RISE: Self-Improving Robot Policy with Compositional World Model
Abstract: Despite the sustained scaling on model capacity and data acquisition, Vision-Language-Action (VLA) models remain brittle in contact-rich and dynamic manipulation tasks, where minor execution deviations can compound into failures. While reinforcement learning (RL) offers a principled path to robustness, on-policy RL in the physical world is constrained by safety risk, hardware cost, and environment reset. To bridge this gap, we present RISE, a scalable framework of robotic reinforcement learning via imagination. At its core is a Compositional World Model that (i) predicts multi-view future via a controllable dynamics model, and (ii) evaluates imagined outcomes with a progress value model, producing informative advantages for the policy improvement. Such compositional design allows state and value to be tailored by best-suited yet distinct architectures and objectives. These components are integrated into a closed-loop self-improving pipeline that continuously generates imaginary rollouts, estimates advantages, and updates the policy in imaginary space without costly physical interaction. Across three challenging real-world tasks, RISE yields significant improvement over prior art, with more than +35% absolute performance increase in dynamic brick sorting, +45% for backpack packing, and +35% for box closing, respectively.

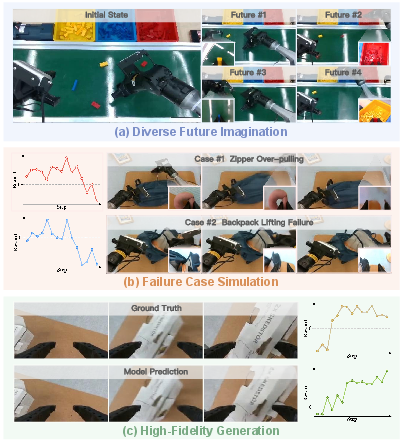


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces RISE, a way for robots to teach themselves new skills safely and quickly by “imagining” what will happen before they move. Instead of practicing risky actions over and over in the real world, the robot learns inside a smart simulator in its head (a learned “world model”). This helps the robot get better at tough jobs like grabbing moving objects, packing a backpack, or closing a box—tasks that need precise timing and careful control.
Key Objectives
The researchers set out to:
- Make robots more reliable at hands-on, tricky tasks where small mistakes can snowball into failure.
- Avoid the cost, danger, and slowness of learning only in the real world.
- Build a learning system where the robot can plan, practice, and improve by imagining different actions and judging which ones are better.
How RISE Works (Methods in Simple Terms)
Think of RISE as giving a robot two superpowers inside its “mind” and a simple training routine that uses them.
The Two-Part “World in the Head”
- Dynamics model: “What happens if I do this?”
- This part predicts the next few moments of camera views if the robot took a certain sequence of actions.
- It’s like a fast, realistic mini-video generator that can quickly “play out” different choices.
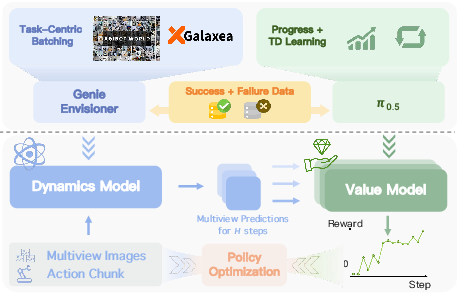
- The team trains it to follow actions closely (so the imagined future matches what the robot actually does), using a strategy called “task-centric batching” that focuses on action variety within the same task for better control.
- Value model: “How good is that future?”
- This part looks at the predicted future images and scores how much closer the robot is to finishing the task.
- It learns two things:
- Progress estimate: a smooth sense of “how far along” the robot is.
- Temporal-Difference (TD) learning: a sharper sense that can spot subtle failures (e.g., a zipper not actually catching).
- Together, these give steady yet sensitive judgment of imagined outcomes.
What is “Advantage” (in plain language)?
- Advantage measures how much better a chosen action is compared to the robot’s usual behavior in the same situation.
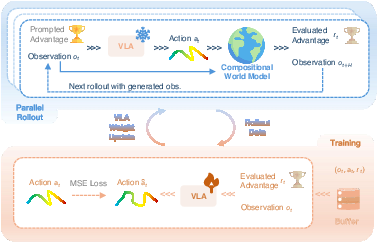
- In practice, RISE imagines the next few steps for a proposed action, lets the value model score those futures, and compares that score to the current moment. If the future looks better, the advantage is positive; if worse, it’s negative. This becomes the teaching signal.
