- The paper demonstrates that incorporating structured medical knowledge as spatial priors overcomes limitations of latent prompting, delivering improved localization of pathologies in radiological images.
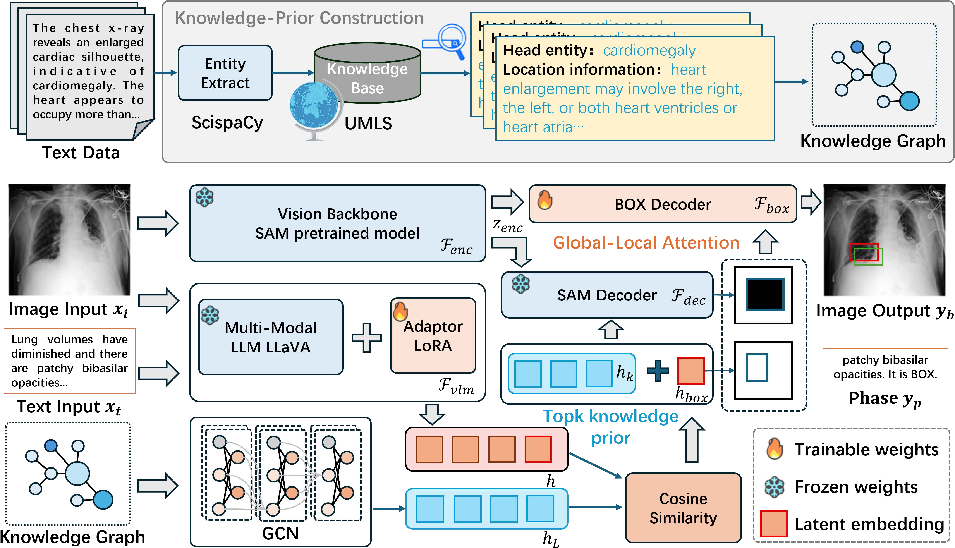
- It introduces the KnowMVG framework, which combines a knowledge-enhanced prompting strategy with a global-local attention module to optimize spatial discrimination.
- Experimental results on multiple datasets show significant improvements in mIoU and AP50 benchmarks, confirming the framework’s clinical applicability.
Knowledge-Guided Spatial Prompts for Enhanced Medical Visual Grounding
Introduction
Medical Visual Grounding (MVG) is essential for associating free-text radiological findings with spatially localized evidence in medical images, thus improving interpretability and aiding clinical decision-making. While Vision-LLMs (VLMs) have demonstrated robust multimodal reasoning, their reliance on latent token prompts leads to diffuse or unstable attention, insufficient for high-precision medical grounding. The paper "Enhancing Medical Visual Grounding via Knowledge-guided Spatial Prompts" (2604.01915) addresses this deficiency by explicitly injecting structured medical knowledge as spatial priors and synergizing global and local attention mechanisms, yielding improved spatial discrimination and interpretability.
Limitations of Latent Token Prompting in Medical Visual Grounding
The authors systematically analyze the limitations of current VLM-based MVG, identifying an attention gap at the decoder stage, which manifests as poorly-aligned or distracted spatial predictions when using latent text embeddings.
