- The paper proposes go-mHC, which offers a direct and exact parameterization of the Birkhoff polytope via generalized orthostochastic matrices with a tunable hyperparameter s.
- It leverages the Cayley transform and block Frobenius projections to achieve efficient spectral coverage and robust convergence in deep neural network training.
- Empirical results show that go-mHC converges faster and scales more effectively than traditional methods, promising enhanced stability and performance in high-dimensional architectures.
Direct Parameterization of Manifold-Constrained Hyper-Connections via Generalized Orthostochastic Matrices
Introduction
The work "go-mHC: Direct Parameterization of Manifold-Constrained Hyper-Connections via Generalized Orthostochastic Matrices" (2604.02309) addresses the open problem of efficiently and exactly parameterizing the set of d×d doubly stochastic matrices—the Birkhoff polytope (Bd)—especially as applied to learned mixing of residual streams in deep networks. Existing approaches either sacrifice computational efficiency (m-lite, factorial scaling) or expressive coverage (KromHC, Kronecker-structured scaling). This paper proposes a construction grounded in generalized orthostochastic matrices (go-m), controlling a single hyperparameter s that affords a balance between computational cost and Birkhoff coverage.
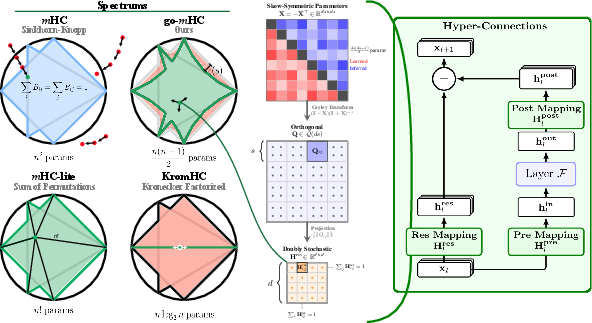
Figure 1: Spectral analysis and architectural integration of go-m. Left: Spectral reach comparison of manifold parameterizations in Bd; m-lites (factorial) reach the boundary, KromHC is highly restricted, while go-m with moderate s densely fills the polytope. Middle: Mapping pipeline via the Cayley transform and block Frobenius projection. Right: Integration within hyper-connected residual streams in deep models.
The method is demonstrated in Manifold-Constrained Hyper-Connections (mHC) and its generalizations, which have emerged as a major design element for deep network stability and scaling. This essay provides a detailed technical exposition of the proposed parameterization, thorough spectral and convergence analyses, empirical performance, and implications for scalable capacity in neural architectures.
Manifold-Constrained Hyper-Connections and the Birkhoff Polytope
Standard residual connections in deep nets are extended in Hyper-Connections (HCs) and mHC by allowing dynamic, learned mixing of d parallel residual streams, with the mixing matrices constrained to Bd. Theoretical motivation and prior empirical results (Xie et al., 31 Dec 2025, Zhu et al., 2024) have shown that exact manifold constraints—the hallmark of mHC—stabilize deep training by bounding the spectral norm, mitigating both vanishing and exploding gradients, and preserving an identity shortcut mapping regardless of depth.
However, covering all of Bd is computationally fraught. Convex combinations of all d! permutations (m-lite) are exact but not tractable beyond small d×d0; Kronecker factorizations (KromHC) scale as d×d1 but are expressively degenerate, representing a vanishing fraction of doubly stochastic matrices. Iterative Sinkhorn normalization (SK) is inexact, incurs an approximation gap, and requires heavyweight custom kernels.
The go-m approach leverages the theory of generalized orthostochastic matrices: any d×d2 doubly stochastic matrix can be approximated arbitrarily closely (and exactly in the d×d3 limit) as a block Frobenius-norm projection of an orthogonal matrix, parametrized as a d×d4 grid of d×d5 blocks. The key hyperparameter d×d6 enables an exact-expressive trade-off—a salient property for scalability in large networks.
Generalized Orthostochastic Parameterization
go-m's construction operates as follows:
- A learnable skew-symmetric matrix d×d7 is formed via low-dimensional parameters (quadratic in d×d8, quadratic in d×d9).
