OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models
Abstract: We present OmniVoice, a massive multilingual zero-shot text-to-speech (TTS) model that scales to over 600 languages. At its core is a novel diffusion LLM-style discrete non-autoregressive (NAR) architecture. Unlike conventional discrete NAR models that suffer from performance bottlenecks in complex two-stage (text-to-semantic-to-acoustic) pipelines, OmniVoice directly maps text to multi-codebook acoustic tokens. This simplified approach is facilitated by two key technical innovations: (1) a full-codebook random masking strategy for efficient training, and (2) initialization from a pre-trained LLM to ensure superior intelligibility. By leveraging a 581k-hour multilingual dataset curated entirely from open-source data, OmniVoice achieves the broadest language coverage to date and delivers state-of-the-art performance across Chinese, English, and diverse multilingual benchmarks. Our code and pre-trained models are publicly available at https://github.com/k2-fsa/OmniVoice.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces OmniVoice, a text-to-speech (TTS) system that can read text out loud in more than 600 languages. It can copy a speaker’s voice from just a few seconds of audio (this is called “zero-shot” voice cloning). The key idea is a simpler, faster way to turn text into natural, clear speech across many languages, including ones that don’t have much training data.
The big questions the researchers asked
The authors focused on a few easy-to-understand goals:
- Can we build one TTS model that works well in hundreds of languages, not just a few?
- Can we make it fast and stable, so it speaks clearly and naturally?
- Can we avoid complicated multi-step pipelines and still get great sound quality?
- Can we help the model pronounce words correctly by starting it off with strong language knowledge?
- Can users control the voice (like removing background noise, choosing voice traits, or fixing tricky pronunciations)?
How the system works (in plain language)
Here’s the big picture: OmniVoice reads text and directly produces speech “building blocks,” then turns those into audio. It avoids the typical two-step approach that can lose detail or pass along mistakes.
From text straight to speech “building blocks”
- Think of making speech like building with LEGO bricks. Each tiny brick is an “acoustic token” that represents a small slice of sound.
- OmniVoice uses several “codebooks” at once. You can imagine these like a stack of transparent sheets: one might capture pitch, another tone color (timbre), another rhythm, and so on. Stacking them together creates a detailed voice.
- Instead of first predicting a rough “meaning layer” and then turning that into sound (the old two-stage method), OmniVoice goes straight from text to these multi-layer sound tokens. This keeps fine details and avoids passing errors from one stage to the next.
Learning by hiding and revealing pieces (masking)
- Training the model is like a fill-in-the-blank puzzle. The model sees the text, a short audio prompt of the target voice, and a big grid of speech tokens—except many tokens are hidden.
- “Full-codebook random masking” means the model hides random pieces across all layers at once (not just one layer at a time). Because it practices filling in many blanks every time, it learns faster and better—like doing more of the puzzle on each try.
Borrowing smarts from LLMs (LLM initialization)
- Good pronunciation depends on understanding language. The authors “start” OmniVoice with the knowledge of a pre-trained LLM, so it already knows a lot about words, spelling, and grammar.
- This makes the speech more intelligible (easier to understand), especially in tricky or unfamiliar languages.
Training data and balancing languages
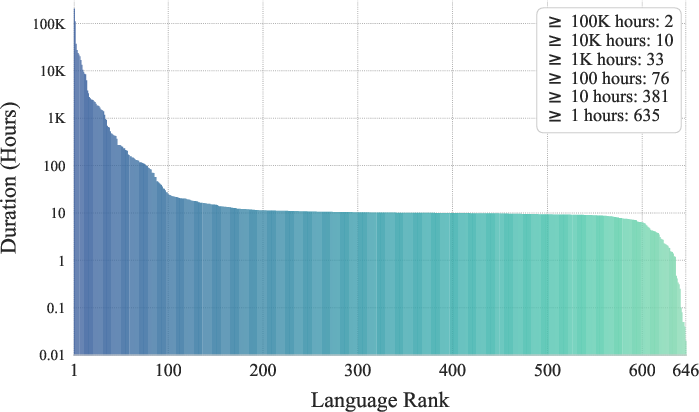
- The team gathered about 581,000 hours of audio from open-source data in over 600 languages. That’s huge.
- Some languages have tons of data, others have very little. To be fair, they repeat (upsample) the rarer languages more often during training—like giving quieter students extra turns to speak—so the model gets good at them, too.