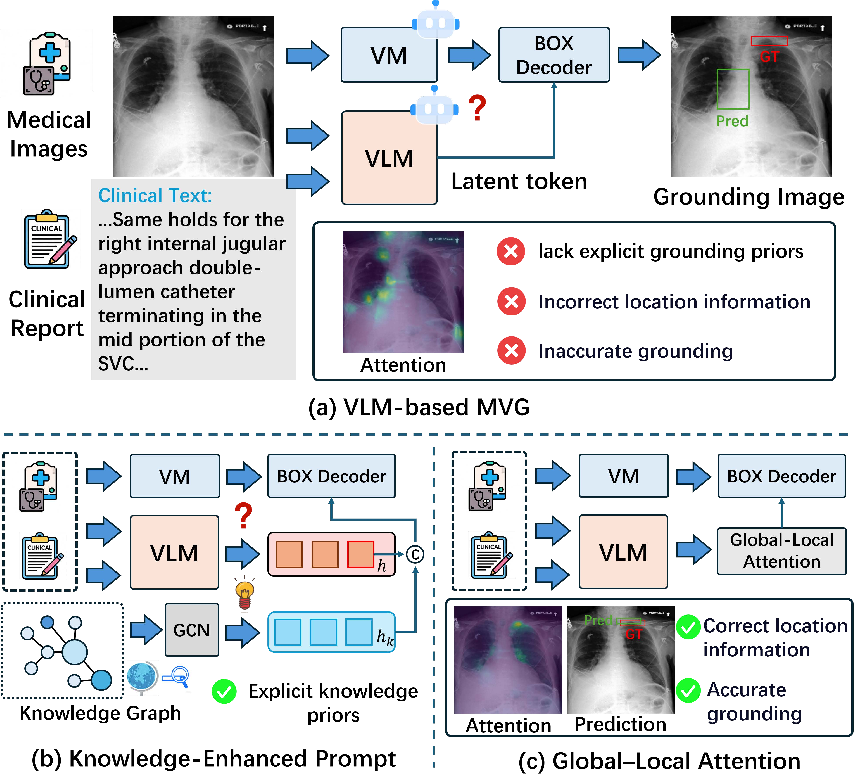
Figure 1: Motivation and architectural comparison for MVG: (a) Latent prompts yield ambiguous attention; (b) Knowledge prompts provide phrase-level priors; (c) Global-local attention achieves accurate and consistent grounding.
Latent token prompts, lacking structured anatomical priors, fail to guide the model toward clinically relevant spatial regions, especially in the presence of limited annotations and ambiguous pathologies. The analysis demonstrates that explicit, structured knowledge injection is required to bridge the gap between high-level semantics and spatial localization.
KnowMVG: Knowledge-Enhanced Prompting and Global-Local Attention
The proposed KnowMVG framework addresses the identified deficiencies with two core contributions: the Knowledge-Enhanced Prompting Strategy (KPS) and a Global-Local Attention (GLA) module.
1. Knowledge-Enhanced Prompting Strategy (KPS):
- Key diagnostic phrase entities are extracted from clinical texts and mapped to anatomical localizations via UMLS and SciSpaCy.
- A dataset-specific relational knowledge graph encodes entity-localization relations.
- Graph convolutional embeddings are constructed from the knowledge graph, yielding phrase-aware, compact spatial priors.
- Top-k knowledge prompts are selected based on similarity to multimodal representations, avoiding the inference overhead of lengthy textual augmentation and providing high-level constraints directly to the decoder.
2. Global-Local Attention (GLA):
Experimental Evaluation
KnowMVG is benchmarked on four datasets targeting both phrase- and task-level variants (MRG-MS-CXR, MRG-ChestX-ray8, MRG-MIMIC-VQA, and MRG-MIMIC-CLASS). In all settings, KnowMVG consistently outperforms baselines on all spatial precision metrics, including AP50 and mIoU.
Key quantitative highlights:
- On MRG-MS-CXR, KnowMVG improves mIoU to 50.31% and AP50 to 56.29%, representing a 2.6% and 3.0% advancement over prior state-of-the-art.
- On the more challenging MRG-ChestX-ray8 with GPT-generated reports, KnowMVG achieves an mIoU of 41.13% and robust AP performance, demonstrating resilience to noisy textual input.
- Task-extensive evaluation with VQA- and category-derived queries confirms generalization: KnowMVG attains an mIoU of 50.40% in category-level grounding, outperforming all baselines.
