- The paper surveys the evolution of long-document retrieval techniques using PLMs and LLMs, presenting a unified taxonomy of paradigms and evaluation protocols.
- It addresses key challenges such as evidence dispersion, semantic drift, and segmentation issues that impact retrieval accuracy.
- The study outlines domain-specific applications and future research directions, emphasizing efficiency, scalability, and interpretability.
Survey of Long-Document Retrieval in the PLM and LLM Era
Introduction and Problem Scope
Long-document retrieval (LDR) addresses the challenge of extracting relevant information from documents that far exceed the input limits of standard neural architectures, often spanning thousands to tens of thousands of tokens and exhibiting complex hierarchical structures. Unlike conventional passage-level retrieval, LDR must contend with evidence dispersion, semantic drift, and intricate document organization. The survey systematizes the evolution of LDR methods, from classical lexical and early neural models to modern pre-trained LLMs (PLMs) and LLMs, and provides a unified taxonomy of paradigms, evaluation protocols, and domain-specific applications.

Figure 1: General retrieval methods fail to capture detailed, scattered information in long documents, while long-document retrieval methods excel at organizing and presenting in-depth content from large textual resources.
Core Challenges in Long-Document Retrieval
LDR is distinguished by several technical challenges:
- Sparse and Inconsistent Supervision: Most benchmarks provide coarse document- or paragraph-level labels, while queries often target fine-grained evidence, impeding discriminative learning and fine-grained alignment.
- Document Segmentation and Chunking: Fixed-length chunking disrupts semantic units, leading to fragmentation. Empirical analysis shows that chunk size selection critically affects retrieval performance, with smaller chunks favoring factoid retrieval and larger chunks supporting thematic summarization.