Extra controls you can give the system
OmniVoice supports handy “controls” that make it more useful in real life:
- Clean-noise prompts: If your voice sample has noise (like traffic or echo), the model learns to keep your voice but remove the noise, producing clean speech.
- Pick voice traits: If you don’t have a sample, you can describe the voice (e.g., “female, warm, mid-pitch, slight accent”) and the model generates it.
- Fix tricky pronunciations: For hard words or names, you can provide phonetics (like Pinyin for Chinese or phonemes for English) so the model says them exactly right.
What did they find?
OmniVoice delivered strong, state-of-the-art results:
- Very wide language coverage: It works in 600+ languages, which is much broader than most TTS systems.
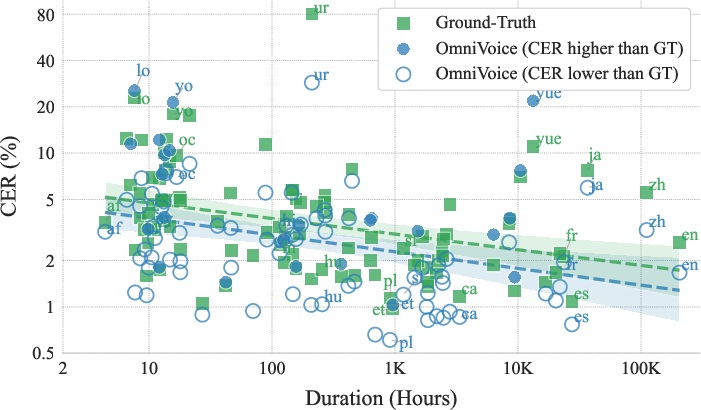
- High quality and clarity: It speaks clearly (low error rates), sounds natural, and keeps the speaker’s voice characteristics well.
- Works well even for low-resource languages: It stays understandable even when there’s very little training data for a language.
- Fast generation: Because it fills in many parts at once (non-autoregressive), it can generate speech faster than real time on a single GPU.
- Competitive with top systems: It matches or outperforms popular models on Chinese, English, and multilingual benchmarks. The authors even compare favorably to commercial systems on a 24-language test and show strong performance on a 102-language test.
Why these results matter:
- Directly predicting the acoustic tokens avoids the common “two-stage” problems (like lost details or error chains).
- The full-codebook random masking speeds up learning and improves quality.
- Starting from an LLM makes speech easier to understand from day one.
Why it matters
OmniVoice can bring natural-sounding TTS to many communities at once:
- Inclusion: Speakers of low-resource or under-served languages can get high-quality TTS and voice cloning, which helps with education, accessibility, and digital participation.
- Content creation: Audiobooks, podcasts, tutoring, and dubbing can be produced in many languages with consistent quality.
- Language support: It can help preserve and promote languages that don’t have much data available.
- Practical control: Users can clean noise from prompts, design voices with attributes, and ensure precise pronunciations—useful for names, technical terms, or language learning.
Key takeaways
- OmniVoice is a simple-but-powerful TTS design that goes straight from text to detailed sound tokens.
- It learns faster and better by masking random parts across all sound layers and by starting with a LLM’s knowledge.
- Trained on a massive, open-source multilingual dataset, it supports 600+ languages and performs at or near the state of the art.
- It’s fast, controllable, and works well even for languages with little data—bringing high-quality TTS to a much larger part of the world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances multilingual zero-shot TTS with a simplified discrete NAR architecture, but several aspects remain uncertain or underexplored. The following concrete gaps can guide future research:
- Data quality and bias
- Quantify residual transcription and audio noise after “speech restoration” and rule-based filtering across the 50 source datasets; report per-language noise rates and their effect on intelligibility and speaker similarity.
- Assess demographic, accent, gender, and age distributions per language to identify biases that may affect voice design controllability and fairness.
- Evaluate coverage of dialects and orthographic variants within languages (e.g., Arabic dialects, Chinese regional readings, Hindi–Urdu script variants), and whether the model conflates or preserves them.
- Report code-switching prevalence in the training data and study its impact on mixed-language synthesis.
- Text processing and front-end
- The model relies on an LLM subword tokenizer and avoids G2P for most languages; measure the impact on languages with opaque orthography or rich morphology (e.g., English, French, Irish, Amharic) and those lacking standard orthographies.
- Extend and evaluate explicit phonetic overrides beyond Chinese Pinyin and English CMU phonemes to other languages (e.g., Vietnamese, Yoruba, Thai, Arabic), and analyze the trade-offs in usability and accuracy.