The Training Steps
- Warm-up on real examples:
- The robot first learns from a set of recorded experiences (good demos, some failures, and human fixes), so it behaves sensibly and safely.
- During this stage, the policy (the robot’s action generator) is taught to listen to an “advantage condition” (a hint like “aim for better-than-usual actions”).
- Self-improving loop (learning by imagination):
- Start from a real starting state (e.g., a frame from a real task).
- Ask the policy for a promising action plan.
- Use the dynamics model to imagine what happens next.
- Use the value model to score that imagined future and compute the advantage.
- Teach the policy to produce actions that lead to higher advantage.
- Repeat, mixing in some real data to prevent forgetting.
- Important: The world model (imagination) is only used during training. When the robot acts for real, it just uses the improved policy—no extra slowdowns.
Main Findings
The team tested RISE on three challenging real-world tasks:
- Dynamic brick sorting: pick and sort colored bricks moving on a conveyor belt.
- Backpack packing: open, insert clothes, lift, and zip—handling soft, deformable objects.
- Box closing: fold a flap and tuck a tab with precise two-handed coordination.
Results:
- RISE beat strong existing methods by a large margin.
- Success rate improvements were roughly +35 to +45 percentage points compared to prior approaches.
- Final success rates reached about 85%–95% across tasks.
- Unlike traditional real-world reinforcement learning, RISE didn’t need lots of slow, risky, physical trial-and-error because most learning happened in imagination.
Why this matters:
- The robot becomes more robust to small mistakes.
- It can practice many “what if” scenarios quickly and safely.
- It learns not just to copy demonstrations but to recover when things go off track.
Implications and Impact
- Safer, faster learning: Robots can improve without constant human oversight or risky testing in the real world.
- Better at hard, physical tasks: The combination of “imagine the future” and “score how good it is” helps with contact-rich, delicate moves where tiny errors matter.
- Scalable training: The main cost shifts from physical wear-and-tear to computation. As computers get faster and models get better, this approach becomes even more powerful.
- Real-world readiness: Because RISE mixes imagination with some real data and uses a value model that’s sensitive to failures, it’s more likely to transfer well to actual robots.
Limits and Future Directions (in brief)
- Imagination isn’t perfect: The world model can still make mistakes in rare situations, so improving realism and physics awareness is important.
- Balance needed: You still need some real data to anchor the learning. Finding the best mix of real vs. imagined experience is an open question.
- Compute cost: Training the world model can be heavy. Making it cheaper and faster would help more teams use it.
In short, RISE shows a practical path for robots to self-improve by thinking ahead—imagining, judging, and refining—so they can handle tricky tasks more reliably in the real world.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper on the RISE framework, while comprehensive, leaves several knowledge gaps and limitations that future research might address. Here's a consolidated list of these aspects for clarity:
Knowledge Gaps
- Imagination and Realism Gap: The paper indicates a gap between the imagined rollouts and real-world physical interactions, particularly in rare scenarios. Future work could focus on reducing this gap through enhanced model realism and incorporating explicit geometric constraints.
- Simulated vs. Real Data Efficiency: While a balance in simulated and real data usage is discussed, the optimal ratio remains unclear. Investigating specific environments or scenarios might yield general principles for computational resource allocation.
- Exploration in Robotics: Although leveraging imagined environments reduces physical exploration burdens, the exploration strategies within these environments remain underexplored. How to optimally explore virtual spaces for real-world gains is an open question.
Limitations
- Computational Cost of World Models: The approach significantly reduces physical interaction costs but increases computational demands due to the complexity of the world models. Exploring more computationally efficient models or scalable computing solutions could be beneficial.
- Generalization Across Tasks: The framework's performance consistency across a diverse range of tasks is yet to be fully established. Research into adaptive frameworks that generalize better across different tasks might improve robustness.
- Progress and TD Learning Balance: The paper uses a combination of progress and temporal-difference (TD) learning, but the exact contribution of each to final performance remains unclear. Further research could dissect the proportional influence of these components on policy development.
Open Questions
- Long-term Stability: The long-term stability and performance of policies trained extensively in simulated environments need further validation. Research focused on long-term deployment could offer insights into maintenance and adaptation strategies.
- Enhanced Dynamics Models: The creation of dynamics models that are both efficient and accurate in real-time scenario prediction opens several avenues for exploration, potentially involving novel architectures or learning techniques.
- Value Estimation Accuracy: The accuracy of value estimation in providing effective learning signals is critical. Continued innovation in neural network architectures for value models might enhance this aspect comprehensively.