- Computational and Efficiency Constraints: Transformer-based models incur quadratic complexity with input length, making ultra-long sequence processing infeasible without architectural innovations such as sparse attention or input compression.
Taxonomy of LDR Paradigms
The survey organizes LDR methods into four principal paradigms, reflecting the field’s progression in balancing effectiveness, efficiency, and scalability.
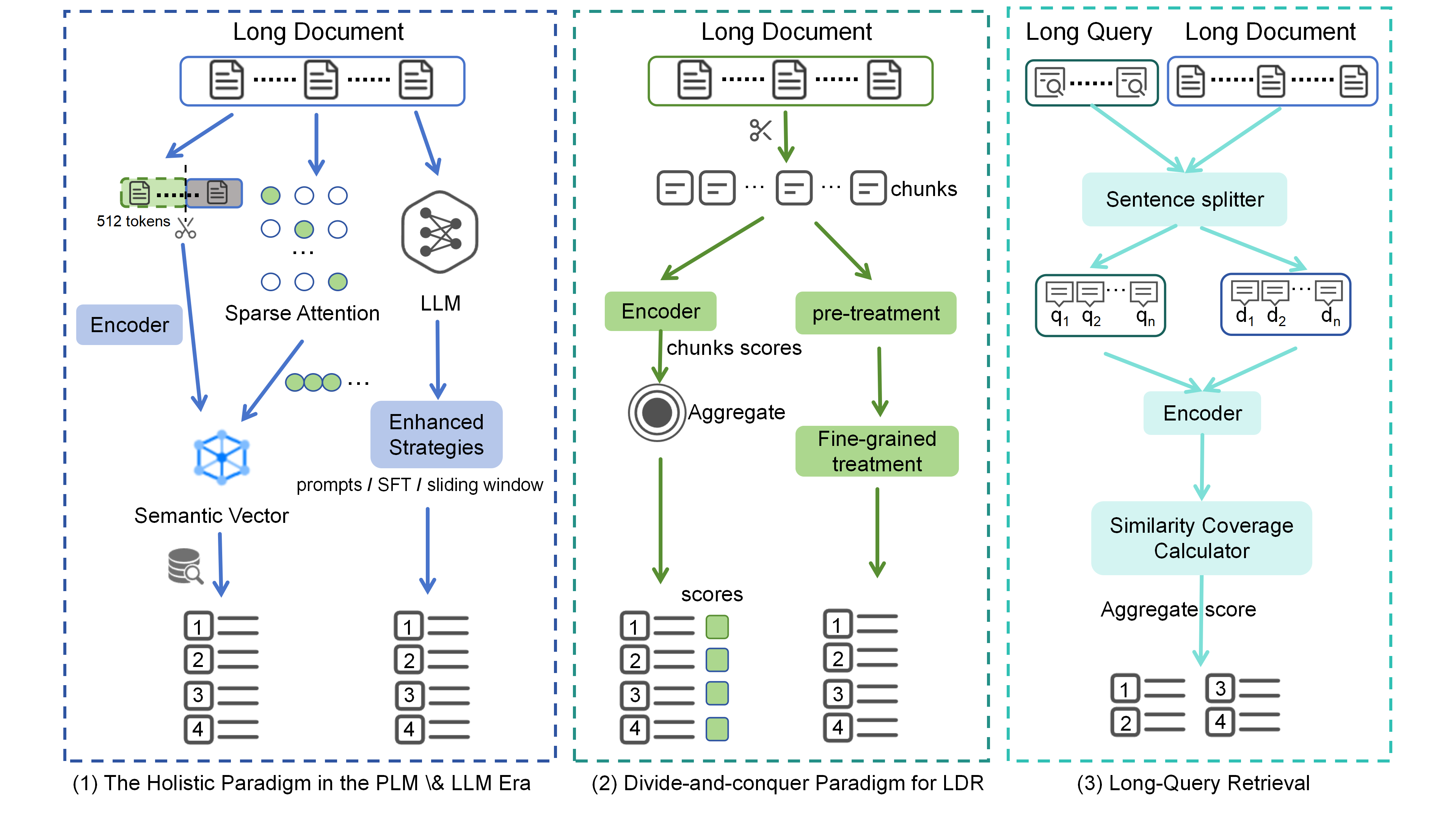
Figure 2: The evolution of long-document retrieval paradigms: holistic modeling, divide-and-conquer segmentation, and long-query retrieval, each addressing distinct challenges in the PLM and LLM era.
Holistic Paradigm
Holistic approaches attempt to model the entire document as a single unit, leveraging long-sequence Transformer architectures (e.g., Longformer, BigBird, Reformer, FlashAttention) and LLM-based rerankers (e.g., RankGPT, RepLLaMA, RankLLaMA). These models preserve global semantics but are limited by context window size and computational cost. Sparse attention and position encoding extensions (e.g., LONGEMBED, M3-Embedding) have expanded context length to 32k tokens, but scalability to multi-document scenarios remains unresolved.
Divide-and-Conquer Paradigm
Divide-and-conquer methods segment documents into smaller blocks, process them locally, and aggregate results. Pooling heuristics (BERT-MaxP/SumP), hierarchical aggregation (PARADE, DRSCM, LTR-BERT, MORES+), and key block selection (IDCM, KeyB, KeyB2, DCS) are prominent strategies. Key block selection, in particular, enables efficient reranking by focusing model capacity on salient evidence, often outperforming full-document rerankers in both effectiveness and efficiency.
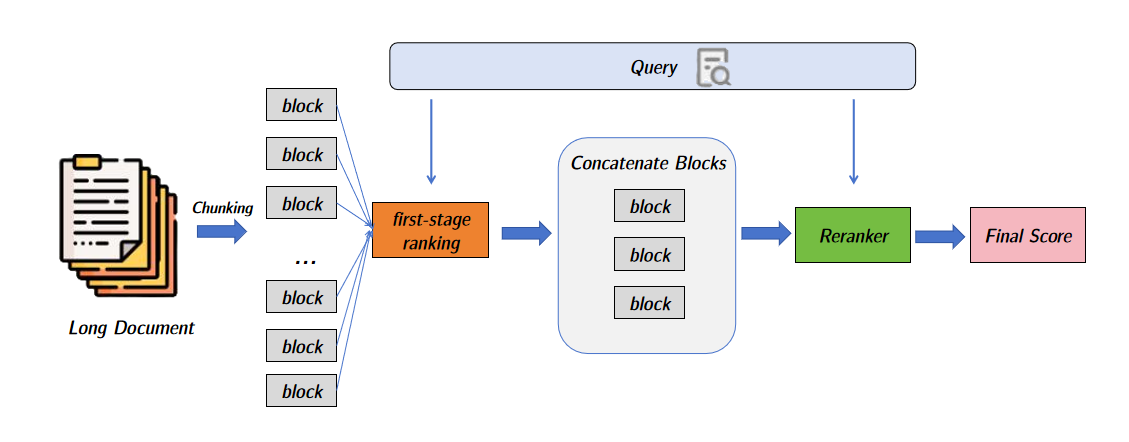
Figure 3: Key block selection workflow: selected blocks are concatenated and reranked, exemplified by models like KeyB.
