- The paper introduces KG-CMI, a multimodal framework that integrates graph-based medical knowledge with vision and text to improve Med-VQA performance.
- It leverages a fine-grained cross-modal alignment module and a novel cross-Mamba interaction block to reduce computational complexity.
- Experimental results show KG-CMI achieves state-of-the-art accuracy on benchmarks with superior interpretability and scalability for clinical applications.
Knowledge Graph Enhanced Cross-Mamba Interaction for Medical Visual Question Answering: A Technical Analysis
Introduction and Motivation
Medical Visual Question Answering (Med-VQA) requires deep integration of vision and language, underpinned by domain-specific knowledge. Existing methods often fail to capture fine-grained semantics and the crucial associations between pathological image features and clinical textual information. Conventional classification-based Med-VQA models are hampered by their reliance on closed answer sets and lack flexibility for nuanced, open-ended clinical questions. This paper introduces KG-CMI, a cross-modal learning framework that utilizes external medical knowledge graphs and a new cross-Mamba interaction mechanism, yielding substantial improvements in multimodal medical QA. The architecture is tailored to address alignment, knowledge reasoning, scalable interaction, and generative capabilities.
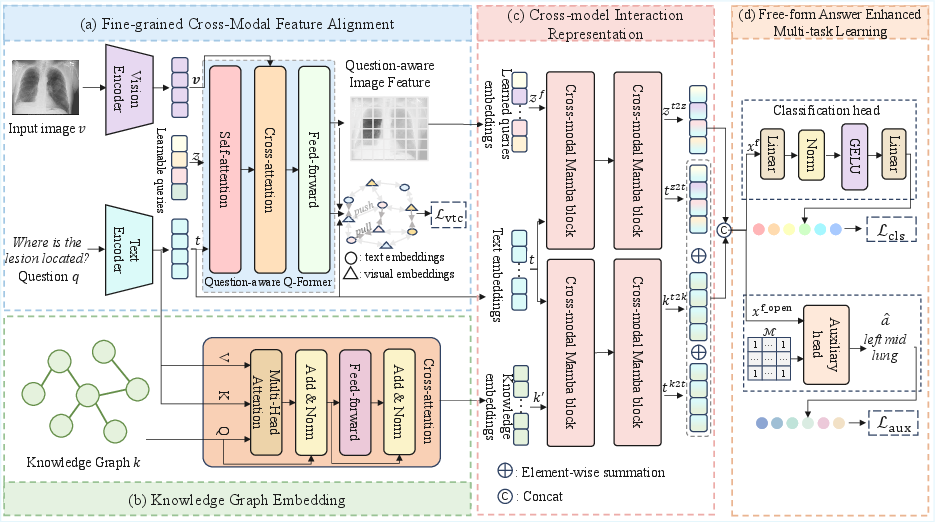
Figure 1: The overall architecture of KG-CMI, illustrating the sequential flow from visual-text feature alignment through knowledge graph integration to cross-modal reasoning and multi-task learning.
Methodology
Fine-Grained Cross-Modal Feature Alignment
KG-CMI starts with a Fine-Grained Cross-Modal Feature Alignment (FCFA) module, leveraging a ViT backbone for image encoding and RoBERTa for question embedding. Central to the alignment is the question-aware Q-Former (QQ-former), a lightweight transformer variant combining self- and cross-attention over image and text queries. Cross-modal contrastive loss is employed to enforce tight semantic correspondence between regions of interest in medical images and language tokens, thus improving alignment at the representation level.
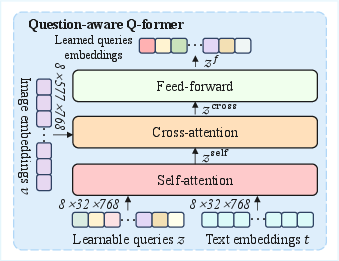
Figure 2: The question-aware Q-Former (QQ-former) applies targeted self- and cross-attention mechanisms to bond visual and textual features.
Knowledge Graph Embedding and Integration
The Knowledge Graph Embedding (KGE) module encodes structured medical domain knowledge (e.g., diseases, organs, findings) via a GAT, facilitating dynamic information flow based on the input question context. The medical knowledge graph provides relational priors that guide the model in associating subtle visual features with clinical concepts, filling the reasoning gap left by pure image-text models.
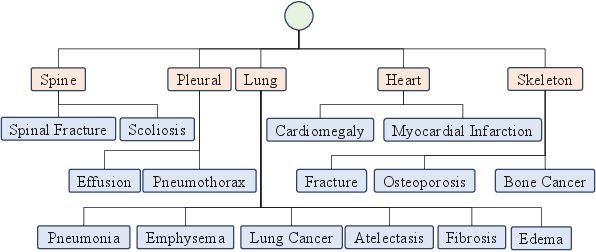
Figure 3: Example of a three-level medical knowledge graph, showing global, organ, and finding nodes with their relationships.
