- The paper introduces a novel multilingual encoder-decoder TTS architecture that uses persistent, bidirectional text conditioning to maintain semantic grounding over long audio sequences.
- It employs Progress-Monitoring RoPE for precise duration control, significantly improving performance—especially in Japanese—while bypassing traditional phoneme conversion.
- Evaluation on diverse languages demonstrates superior intelligibility and voice cloning capabilities, highlighting the model's efficacy in scalable zero-shot synthesis.
T5Gemma-TTS: An Encoder-Decoder Framework for Multilingual Zero-Shot Text-to-Speech with Persistent Text Conditioning and Duration Control
Model Architecture and Innovations
T5Gemma-TTS introduces a multilingual encoder-decoder approach to zero-shot text-to-speech synthesis, directly addressing limitations inherent in conventional decoder-only neural codec LLMs (NCLMs). The core architecture leverages the T5Gemma backbone, comprising a 2B-parameter encoder and a 2B-parameter decoder, initialized with broad UL2 text pretraining. Unlike decoder-only models, which treat input text as a prefix and suffer from text-conditioning dilution over extended audio generations, T5Gemma-TTS routes bidirectional text representations via cross-attention at every decoder layer. This persistent and structured text-conditioning mechanism ensures robust semantic grounding regardless of the generated sequence length.
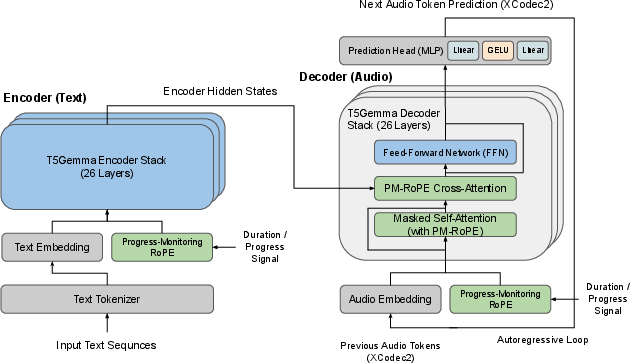
Figure 1: T5Gemma-TTS architecture, highlighting persistent bidirectional text conditioning and PM-RoPE cross-attention throughout every decoder layer.
Generation is performed autoregressively, producing XCodec2 audio tokens conditioned jointly on encoder outputs and a reference speech prompt. Utilizing the single-codebook XCodec2 codec provides efficient mapping and reconstruction fidelity, especially for Japanese, given the fine-tuned decoder. Crucially, T5Gemma-TTS bypasses explicit phoneme conversion—subword tokens from SentencePiece, inherited from multilingual pretraining, enable seamless text processing for English, Chinese, and Japanese.
Progress-Monitoring RoPE for Duration Control
Duration control is a critical challenge in autoregressive TTS. T5Gemma-TTS integrates Progress-Monitoring Rotary Position Embedding (PM-RoPE) within all 26 cross-attention layers. PM-RoPE injects normalized generation-progress signals, enabling continuous decoder awareness of its position relative to target speech length. During inference, the target length is estimated via heuristics based on reference phoneme counts, and PM-RoPE dynamically conditions cross-attention queries on normalized progress IDs.
A configuration analysis demonstrates the essentiality of PM-RoPE: disabling PM-RoPE at inference causes near-catastrophic synthesis failure on Japanese—CER rises from 0.129 to 0.982, and duration accuracy drops from 79% to 46%. This evidences that PM-RoPE enables reliable text-conditioned decoding and coherent duration tracking, especially in models trained to exploit this mechanism.
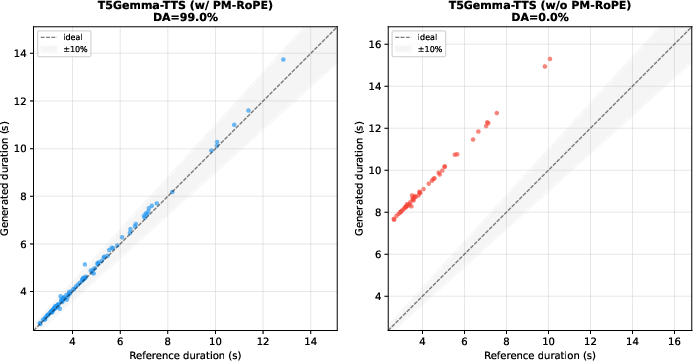
Figure 2: Duration tracking with PM-RoPE enabled yields near-perfect correlation to target; disabling PM-RoPE leads to breakdown in duration control.