- Acoustic tokenization choices
- Analyze how the Higgs-audio 8-codebook tokenizer’s bitrate and codebook count constrain fine-grained prosody and timbre; provide ablations on codebook numbers/bitrates and their effect on quality, diversity, and speed.
- Compare discrete acoustic tokens with continuous latent representations within the same architecture to quantify the diversity/quality trade-offs.
- Objective design and sampling
- Provide theoretical and empirical analysis of the full-codebook random masking scheme (e.g., convergence properties, gradient variance) versus per-layer masking under varying mask ratios and codebook counts.
- Explore alternative inference schedules (e.g., different unmasking curves, adaptive step counts) and sampling strategies (top-k, nucleus, stochastic token assignment) for quality–speed trade-offs and prosodic variability.
- Investigate the sensitivity of classifier-free guidance scale, layer penalties, and temperature to language, prompt quality, and utterance length; develop auto-tuning or language-adaptive settings.
- LLM initialization
- Systematically compare different LLMs (size, training data, multilingual coverage) for initialization; quantify gains across language families and scripts, and minimal viable LLM scale for strong intelligibility.
- Study how causal LLMs initialized for bidirectional masking preserve or forget linguistic knowledge (catastrophic forgetting) during TTS fine-tuning; test partial freezing and adapters.
- Evaluate whether LLM initialization improves pronunciation for low-resource languages with limited text normalization or scarce text corpora.
- Alignment and prosody control
- Analyze how the single-stage mapping implicitly learns duration and rhythm without explicit aligners; add and evaluate controls for speaking rate, pause placement, and phrasing.
- Introduce objective prosody metrics (e.g., F0 RMSE, energy contours, duration/phoneme timing errors) and human judgments of expressiveness beyond WER/CER and UTMOS.
- Controllability validation
- Quantitatively evaluate prompt denoising’s effect on similarity and intelligibility across noise types and SNRs; characterize the quality–similarity trade-off and provide user controls for denoise strength.
- Benchmark speaker-attribute-based voice design (gender, age, pitch, accent) on unseen combinations and languages; report attribute prediction accuracy and disentanglement (e.g., does changing pitch alter perceived accent?).
- Extend paralinguistic control beyond laughter (e.g., sadness, anger, emphasis) and measure fidelity, naturalness, and controllability across languages.
- Multilingual generalization
- Provide ablations on the data balancing hyperparameter β and alternative sampling schemes; measure effects on high- vs. low-resource languages and catastrophic forgetting over long training.
- Evaluate truly low-resource languages (<1–5 hours) and languages unseen during training (zero-shot across language families) to establish limits of generalization.
- Test cross-lingual voice cloning robustness (prompt language A, target text language B) for many language pairs, including distant families and tonal vs. non-tonal transfers.
- Evaluation methodology
- Reduce dependence on ASR-based intelligibility where ASR is unreliable; conduct human MOS/CMOS/SMOS across a representative subset of the 600+ languages, including low-resource and tonal languages.
- Introduce pronunciation error taxonomies (e.g., phoneme confusions, tone errors, geminate/diphthong issues) to pinpoint language-specific failure modes.
- Validate subjective evaluation at scale for multilingual benchmarks (not just Chinese/English) and examine inter-rater agreement per language.
- Long-form and conversational synthesis
- Assess long-form generation (paragraphs, audiobooks) for prosodic coherence, fatigue artifacts, and stability over minutes; test memory of discourse cues and paragraph-level phrasing.
- Evaluate conversational turn-taking, breath noise insertion, and natural pause placement in dialogues; analyze latency for interactive applications.
- Robustness and edge cases
- Test robustness to messy inputs: punctuation errors, casing, numerals, abbreviations, emoji, mixed scripts, typos, and transliteration; provide normalization strategies or confidence-based fallbacks.
- Measure performance on tonal languages specifically for tone stability and sandhi phenomena (e.g., Mandarin, Cantonese, Vietnamese, Yoruba, Thai), beyond CER.
- Examine sensitivity to prompt length and content (e.g., 1–2 seconds, cross-channel prompts, compressed or bandwidth-limited audio).
- Comparisons and ablations
- Provide parameter- and data-matched comparisons to two-stage discrete NAR and AR baselines to isolate architectural effects versus data scale.
- Ablate each proposed inference component (layer penalty, CF guidance, temperature, schedule) on multilingual datasets, not only Emilia.
- Analyze scaling laws (model size, data size, steps) for quality and coverage, and determine the next performance bottlenecks.