By addressing these gaps and limitations, future research can build upon the RISE framework to further enhance robotic learning capabilities and efficiencies.
Glossary
- Advantage: In reinforcement learning, a measure of how much better an action performs compared to the average or baseline at a given state. "then evaluates imagined states to derive advantage for policy improvement."
- Advantage conditioning: Training a policy by conditioning its action generation on discretized advantage values to bias toward higher-return behaviors. "generate proper action under an advantage-conditioning scheme."
- Action chunk: A sequence of consecutive actions treated as a single unit for planning or evaluation over a fixed horizon. "where is commonly applied as a sequence of actions with chunk length , i.e., action chunk,"
- Bayes' rule: A probabilistic principle used to express conditional probabilities; here used to derive an improvement likelihood as a density ratio. "Applying Bayes' rule allows us to express the improvement likelihood as a density ratio:"
- Compositional World Model: A world model design that separates dynamics prediction from value estimation so each can use tailored architectures and objectives. "At its core is a Compositional World Model that (i) predicts multi-view future via a controllable dynamics model, and (ii) evaluates imagined outcomes with a progress value model, producing informative advantages for the policy improvement."
- DAgger: A dataset aggregation method that collects on-policy expert corrections to mitigate compounding errors. "+DAgger~\cite{ross2011dagger,kelly2019hgdagger}"
- Discount factor (Temporal discount factor): A parameter that determines how future rewards are weighted relative to immediate rewards in value estimation. "where is the temporal discount factor,"
- Distribution shift: A mismatch between the data used to train a model and the data encountered during deployment, leading to degraded performance. "previous methods of real-world RL to offline data with heavy distribution shift to current policy"
- Dynamics model: A model that predicts future observations conditioned on current state and actions, used to emulate environment transitions. "The dynamics model predicts future observations "
- Exponential Moving Average (EMA): A parameter update technique that smooths model changes by averaging weights over time. "The rollout policy parameters are updated via an Exponential Moving Average (EMA)"
- Flow matching: A generative training criterion for mapping noise to data distributions, used here to optimize the VLA policy. "which is optimized under generic flow-matching criteria~\cite{black2024pi0,intelligence2025pi05}."
- Fréchet Video Distance (FVD): A metric that evaluates video generation quality by comparing distributions of deep video representations. "We evaluate generation quality using PSNR, SSIM~\cite{wang2004image}, LPIPS~\cite{zhang2018unreasonable}, and FVD~\cite{unterthiner2019fvd}"
- Genie Envisioner: A video generative model backbone adapted for fast, action-conditioned dynamics prediction. "we initialize our dynamics model from pre-trained Genie Envisioner~\cite{liao2025genie}, i.e., GE-base variant,"
- Horizon: The number of future steps over which actions or predictions are planned or evaluated. "the policy generates an action sequence of horizon "
- Imitation Learning (IL): Learning to act by mimicking expert demonstrations rather than optimizing a reward signal. "of Imitation Learning (IL), a core mechanism enabling VLAs to generate executable actions."
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual image similarity metric based on deep features, used to evaluate visual fidelity. "We evaluate generation quality using PSNR, SSIM~\cite{wang2004image}, LPIPS~\cite{zhang2018unreasonable}, and FVD~\cite{unterthiner2019fvd}"
- Markov Decision Process (MDP): A formal framework for sequential decision-making with state, action, transition dynamics, and rewards. "We formulate the problem as a standard RL setting with decision-making process as a Markov Decision Process (MDP)"
- Multi-view: Using multiple camera perspectives of the scene simultaneously in observation and modeling. "let be the multi-view observation at time "
- Off-policy: Learning from data collected by a different policy than the one currently being optimized. "previous methods of real-world RL to offline data with heavy distribution shift to current policy"
- On-policy: Learning from data collected by the current policy being optimized. "on-policy RL in the physical world is constrained by safety risk, hardware cost, and environment reset."
- Optical flow end-point error (EPE): A metric evaluating motion prediction accuracy by measuring the distance between predicted and true flow vectors. "alongside optical flow end-point error (EPE)~\cite{zhang2025reinforcing} for action controllability."
