Posterior Behavioral Cloning: Pretraining BC Policies for Efficient RL Finetuning
Abstract: Standard practice across domains from robotics to language is to first pretrain a policy on a large-scale demonstration dataset, and then finetune this policy, typically with reinforcement learning (RL), in order to improve performance on deployment domains. This finetuning step has proved critical in achieving human or super-human performance, yet while much attention has been given to developing more effective finetuning algorithms, little attention has been given to ensuring the pretrained policy is an effective initialization for RL finetuning. In this work we seek to understand how the pretrained policy affects finetuning performance, and how to pretrain policies in order to ensure they are effective initializations for finetuning. We first show theoretically that standard behavioral cloning (BC) -- which trains a policy to directly match the actions played by the demonstrator -- can fail to ensure coverage over the demonstrator's actions, a minimal condition necessary for effective RL finetuning. We then show that if, instead of exactly fitting the observed demonstrations, we train a policy to model the posterior distribution of the demonstrator's behavior given the demonstration dataset, we do obtain a policy that ensures coverage over the demonstrator's actions, enabling more effective finetuning. Furthermore, this policy -- which we refer to as the posterior behavioral cloning (PostBC) policy -- achieves this while ensuring pretrained performance is no worse than that of the BC policy. We then show that PostBC is practically implementable with modern generative models in robotic control domains -- relying only on standard supervised learning -- and leads to significantly improved RL finetuning performance on both realistic robotic control benchmarks and real-world robotic manipulation tasks, as compared to standard behavioral cloning.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
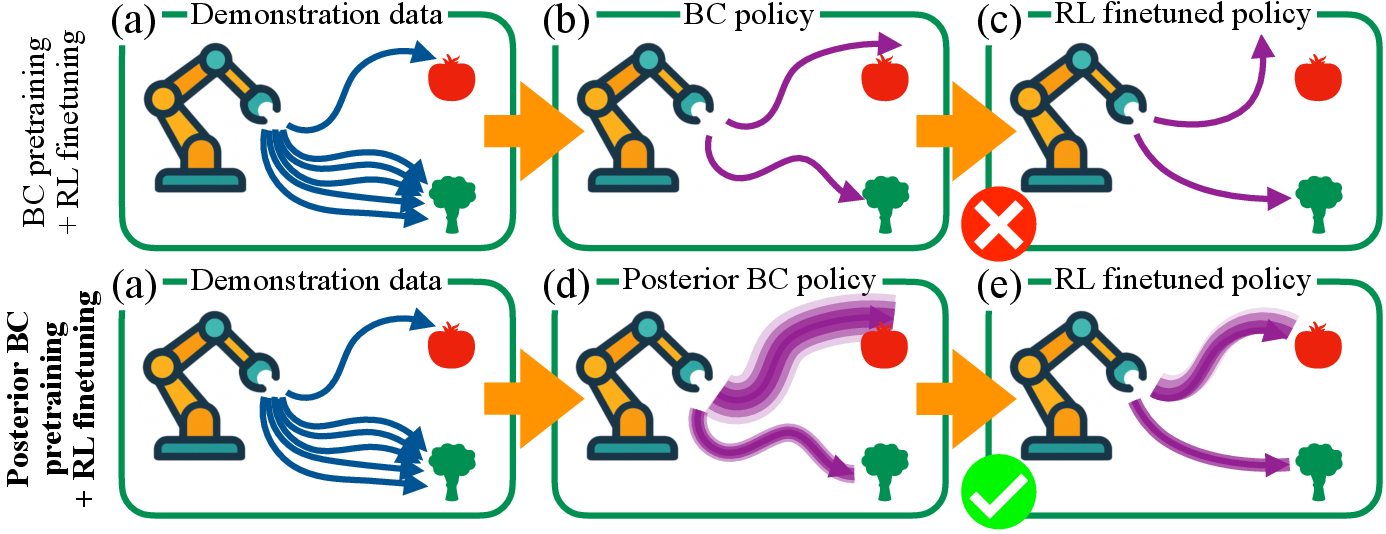
This paper looks at a common way we train smart systems (like robots or AI assistants): first we teach them by copying examples (called behavioral cloning), and then we let them practice and improve using rewards (called reinforcement learning, or RL). The authors ask a simple but important question: can we pretrain differently so that the later RL practice works better and faster?
They propose a new pretraining method called Posterior Behavioral Cloning (PostBC). It makes the pretrained policy both good at copying what it saw and open-minded enough to try reasonable alternatives—so RL has something useful to improve.
What questions did the researchers ask?
- Why do some pretrained policies make RL finetuning slow or ineffective?
- Can we change pretraining so the policy tries all actions the demonstrator might use (they call this “coverage”), which is often necessary for RL to improve?
- Can we get that coverage without making the pretrained policy worse?
- Will this idea work in practice, especially for robots?
How did they approach the problem?
Key ideas explained in everyday terms
- Behavioral Cloning (BC): Imagine you’re learning basketball by watching a coach. BC means you copy exactly what the coach did in the recorded videos. This works best where you’ve seen many examples. But in places with few examples, you might copy too narrowly and never try other good moves the coach sometimes makes.
- RL Finetuning: After copying, you actually play the game and get points (rewards). You change your behavior to get more points next time. This “practice with feedback” can make you much better.
- Coverage: To improve with RL, you need your current policy to sometimes try all the actions the coach might use. If your policy never tries certain actions, you can’t discover they’re good, and RL can’t help.
- Posterior (best guess after seeing data): Instead of assuming the coach always does the exact same thing you observed, you form a smart “best guess” distribution of what the coach could reasonably do based on the examples. Where you saw few examples, you stay uncertain and keep a wider spread of actions; where you saw many examples, you’re confident and stick close to them.
- Entropy (spread/randomness): This is how “wide” or “varied” your action choices are. PostBC increases spread where uncertainty is high, and keeps it tight where you’re sure.
The PostBC training recipe (in simple steps)
To build a PostBC policy, the authors:
- Start with the usual BC policy trained on demonstrations.
- Estimate how uncertain the policy is about the coach’s actions at each situation (state). They do this by training multiple slightly different predictors (an ensemble), often using bootstrapped data subsets, and measuring how much their predictions vary. More variation = more uncertainty.
- During training, they add a bit of noise to the target actions that matches that uncertainty. In states with few or inconsistent examples, they add more noise (wider spread); in well-covered states, they add little or none.