- Vocoder/codec effects
- Quantify reconstruction artifacts of the chosen codec across languages and speakers; test alternative neural codecs and their impact on high-frequency content, fricatives, and sibilants.
- Investigate codebook interaction modeling and whether independent prediction heads limit cross-codebook consistency.
- Efficiency and deployment
- Report memory footprint, latency, and RTF on commodity GPUs, CPUs, and edge devices; explore distillation or step truncation without large quality loss.
- Evaluate streaming/online TTS (low-latency chunked synthesis) and its trade-offs with bidirectional context.
- Safety, misuse, and watermarking
- Address impersonation risks for 600+ languages; evaluate or integrate watermarking/traceability and anti-spoofing measures.
- Study the effect of prompt denoising and attribute control on potential misuse (e.g., removing recording artifacts to evade detection).
- Reproducibility and data governance
- Provide reproducible pipelines for data curation (restoration, filtering, balancing) and document licensing constraints per dataset; enable community audits and dataset updates.
- Release per-language training hours after filtering and scripts to reproduce language IDs and mappings used by the model.
These gaps point to concrete experiments, evaluations, and engineering work that can strengthen the scientific claims and practical readiness of large-scale omnilingual TTS.
Practical Applications
Below is a concise synthesis of practical, real-world applications that follow from the paper’s findings, methods, and innovations. Each item includes suggested sectors and potential tools or workflows, along with key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed now using the released code/models and standard integration patterns.
- Healthcare: Multilingual patient communications and IVR
- Use case: Hospitals and clinics deliver appointment reminders, triage instructions, medication and discharge guidance in patients’ preferred languages (including low-resource ones).
- Tools/workflows: OmniVoice API microservice integrated with EHR/CRM; IVR/CCaaS platforms; optional ASR+MT for voice-to-voice encounters.
- Assumptions/dependencies: Clinical terminology support; consent and governance for any voice cloning; ASR/MT quality for some languages; regulatory compliance (HIPAA/GDPR).
- Public sector & emergency services: Inclusive alerts and public information
- Use case: Municipalities broadcast public service announcements, emergency alerts, and voter information in hundreds of languages; hotline services support callers with multilingual voice responses.
- Tools/workflows: Cloud or on-prem TTS service; CMS-integrated voice publishing; templated scripts with phonetic overrides for names/places.
- Assumptions/dependencies: Vetting of pronunciations for critical terms; content authenticity/watermarking policy.
- Contact centers and customer service (Finance, Retail, Utilities)
- Use case: Low-latency, zero-shot multilingual voicebots and IVR with brand-consistent voices; outbound compliance messages and reminders at scale.
- Tools/workflows: OmniVoice behind conversational AI stacks (Rasa/Dialogflow/Genesys); speaker-attribute voice libraries for brand “personas”; prompt denoising for field recordings.
- Assumptions/dependencies: Guardrails for voice cloning consent; latency budgets met with 16–32 inference steps; speech-to-text quality where bi-directional dialogues are needed.
- Media and entertainment: Multilingual dubbing and localization
- Use case: Films, series, games, podcasts, audiobooks localized rapidly into 50–600+ languages with controllable prosody and paralinguistics (e.g., laughter, affect).
- Tools/workflows: DAW/NLE plugins; batch dubbing pipelines with script alignment; phonetic overrides for proper nouns; attribute-driven voice casting without prompts.
- Assumptions/dependencies: IP/licensing for cloned voices; editorial QA for emotion and timing; lip-sync may need separate tools (e.g., viseme/lip-sync engines).
- Education and e-learning
- Use case: Courseware, MOOCs, and K–12 materials voiced in learners’ native languages; language-learning apps synthesize examples with precise pronunciation control.
- Tools/workflows: LMS integrations; auto-generation of lesson audio; dictionary and example sentences via phoneme/Pinyin inputs for edge cases.
- Assumptions/dependencies: Curriculum approvals; consistent pronunciations for domain jargon; acoustic style guidance for age-appropriate tone.
- Accessibility and assistive tech
- Use case: Screen readers and assistive communication devices deliver natural, intelligible speech for low-resource languages and dialects; personalized voices for users with speech impairments.
- Tools/workflows: On-device or edge-accelerated TTS SDK; voice cloning from small personal recordings; denoise mode to avoid ambient artifacts.
- Assumptions/dependencies: Compute availability on edge; privacy-preserving storage; quality variability on extremely scarce-language settings.