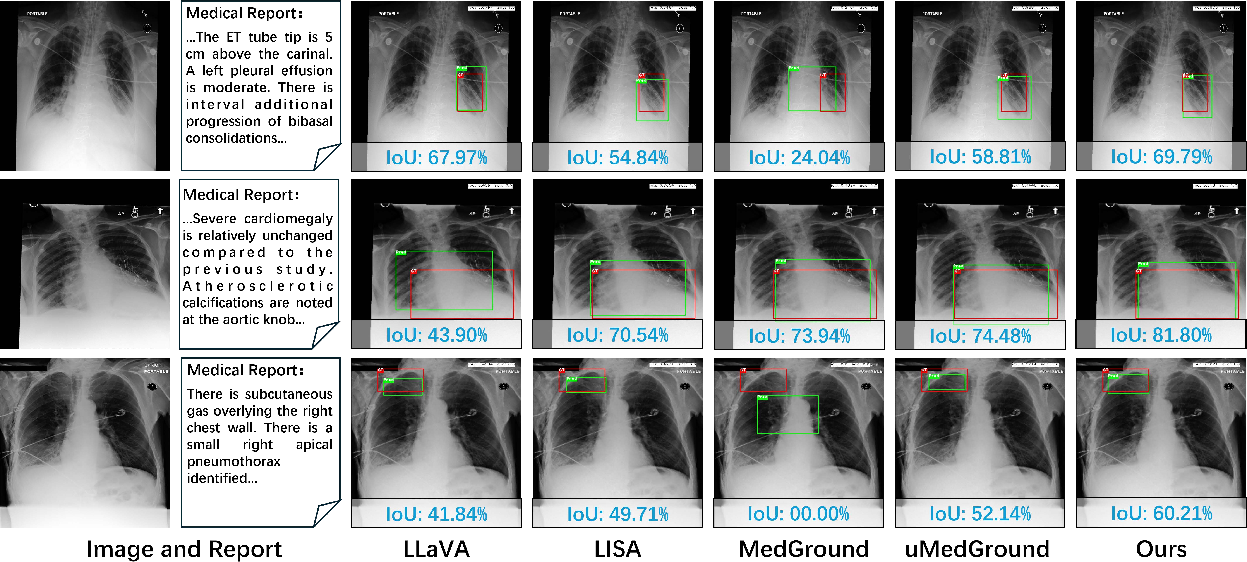
Figure 3: Visual comparison of MVG methods on MRG-MS-CXR; KnowMVG produces well-aligned, compact boxes, even in subtle abnormalities.
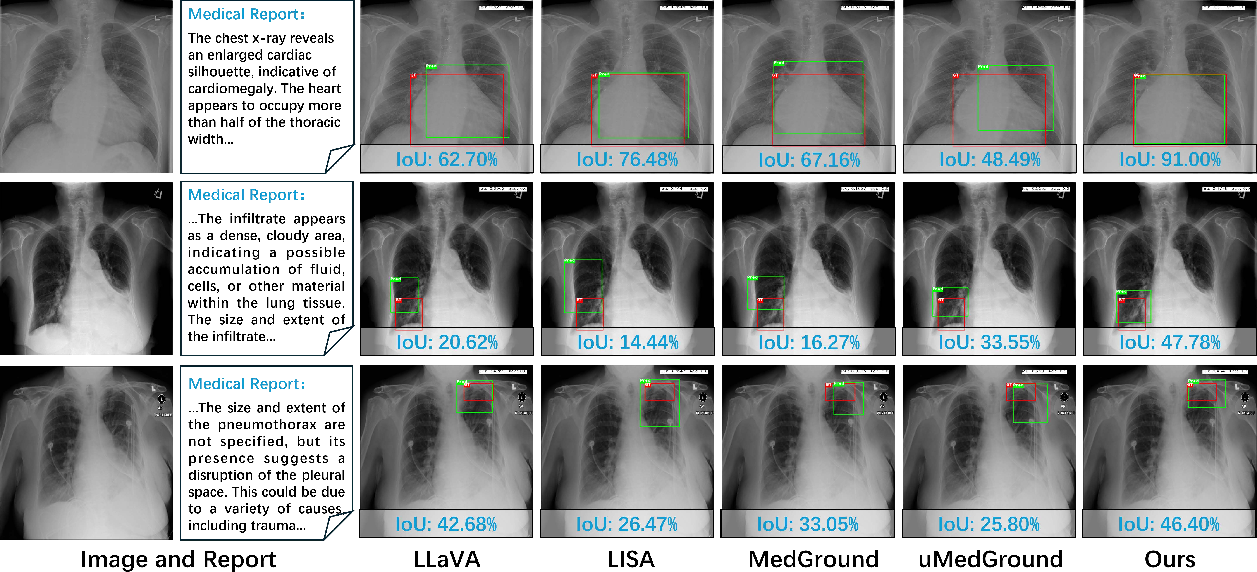
Figure 4: MVG results on ChestX-ray8; the method demonstrates robust spatial grounding in the presence of noisy, generated reports.
