- The paper introduces a high-fidelity diffusion-based text-to-speech system that models speech directly in the waveform latent space.
- It leverages a fully convolutional Wav-VAE and a diffusion Transformer backbone with innovations like Adaptive Projection Guidance and prompt correction.
- Empirical results demonstrate state-of-the-art zero-shot voice cloning with improved speaker similarity and competitive intelligibility metrics.
Introduction
LongCat-AudioDiT introduces a non-autoregressive (NAR) diffusion-based text-to-speech (TTS) framework that models speech directly in the waveform latent space. The approach fundamentally diverges from previous paradigms that rely on intermediate representations such as mel-spectrograms and subsequent neural vocoders. The LongCat-AudioDiT system consists solely of a waveform variational autoencoder (Wav-VAE) and a diffusion Transformer backbone, resulting in strong simplification of the TTS pipeline, improved system robustness, and a marked reduction in compounding errors during acoustic-to-waveform conversion.
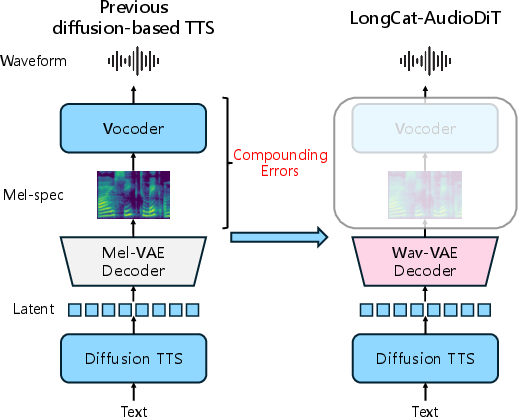
Figure 1: Overview of LongCat-AudioDiT, which generates continuous waveform latents to bypass errors arising from mel-spectrogram prediction and conversion steps.
Core Architecture and Methodology
LongCat-AudioDiT's architecture is comprised of two principal modules: a fully convolutional Wav-VAE that encodes and decodes raw audio waveforms into compact, continuous latents, and a diffusion Transformer (DiT) backbone that models the generative process in this latent space. This design eliminates the requirement for complex acoustic feature prediction and vocoder-based synthesis, which are primary sources of artifacts and fidelity loss in prior methods.
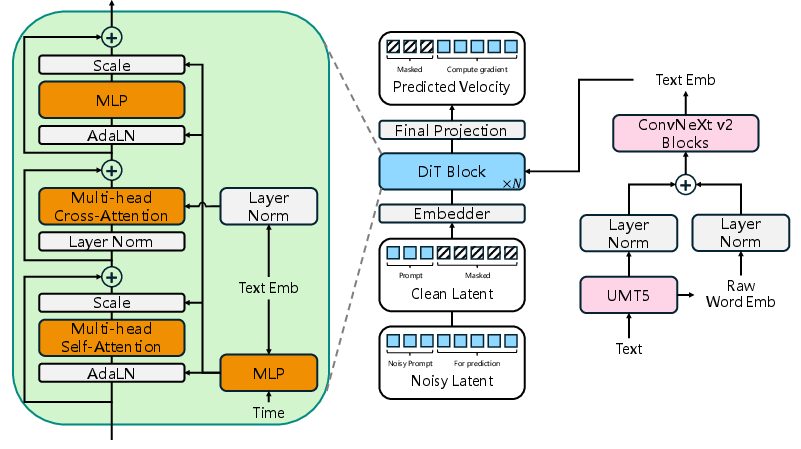
Figure 2: The end-to-end architecture, displaying the DiT backbone and the specialized text encoder suitable for multilingual synthesis.
The diffusion backbone adopts the Conditional Flow Matching (CFM) framework, constructing the generative process as an ODE in latent space. Key innovations include:
- Direct Latent Modeling: Diffusion is performed on continuous Wav-VAE latents rather than mel or other intermediate spaces.