- Robotics and IoT (Smart home, service robots)
- Use case: Multilingual audio responses with expressive, user-configurable voices on devices and robots; robust to noisy prompts captured in the field.
- Tools/workflows: Embedded SDKs; attribute-based voice templates; latency tuning (reduced steps, quantization).
- Assumptions/dependencies: Hardware constraints; real-time factor targets; local memory for acoustic tokenizers/vocoder.
- Developer platforms and software tooling
- Use case: TTS APIs/SDKs for apps; CI/CD pipelines that generate localized audio assets on commit; rapid A/B testing of voice styles.
- Tools/workflows: REST/gRPC endpoints; caching and batch synthesis; configuration of guidance scales and unmasking steps for quality/latency trade-offs.
- Assumptions/dependencies: Proper caching and token budgets; licensing for commercial deployment; monitoring intelligibility for long-tail languages.
- Marketing and creator economy
- Use case: Creators and marketers produce multilingual voiceovers, micro-segmented campaigns, and personalized ads with consistent brand voices.
- Tools/workflows: Web studio with speaker-attribute sliders; pronunciation dictionaries; paralinguistic markup for emphasis and emotion.
- Assumptions/dependencies: Consent and disclosure for synthetic voices; content moderation; regional ad regulations.
- Academia and R&D: Multilingual TTS baseline and data augmentation
- Use case: Researchers use OmniVoice as a reproducible baseline for TTS, prosody control, and low-resource language modeling; generate synthetic speech to augment ASR datasets.
- Tools/workflows: Open-source repo and checkpoints; data balancing scripts; full-codebook random masking in other tokenized generative tasks.
- Assumptions/dependencies: Reproducibility across different tokenizers; dataset licensing for redistribution; evaluation (ASR) biases for specific languages.
- ML engineering: Training efficiency and architecture transfer
- Use case: Apply full-codebook random masking to speed up training and improve quality in discrete multi-codebook generators (music, sound effects); initialize NAR backbones with LLM weights for higher intelligibility.
- Tools/workflows: Swap-in masking schedule; LLM-weight transfer to bidirectional Transformers; iterative unmasking schedules.
- Assumptions/dependencies: Compatibility with tokenizer/vocoder stacks; availability of suitable LLM weights; careful learning-rate tuning.
Long-Term Applications
These require further research, scaling, productization, or cross-modal integration.
- Real-time, full-duplex conversational agents (Healthcare, Finance, Customer Support)
- Use case: Human-level voice assistants operating across 600+ languages with consistent persona and emotional nuance in real time.
- Dependencies: Further latency reduction (fewer diffusion steps, distillation); fast ASR and MT integration; robust diarization and turn-taking; on-device acceleration.
- End-to-end speech-to-speech translation with consistent speaker identity
- Use case: Live cross-lingual conversations and media translation that preserve the speaker’s voice timbre and style.
- Dependencies: Tight coupling with ASR+MT; prosody transfer; lip-sync for video; quality control for long-tail languages.
- On-device/edge deployment at scale (Phones, wearables, cars)
- Use case: Offline TTS in many languages for privacy and reliability.
- Dependencies: Model compression/quantization; smaller acoustic tokenizers/vocoders; energy-efficient decoding; memory footprint reductions.
- Advanced expressive control for creative industries
- Use case: Fine-grained control of emotion, speaking style, and actor-like performance for dubbing, games, and virtual humans.
- Dependencies: Larger and diverse expressive datasets; standardized markup for paralinguistics; feedback-in-the-loop tools for directors.
- Language revitalization and preservation
- Use case: Community tools to create learning materials, audiobooks, and public-service content for endangered languages with few speakers.
- Dependencies: Expert-in-the-loop pronunciation verification; ethical data sourcing; trust frameworks with communities.
- Regulatory and policy frameworks for synthetic speech
- Use case: Standardized disclosures, watermarking, and provenance for synthetic audio used in public services, ads, and political communications.
- Dependencies: Industry and standards-body alignment; watermarking robustness; detection benchmarks for multilingual audio.
- Cross-modal production pipelines (Audio + video lip-sync)
- Use case: Automated localization that aligns synthesized speech with mouth movements and cultural context in video.
- Dependencies: Integration with visual lip-sync models; actor/scene-aware timing models; editorial toolchains.
- Personalized medical voice prostheses
- Use case: Patients retain or restore their own or designed voices (with controlled prosody/emotion) for daily communication.
- Dependencies: Clinically-validated pipelines; ethical consent/ownership; ultra-low-latency edge inference.