- Peak Signal-to-Noise Ratio (PSNR): A signal fidelity metric used to assess image or video reconstruction quality. "We evaluate generation quality using PSNR, SSIM~\cite{wang2004image}, LPIPS~\cite{zhang2018unreasonable}, and FVD~\cite{unterthiner2019fvd}"
- Policy Warm-up: An initial fine-tuning stage on offline data to anchor behavior before online self-improvement. "we establish a Policy Warm-up stage on real-world experience to anchor the policy to practical behavioral distribution"
- PPO (Proximal Policy Optimization): A popular RL algorithm that updates policies with constrained steps to stabilize training. "+PPO~\cite{PPO}"
- Progress estimate: A value modeling objective that regresses how far along an episode is, providing dense signals for learning. "adapted with both progress estimate~\cite{ma2024gvl,zhai2025vlac,ghasemipour2025self} and Temporal-Difference learning"
- Reinforcement Learning (RL): Learning to make decisions by maximizing cumulative reward through interaction with an environment. "Reinforcement Learning (RL), which improves agents through their own success and failure, offers a potential remedy."
- RECAP: An advantage-conditioned offline RL approach used to warm-start policies on task data. "Both data composition and training objective mainly follow RECAP~\cite{amin2025pi06}."
- Rollout: Executing a policy to generate trajectories (real or imagined) for training or evaluation. "continuously generates imaginary rollouts, estimates advantages, and updates the policy in imaginary space"
- SSIM (Structural Similarity Index Measure): An image quality metric that compares structural information between images. "We evaluate generation quality using PSNR, SSIM~\cite{wang2004image}, LPIPS~\cite{zhang2018unreasonable}, and FVD~\cite{unterthiner2019fvd}"
- Task-Centric Batching: A data sampling strategy that emphasizes action diversity within a task to improve controllability and convergence. "We mitigate this issue with a Task-Centric Batching strategy"
- Temporal-Difference learning (TD): A value-learning method that bootstraps from future estimates to learn from successive states and rewards. "we augment the progress loss with Temporal-Difference (TD) learning~\cite{Sutton_temporal_diff}"
- Value model: A function approximator that assigns scalar values to observations to evaluate progress or expected return. "The value model is initialized from a pre-trained VLA backbone"
- Vision–Language–Action (VLA): Models that map visual inputs and language instructions to robot actions, often pre-trained on large datasets. "Vision–Language–Action (VLA) models remain brittle in contact-rich and dynamic manipulation tasks"
- World model: A learned simulator that predicts future outcomes conditioned on actions, enabling planning and imagined training. "motivates the development of world models, which first learn from passive experience and then simulate future outcomes conditioned on different actions"
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can leverage the paper’s methods now, assuming access to task data, multi-view cameras, and moderate GPU resources for fine-tuning.
- Dynamic conveyor sorting retrofit
- Description: Train and deploy RISE-improved policies to pick/sort moving items on conveyors (analogous to “Dynamic Brick Sorting”) with fewer on-robot trials and less downtime.
- Sectors: Manufacturing, logistics/parcel hubs, recycling facilities.
- Tools/Products/Workflows: Multi-view camera rig over conveyor; action-logged robot data; RISE “Policy Warm-up” on historical logs; compositional world model fine-tuning with task-centric batching; advantage-conditioned VLA policy update; gated rollout validation before OTA deployment.
- Assumptions/Dependencies: Sufficient task-specific logs; calibration between camera frames and robot actions; availability of 1–8 GPUs for fine-tuning; safety interlocks for deployment.
- Semi-automated packing of deformable items
- Description: Use RISE to improve manipulation of soft goods (e.g., apparel into polybags/backpacks), reducing human intervention for bag opening, insertion, and closure.
- Sectors: E-commerce fulfillment, 3PLs, apparel manufacturing.
- Tools/Products/Workflows: Deformable-object datasets from production lines; value model to flag failure-prone steps; imagination rollouts to refine insertion and closure primitives; mixed offline/online training ratio monitoring.
- Assumptions/Dependencies: Multi-view coverage to handle occlusions; adequate deformable-object variability in logs; real-to-imagined fidelity for contact-rich phases.
- Automated box closing and sealing cells
- Description: Improve bi-manual flap folding/tucking policies without repeated physical trials (mirrors “Box Closing”), then integrate with taping/sealing modules.
- Sectors: Packaging, CPG, food and beverage, consumer electronics.
- Tools/Products/Workflows: Action-conditioned dynamics fine-tuned per SKU/box geometry; value model with TD learning to distinguish subtle flap/tuck failures; workstation-level “imagination QA” before release.
- Assumptions/Dependencies: Robust kinematic control and force limits; SKU-specific fine-tuning; multi-view views of the fold line and tab.