The GAT-based node aggregation ensures essential anatomical and pathological knowledge supports both frequent and rare disease scenarios, promoting out-of-distribution inference and enhanced clinical interpretability.
Cross-Modal Mamba Interaction
KG-CMI introduces the Cross-modal Mamba (CMM) block within its Cross-Modal Interaction Representation (CMIR) module. This replaces standard transformer cross-attention to address the quadratic complexity inherent in cross-modal sequence modeling. The Mamba approach implements selective state-space scans, achieving linear complexity and scaling effectively to long multimodal sequences common in clinical datasets. The CMM interleaves visual, textual, and knowledge-graph features through learned fusion operations, enabling more expressive and precise semantic fusion across modalities.
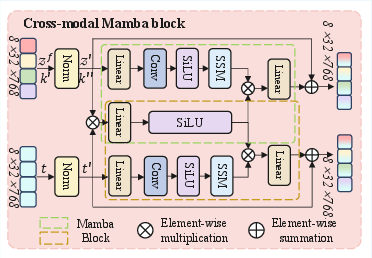
Figure 4: The architecture of the Cross-modal Mamba (CMM) block, enabling efficient, selective interaction among vision, language, and knowledge features.
To support flexible response formats beyond closed vocabulary classification, KG-CMI adopts a Free-form Answer enhanced Multi-Task (FAMT) module. It introduces an auxiliary generative head using a T5 decoder, masked to focus only on open-ended QA samples, in parallel with the standard classification head. Multi-task loss combines classification, contrastive alignment, and auxiliary generative objectives, driving robust feature learning and improving model generalization.
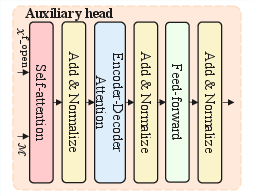
Figure 5: Architecture of the Auxiliary Head (AHead)—a masked, question-type aware generative module based on T5.
Experimental Validation and Results
Benchmark Comparison
KG-CMI achieves state-of-the-art performance on SLAKE, VQA-RAD, and OVQA datasets, surpassing previous best methods in both closed- and open-ended question accuracy. The framework shows particularly notable improvements on OVQA open-ended performance, indicating superior generalization and knowledge transfer.
Key results:
- SLAKE overall accuracy: 84.26% (↑0.18% over previous best)
- VQA-RAD overall accuracy: 78.21%
- OVQA overall accuracy: 79.58% (↑4.26%)
The improvements are statistically significant and consistent across five independent runs.
Ablation and Component Analysis
Ablation studies demonstrate that each architectural module—QQ-former, contrastive loss, KGE, CMM, and AHead—confers incremental performance benefits. Exclusion of any module leads to a measurable decrease in both open- and closed-ended metrics, confirming their complementary roles.
Parameter Sensitivity and Efficiency
Varying the CMM block depth, QQ-former layers, and GAT layers reveals that shallower but expressively configured modules (1-2 layers) offer optimal trade-off between performance and computational cost. The CMM block provides marked reduction in floating point operation counts (FLOPs) versus transformer baselines, without sacrificing accuracy.
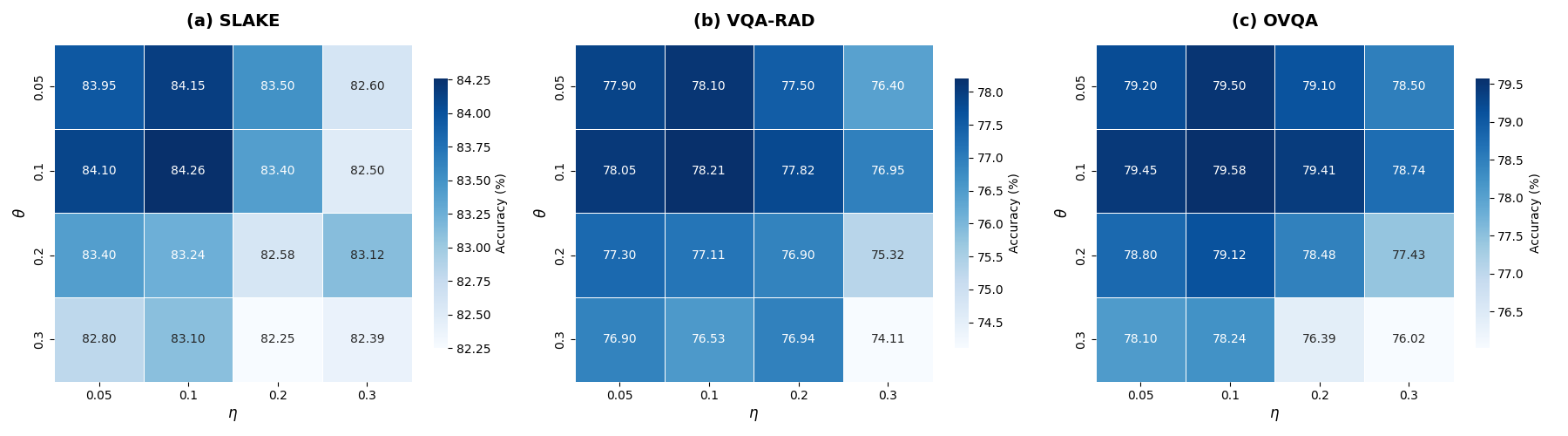
Figure 6: Heatmaps show overall accuracy as a function of feature interaction weights (η, θ); best settings balance visual-textual and knowledge features.
