: LoRA adapters are attached to the last aligned LLM checkpoint, freezing pretrained weights and learning only a small set of low-rank matrices (typically <1% of the model parameters). This ensures (a) computational efficiency, and (b) retention of general-purpose linguistic capabilities (see Figure 2).
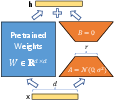
Figure 2: LoRA reparametrization introduces trainable low-rank matrices to transform representations without updating the full LLM weight matrices.
- Early Stopping and Validation: An isolated validation split ensures model selection eschews overfitting.
- Out-of-Sample Testing: The fine-tuned model is evaluated on held-out prompts, never seen during training/tuning phases.
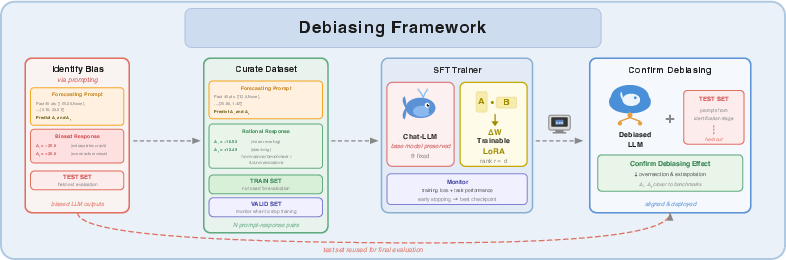
Figure 3: The debiasing framework depends on partitioned datasets and SFT with LoRA for parameter-level intervention, followed by strictly held-out testing.
Controlled Experimental Replication: AR(1) Forecasting
Adapting the design of Afrouzi et al. (2023), baseline Qwen3-32B is used as a subject forecasting AR(1) processes parameterized by varying degrees of persistence (ρ ranging from 0 to 1). The standard error-revision regression
xt+1−Fi,txt+1=a+b(Fi,txt+1−Fi,t−1xt+1)+vi,t
is estimated. Consistent with human subjects, the baseline LLM is found to significantly overreact: for all ρ, the forecast revision coefficient (b) is strongly negative and highly significant, implying that positive forecast revisions systematically predict negative errors.
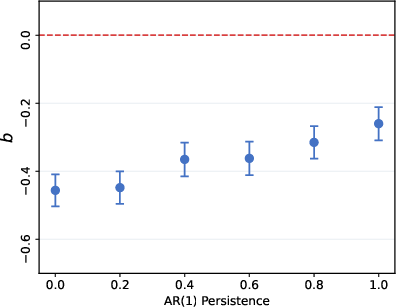
Figure 4: Baseline AR(1) error-revision regression coefficients: substantial negative bias indicates overreaction across all process persistences.
After SFT with LoRA using rational-expectations responses, the overreaction coefficients become statistically insignificant across all values of ρ (point estimates near zero, ∣t∣<2), thus demonstrating that the bias is a learned, not structural, property and can be eliminated through SFT.
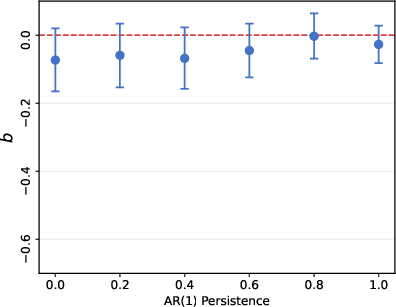
Figure 5: Fine-tuned model AR(1) error-revision regression: bias is statistically eliminated across all process parameters.
Asset Return Forecasting: Cross-Sectional Debiasing
The experiment is extended to S&P 500 stock return prediction, following conventions of empirical asset pricing. Baseline forecasts are strongly extrapolative: regressing forecasts on lagged realized returns yields uniformly positive and highly significant coefficients (e.g., 0.394 for most recent lag, t=53.92), consistent with overextrapolation. Following SFT on realized returns from a pre-specified training window, the fine-tuned LLM demonstrates (i) negative loadings on all lags in the test window (e.g., −0.120 on the most recent), and (ii) alignment with empirical mean reversion properties of asset returns. This establishes that SFT not only debiases forecasting but can also induce empirically-grounded behavior in practical financial settings.
Practical and Theoretical Implications
The demonstrated methodology has direct applications in financial automation, where uncorrected LLMs risk amplifying behavioral inefficiencies—contradicting aims of robo-advisory and algorithmic decision support. By leveraging parameter-efficient SFT, developers can directly align LLM forecasting with rational/empirically optimal benchmarks without sacrificing other capabilities or incurring prohibitive computation costs.
Theoretically, this establishes that widespread LLM biases (e.g., extrapolation, overreaction) are neither inevitable outcomes of Transformer-based architectures nor entirely due to training data contamination—they are malleable under post-alignment fine-tuning. The out-of-sample disciplines enforced here further ensure robustness of corrections, mitigating overfitting concerns.
This parameter-efficient debiasing recipe is directly extensible to other domains (e.g., credit risk assessment, macroeconomic nowcasting, automated prediction markets) wherever rational benchmarks can be precisely specified.
Prospects and Future Directions
The framework presented could catalyze a systematic "debiasing layer" atop LLM-based agent stacks, wherein practitioners routinely retune domain-specific models using rational-response datasets matching deployment contexts. Extending SFT-based debiasing to RLHF-aligned LLMs, other parameter-efficient adapters (e.g., QLoRA, IA3, Prefix-Tuning), and non-forecasting cognitive biases constitutes fertile ground for future research. Furthermore, sharper theoretical work comparing permanence of learned biases at different training phases (pre-training, alignment, SFT) in LLMs would clarify the best locus for debiasing interventions.
Conclusion
This paper substantiates that SFT using LoRA provides an accessible, rigorous methodology for removing persistent extrapolation and overreaction biases from LLMs. By intervening at the parameter level, rather than the prompt or dataset surface, LLMs can be efficiently pushed toward rational and empirically consistent behaviors in forecasting—an imperative development for trustworthy AI agents in high-stakes economic domains.