Published 24 Jul 2025 in cs.LG, cs.AI, and cs.CL | (2507.18071v2)
Abstract: This paper introduces Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant reinforcement learning algorithm for training LLMs. Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. We demonstrate that GSPO achieves superior training efficiency and performance compared to the GRPO algorithm, notably stabilizes Mixture-of-Experts (MoE) RL training, and has the potential for simplifying the design of RL infrastructure. These merits of GSPO have contributed to the remarkable improvements in the latest Qwen3 models.
The paper introduces a sequence-level off-policy correction method that replaces high-variance token-level importance weighting in RL.
It leverages a normalized importance ratio computed over entire sequences to enhance stability and efficiency, particularly in MoE architectures.
Empirical results show improved training accuracy and benchmark performance compared to token-based methods, reducing the need for complex stabilization strategies.
Group Sequence Policy Optimization: A Sequence-Level Approach to Stable RL for LLMs
Introduction
Group Sequence Policy Optimization (GSPO) addresses critical stability and efficiency challenges in reinforcement learning (RL) for LLMs, particularly in the context of Mixture-of-Experts (MoE) architectures. The paper identifies fundamental flaws in token-level importance weighting, as used in @@@@1@@@@ (GRPO), and introduces a theoretically grounded, sequence-level alternative. GSPO aligns the unit of off-policy correction with the unit of reward, resulting in improved training stability, efficiency, and performance, and obviates the need for complex stabilization strategies such as Routing Replay in MoE RL.
Motivation and Theoretical Foundations
The instability of GRPO is traced to its misapplication of importance sampling at the token level. In GRPO, the importance ratio is computed for each token as wi,t(θ)=πθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t), but this approach introduces high-variance noise, especially for long sequences, due to the lack of averaging over multiple samples as required by importance sampling theory. This noise accumulates and is exacerbated by the clipping mechanism, leading to catastrophic and often irreversible model collapse during RL training of large LLMs.
GSPO resolves this by defining the importance ratio at the sequence level:
si(θ)=(πθold(yi∣x)πθ(yi∣x))1/∣yi∣
This formulation ensures that the off-policy correction matches the granularity of the reward, which is also sequence-level. The sequence-level importance ratio is further normalized by sequence length to control variance and maintain a consistent numerical range across varying response lengths.
This contrasts with GRPO, where token-level importance ratios introduce instability due to their high variance and sensitivity to expert routing in MoE models.
A token-level variant, GSPO-token, is also introduced for scenarios requiring finer-grained advantage adjustment, such as multi-turn RL. However, when all token advantages are set equal, GSPO-token is numerically equivalent to GSPO.
Empirical Results
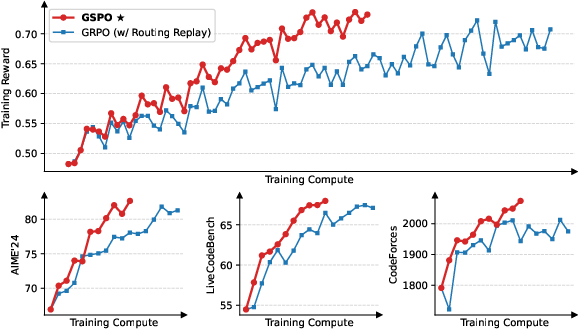
GSPO demonstrates superior training stability and efficiency compared to GRPO across multiple benchmarks, including AIME'24, LiveCodeBench, and CodeForces. Notably, GSPO achieves higher training accuracy and benchmark performance under equivalent compute and data budgets.
Figure 1: Training curves of a cold-start model fine-tuned from Qwen3-30B-A3B-Base, showing GSPO's higher training efficiency compared to GRPO.
A key empirical observation is that GSPO clips a much larger fraction of tokens than GRPO—by two orders of magnitude—yet still achieves better training efficiency. This counter-intuitive result highlights the inefficiency and noisiness of GRPO's token-level gradient estimates, whereas GSPO's sequence-level approach provides a more reliable learning signal.
Figure 2: Average fractions of clipped tokens over the RL training of GSPO and GRPO, illustrating GSPO's higher clipping rate but superior efficiency.
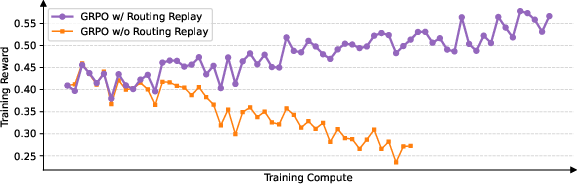
MoE Training and Routing Replay
MoE models present unique challenges due to expert-activation volatility. In GRPO, the set of activated experts for a given response can change significantly after each gradient update, causing token-level importance ratios to fluctuate and destabilize training. The Routing Replay strategy, which caches and reuses expert routing decisions, is required for GRPO to converge in MoE RL but introduces additional memory and communication overhead.
GSPO eliminates the need for Routing Replay by focusing on sequence-level likelihoods, which are robust to changes in token-level expert activation. This simplification not only stabilizes training but also allows the MoE model to utilize its full capacity without artificial constraints.
Figure 3: The Routing Replay strategy is essential for GRPO's convergence in MoE RL, but GSPO obviates this requirement.
Implications for RL Infrastructure
GSPO's reliance on sequence-level likelihoods, rather than token-level, increases tolerance to precision discrepancies between training and inference engines. This enables direct use of inference engine likelihoods for optimization, reducing the need for recomputation and facilitating more efficient RL infrastructure, especially in disaggregated training-inference frameworks and multi-turn RL scenarios.
Conclusion
GSPO provides a theoretically sound and empirically validated solution to the instability and inefficiency of token-level importance weighting in RL for LLMs. By aligning the unit of off-policy correction with the unit of reward, GSPO achieves superior stability, efficiency, and performance, particularly in large-scale and MoE settings. The elimination of complex stabilization strategies and improved infrastructure compatibility position GSPO as a robust foundation for future RL scaling in LLMs. Future work may explore further extensions to multi-turn and partially observable RL, as well as integration with advanced reward modeling and credit assignment techniques.