- The Cayley transform maps Bd0 to a special orthogonal matrix Bd1. This avoids the pathologies of the matrix exponential and ensures architectural smoothness.
- The Bd2 mixing matrix is then constructed by projecting onto the Birkhoff polytope via block-wise Frobenius norm: each entry is Bd3.
Crucially, for moderate Bd4 (e.g., Bd5), the set Bd6 nearly fills Bd7 (in terms of spectral and geometric volume), with Bd8 corresponding to the "orthostochastic boundary" and higher Bd9 interpolating toward the full interior.
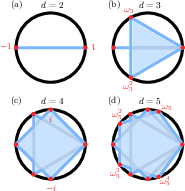
Figure 2: The Karpelevič region for s0, with s1 to s2. The region encodes all possible spectra of stochastic matrices; orthostochastic matrices (black) are a proper (hypocycloidal) subset.
The Cayley transform's norm-preserving characteristics and avoidance of the saturated softmax nonlinearity further lead to improved optimization properties—accelerated convergence, absence of gradient vanishing, and enhanced numerical stability.
Expressivity: Spectral Analysis and Limitations of Prior Approaches
Expressivity is rigorously benchmarked via the spectral reach—the subset of the Karpelevič region in the complex plane accessible by eigenvalues of parameterized mixing matrices.
- m-lite (Birkhoff-von Neumann convex combinations) essentially fills the boundary of s3 but is computationally prohibitive for s4.
- KromHC is formally confined to low-dimensional subspaces, representing only spectra associated with Kronecker products of permutations; complex cycles and off-boundary interior points are omitted asymptotically as s5 increases.
- go-m with s6 fills the Karpelevič region's interior with high density, as shown both empirically and via mathematical guarantees (Nechita et al., 2023).
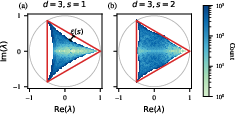
Figure 3: Histogram of spectral reach for s7-orthostochastic parameterization (s8, s9). For Bd0, the spectrum fills a finite region with a hypocycloidal geometry; Bd1 nearly covers the full region.
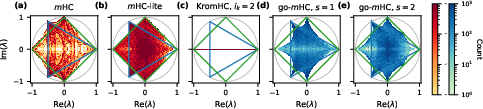
Figure 4: Comparative spectral reach in Bd2 for SK-projected (m), m-lite, KromHC, and go-m (Bd3). go-m exhibits near-complete coverage for small Bd4, in contrast to KromHC's highly restricted expressivity.
These results establish that go-m preserves a scalable balance of expressivity and computational tractability, outperforming all previous exact parameterizations in terms of Birkhoff coverage for practical Bd5.
Parameter and Computational Complexity
The parameter count for a single go-m mixing matrix is Bd6, with cubic FLOP complexity Bd7 per layer. This makes it several orders of magnitude more efficient than m-lite, yet with substantially higher expressivity than KromHC, which scales as Bd8. The efficient mapping between trainable parameters and resultant doubly stochastic matrices avoids custom CUDA kernels and iterative normalization entirely.
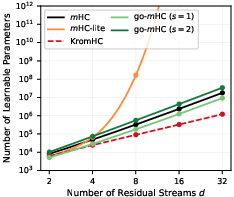
Figure 5: Scaling of learnable parameter counts for m, go-m (Bd9), m-lite, and KromHC as a function of s0; m-lite becomes immediately intractable for s1, while go-m and KromHC provide scalable alternatives.
The construction naturally composes with Kronecker-structured schemes, allowing the size of Kronecker factors (s2) to be increased without encountering m-lite's factorial blow-up, effectively bridging the gap between parameter economy and expressive power.
Empirical Convergence and Optimization Dynamics
Synthetic "toy model" experiments, in which random s3 doubly stochastic targets are reconstructed from noisy inputs, confirm several properties:
- go-m (s4) achieves loss floors at the theoretical optimum (noise floor), matching m-lite, but does so up to s5 faster in convergence steps.
