- The paper showcases a novel end-to-end TTS system using neural transducers that enforce monotonic alignment to accurately map text to speech tokens.
- It combines an autoregressive Transformer for initial token prediction with a non-autoregressive residual codebook head to enhance synthesis quality and reduce error rates.
- Experimental results on LibriTTS-R indicate that increasing model complexity improves intelligibility, rivaling state-of-the-art models like Bark and VALL-E-X.
TTS-Transducer: End-to-End Speech Synthesis with Neural Transducer
Introduction
The TTS-Transducer presents a novel approach to text-to-speech (TTS) synthesis by integrating neural transducers with audio codec models. This model addresses the inherent challenge of aligning textual inputs with the variable length and continuous nature of speech outputs. Utilizing neural transducers, the TTS-Transducer enforces monotonic alignment constraints, which are critical for maintaining order and coherence in generated speech. Moreover, by leveraging neural audio codecs, the model facilitates the conversion of speech into discrete audio tokens, enabling the application of text modeling techniques.
Model Architecture
The architecture comprises two primary components: a neural transducer for predicting initial audio codes and a non-autoregressive Transformer for subsequent code prediction. The transducer, responsible for learning monotonic alignments between text and speech codec tokens, capitalizes on its ability to handle discrete prediction tasks despite the continuous nature of raw audio data.
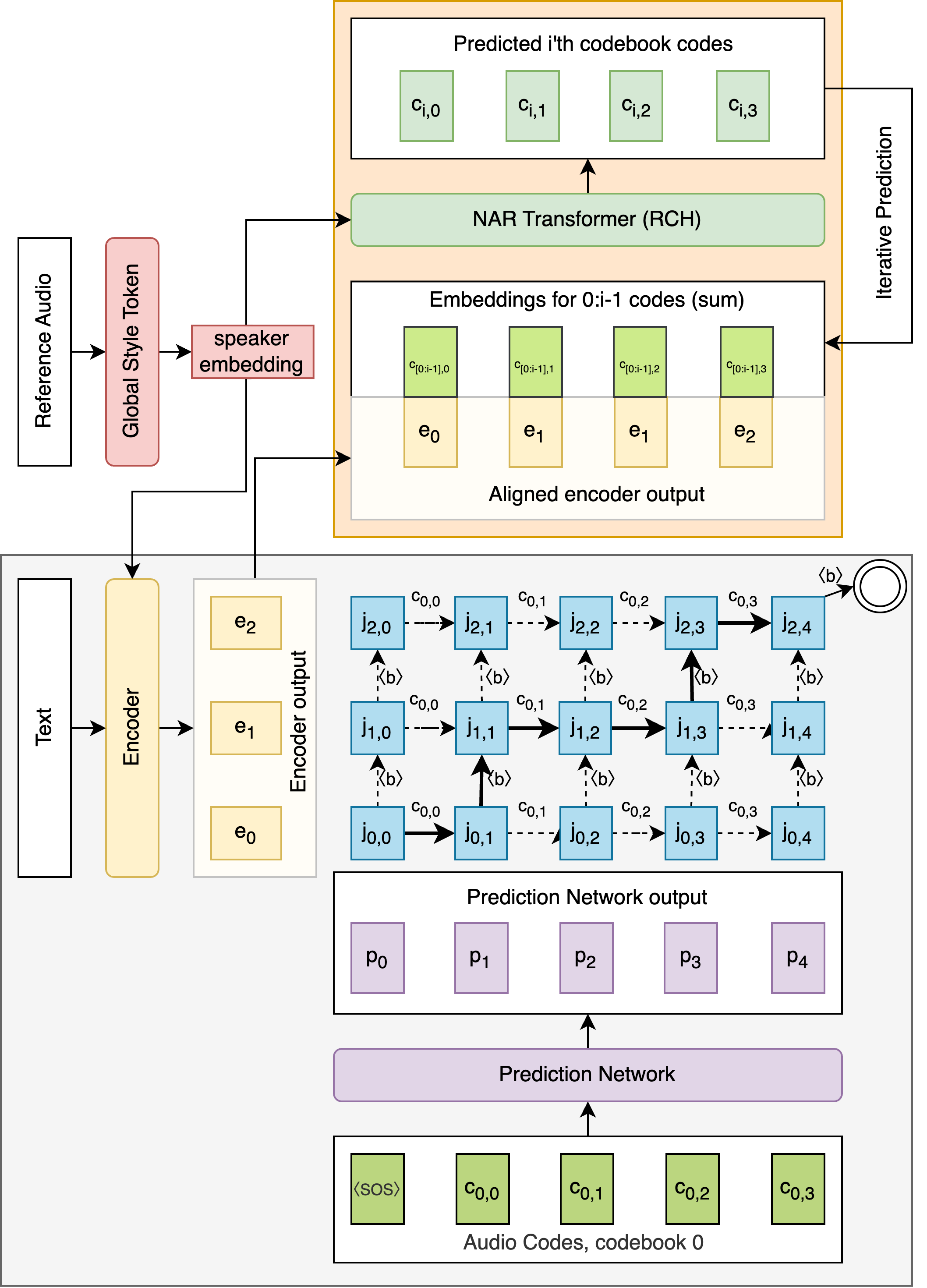
Figure 1: TTS-Transducer model architecture.
In detail, the encoder processes tokenized text to generate vectors, while the prediction network, an autoregressive Transformer-Decoder, uses these vectors to predict token sequences. The joint network combines these outputs to optimize the alignment probability distribution. The second component, the residual codebook head, predicts remaining audio codes using a non-autoregressive Transformer conditioned on speaker embeddings via Global Style Tokens (GST).
Methodology
The TTS-Transducer handles the extensive memory requirements of traditional transducer applications by using a residual codebook head to iteratively predict residual codes. This component improves efficiency by leveraging the alignment learned via the transducer loss. The training utilizes a weighted loss function combining RNNT and cross-entropy losses to optimize both components jointly.
Experiments and Results
Experiments conducted on the LibriTTS-R dataset demonstrated the TTS-Transducer's capability to produce high-quality and robust speech synthesis. The model showed competitive performance across various evaluation metrics including Character Error Rate (CER) and Word Error Rate (WER). Notably, IPA-based models exhibited superior intelligibility compared to their BPE-based counterparts.
Ablation studies reflected that increasing model layers enhances the intelligibility of speech output, confirming the importance of model complexity in producing more accurate alignments and predictions.
Comparison with State-of-the-Art
When compared to contemporary models like Bark and VALL-E-X, the TTS-Transducer exhibited comparable naturalness and superior intelligibility, particularly over challenging text corpora. This demonstrates its robustness and efficiency despite its relatively smaller pretraining requirements.
Implications and Future Directions
The TTS-Transducer signifies a substantial step forward in TTS technology, providing a path for further research into hybrid models that combine neural transducers with powerful sequence modeling frameworks. Future enhancements could explore streaming capabilities and the integration of more complex speaker embeddings to enrich expressive capabilities.
Conclusion
The TTS-Transducer establishes a new paradigm in TTS synthesis by harnessing neural transducer architecture and neural audio codecs. It achieves state-of-the-art performance without necessitating large-scale pretraining, offering a robust, scalable solution for high-quality speech synthesis. The model's flexibility across various codecs and tokenizations underlines its potential for broad applicability in real-world TTS applications.

