- The paper introduces a novel zero-shot schema linking approach that decomposes database schemas for effective text-to-SQL conversion.
- It implements a dual-phase method with build-time semantic knowledge base construction and inference-time relevance retrieval.
- Results show improved table recall and token efficiency across large databases, providing a scalable solution for enterprise applications.
RASL: Retrieval Augmented Schema Linking for Massive Database Text-to-SQL
Overview
"RASL: Retrieval Augmented Schema Linking for Massive Database Text-to-SQL" explores techniques for efficiently scaling text-to-SQL interfaces to industrial database environments. The paper introduces a novel architecture that employs schema decomposition and targeted retrieval to leverage semantic units within database metadata. This system does not require domain-specific fine-tuning, presenting a practical solution for deploying text-to-SQL systems across diverse enterprise contexts.
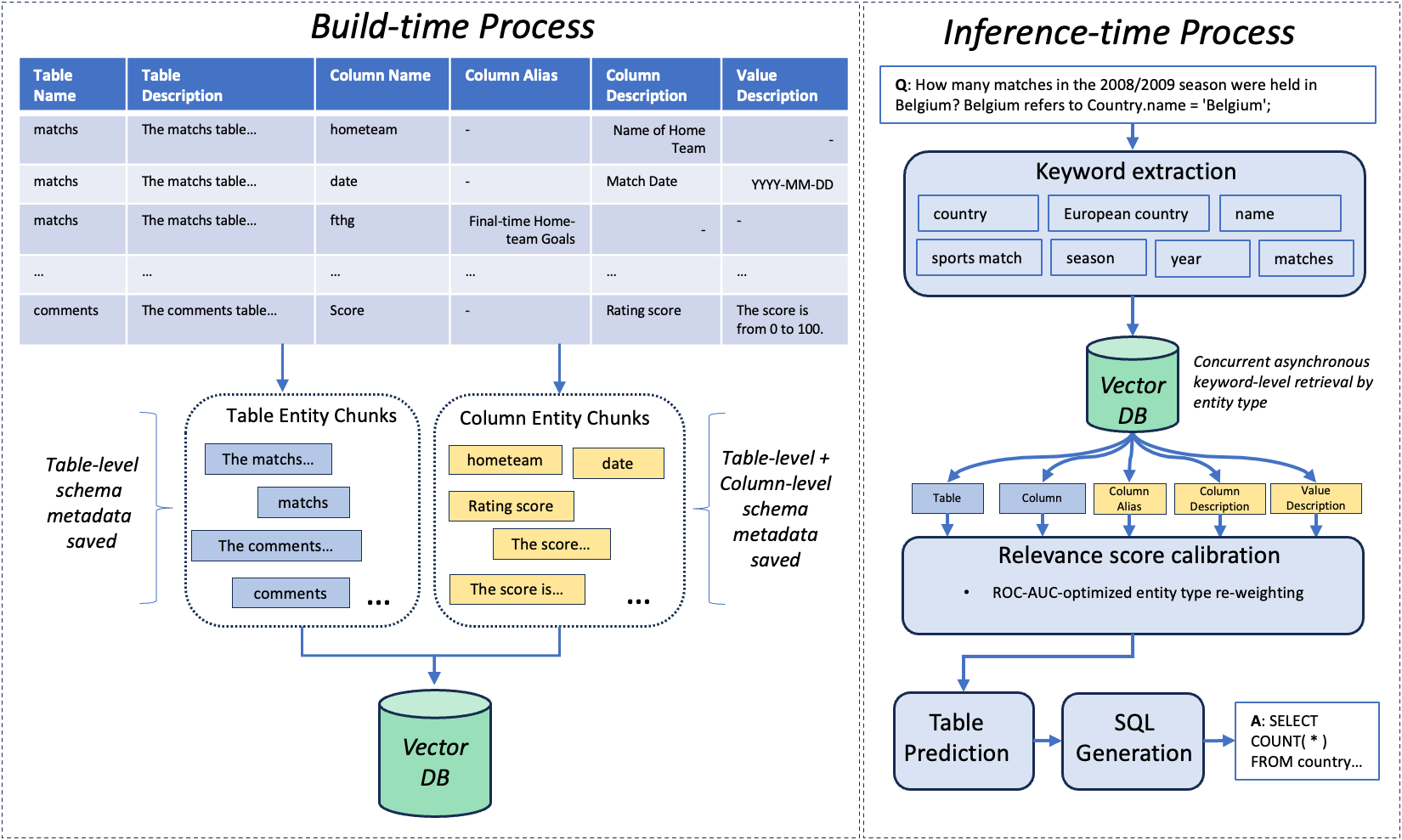
Figure 1: System overview. (left) Build-time process of constructing the schema metadata knowledge base. (right) Inference-time retrieval process for text-to-SQL applications.
Introduction
The paper emphasizes the importance of text-to-SQL systems which interpret natural language questions into executable SQL queries, bridging the skill gap for non-technical users to interact with databases. Despite significant advances, scaling these systems to massive enterprise data catalogs presents challenges due to token limitations and computational constraints associated with LLMs. RASL provides a solution by focusing on schema decomposition, indexing semantic units in a vector database, and applying retrieval augmented schema linking without elaborate fine-tuning processes.
Existing approaches include hierarchical models like DBCopilot, computational frameworks such as CHESS, and table embedding strategies by CRUSH. These, however, suffer from scalability issues or require extensive synthetic training, proving inadequate for dynamic and vast industrial schemas. RASL differentiates itself through zero-shot schema linking architecture, which efficiently uses both table-level and column-level context while remaining adaptable to evolving database structures.