- Low-disruption policy improvement for existing robot fleets
- Description: Shift the bulk of on-policy improvement into imagination to reduce robot downtime and manual resets; deploy only validated updates.
- Sectors: Any production or lab with deployed arm/mobile manipulators.
- Tools/Products/Workflows: Fleet logging pipeline; RISE server that consumes logs, fine-tunes world/value models, produces advantage-labeled data; scheduled OTA updates with rollback; drift monitors using imagined edge cases.
- Assumptions/Dependencies: High-quality time-synced logs (images+actions); basic MLOps (versioning, A/B testing); correlation between imagined advantages and real gains.
- Pre-deployment safety and performance gating
- Description: Use imagined rollouts to estimate failure likelihood and performance distributions before deploying revised policies.
- Sectors: Robotics QA/compliance; internal safety review boards.
- Tools/Products/Workflows: Batch imagination for hazard scenarios (e.g., near-singularity postures, tight clearances); advantage-bin thresholds to gate release; reports with FVD/EPE and task-specific KPIs.
- Assumptions/Dependencies: World model fidelity on rare scenarios; documented risk acceptance criteria; human-in-the-loop sign-off.
- Data-efficient long-horizon annotation
- Description: Leverage the value model (progress + TD) to auto-generate dense progress/failure labels on long-horizon videos, reducing manual labeling.
- Sectors: Data operations for robotics, AI tooling vendors.
- Tools/Products/Workflows: Batch labeling service that ingests task videos and outputs progress curves, terminal success/failure labels, and advantage estimates for CF-GRL/RECAP-style training.
- Assumptions/Dependencies: Value model reliability on target task distribution; periodic human audit; calibration to avoid over-smoothed progress.
- Simulation augmentation without heavy CAD/digital-twin setup
- Description: Use generative dynamics to augment limited simulator coverage (e.g., rare object poses), reducing reliance on expensive physics-based domain randomization for perception+policy training.
- Sectors: Robotics simulation, software tooling, education labs.
- Tools/Products/Workflows: “Imagination augmentation” interface that takes simulator rollouts and generates visual/action-conditioned variants; plug-ins for ROS/Isaac data pipelines.
- Assumptions/Dependencies: Acceptable sim-to-imagination domain gap; curated filters against unphysical samples.
- Research reproducibility and benchmarking
- Description: Adopt the compositional world model + advantage-conditioned RL recipe as a baseline for robust manipulation research and ablations (e.g., task-centric batching, progress vs TD).
- Sectors: Academia, corporate research labs.
- Tools/Products/Workflows: Open training/eval scripts mirroring paper’s ablations; multi-view datasets; standard metrics (PSNR/SSIM/LPIPS/FVD/EPE + task scores).
- Assumptions/Dependencies: Availability of pre-trained VLA backbones; compute budget similar to reported setups or scaled-down proxies.
Long-Term Applications
These opportunities likely require further advances in controllability, uncertainty-aware modeling, scaling infrastructure, or regulatory acceptance.
- General-purpose home assistants that self-improve safely
- Description: Household robots that learn tidying, laundry folding, and organizing by training in imagination from nightly logs; deploy only validated improvements.
- Sectors: Consumer robotics, smart home.
- Tools/Products/Workflows: On-device logging with privacy controls; “imagination sandbox” running in the cloud/edge; skill library with advantage-conditioned updates; failure simulators for homes.
- Assumptions/Dependencies: Robust world models for diverse homes; privacy-by-design; low-cost compute; reliable multi-view sensing or learned egocentric substitutes.
- Surgical and interventional robotics skills refinement
- Description: Use high-fidelity imagination to improve suturing/knot-tying/tissue manipulation policies with minimal patient risk; pre-validate skill improvements.
- Sectors: Healthcare, surgical robotics.
- Tools/Products/Workflows: Domain-specific value heads (e.g., tension, tissue trauma proxies); synthetic patient variability; strict gating and audit trails.
- Assumptions/Dependencies: Regulatory approval; validated biomechanical fidelity; expert oversight; stringent safety cases.
- Fleet-level “Imagination Servers” for continuous learning
- Description: Cross-site data aggregation to train shared world/value models and dispatch tailored policy updates to heterogeneous robot fleets (arms, mobile manipulators).
- Sectors: Warehousing, retail, manufacturing networks.
- Tools/Products/Workflows: Multi-tenant learning platform; per-site calibration layers; uncertainty-aware selection of logs for fine-tuning; staged rollout with online monitoring.