Generative Metrics
NLG evaluation (BLEU, METEOR, CIDEr) on open-ended tasks indicates KG-CMI’s generative auxiliary head produces more fluent and precise clinical answers than prior multimodal baselines.
Interpretability
Grad-CAM visualizations confirm that KG-CMI attentively localizes relevant anatomical and pathological regions corresponding to queries, outperforming prior methods on both focal precision and reasoning tasks.
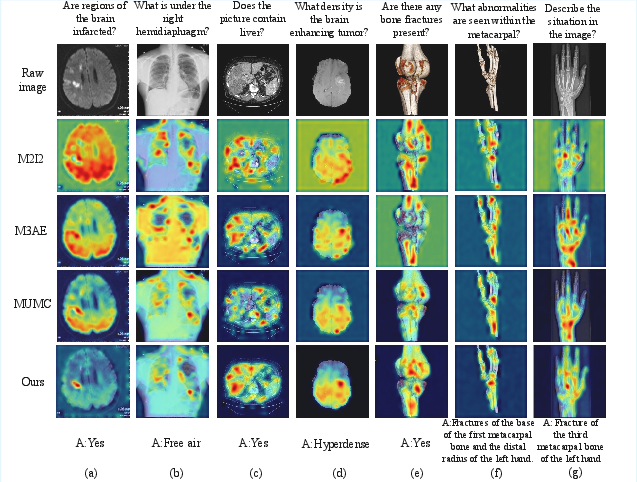
Figure 7: Visual saliency maps highlight the superior question-image attention alignment of KG-CMI compared to competing approaches.
Failure Analysis
Fine-grained failure modes—such as location confusion and negative evidence misjudgment—are identified, with KG-CMI demonstrating more calibrated intermediate reasoning even when ultimate predictions are incorrect.
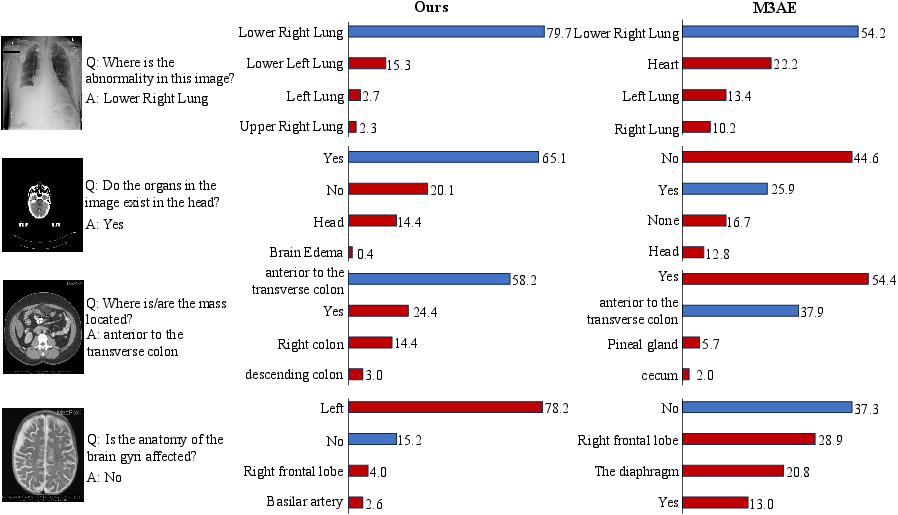
Figure 8: Comparative prediction probability and error analysis for challenging clinical samples exposes diagnostic strengths and residual limitations.
Theoretical and Practical Implications
KG-CMI advances the theoretical modeling for Med-VQA by unifying vision, language, and structured knowledge through efficient, scalable cross-modal mechanisms. The adoption of GAT-based knowledge priors and Mamba-based interaction not only improves accuracy and generalization but also yields more interpretable decisions. Practically, the framework’s linear complexity and modularity make it suitable for hospital deployment, supporting real-world integration for telemedicine and clinical decision support.
All components contribute to robustness across heterogeneous datasets, signifying strong transferability for future adoption in diverse medical specialties and data regimes.
Conclusion
KG-CMI offers a systematic architectural advance for medical visual question answering by integrating knowledge-grounded reasoning, cross-modal fusion efficiency, and flexible generative capacities. Its technical contributions—fine-grained contrastive alignment, structured knowledge incorporation, cross-Mamba multimodal interaction, and multi-task answer space modeling—culminate in state-of-the-art results and enhanced clinical interpretability. Future progress can extend KG-CMI for even more detailed temporal clinical data, multi-image reasoning, and richer knowledge integration.