Hybrid cascades (ICLI, Match-Ignition, Longtriever) integrate local and global semantics, balancing efficiency and comprehensiveness. However, semantic fragmentation and risk of missing distributed signals persist.
Indexing-Structure-Oriented Paradigm
Recent work emphasizes document segmentation and indexing, moving beyond fixed-length chunking. MC-indexing, HELD, and RAPTOR construct semantic or logical hierarchies, enabling multi-view and abstraction-aware retrieval. These methods are orthogonal to model architecture and can be integrated with both sparse and dense retrievers, substantially improving recall and robustness.
Long-Query Retrieval
In domains such as legal and patent search, queries themselves are long documents. Sentence-level bi-encoder models (e.g., RPRS) segment both query and candidate into sentences, compute coverage proportions, and aggregate relevance, enabling scalable and effective retrieval without truncation.
Evaluation Protocols and Benchmarks
Standard IR metrics (nDCG, MAP, Recall@k, MRR, ERR) are widely used but exhibit limitations in LDR due to label sparsity and evidence dispersion. Segment-level and hierarchical recall metrics are necessary for realistic evaluation. Efficiency metrics (latency, index size) and robustness across domains are critical for practical deployment. Benchmarking practices must account for pooling bias, query realism, structure/layout, and reproducibility.
Domain-Specific Applications
LDR has demonstrated utility across multiple domains:
- Legal Retrieval: Models like Lawformer, Legal-BigBird, and LawGPT address hierarchical structure, cross-version mapping, and cross-document reasoning in legal texts.
- Scholarly Paper Retrieval: Citation- and concept-aware encoders (SciBERT, SPECTER, SciNCL), multi-agent systems (PaSa, SPAR), and LLM-enhanced rerankers (PaperQA, DocReLM) support facet-specific search and provenance-grounded retrieval.
- Biomedical Retrieval: Clinical-Longformer, Clinical-BigBird, and BioClinical ModernBERT process long clinical records and literature, integrating multimodal signals and domain-specific knowledge.
- Cross-Lingual Retrieval: Multilingual encoders (mBERT, LaBSE, mGTE, CROSS) and multi-consistency training frameworks (McCrolin) enable semantic alignment and evidence aggregation across languages.
Current Challenges and Future Directions
Key open problems include:
- Efficient Scaling: Sub-linear architectures and indexing schemes are needed to process million-token contexts without loss of fidelity.
- Relevance Localization: Discourse-aware and structure-aware retrieval must be advanced to aggregate distributed signals and enable reasoning across blocks.
- Data Scarcity: Synthetic data generation and cross-task supervision are required to overcome sparse labeling.
- Domain Adaptation: Robust handling of specialized structures and vocabularies in legal, biomedical, and multilingual settings remains underdeveloped.
- Interpretability: Faithful attribution and span-level justification are essential for user trust and auditability.
Future research should focus on unified retrieval–reading models, advances in long-context architectures, retrieval-enhanced LLMs, improved benchmarking, and multimodal integration. Hybrid systems combining efficient indexing, neural encoding, and LLM reasoning are likely to dominate, with next-generation evaluation frameworks capturing attribution, faithfulness, and user utility.
Conclusion
Long-document retrieval is a foundational problem in information retrieval, requiring a balance between computational efficiency and accurate localization of sparse signals in lengthy contexts. The survey synthesizes four complementary paradigms—holistic modeling, divide-and-conquer segmentation, indexing-structure innovation, and long-query retrieval—highlighting the shift toward dynamic, agentic systems empowered by LLMs. No single paradigm suffices; hybrid architectures and user-centered evaluation are essential for trustworthy, deployable LDR systems. As the field advances, deep evidence synthesis and automated knowledge discovery at scale will become increasingly feasible, transforming interaction with large-scale information resources.