- Robust evaluation for omnilingual intelligibility and naturalness
- Use case: New benchmarks and metrics beyond current ASR-based WER/CER to evaluate TTS across hundreds of languages.
- Dependencies: Community-built test sets; human-in-the-loop evaluation protocols; bias and fairness audits.
- Secure, compliant voice identity management
- Use case: Enterprise-grade systems to manage voice rights, consent, and usage logs for cloned or designed voices.
- Dependencies: Rights management infrastructure; audio watermarking; legal frameworks across jurisdictions.
- Generalization of the training innovations to other domains
- Use case: Apply full-codebook random masking and LLM-initialized bidirectional NAR backbones to music generation, sound design, and other token-based modalities.
- Dependencies: Suitable discrete tokenizers; domain-specific datasets; convergence and quality validation in new modalities.
Each application’s feasibility depends on several shared assumptions and dependencies:
- Data and licensing: Verify commercial-use rights for any training or prompt data and obtain consent for any voice cloning.
- Tokenizer/vocoder stack: OmniVoice relies on a multi-codebook acoustic tokenizer and a compatible vocoder (e.g., Higgs-audio); swapping components may affect quality/latency.
- Compute and latency: Meeting real-time constraints may require step reduction, model distillation, or hardware acceleration.
- Language variability: Performance in extremely low-resource languages may require phonetic overrides or human QA.
- Safety and ethics: Implement watermarking/provenance, user consent flows, and misuse detection to comply with laws and norms.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update in Adam to improve generalization. "The AdamW optimizer~\cite{loshchilov2017decoupled} is used, with a peak learning rate of $1e-4$ and a cosine learning rate schedule that includes 3\% of total training steps as warmup."
- affective cues: Labeled nonverbal or emotional signals in speech used to enable expressive synthesis. "we incorporate paralinguistic control (e.g., laughter) by training on datasets enriched with affective cues~\cite{liao2025nvspeech,ye2025scalable}."
- autoregressive (AR): A modeling paradigm that generates outputs sequentially, conditioning on previously generated tokens. "current research primarily adheres to two paradigms: autoregressive (AR)~\cite{du2024cosyvoice2,guo2024fireredtts,zhou2025indextts2,jia2025ditar,wang2025spark,ye2025llasa,song2025distar,zhou2025voxcpm,cui2025glm} and non-autoregressive (NAR) models~\cite{le2023voicebox,eskimez2024e2,chen2024f5}."
- BF16: A 16-bit floating-point format (bfloat16) used for mixed-precision training to save memory and speed up computation. "Mixed precision (BF16) and sequence packing (8192 tokens per GPU) are employed during training to improve efficiency."
- bidirectional context: Using information from both past and future positions in a sequence during modeling. "NAR models offer advantages in both inference speed (via parallel decoding) and robustness (owing to bidirectional context)~\cite{le2023voicebox,chen2024f5,yang2025pseudo}."
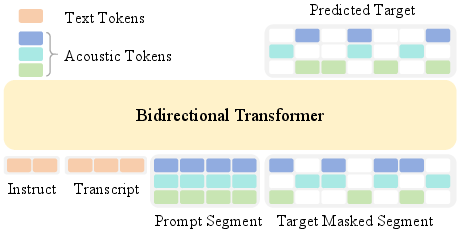
- bidirectional Transformer: A Transformer that attends to both left and right context, enabling non-causal sequence modeling. "the model is trained with discrete diffusion objection and adopts a bidirectional Transformer backbone."
- Bernoulli distribution: A distribution over binary outcomes used here to sample token masks. "we independently sample a binary mask for every entry in the token matrix"
- causal mask: An attention mask that restricts a model to only attend to past positions to ensure autoregressive behavior. "While these LLMs are originally trained with a causal mask, we empirically find that their pre-trained knowledge translates well to our bidirectional architecture."
- character error rate (CER): An ASR-based metric measuring the percentage of character-level transcription errors. "Intelligibility is measured using word error rate (WER) or character error rate (CER) across different languages."
- classifier-free guidance: A sampling technique that blends conditional and unconditional model predictions to steer generation. "classifier-free guidance~\cite{ho2021classifierfree} is utilized in the log-softmax space with a guidance scale of 2."
- CMU pronunciation dictionary: A lexicon that maps English words to their phoneme sequences for pronunciation control. "phonemes from the CMU pronunciation dictionary for English."
- codebook: A discrete set of token indices representing quantized audio features used by neural codecs. "OmniVoice directly maps text to multi-codebook acoustic tokens."