- Assumptions/Dependencies: Data-sharing agreements; robust domain adaptation; bandwidth and compute orchestration; governance for model drift.
- Rapid SKU/task onboarding in reconfigurable factories
- Description: Introduce new product geometries or packaging steps by first training policies in imagination, reducing line commissioning time.
- Sectors: High-mix manufacturing, contract packaging.
- Tools/Products/Workflows: SKU-conditioned dynamics; synthetic-edge-case generation; “imagination-first” changeover SOPs; operator-in-the-loop correction capture.
- Assumptions/Dependencies: Availability of CAD/imagery for new SKUs; fast fine-tuning; tooling to update fixtures and camera layouts.
- Regulatory frameworks for model-based evidence
- Description: Standardize acceptance of world-model-based safety/performance evidence in robotics certification and change management.
- Sectors: Policy/regulation, standards bodies (e.g., ISO/ANSI/RIA).
- Tools/Products/Workflows: Auditable imagination datasets; uncertainty quantification; traceable value/advantage metrics; conformance tests.
- Assumptions/Dependencies: Consensus on fidelity thresholds; independent validation suites; liability frameworks.
- Uncertainty-aware imagination and safety envelopes
- Description: Integrate epistemic/aleatoric uncertainty to avoid overconfident policy updates; adaptively gate exploration in imagination.
- Sectors: Robotics software vendors, safety tooling.
- Tools/Products/Workflows: Ensembles/latent spread for world models; conservative value backups; risk-sensitive advantage weighting; safe set filters.
- Assumptions/Dependencies: Scalable uncertainty estimation; calibration under distribution shift.
- Imagination-as-a-Service platforms
- Description: Cloud services offering compositional world modeling (dynamics+value) with APIs to submit logs and receive policy updates, labels, and rollout evaluations.
- Sectors: Cloud/ML platforms, robotics middleware providers.
- Tools/Products/Workflows: ROS2/MCAP connectors; job schedulers for GPU clusters; dataset versioning; billing tied to imagination tokens/horizons.
- Assumptions/Dependencies: Stable APIs; data governance; cost controls for compute-intensive training.
- Cross-task value heads and reusable skill libraries
- Description: Libraries of progress/TD value heads transferable across related tasks (e.g., “pick-and-place → pack → palletize”), accelerating new-task learning.
- Sectors: Robotics integrators, enterprise automation suites.
- Tools/Products/Workflows: Task ontologies and instruction schemas; multi-task fine-tuning; advantage normalization across tasks; retrieval-based skill selection.
- Assumptions/Dependencies: Sufficient cross-task data; language grounding consistency; catastrophic interference mitigation.
- Mobile manipulation in dynamic public spaces
- Description: Stocking, facing, and tidying in retail or hospitality, trained mostly in imagination to cover rare human/traffic interactions.
- Sectors: Retail, hospitality, facilities management.
- Tools/Products/Workflows: Multi-view or egocentric SLAM-aligned imagination; human-in-the-loop preference/value shaping; policy guards for proxemics.
- Assumptions/Dependencies: Social compliance; robust perception of crowds; strong generalization across layouts.
- Energy- and compute-aware learning schedules
- Description: Optimize when and how much to imagine vs. collect real data, minimizing energy cost while meeting performance targets.
- Sectors: Sustainability/Green AI initiatives, MLOps.
- Tools/Products/Workflows: Budgeted imagination planners; active data selection; curriculum schedules that adapt offline/online ratios; carbon accounting dashboards.
- Assumptions/Dependencies: Pareto models of performance vs. compute; accurate telemetry of energy use; enterprise sustainability goals.
Notes on Key Dependencies and Assumptions (common across applications)
- World model fidelity and controllability: Success depends on the action-conditioned, multi-view dynamics model remaining stable under target domain shifts; task-centric batching and targeted fine-tuning are critical.
- Data quality: Time-synchronized multi-view observations and accurate action logs are required; camera calibration and robot kinematic accuracy matter.
- Compute constraints: While inference-time overhead is zero, training/fine-tuning needs GPUs (the paper reports 8–16× H100 for days); production deployments may require scaled or distilled variants.
- Safety and governance: Advantage gains in imagination must correlate with real-world safety/performance; include human review, staged rollouts, and rollback plans.
- IP/licensing: Use of pre-trained VLAs and datasets must comply with licensing; privacy and data-sharing agreements are essential for fleet-wide learning.
Collections
Sign up for free to add this paper to one or more collections.

