- The paper introduces a decomposition method separating layer updates into dominant tokenwise transformations and non-local residuals.
- It shows that tokenwise updates capture most energy through low-dimensional approximations, while residuals display distinct geometric properties that significantly alter outputs.
- Evaluations across architectures demonstrate that model size and function class constraints impact approximation accuracy and the functional relevance of the residual components.
Geometric Structure of Layer Updates in Deep LLMs
Introduction
The paper "On the Geometric Structure of Layer Updates in Deep LLMs" (2604.02459) presents a functional-geometric analysis of how hidden representations are updated from one layer to the next in sequence models such as Transformers and state-space architectures. Departing from representation-centered interpretability paradigms, this work focuses on the structure of transformations mediating transitions between successive hidden states, offering a lens on model dynamics that is agnostic to architecture details.
Framework: Decomposition via Tokenwise Structure and Residuals
The central contribution is a decomposition of layerwise updates into a dominant tokenwise component and a residual term. Specifically, each transition hℓ+1=T(hℓ)+r(hℓ) is split into:
- Tokenwise Transformation T: An input-conditioned, per-token linear map acting locally on each token. Concretely, T(xi)=A(xi)xi where A(xi) is a d×d matrix smoothly varying with the token vector.
- Residual r(hℓ): The remainder that cannot be captured within the constraints of the tokenwise function class.
This decomposition is operationalized by fitting T locally (via k-nearest neighbors in the representation space) for every token, harnessing restricted classes such as low-rank or diagonal linear maps, with the residual interpreted as an empirical signal of what lies outside tokenwise locality.
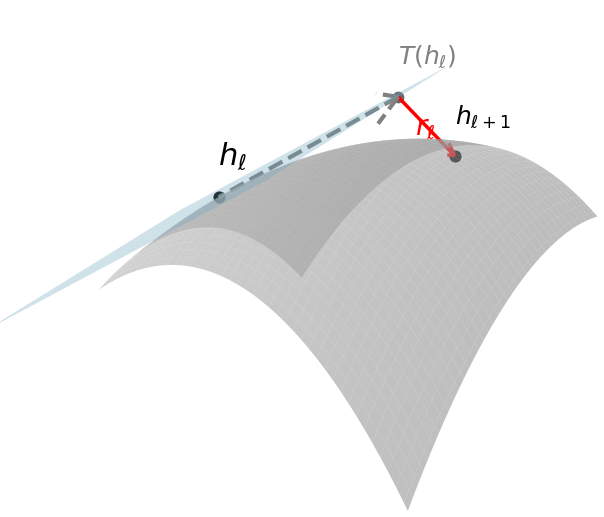
Figure 1: The layerwise update is decomposed into a local linear tokenwise approximation and a residual representing non-local structure.
Geometric Analysis of Layer Updates
The analysis quantifies the geometric alignment between three update vectors per token:
- Full update: hℓ+1−hℓ
- Tokenwise update: T(hℓ)−hℓ
- Residual: T0
Strong alignment is found between the full update and the tokenwise update across layers and models, with cosine similarities near 1 and small angular deviations. The residual, in contrast, displays substantial angular deviation and low alignment, implying it is a geometrically distinct component.
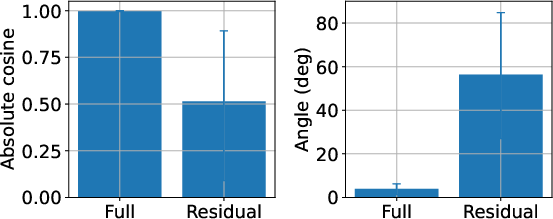
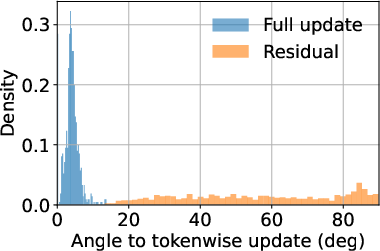
Figure 3: Distribution of alignment summaries for full versus tokenwise and residual versus tokenwise components, highlighting their geometric separation.
Projection analyses further demonstrate that the energy of the full and tokenwise updates is almost entirely recoverable in a low-dimensional subspace defined by T1, while the residual has low projection onto this space.