- The result is a generative policy (they use modern models like diffusion models) that represents the posterior distribution: confident where data is strong, exploratory where data is thin.
Importantly, this pretraining uses standard supervised learning—no RL during pretraining is needed.
What did they find?
Here are the main results and why they matter:
- Standard BC can fail to cover the coach’s full action set. In simple terms, it may never try certain coach-like actions—making RL unable to learn them later.
- Adding uniform random noise everywhere isn’t a good fix. If you sprinkle randomness equally, you either:
- hurt performance in well-understood parts (too much noise), or
- don’t get enough coverage where you need it unless you add so much noise that performance drops.
- PostBC gives strong coverage while keeping pretrained performance. The authors prove that mixing BC with the posterior policy leads to a near-optimal balance: the pretrained policy stays as good as standard BC, yet it samples the coach’s possible actions often enough for RL to improve efficiently.
- Near-optimality (theory): They show you can’t, in general, get much better coverage without hurting pretrained performance. PostBC hits that sweet spot.
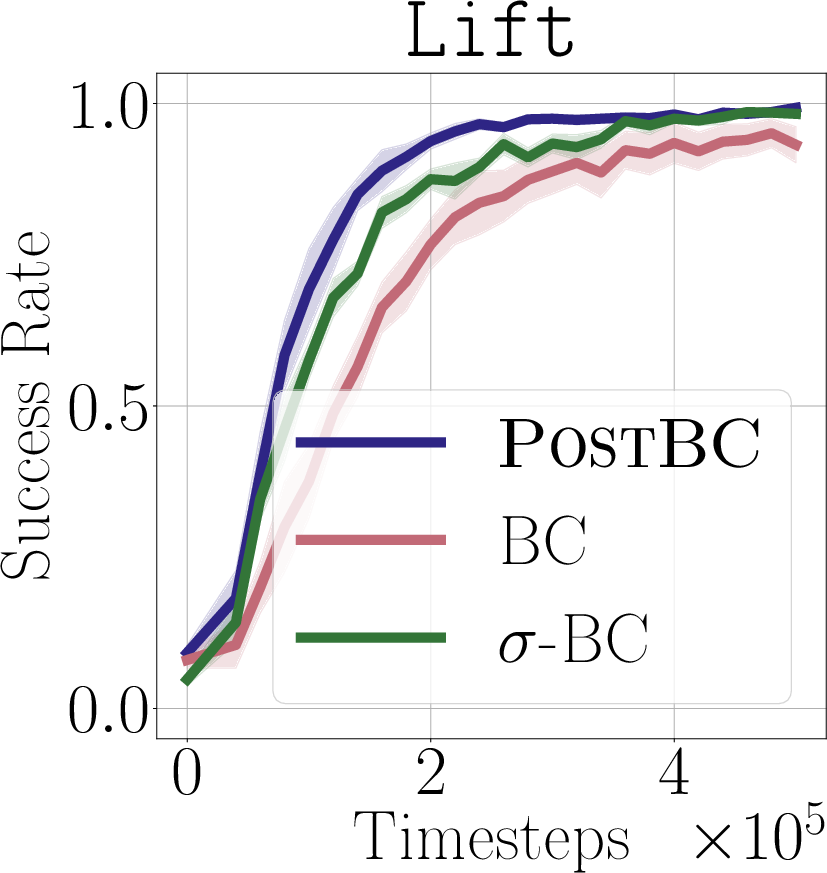
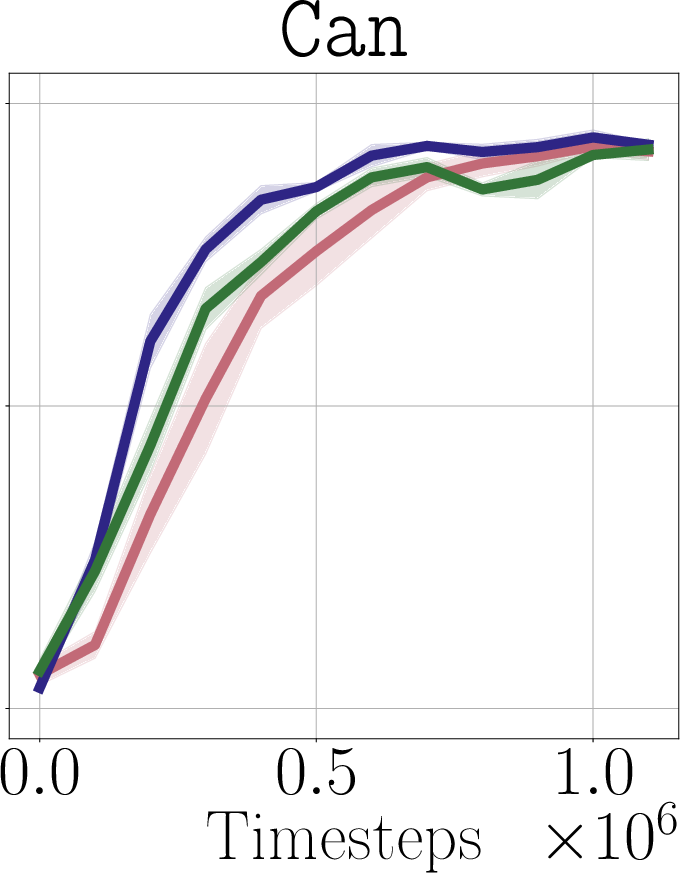
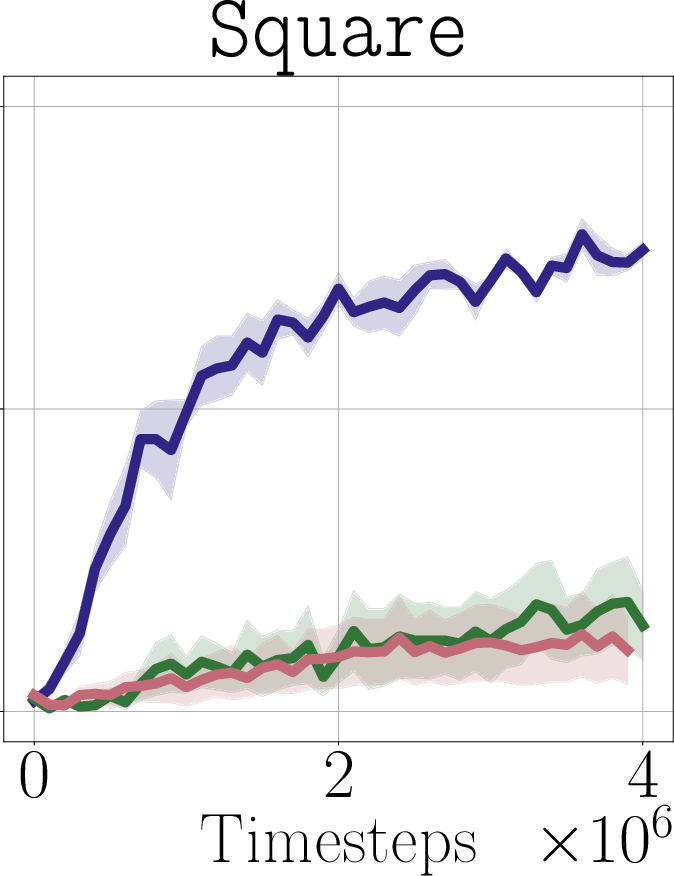
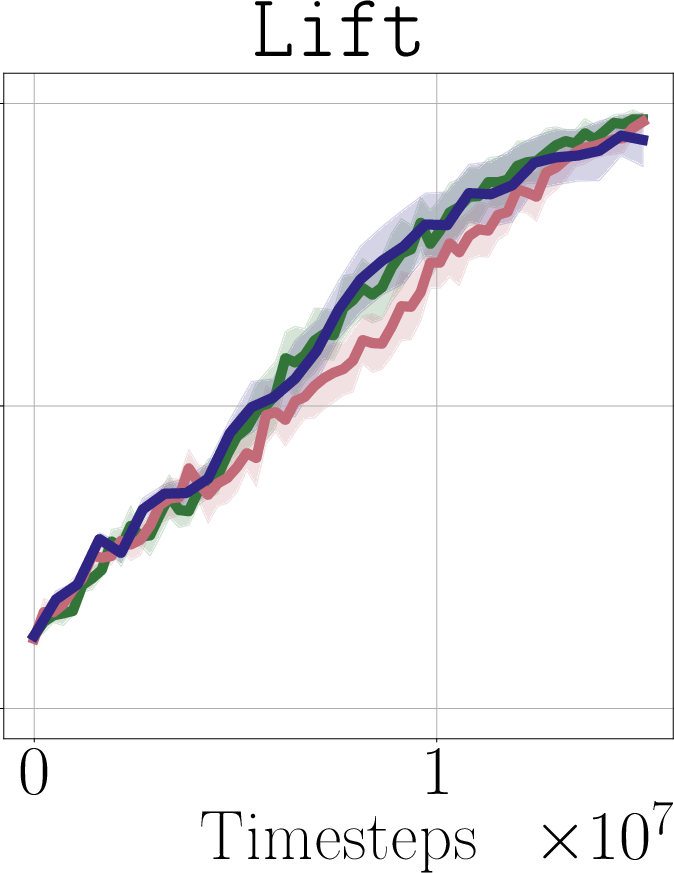
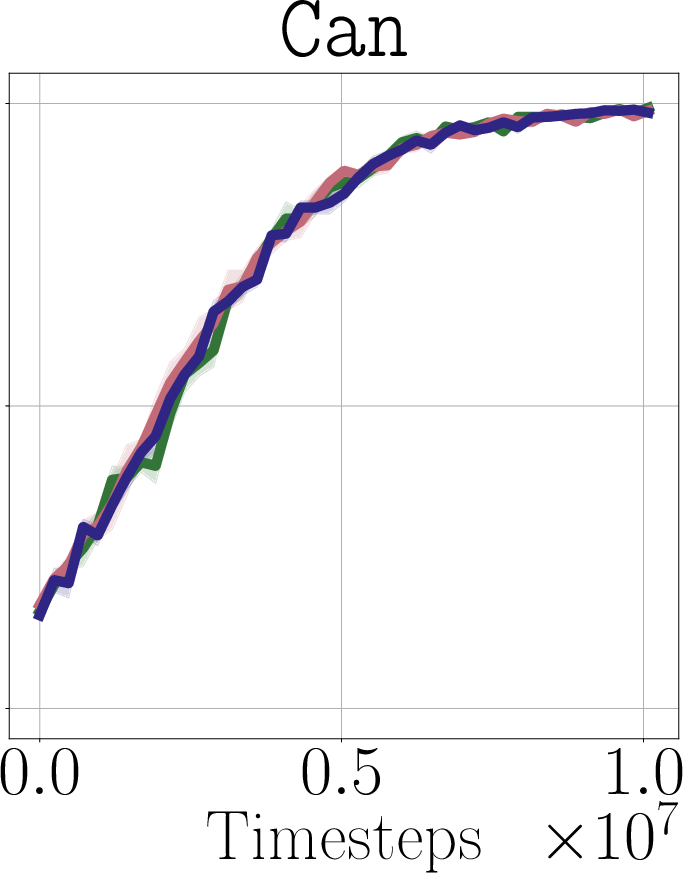
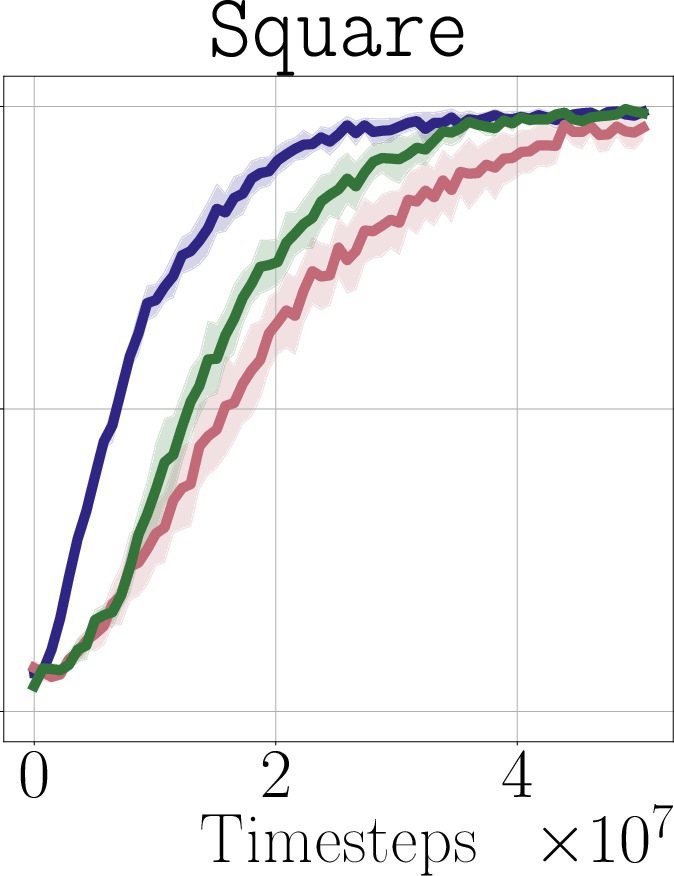
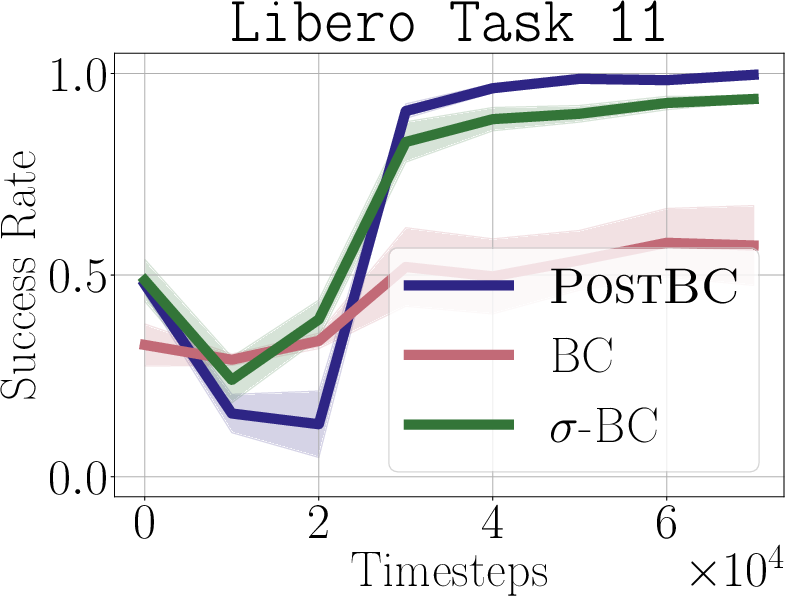
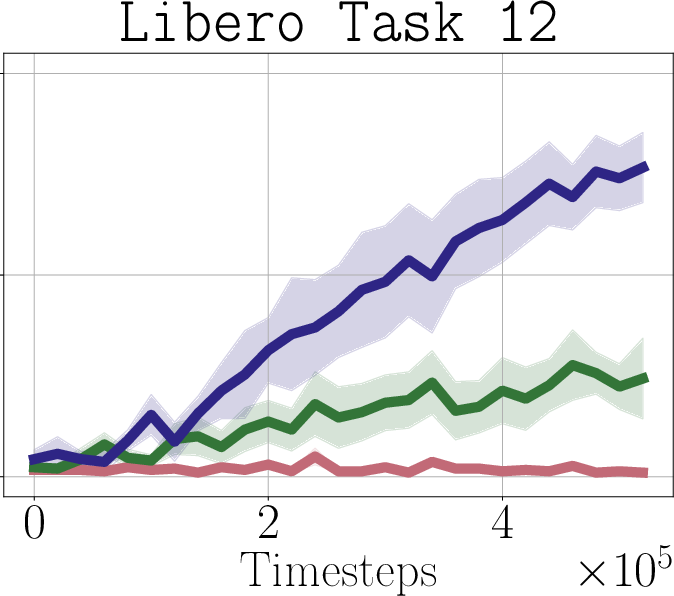
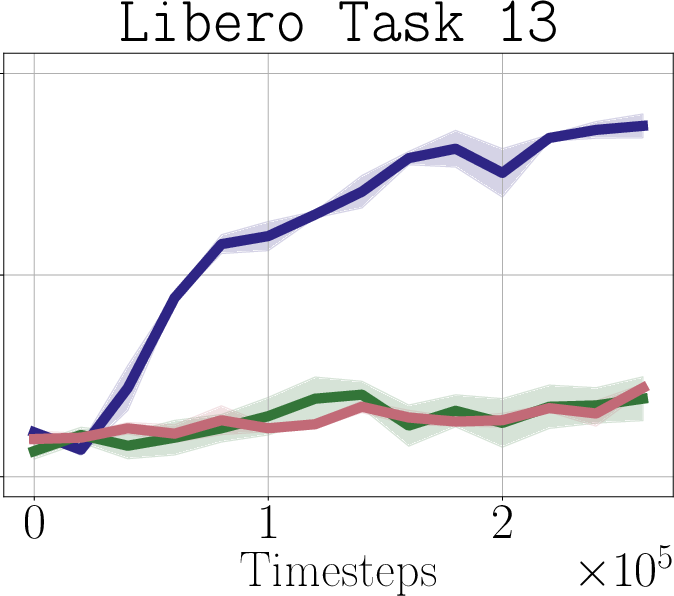
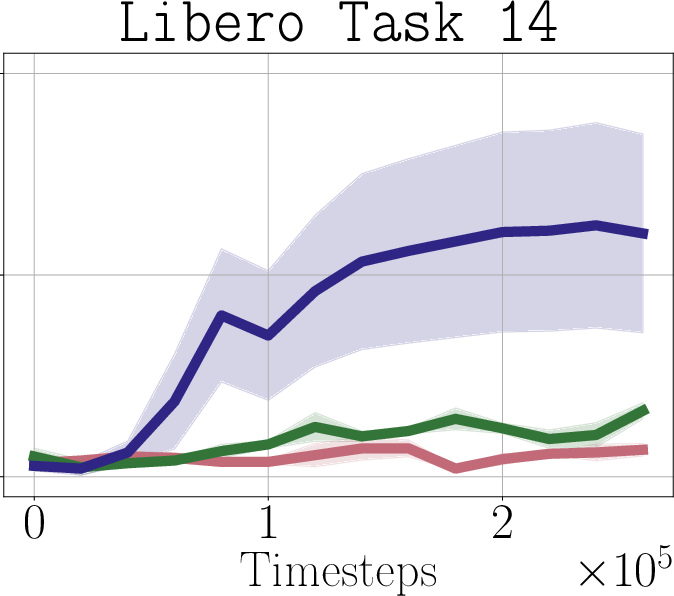
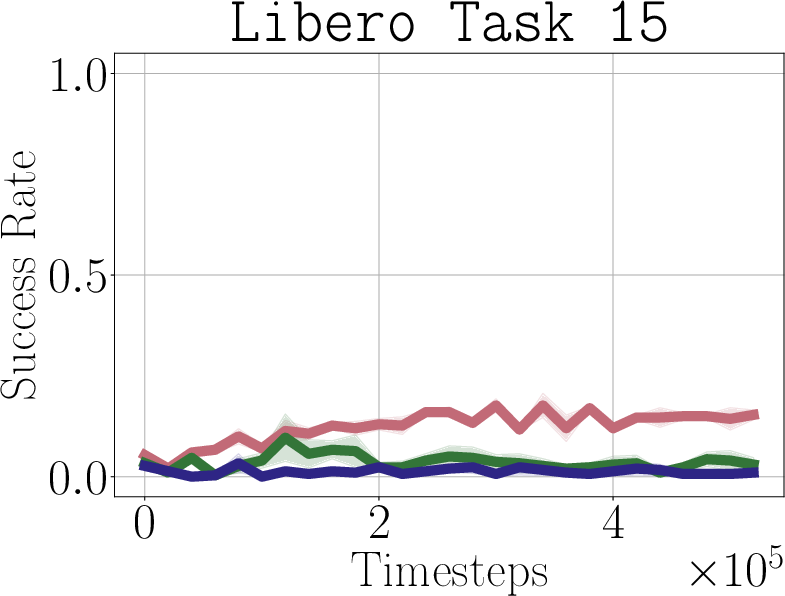
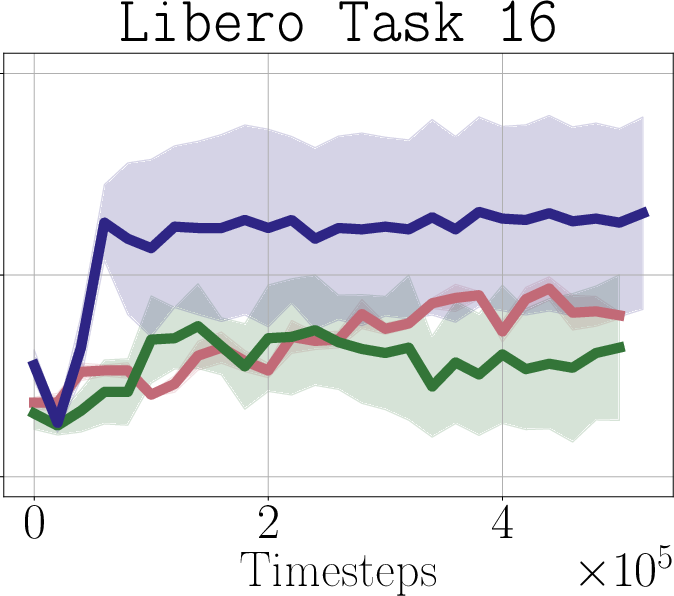
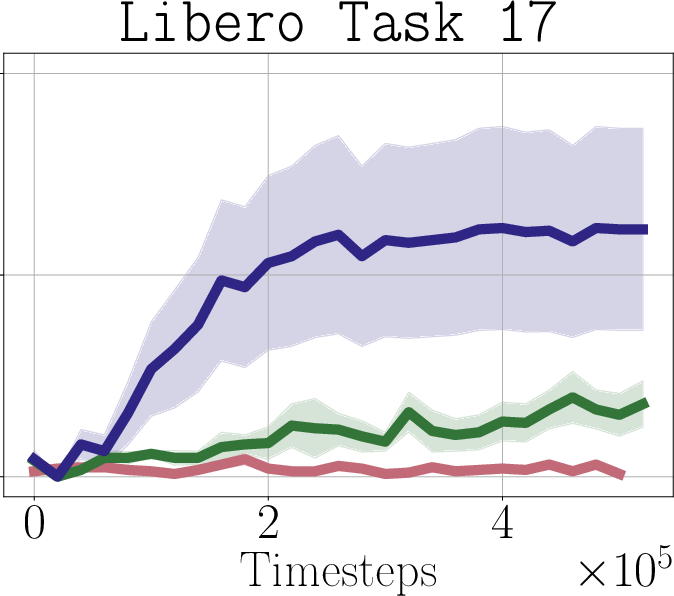
- Real-world impact (experiments): In simulated robot tasks (Robomimic and Libero) and on a real robot arm (WidowX 250), PostBC policies make RL finetuning:
- faster (needs fewer practice trials),
- more effective (higher success rates),
- and without making the initial policy worse.
- Works with multiple finetuning methods: PostBC improves over standard BC across different RL finetuning styles, including policy-gradient approaches, methods that filter the policy’s samples (Best-of-N), and diffusion-policy steering.