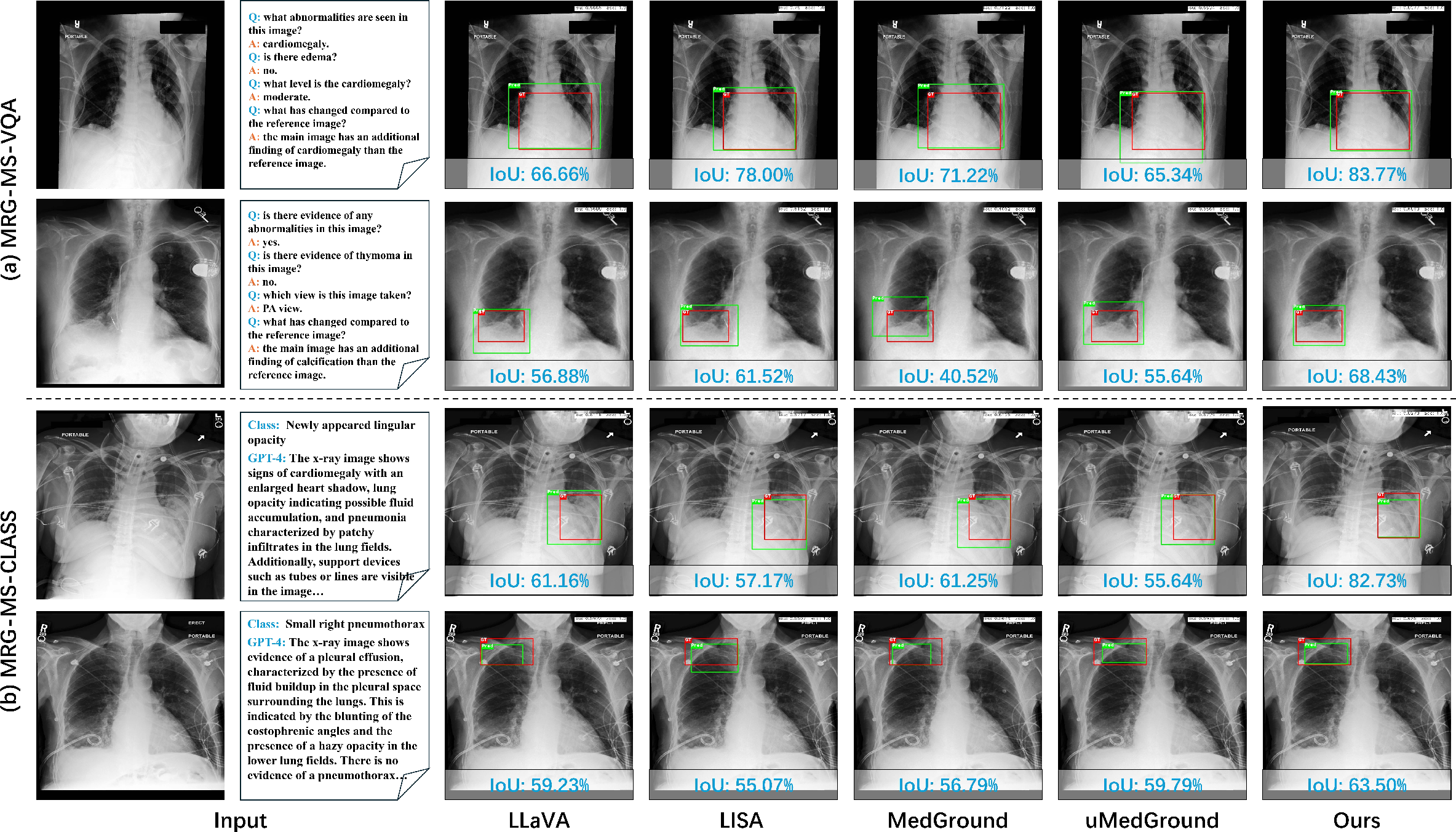
Figure 5: KnowMVG exhibits strong generalization under VQA and category-level input, outperforming prior models in spatial localization.