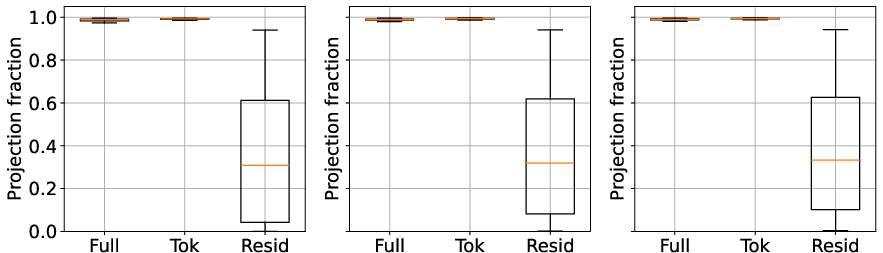
Figure 2: Fraction of energy of updates captured by leading singular vectors (top-1,4,8): residuals remain outside the dominant tokenwise subspace.
Sensitivity analyses show that model size, neighborhood size in local fitting, and the chosen function class (e.g. rank or diagonal constraints) impact the alignment and residual magnitudes. Larger models and higher-rank approximations yield lower errors, but the residual's geometric distinctiveness persists.
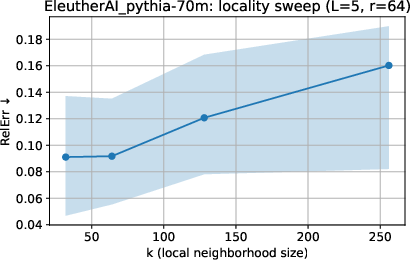
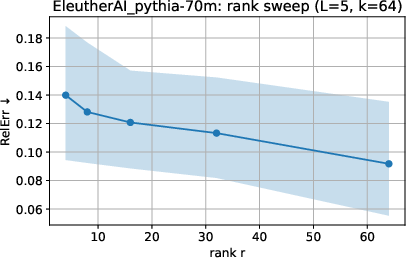
Figure 4: Effect of neighborhood size and rank on approximation error in Pythia-70M; higher locality and larger rank improve the fit but do not eliminate the residual.
Functional Consequences and Error-Output Alignment
The functional relevance of the decomposition is probed by intervening—replacing a layer update with its tokenwise approximation and measuring the impact on the model's output distribution. Output perturbation, quantified by KL divergence, is strongly correlated (Spearman T2 often T3, and up to T4 in large models) with the residual error across models and layers.
This robust finding demonstrates that the geometrically distinct residual component disproportionately contributes to changes in model behavior. Notably, poorly approximated tokens are systematically associated with higher output divergence.
Further, the alignment between residual magnitude and output perturbation varies across layers, pointing to structured regimes where tokenwise approximations either suffice or fail to capture functionally significant updates.
Architectural Trends and Function-Class Dependence
Empirical results across models (e.g. DistilGPT2, Pythia, and Mamba series) suggest both universality and architectural dependency:
- Universality: The geometric separation and functional significance of residuals is observed in both Transformer and state-space architectures, implying a general property not tied to self-attention.
- Architectural Dependence: Smaller models (e.g., DistilGPT2) can be well-approximated by diagonal transformations; larger models benefit from low-rank maps, implicating a richer but structured tokenwise dynamic.
Relation to prior work is established by contrasting this geometric-functional probe with representation-based interpretability methods (e.g., probing, Logit Lens), emphasizing the complementarity and richer understanding enabled by focusing on transformation geometry rather than information content.
Theoretical Implications and Future Directions
The decomposition framework conceptualizes most layerwise transitions as structured reparameterizations along a dominant local axis (the tokenwise component). The residual is consistently shown to:
- Be geometrically non-trivial—neither a small correction nor noise, but situated outside the principal update subspace.
- Be functionally critical, as reflected in its strong association with output changes.
The separation between approximable and ‘residual’ computation is not rigidly dictated by architectural choices, but emerges empirically from learning dynamics and the restriction of function classes.
From a theoretical perspective, these findings suggest:
- Deep LLMs organize computation such that most of the update energy is tokenwise and low-dimensional, but essential, prediction-critical computation is embedded in non-local updates.
- The chosen function class mediates interpretability: higher expressivity can absorb more structure, decreasing residual magnitude but potentially obfuscating functional correspondence.
Two principal open directions are highlighted:
- Residual Structure Analysis: Further structural resolution of residuals—e.g., decomposing within-subspace vs. out-of-subspace interactions, or associating residuals with specific types of contextual computation.
- Interpretability-Expressivity Trade-off: Understanding how increasing the function class’s complexity impacts both approximation quality and the interpretability/functionality alignment of the residual.
Conclusion
This work rigorously delineates the geometric and functional anatomy of layerwise updates in deep LLMs, establishing a framework that isolates a dominant tokenwise direction and a geometrically/behaviorally distinct residual. The findings demonstrate that crucial, prediction-changing computation preferentially resides in this residual, a fact that persists across architectures and model scales. This geometric perspective provides a new, architecture-agnostic tool for interpretability and could inform both mechanistic analysis and novel training paradigms that target functional structure in deep models.