Why does this matter?
Robots and AI systems often learn first by imitation and then improve with RL. But, practicing in the real world is expensive and slow (think robot time, safety, wear-and-tear). PostBC makes that practice more efficient by ensuring the policy already tries a sensible variety of actions where it’s uncertain, so RL can discover better strategies quicker. You get:
- Better starting point for RL (no worse than BC),
- Wider, smarter action exploration where it counts,
- Faster and more reliable improvement after deployment,
- Practical training using standard supervised methods.
In short, PostBC helps turn “copying” into “copying plus thoughtful exploration,” setting up AI and robots to learn more effectively from fewer real-world trials.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future researchers could address.
- Formalizing coverage in continuous-action settings: Theoretical guarantees are proved in tabular, discrete-action MDPs; there is no formal extension of demonstrator action coverage (or its analog) to continuous action spaces with function approximation, including absolute continuity and support-overlap conditions.
- Prior assumptions and optimality trade-offs: Results rely on a uniform prior over Markovian policies; it is unclear how non-uniform, structured, or task-informed priors affect the achievable coverage parameter γ while preserving Bc-level suboptimality.
- Conditions for posterior regularization: The paper references a “slightly regularized” posterior demonstrator policy with conditions like HT ≲ eA but does not specify a general, robust regularization scheme or its impact on γ and pretraining performance in practice.
- State distribution and occupancy coverage: Action-coverage is defined conditionally on states seen in the dataset; there is no analysis of coverage under changing state-occupancy measures during finetuning, where the policy visits previously unseen states.
- Sample complexity in continuous control: The factor-of-1/γ sample penalty is discussed for discrete settings; the paper does not quantify the sample-complexity impact of PostBc in continuous domains under function approximation.