- Alignment-Free End-to-End Training: The DiT leverages cross-attention with a robustly designed multilingual text encoder based on UMT5. Both the raw word embedding and last hidden state of the LLM are combined to preserve phonetic as well as semantic cues.
- Efficient Inference: The system introduces two improvements over standard diffusion inference:
- Rectifying the long-standing training-inference mismatch by explicitly overwriting the prompt region of the noisy latent with its ground truth at each ODE step.
- Replacement of traditional classifier-free guidance (CFG) with Adaptive Projection Guidance (APG), which selectively dampens oversaturated update directions, thus mitigating artifacts without loss of sample diversity.
Wav-VAE Latent Representation
The Wav-VAE is fully convolutional, operating directly in the time domain and capturing multi-scale temporal dependencies using cascaded Oobleck blocks and dilated residual units. Non-parametric shortcut connections are implemented to stabilize aggressive downsampling. Training is adversarial, with the generator loss comprising multi-resolution STFT, multi-scale mel, L1, KL divergence, and adversarial/feature-matching losses. The result is a continuous latent space preserving high-frequency and phase information inaccessible to mel-spectrogram-based approaches.
Empirical Evaluation and Ablation
Main Results
LongCat-AudioDiT establishes state-of-the-art (SOTA) zero-shot voice cloning performance on the Seed benchmark, improving speaker similarity (SIM) over Seed-TTS from 0.809 to 0.818 (Seed-ZH) and from 0.776 to 0.797 (Seed-Hard). These results are achieved with a streamlined, single-stage training paradigm—without reliance on external high-quality, human-annotated corpora. Intelligibility (CER/WER) is competitive with large-scale proprietary systems while using considerably fewer data and simpler pipelines.
Latent Representation Analysis
A comprehensive investigation of the interplay between the properties of the latent space and TTS performance demonstrates several non-trivial phenomena:
- Higher latent dimensionality and higher frame rates increase VAE reconstruction fidelity (as measured by PESQ, STOI, UTMOS) but impede the downstream TTS generation quality when the DiT backbone is held fixed. This contradicts the widespread assumption that optimal VAE fidelity produces optimal TTS.
- There is an optimal latent dimension/frame rate trade-off; exceeding these results in increased modeling difficulty for the diffusion backbone and destabilizes synthesis.
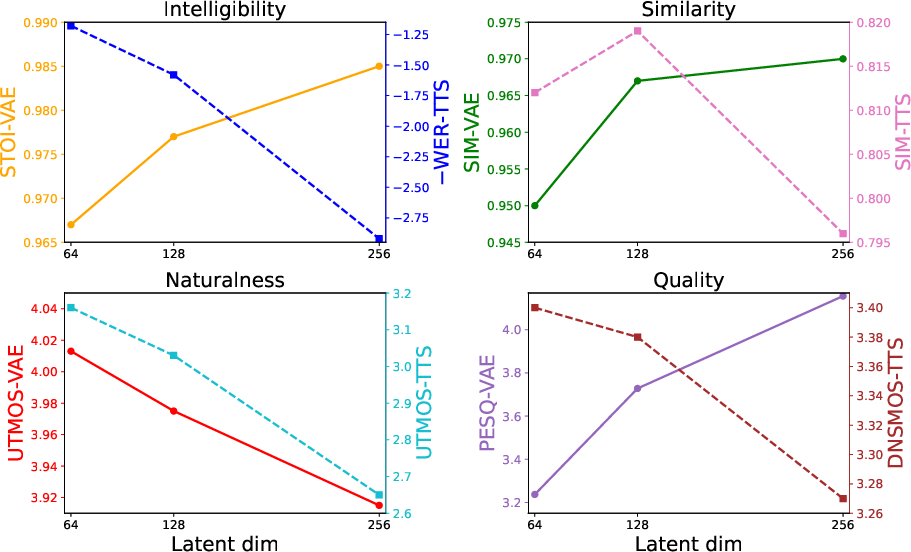
Figure 3: Influence of varying latent dimensionality on both Wav-VAE reconstruction and TTS synthesis efficacy (WER is negated for comparison).