Multilingual Training and Evaluation
T5Gemma-TTS is trained on ~170k hours of audio spanning three typologically diverse languages: English (100k h), Mandarin Chinese (50k h), and Japanese (20k h), sourced from Emilia and LibriHeavy corpora. Evaluation covers six languages: the three in-training, plus Korean, French, and German (FLEURS), allowing assessment of cross-lingual generalization.
Intelligibility and speaker similarity metrics are computed using Whisper and ECAPA-TDNN embeddings, respectively, while UTMOS provides an objective estimation of perceived naturalness. On Japanese, T5Gemma-TTS achieves the lowest CER (0.126) and statistically significant SIM advantage (0.677±0.016 vs. XTTSv2 0.622±0.016) among all systems evaluated. The model also demonstrates strong cross-lingual transfer: Korean SIM (0.747±0.029) is numerically highest despite Korean being absent during training, supporting the claim that multilingual subword pretraining and typological proximity facilitate robust generalization.
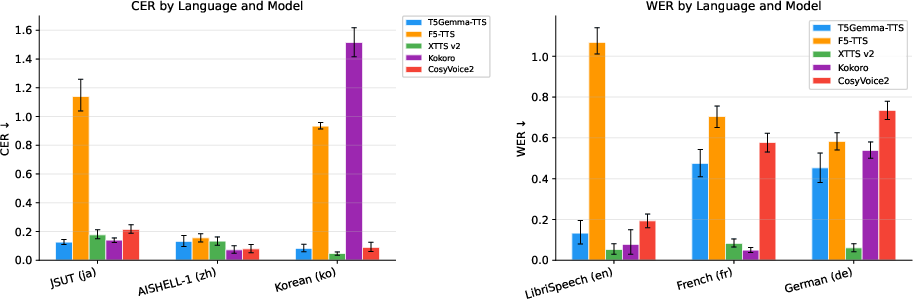
Figure 3: CER/WER across test sets and systems; F5-TTS fails on Japanese, while T5Gemma-TTS attains robust intelligibility.
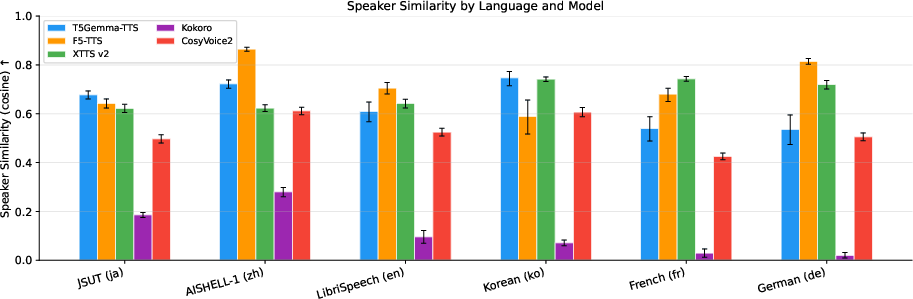
Figure 4: SIM comparison; T5Gemma-TTS achieves strongest similarity on Japanese, and competitive results on Korean.
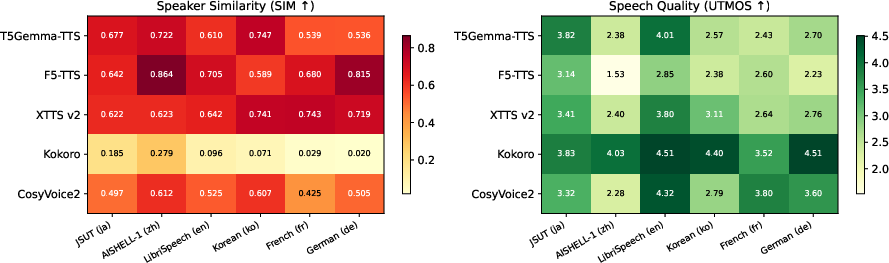
Figure 5: Heatmap of SIM (left) and UTMOS (right) metrics; T5Gemma-TTS leads on SIM for East Asian languages among zero-shot systems.