Methodology
RASL's methodology involves a two-phase process:
- Build-time Knowledge Base Construction: Entity decomposition at the schema level creates semantic units that are indexed in a vector database. This indexing enables fast retrieval by leveraging embeddings in high-dimensional space.
- Inference-time Retrieval: The system utilizes a multi-stage retrieval process, focusing on relevance calibration to manage context retrieval effectively. For table prediction, RASL filters tables based on relevancy scores drawn from both level contexts, supplying full schema information exclusively for identified tables to assist in SQL generation.
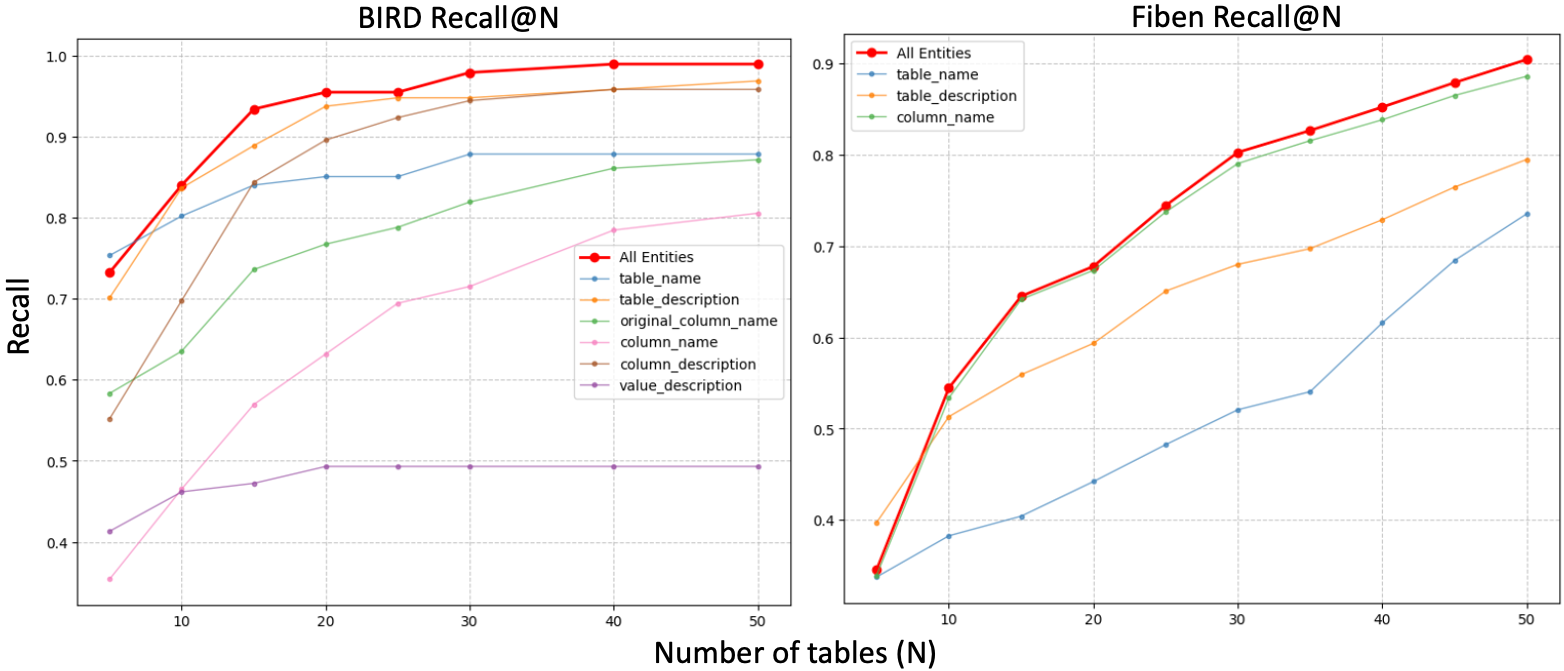
Figure 2: Table Recall@N over BIRD (left) and Fiben (right). BIRD benefits from both Lambda_C and Lambda_T, achieving notable recall improvement over individual lambda at higher N, while Fiben primarily leverages E_C.
Experiments and Results
Experiments demonstrate RASL's high recall rates and effectiveness across datasets like Spider, BIRD, and Fiben. In comparisons against retrieval baselines such as BM25, SXFMR, CRUSH, and DTR, RASL consistently excels in table recall at various context sizes. The results highlight RASL's ability to maintain high precision without extensive fine-tuning of models.
Additional studies illustrate the efficiency of RASL's dual-stage retrieval-prediction approach and the impact of synthesized table descriptions, underscoring the trade-offs between token consumption and accuracy improvements when descriptions are incorporated.
Error Analysis
Through examples of common error cases observed, the paper identifies challenges like assuming schema structure in CRUSH, potentially leading to poor context matches. In contrast, RASL's granular keyword extraction ensures more precise retrieval.
End-to-End SQL Generation
Further, RASL shows superior performance in SQL generation tasks, with more efficient token usage compared to baseline methods. It showcases its scalability in cost analysis, demonstrating reduced input token costs and improved resource efficiency.
Conclusion
RASL provides an efficient framework for querying massive databases using natural language, achieving superior performance while maintaining practical computational constraints. By addressing scalability through innovative schema linkage and retrieval methods, RASL sets the stage for future research in text-to-SQL systems poised to bridge the gap between academic exploration and real-world deployment challenges.
Researchers interested in scalable LLM applications for enterprise data environments will find the insights gathered from RASL's evaluations and proposed methodologies applicable to expanding database querying capabilities on a large scale. Future advancements may focus on refining synthesized context generation and exploring dynamic retrieval approaches for even more enhanced performance.