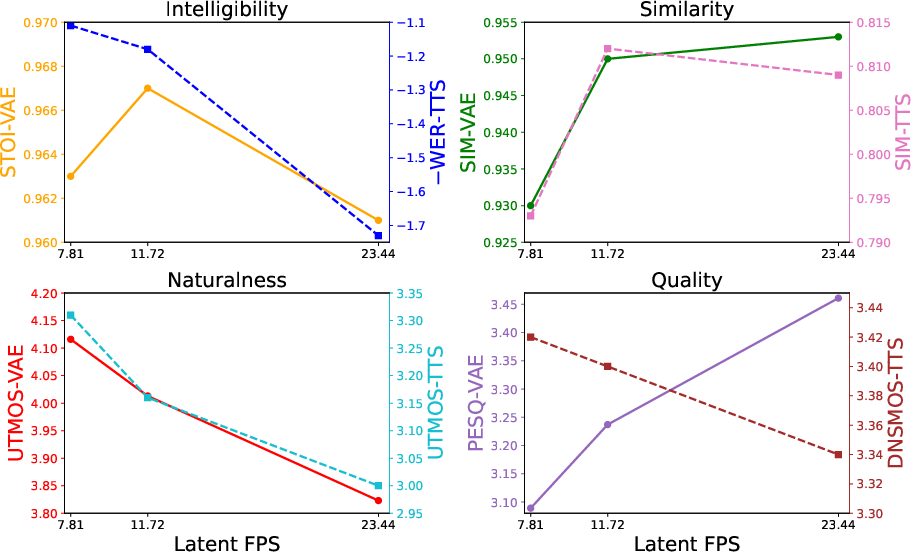
Figure 4: Objective impact of latent frame rate (FPS) on VAE reconstruction and TTS synthesis quality (WER is negated for direct visualization).
Inference Enhancements
Ablation studies isolate the effects of key inference methodologies:
- Training-Inference Mismatch Mitigation: Explicitly correcting the prompt latent during ODE integration consistently increases generation stability and perceptual quality; failing to do so degrades all metrics.
- Adaptive Projection Guidance (APG): APG replaces high-scale CFG, eliminating oversaturation-induced artifacts and resulting in improved naturalness (objective UTMOS/DNSMOS) without harming intelligibility or speaker similarity. This confirms APG’s value in speech generation tasks, paralleling observations in diffusion-based image synthesis domains.
Practical and Theoretical Implications
By circumventing the mel-spectrogram and upsampling vocoder bottleneck, LongCat-AudioDiT demonstrates that high-fidelity, scalable, and robust TTS can be achieved with minimal pipeline complexity. The system's performance underscores the potential for direct latent-space modeling in audio foundation models. Furthermore, the observed generative bottleneck—where increased latent fidelity can impair generative quality—suggests that latent space design must be balanced and co-optimized with diffusion model capacity and training objectives.
For multilingual TTS, integration with generalized LLM text encoders (UMT5) and dual-level embedding extraction offers an effective, language-agnostic approach without suffering from sequence length expansion (as with byte-level tokenization like ByT5).
Future Directions
Potential developments include leveraging reinforcement learning for further aligning synthesis characteristics with human quality perceptions and employing knowledge distillation for real-time, low-latency deployment. These directions could yield more controllable and efficient TTS systems for practical applications, supporting the evolution toward universal audio generative models.
Conclusion
LongCat-AudioDiT presents a minimalistic, end-to-end, diffusion-based TTS model that achieves SOTA zero-shot voice cloning by operating directly in the waveform latent space. Extensive empirical analysis reveals important principles governing the interaction between representation learning and gen-erative modeling in high-dimensional audio. The system is entirely open-sourced, fostering future reproducibility and investigation in diffusion-based speech synthesis.