- comparative mean opinion score (CMOS): A subjective evaluation where listeners rate the relative quality difference between two audio samples. "These objective metrics are supplemented with subjective evaluations, including comparative mean opinion score (CMOS, )"
- cosine learning rate schedule: A schedule that decays the learning rate following a cosine function over training. "a cosine learning rate schedule that includes 3\% of total training steps as warmup."
- diffusion LLM: A language modeling framework that iteratively denoises masked/noisy tokens to generate sequences. "OmniVoice is a single-stage NAR TTS model with a diffusion LLM style architecture~\cite{nie2025large,ye2025dream}."
- discrete masked diffusion objective: A training objective where the model reconstructs masked discrete tokens via iterative denoising. "OmniVoice employs a discrete masked diffusion objective~\cite{sahoo2024simple} with a bidirectional Transformer~\cite{vaswani2017attention}"
- ECAPA-TDNN: A speaker embedding architecture used for speaker similarity evaluation. "we use SIM-o~\cite{le2023voicebox} with a WavLM-based~\cite{chen2022wavlm} ECAPA-TDNN model~\cite{desplanques2020ecapa}."
- FLEURS: A multilingual speech dataset commonly used for cross-lingual evaluation. "FLEURS-Multilingual-102: A 102-language multilingual benchmark constructed from the dev/test splits of the FLEURS dataset~\cite{conneau2023fleurs}"
- full-codebook random masking: A masking scheme that stochastically masks entries across all codebooks to increase training signal density. "Full-codebook random mask"
- grapheme-to-phoneme conversion: The process of converting written characters to phonemes for pronunciation; often language-specific. "eliminating cumbersome grapheme-to-phoneme conversion and language-specific text normalization."
- Higgs-audio tokenizer: A neural audio tokenizer that discretizes audio into multiple codebooks for modeling and reconstruction. "The Higgs-audio tokenizer~\cite{higgsaudio2025} is adopted to extract 8-codebook acoustic tokens and reconstruct audio from these tokens."
- HuBERT: A self-supervised speech representation model used here as an ASR backbone for evaluation. "we use the Hubert-based ASR model~\cite{hsu2021hubert} for LibriSpeech-PC test-clean"
- iterative unmasking: A generation procedure that progressively reveals masked tokens over multiple steps. "During inference, we perform a 32-steps iterative unmasking process."
- language-level data resampling: A data balancing method that adjusts sampling frequency per language to mitigate resource imbalance. "we apply a language-level data resampling strategy."
- layer penalty: A bias in decoding that prioritizes unmasking or predicting certain codebook layers before others. "We also apply a layer penalty on the confidence scores to encourage unmasking lower-layer tokens first."
- LLM initialization: Initializing a model with pre-trained LLM weights to transfer linguistic knowledge. "we initialize our backbone with pre-trained AR LLM weights to inherit linguistic knowledge"
- log-softmax: The logarithm of the softmax probabilities, often used for numerical stability in sampling and loss computation. "by sampling from the confidence scores in the log-softmax space."
- long-tail distribution: A skewed distribution where many categories (e.g., languages) have small amounts of data. "Setting retains the natural long-tail distribution of the dataset"
- mask token [M]: A special placeholder token indicating positions to be predicted/denoised. "tokens are randomly replaced with a special mask token ."
- MaskGCT: A discrete-token TTS framework employing layer-wise masking; used here as a baseline and masking variant. "MaskGCT-style mask"
- non-autoregressive (NAR): A modeling paradigm that predicts all (or many) outputs in parallel without conditioning on previous outputs. "non-autoregressive (NAR) models~\cite{le2023voicebox,eskimez2024e2,chen2024f5}."
- parallel decoding: Generating multiple tokens simultaneously during inference for efficiency. "NAR models offer advantages in both inference speed (via parallel decoding)"
- Paraformer-zh: A Mandarin ASR model used to compute intelligibility metrics. "Paraformer-zh~\cite{gao2022paraformer} for Chinese"
- paralinguistic control: Control over non-lexical vocal behaviors (e.g., laughter) to enhance expressiveness. "we incorporate paralinguistic control (e.g., laughter)"
- Pinyin: A romanization system for Chinese characters used for phonetic specification. "specifically Pinyin for Chinese"
- prompt denoising: Training and inference mechanism to remove noise/reverberation from reference prompts while preserving speaker identity. "we implement a prompt denoising task~\cite{zhang2025advanced,wang2024investigation}."