- Posterior covariance estimation validity: The ensemble-based covariance approximation (bootstrapping or noise-injection regression) lacks theoretical guarantees in non-Gaussian, high-dimensional, image-conditioned policies; conditions under which it approximates the true posterior uncertainty are not characterized.
- Unknown noise scale in practice: The Gaussian derivation assumes known action noise σ; the paper does not describe how to estimate σ (or an analog) from demonstrations, nor the sensitivity of PostBc to mis-specified noise models.
- Per-state adaptive weighting of posterior noise: α is global in practice; there is no method or analysis for per-state (or per-context) adaptive α based on uncertainty, nor for scheduling α during training or finetuning.
- Safety and constraint handling: Adding entropy in low-data regimes may induce unsafe actions on real robots; there is no mechanism or analysis for constraint-aware or risk-sensitive posterior noise injection during pretraining or online finetuning.
- Robustness to multi-modal demonstrator behavior: The approach perturbs Bc targets with Gaussian noise; it is unclear how this handles strongly multi-modal demonstrator policies where posterior mass is distributed across distinct modes.
- Outliers and heavy-tailed noise: The method assumes regression with squared error; robustness to outliers or heavy-tailed demonstration noise is not analyzed, and alternative robust posterior approximations are not explored.
- Generalization to off-policy RL finetuning: Experiments focus on a few on-policy or policy-refinement methods (Dsrl, Dppo, Best-of-N); the compatibility and impact of PostBc on off-policy algorithms (e.g., Q-learning, actor-critic with replay) is not evaluated.
- Interaction with value-based filtering: Theoretical coverage focuses on demonstrator actions; whether posterior-induced entropy improves or degrades performance of value-filtered sampling (Best-of-N) as N varies is not systematically analyzed.
- Coverage vs. optimality beyond demonstrator: Guarantees target covering the demonstrator’s action set; the paper does not address whether PostBc helps discover actions superior to demonstrator actions, nor conditions where increased entropy slows convergence to better-than-demonstrator policies.
- Sensitivity to ensemble size and architecture: The impact of the ensemble size K, model class F, and bootstrapping scheme on posterior covariance quality and downstream finetuning efficiency remains unquantified.
- Computational overhead and training stability: The added steps (ensembles, covariance estimation, stochastic target perturbation) may incur nontrivial compute and instability; no analysis or reporting of overhead, convergence issues, or training-time trade-offs is provided.
- Domain shift and sparse data regimes: The method assumes enough local data to estimate uncertainty; it is unclear how PostBc behaves under severe domain shift, sparse demonstrations, or highly imbalanced coverage across tasks or states.
- Theoretical link to policy performance in continuous domains: The paper claims pretrained performance “no worse than Bc” for tabular cases; a formal bound for function-approximation policies (e.g., diffusion models) under posterior noise is missing.
- Action bounds and actuator limits: Gaussian perturbations can violate control limits; the paper does not discuss clipping, squashing, or constraint-aware sampling to keep actions feasible in real robotic systems.
- Multi-task posterior modeling: In Libero, demonstrations span multiple tasks; there is no formal treatment of shared posterior structure across tasks (e.g., hierarchical priors or task-conditioned posterior estimation).
- Quantifying exploration-exploitation balance: While entropy is increased in low-data states, there is no metric or analysis to quantify the exploration induced by PostBc or to calibrate it against finetuning efficacy and safety.
- Data quality and suboptimal demonstrators: The approach presumes demonstrator coverage is desirable; the method’s behavior with noisy, inconsistent, or suboptimal demonstrations (e.g., when high entropy favors poor actions) is not examined.
- Alternative posterior sampling methods: Beyond ensembles/bootstrapping and Gaussian noise, other Bayesian approximations (e.g., Laplace, SWA, variational inference) are not investigated for action posterior modeling in large models.
- Coverage definitions for function approximation: The discrete definition π_h(a|s) ≥ γ·π*_h(a|s) lacks a clear analog for continuous densities; guidance on selecting appropriate divergences or distances (e.g., KL, TV, support inclusion) is missing.
- Empirical diagnostics of coverage: There is no experimental metric reported for “coverage” (e.g., probability mass on demonstrator actions, acceptance rates in Best-of-N) to validate the theoretical claims in robotic settings.
- Hyperparameter tuning protocols: The paper does not specify principled procedures for tuning α, ensemble K, noise scales, or training schedules, nor ablation studies to isolate their effects on finetuning performance.
- Real-world robustness and generalization: WidowX experiments are mentioned but details (task variety, number of trials, failure cases, resets, intervention rates) are insufficient to assess robustness; broader real-world evaluation across platforms is needed.
- Impact on long-horizon credit assignment: Posterior-induced exploration is local at action-step level; whether this aids or hinders learning of temporally extended behaviors with sparse rewards is not analyzed.
- Integration with constraint/skill libraries: It is unexplored whether posterior-based pretraining can be combined with known skill primitives, safety shields, or structured priors to improve both coverage and safety in robotics.
Practical Applications
Immediate Applications
Below are concrete ways to use Posterior Behavioral Cloning (PostBC) now, based on the paper’s theory and practical diffusion-policy implementation with ensembles and noise-injection.
- Robotics: faster and safer RL finetuning for manipulation
- Sector: robotics, manufacturing, logistics, lab automation
- Use cases:
- Adapt grasping, pick-and-place, assembly policies to new fixtures or SKUs with fewer real rollouts.
- Speed up sim-to-real transfer by pretraining with PostBC on demos, then RL finetune on hardware.
- Improve Best-of-N action selection pipelines (e.g., value-filtered sampling) with better action coverage.
- Tools/workflows:
- Add ensemble-based posterior covariance estimation (bootstrapped models) to your BC pipeline.
- Train diffusion policies with action-target noise scaled by posterior covariance (alpha-tuned).
- Finetune with DPPO, DSrl, or value-guided Best-of-N sampling.
- Assumptions/dependencies:
- Sufficient demonstration data for target tasks/domains.
- Availability of reward signals during RL finetuning.
- Expressive generative policy class (e.g., diffusion) and compute for ensembles.
- Safety constraints and guardrails during online RL in physical systems.
- Multi-task robotic pretraining that adapts efficiently to single tasks
- Sector: robotics, generalist robot models
- Use cases:
- Train a single policy across diverse tasks (e.g., Libero-style) using PostBC, then efficiently finetune on a specific task/site.