- KromHC incurs a large, dimension-dependent final error due to limited expressivity, and converges slowly.
- These trends are robust to sparsity, optimizer choice (SGD, Adam), target matrix sampling, and include read/write symmetry-breaking projections.
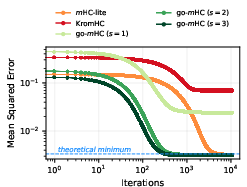
Figure 6: Training loss on a representative s6 stream mixing task. go-m converges rapidly and to the optimal floor, outperforming m-lite and KromHC, the latter stalling at a higher error due to expressivity constraints.
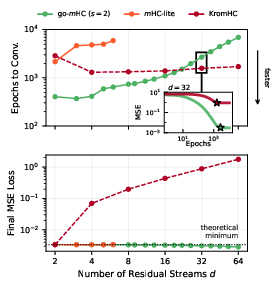
Figure 7: Top: Epochs to convergence increase mildly with s7 for go-m. Bottom: m-lite and go-m reach the optimal MSE for all s8; KromHC error grows linearly with s9.
Large-scale ablations confirm these findings for a range of d0, d1, input sparsity, and optimization details. Furthermore, go-m's avoidance of the exponential nonlinearity (softmax/Sinkhorn) is shown to be central in avoiding the vanishing gradient regime—empirical analyses identify this as a bottleneck in m-lite.
Validation in LLMs
Experiments on a 30M parameter GPT-style model (nanoGPT on TinyStories) demonstrate that go-m, m-lite, and KromHC all perform comparably on standard metrics (cross-entropy loss, gradient norm stability) for d2, but only go-m and KromHC scale tractably beyond d3, reinforcing go-m's advantage for the scaling regime of interest.
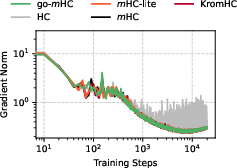
Figure 8: Gradient norm evolution during training for HC, m-lite, KromHC, and go-m. All exact manifold-constrained variants exhibit smooth, non-pathological gradient flow, in contrast to unconstrained HC.
Machine-graded sample generations show that go-mHC achieves or exceeds baseline performance (grammar, consistency, and creativity), with statistical parity in human-in-the-loop and GPT-based LLM-as-a-judge evaluations, confirming practical viability for real architectures.
Theoretical and Practical Implications
This construction unlocks practical manifold parameterizations for large-scale models exploiting multidimensional residual topologies. The method's intrinsic exactness and tunable expressivity establish d4 as a new axis for model scaling, orthogonal to width and depth. Additionally, products of independent doubly stochastic matrices show depth decoupling, with long-range convergence to the barycenter—potentially simplifying gradient lightcones and enabling novel forms of distributed computation and layer parallelism.
Future Research Directions
The introduction of d5-orthostochastic parameterization in network components paves the way for several research directions:
- Scalability in Large LLMs: Exploring capacity gains and convergence behavior in high-d6 models, far beyond the m-lite tractability barrier.
- Alternative Orthogonal Parametrizations: Investigating computationally favorable alternatives to the Cayley transform (e.g., Householder, Hurwitz parametrizations) to minimize inversion overhead.
- Task-Adaptive Expressivity Tuning: Learning or scheduling the block size d7 as a hyperparameter, adapting expressivity per layer or per task.
- Composition with Kronecker Products: Layering KromHC and go-m for hybrid scaling—balancing FLOP cost, memory, and expressivity as dictated by hardware and application constraints.
- Gradient Dynamics: A formal study of information retention, spectral shrinking, and the long-term implications of depth decoupling induced by manifold constraints.
Conclusion
go-m introduces an exact, scalable, and tunable parameterization of the Birkhoff polytope for hyper-connections in neural networks, leveraging the algebraic structure of generalized orthostochastic matrices. It ameliorates the long-standing expressivity/complexity trade-off and validates its theoretical guarantees in both synthetic and real-world settings. This general construction is immediately applicable wherever doubly stochastic parameterizations are desired (e.g., attention, routing, normalization), and is poised to enable novel architectures exploiting high-dimensional residual topologies for future AI systems.