- prosodic diversity: Variation in rhythm, stress, and intonation of speech; important for naturalness. "The latter was shown to yield superior prosodic diversity~\cite{yang2025measuring}."
- real-time factor (RTF): The ratio of processing time to audio duration; lower is faster. "report the real-time factor (RTF) across different batch sizes and inference steps."
- repetition factor: A per-language multiplier used to upsample low-resource languages during training. "we upsample the training data of low-resource languages by assigning a repetition factor, , to each language ."
- reverberation: Acoustic reflections that smear speech over time; often undesirable in prompts. "by injecting synthetic noise and reverberation into the prompt segments."
- rule-based filtering: Heuristic text filtering to remove invalid or noisy transcriptions. "applied rule-based filtering~\cite{zhu2025zipvoicedialog} to exclude invalid transcriptions."
- sequence packing: Concatenating multiple sequences into longer ones to better utilize hardware parallelism during training. "sequence packing (8192 tokens per GPU) are employed during training to improve efficiency."
- SIM-o: An objective speaker similarity metric computed from speaker embeddings. "For speaker similarity evaluation, we use SIM-o~\cite{le2023voicebox}"
- similarity mean opinion score (SMOS): A subjective score where listeners rate how similar synthesized speech is to a reference speaker. "similarity mean opinion score (SMOS, )"
- state-of-the-art (SOTA): The best performance known in the literature at the time of writing. "delivers state-of-the-art performance across Chinese, English, and diverse multilingual benchmarks."
- subword tokenizer: A text tokenizer that segments text into subword units for multilingual robustness. "we employ the subword tokenizer of pre-trained LLMs"
- speaker-attribute-based voice design: Specifying target speaker traits (e.g., gender, age, pitch) to synthesize voices without prompts. "OmniVoice supports speaker-attribute-based voice design~\cite{hu2026voicesculptor,hu2026qwen3}."
- speech restoration model: A model that improves degraded audio quality (e.g., denoising, dereverberation). "we employed a speech restoration model~\cite{nakata2025sidon} to enhance degraded speech"
- TensorRT: An NVIDIA inference optimization toolkit to accelerate neural networks. "its inference efficiency can be further improved with acceleration techniques such as TensorRT."
- text-to-semantic: The first stage in a two-stage pipeline that predicts intermediate semantic tokens from text. "two-stage cascaded pipelines (text-to-semantic followed by semantic-to-acoustic)."
- time-shifted schedule: A progression curve that delays early unmasking and accelerates later stages during iterative decoding. "The cumulative proportion of unmasked tokens at step , denoted as , follows a time-shifted schedule:"
- two-stage cascaded pipelines: Architectures that decompose TTS into sequential modules (e.g., text→semantic→acoustic), risking error compounding. "two-stage cascaded pipelines (text-to-semantic followed by semantic-to-acoustic)."
- UTMOS: An objective metric predicting perceived speech quality (MOS) using learned models. "We also adopt UTMOS~\cite{saeki2022utmos} to assess objective speech naturalness."
- uniform distribution: A distribution with equal probability over an interval; used here to sample mask ratios. "the masking ratio is drawn from a uniform distribution "
- upsample: To increase the sampling frequency of underrepresented data (e.g., low-resource languages) during training. "we upsample the training data of low-resource languages"
- vocoder: A neural decoder that converts discrete or acoustic tokens into waveform audio. "Params. (Parameters) denotes the total parameter size of voice cloning TTS systems (including audio tokenizer, vocoder, and other related components)."
- WavLM: A self-supervised speech model used here to extract embeddings for speaker similarity. "WavLM-based~\cite{chen2022wavlm} ECAPA-TDNN model~\cite{desplanques2020ecapa}."
- Whisper-large-v3: An open ASR model used for intelligibility evaluation across many languages. "Whisper-large-v3~\cite{radford2023robust}"
- word error rate (WER): An ASR-based metric measuring the percentage of word-level transcription errors. "Intelligibility is measured using word error rate (WER) or character error rate (CER) across different languages."
- zero-shot text-to-speech (TTS): Generating speech in a target voice/language without explicit training examples for that specific setting, often using a short prompt. "Zero-shot text-to-speech (TTS) models trained on large-scale datasets have demonstrated a remarkable ability to generate high-quality speech"
- zero-shot voice cloning: Mimicking a target speaker’s voice without speaker-specific training data. "yet lacks zero-shot voice cloning capabilities and relies on language-specific modeling."
Collections
Sign up for free to add this paper to one or more collections.