- Tools/workflows:
- Multi-task diffusion transformers + PostBC noise-injected training.
- Per-task or per-scene RL finetuning with on-policy or value-filtered methods.
- Assumptions/dependencies:
- Multi-task datasets with task identifiers/conditioning inputs (e.g., language prompts).
- Compute/memory for multi-task model capacity.
- Better pretraining diagnostics for finetuning readiness
- Sector: academia, R&D, MLOps
- Use cases:
- Use “demonstrator action coverage” as a metric to predict finetuning success, not just cross-entropy.
- Early-stop/tune alpha and ensemble size to balance pretrained performance with coverage.
- Tools/workflows:
- Coverage estimator over (state, action) distributions across validation sets.
- Automated hyperparameter sweeps to target coverage thresholds.
- Assumptions/dependencies:
- Access to state-action logging and the ability to estimate/support densities or proxies.
- Proper calibration of coverage in high-dimensional action spaces.
- Safer exploration during online finetuning
- Sector: robotics, industrial automation
- Use cases:
- Reduce overconfident, brittle behavior in sparse-data states by increasing action entropy only where uncertainty is high.
- Tools/workflows:
- Posterior-weighted noise (alpha) controlled per-state using ensemble variance.
- Combine with safety layers (e.g., constraint filters, safety critics).
- Assumptions/dependencies:
- Reliable uncertainty estimation from ensembles or alternative approximations.
- Safety monitors for constraint violations and fail-safes in hardware.
- Drop-in upgrade for existing BC pipelines
- Sector: software/AI tooling, robotics
- Use cases:
- Retrofitting OpenVLA/Octo-style BC systems: add ensemble variance estimation and posterior noise to targets, then proceed with usual finetuning.
- Tools/workflows:
- “Posterior Noise Augmentor” module for PyTorch/TensorFlow imitation learning.
- Bootstrapped ensemble trainers; covariance buffers; alpha scheduling.
- Assumptions/dependencies:
- Access to training code and flexibility to add ensemble heads or separate models.
- Compute overhead for K-model ensembles and noise-injection.
- Improved Best-of-N sampling for decision-time control
- Sector: robotics, autonomous systems, content/plan generation
- Use cases:
- Generate a more diverse but relevant set of candidate actions/plans; select with a value/score model.
- Tools/workflows:
- PostBC-trained diffusion policy for candidate generation; learned critic/value for selection.
- Assumptions/dependencies:
- Tractable evaluation of candidates (scoring function or learned critic).
- Compute budget for sampling N candidates at runtime.
- Academic benchmarking and curriculum design
- Sector: academia
- Use cases:
- Include PostBC in imitation-to-RL benchmarks; compare sample-efficiency vs BC baselines.
- Study coverage–performance trade-offs by varying alpha and ensemble size.
- Tools/workflows:
- Robomimic/Libero/IsaacGym-based evaluations with standardized seeds and metrics.
- Assumptions/dependencies:
- Availability of shared datasets and open-source implementations.
Long-Term Applications
Below are applications that require further research, scaling, or sector-specific development beyond current demonstrations.
- LLM pretraining for RLHF and reasoning tasks
- Sector: software/AI, education
- Use cases:
- Posterior-aware imitation of human demonstrations (e.g., solutions, chain-of-thought) to retain entropy where data is sparse, improving RLHF/DPO sample-efficiency.
- Tools/workflows:
- Token-level posterior variance approximations (ensembles, MC-dropout, deep ensembles).
- PostBC-like sampling during supervised pretraining; RLHF/DPO finetuning thereafter.
- Assumptions/dependencies:
- Scalable and calibrated uncertainty estimates for sequence models.
- Alignment/safety considerations for exploration in text generation.
- Autonomous driving policy adaptation
- Sector: automotive, mobility
- Use cases:
- Use PostBC on large driving logs to improve coverage of human behaviors; finetune in high-fidelity simulators or shadow mode before deployment.
- Tools/workflows:
- Dataset distillation + posterior-aware BC; simulator-based RL finetuning and safety filters.
- Assumptions/dependencies:
- High-quality, diverse demonstrations; realistic simulators; rigorous safety validation and regulatory approval.
- Healthcare and assistive robotics
- Sector: healthcare, eldercare, rehabilitation
- Use cases:
- Learn from clinician/therapist demonstrations; safely finetune in controlled trials for personalization (e.g., assistive grasping, feeding).
- Tools/workflows:
- Posterior-aware imitation; constrained RL; clinician-in-the-loop evaluation.
- Assumptions/dependencies:
- Strict safety, ethics, and regulatory governance; robust perception; well-defined reward proxies.
- Energy and industrial process control
- Sector: energy, manufacturing
- Use cases:
- HVAC optimization, plant control: learn policy priors from operator logs; finetune on digital twins and gradually in production with constraints.
- Tools/workflows:
- Posterior-aware BC from logs; conservative RL with safety constraints; anomaly detection.
- Assumptions/dependencies:
- Accurate simulators/digital twins; safe RL under hard constraints; reliable reward signals (KPIs).
- Algorithmic trading and execution
- Sector: finance
- Use cases:
- Learn from trader demonstrations; maintain coverage to avoid overfitting to observed regimes; cautiously finetune online under risk constraints.
- Tools/workflows:
- Posterior-aware imitation; risk-sensitive RL; offline backtesting + live shadow mode.
- Assumptions/dependencies:
- Compliance and risk controls; non-stationarity handling; robust uncertainty estimation.
- Personalized home assistants and IoT agents
- Sector: consumer robotics, smart homes
- Use cases:
- Quickly adapt to user-specific routines from a few demos (e.g., tidying, fetching) with minimal online trials.
- Tools/workflows:
- On-device/edge PostBC with privacy-preserving ensembles; small-scale RL finetuning.
- Assumptions/dependencies:
- Resource constraints on-device; privacy and data governance; robust perception in unstructured environments.
- Standards and governance for safe exploration in learning systems
- Sector: policy, standards bodies
- Use cases:
- Incorporate “coverage” and posterior-aware pretraining as recommended practices for systems that will undergo online adaptation.
- Tools/workflows:
- Benchmark suites and audit checklists (coverage thresholds, uncertainty calibration tests).
- Assumptions/dependencies:
- Community consensus, standardized metrics, sector-specific safety cases.
- Active data collection and curation strategies
- Sector: academia, data providers
- Use cases:
- Use posterior variance to target new demonstrations in low-coverage states; improve dataset efficiency.