Qualitative analyses further indicate that traditional and VLM-based baselines are frequently distracted by salient regions unrelated to pathology, while KnowMVG, with anatomy-informed priors, achieves accurate box placement even for subtle or weakly described lesions.
Ablations and Attention Analysis
A comprehensive ablation study isolates the contributions of KPS and GLA:
- KPS alone yields substantial low-threshold AP gains, confirming that structured medical knowledge improves gross localization.
- GLA enhances high-threshold AP and mIoU, necessary for fine-grained boundary alignment.
- The combination delivers optimal results, underscoring the complementarity of semantic priors and multi-scale spatial attention.
Attention map visualization reveals more concentrated and pathology-aligned activations for KnowMVG relative to MedGround and uMedGround. Traditional latent token prompting methods generate diffuse and sometimes off-target attention, whereas KnowMVG's attention is compact and semantically consistent.
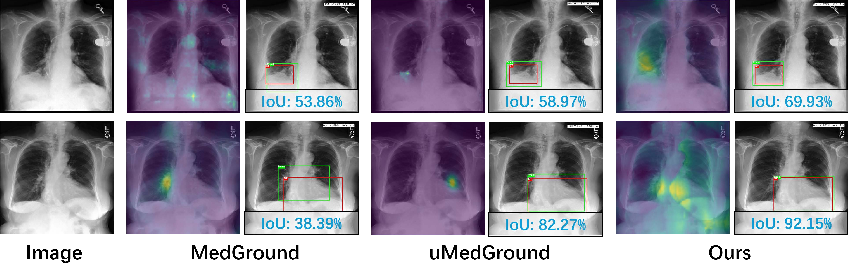
Figure 6: Attention maps show that KnowMVG focuses on clinically relevant regions; baselines exhibit scattered or misaligned responses.
Practical and Theoretical Implications
KnowMVG presents a scalable, annotation-efficient framework that augments VLM-based radiology systems with explicit medical knowledge priors, dramatically enhancing interpretability and reliability. The modular prompting mechanism and decoupled dual-decoder architecture facilitate seamless integration with emerging foundation models and domain-specific ontologies. By reducing dependence on extensive phrase-level annotation and improving generalization to noisy or abstracted clinical text (e.g., VQA, category descriptions), KnowMVG increases the applicability of MVG in real-world clinical workflows.
On the theoretical front, this work highlights the critical limitation of implicit semantic-to-spatial translation in VLMs for medical tasks and establishes the value of explicit, structured knowledge and multiscale attention for bridging this gap. Future VLMs for medical applications should further explore hierarchical, context-aware prompting and integration of richer domain-specific ontologies, potentially extending to graph-augmented transformers or multimodal knowledge graph reasoning architectures.
Conclusion
The KnowMVG framework substantially advances medical visual grounding by addressing the semantic-spatial dissociation inherent in existing VLM pipelines. By leveraging knowledge-guided spatial prompts and a synergistic global-local attention strategy, it achieves robust gains in both spatial precision and clinical interpretability across diverse datasets and task formulations. The results support the broader adoption of structured knowledge priors and multiscale attention in medical foundation models and open promising avenues for future research on knowledge-augmented, interpretable multimodal AI systems for healthcare.