Architectural Trade-Offs and Ablations
PM-RoPE integration extends duration control properties to multilingual encoder-decoder backbones, generalizing prior VoiceStar results from English to wider language coverage. Empirical analysis confirms that disabling PM-RoPE in inference results in breakdown in all core metrics (CER, SIM, UTMOS, duration accuracy), underscoring the mechanism's necessity for coherent decoder behavior.
The reliance on subword tokenization, instead of phoneme conversion, simplifies multilingual input pipelines and preserves embedding transferability but may introduce non-monotonic text–audio alignment. The model’s ability to extrapolate to out-of-training languages—especially those with typological affinity—is further facilitated by extensive subword vocabulary coverage.
T5Gemma-TTS demonstrates competitive or superior performance in intelligibility and speaker similarity on in-training languages, with robust cross-lingual generalization to Korean. XTTSv2 and CosyVoice2 maintain dominance in European language intelligibility and naturalness, respectively; however, T5Gemma-TTS’s SIM scores highlight its efficacy in voice cloning for Japanese and Korean, attributed to persistent text conditioning and the encoder-decoder backbone.
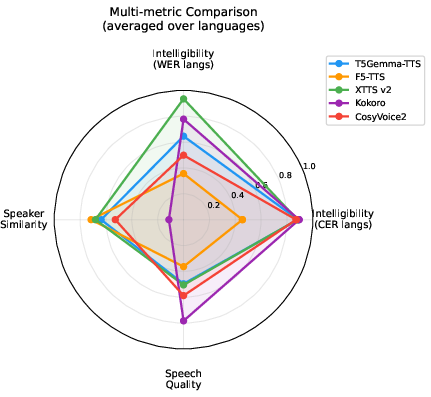
Figure 6: Radar chart visualizes normalized multi-metric averages, illustrating T5Gemma-TTS’s balanced performance and strength in East Asian voice cloning.
CosyVoice2 and Kokoro achieve higher UTMOS scores, reflecting strengths in naturalness, but their SIM is substantially lower given limited voice cloning capabilities. F5-TTS exhibits high SIM in certain languages but catastrophic intelligibility failure in Japanese, highlighting unresolved trade-offs in flow-matching models.
Practical and Theoretical Implications
The architecture and training strategy of T5Gemma-TTS provide evidence for the efficacy of large-scale pretrained encoder-decoder models in multilingual TTS settings, particularly with zero-shot voice cloning. The integration of persistent cross-attention pathways fundamentally alters conditioning dynamics, enabling stable text–audio alignment irrespective of output length. The confirmed generalizability of PM-RoPE advances duration control as a primary architectural requirement in autoregressive speech generation.
Practically, T5Gemma-TTS enables offline, high-fidelity, controllable long-form synthesis applications such as audiobooks, where persistent semantic conditioning and explicit duration control are critical. The voice cloning capability introduces dual-use risks, with implications for privacy and misuse, mandating responsible deployment and research-centric distribution.
Future Directions
Improving naturalness via post-processing (diffusion or flow-matching refinement), accelerating inference with speculative decoding and distillation, and scaling language coverage via continual pretraining are clear directions. Analysis of subword tokenization versus phoneme-based conditioning in PM-RoPE models warrants further controlled ablation. Extending input pipelines and duration estimators to low-resource languages using cross-lingual text representation remains an open challenge.
Conclusion
T5Gemma-TTS substantiates the advantages of encoder-decoder neural codec LLMs with persistent text conditioning and PM-RoPE duration control in zero-shot multilingual TTS. Statistically significant voice cloning results, especially for Japanese and Korean, and robust intelligibility across typologically diverse languages demonstrate the practical potential for scalable and controllable speech generation. The architecture’s generalizability and methodological findings inform subsequent developments in multilingual TTS, encoder-decoder conditioning, and explicit duration control in autoregressive models (2604.01760).