- Tools/workflows:
- Active learning loops guided by ensemble variance; data valuation and acquisition policies.
- Assumptions/dependencies:
- Pipeline for incremental data collection; interfaces to solicit new demos; budget and human-in-the-loop availability.
- Tooling for posterior-regularized imitation learning at scale
- Sector: AI tooling, MLOps
- Use cases:
- General libraries that provide ensemble-based posterior covariance, alpha scheduling, and per-state noise injection across modalities (vision, language, control).
- Tools/workflows:
- Modular PyTorch/JAX components; integration into RL frameworks and foundation robot model stacks.
- Assumptions/dependencies:
- Broad model support and performance engineering; calibration/validation utilities for uncertainty.
Notes on feasibility across all applications:
- Core dependencies: quality and diversity of demonstrations, calibrated uncertainty estimation (ensembles/bootstrapping), expressive generative policies (e.g., diffusion), and safe/efficient RL finetuning mechanisms.
- Key assumptions: rewards (or proxy scores) are available during finetuning; sufficient compute for ensembling; safety constraints are enforced in high-stakes domains.
- Sensitivities: alpha (posterior weight) and ensemble size K must be tuned to balance pretrained performance and action coverage; coverage estimation in high-dimensional spaces must be approximated carefully.
Glossary
- 6-DoF: Six degrees of freedom; the number of independent joint or motion axes of a robot arm. "as well as a real-world WidowX 250 6-DoF robot arm"
- action distribution: The probability distribution over actions that a policy selects in a state. "adjust the entropy of its action distribution based on this uncertainty"
- behavioral cloning (Bc): Supervised imitation learning that trains a policy to mimic actions from demonstrations. "behavioral cloning (Bc)---which trains a policy to directly match the actions played by the demonstrator---can fail to ensure coverage over the demonstrator's actions"
- Best-of- sampling: A technique that samples multiple outputs from a model and selects the best according to a scoring function. "an effective predictor of the downstream success of Best-of- sampling"
- bootstrapped sampling: Resampling with replacement from a dataset to estimate uncertainty or construct ensembles. "bootstrapped sampling \citep{fushiki2005nonparametric,osband2015bootstrapped,osband2016deep}---where we sample with replacement from ---typically outperforms directly adding noise to the actions in "
- cross entropy loss: A standard loss for probabilistic models measuring divergence between predicted and true distributions. "cross entropy loss is not predictive of downstream finetuning performance"
- demonstrator action coverage: A property where a pretrained policy assigns sufficient probability to actions that the demonstrator might take. "We say policy achieves demonstrator action coverage with parameter "
- diffusion models: Generative models that learn to reverse a noise diffusion process to sample from complex distributions. "instantiate PostBc with modern generative models---diffusion models---on robotic control tasks"
- diffusion transformer: A transformer-based architecture adapted for diffusion modeling. "we utilize a diffusion transformer architecture due to \cite{dasari2024ingredients}"
- Dppo: An on-policy policy-gradient algorithm for finetuning diffusion policies. "Dppo \citep{ren2024diffusion}, an on-policy policy-gradient-style algorithm for finetuning diffusion policies"
- Dsrl: A method that refines a pretrained diffusion policy by optimizing over its latent-noise variables with RL. "Dsrl \citep{wagenmaker2025steering}, which refines a pretrained diffusion policy's distribution by running RL over its latent-noise space"
- entropy: A measure of randomness or uncertainty in a distribution. "if we add entropy to the action distribution at each state proportional to our uncertainty about the demonstrator's behavior"
- ensemble: A collection of models trained to represent variability or approximate a posterior. "fits an ensemble of predictors to a perturbed version of "
- exploration noise: Random perturbations added to a policy to encourage exploring unseen actions or states. "add exploration noise to our pretrained policy"
- generative models: Models that learn to produce samples from the data distribution. "with modern generative models---diffusion models---on robotic control tasks"
- horizon: The fixed number of steps per episode in an MDP. "episodic, fixed-horizon Markov decision processes (MDPs)."
- latent-noise space: The space of noise variables used in generative sampling that can be optimized or steered. "running RL over its latent-noise space"
- Libero: A simulated robotic manipulation benchmark suite with multi-task demonstrations. "We test on both the Robomimic \citep{mandlekar2021matters} and Libero \citep{liu2023libero} simulators"
- Markov decision process (MDP): A formal framework for sequential decision making with states, actions, transitions, rewards, and horizon. "Markov decision processes (MDPs)."
- Markovian policy: A policy that selects actions based solely on the current state (and step), not past history. "We assume that as "
- posterior sampling: Selecting actions or policies by sampling from the posterior distribution. "the first example of applying posterior sampling to Bc"
- residual policies: Smaller learned controllers that add corrections to a base pretrained policy’s actions. "learning smaller residual policies to augment the pretrained policy's actions"
- Robomimic: A simulated robotics benchmark with human demonstrations for manipulation tasks. "We test on both the Robomimic \citep{mandlekar2021matters} and Libero \citep{liu2023libero} simulators"
- rollout: Executing a policy in an environment to collect a trajectory of states and actions. "denotes a trajectory rollout of "
- sample efficiency: Achieving effective performance or learning progress with few environment interactions. "Critical to achieving successful RL-based finetuning performance ... is sample efficiency"
- sampling cost: The number of samples required to obtain desired coverage or improvement. "achieves a near-optimal sampling cost out of all policy estimators"
- support (effective support): The set of actions with nonzero probability under a policy, relevant for enabling improvement. "we consider the following definition for the ``effective'' support of a policy"
- suboptimality: The performance gap between a learned policy and an optimal or baseline policy. "incurs no suboptimality in the performance of the pretrained policy as compared to the standard Bc policy"
- tabular setting: A finite, discrete-state/action representation without function approximation. "In the tabular setting, which we consider in \Cref{sec:theory}"
- U-Net: A convolutional encoder-decoder architecture with skip connections used for vision-based policies. "we utilize a U-Net architecture with image observations"
- uniform prior: A prior distribution that assigns equal probability to all possible behaviors or actions. "assuming a uniform prior over the demonstrator's behavior"
- value function: An estimator of expected return used to evaluate or filter actions/policies. "filter the output of the pretrained policy with a learned value function"
- WidowX 250: A specific robotic arm platform used for real-world experiments. "as well as a real-world WidowX 250 6-DoF robot arm"
Collections
Sign up for free to add this paper to one or more collections.