- The paper introduces the CSN pipeline that explicitly structures textual causal links to enhance VLA system performance.
- It integrates a Simplex-based semantic safety supervisor with PL-DPO-NLL alignment to ensure runtime safety and robust control.
- Experimental results demonstrate significant driving score gains and reduced dependency on flat text input in diverse simulated conditions.
Causal Scene Narration and Runtime Safety for Vision-Language-Action Driving
Introduction and Motivation
The integration of Vision-Language-Action (VLA) models into autonomous driving introduces new challenges in the composition and utilization of textual prompts for closed-loop driving. Existing VLA systems traditionally pass disconnected textual fragments—such as navigation instructions, hazard alerts, and traffic state notifications—to the model, requiring implicit reasoning about relevance, causal dependency, and safety. This work proposes Causal Scene Narration (CSN), a structured, causal linking approach to the textual representation of driving environments. CSN is complemented with a runtime Simplex-based safety supervisor and a training-time PL-DPO-NLL alignment scheme, aiming to address three major shortcomings: lack of causal structure in text inputs, absence of runtime safety guarantees, and overfitting induced by preference-based reward alignment.
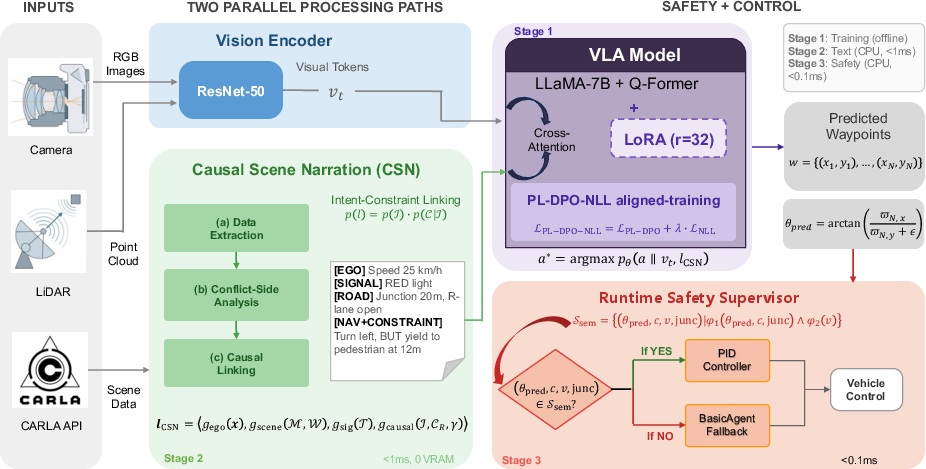
Figure 1: The three-stage architecture integrates CSN restructuring (Stage 2) and semantic runtime safety supervision (Stage 3) atop the standard VLA pipeline.
The core hypothesis is that textual causal structure—not merely the quantity of information—determines VLA system efficacy. Conventional template-based text presents navigational intent and scene constraints as independent fragments, leaving it to the model to infer relevance, similar to the absence of directed edges in a structural causal model. CSN addresses this by explicit alignment: for each navigation intent, relevant environmental constraints are selected, classified by their causal status (blocking, temporal, explanatory), and presented with natural language connectives that reflect this relationship ('BUT', 'BEFORE', 'BECAUSE').
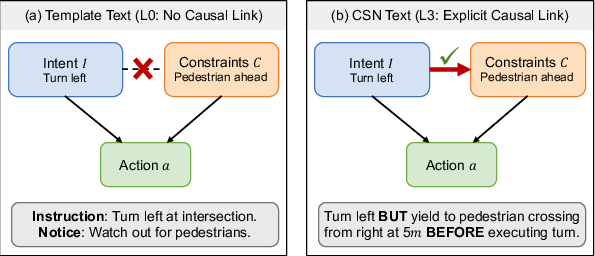
Figure 2: Template text omits causal structure; CSN restores explicit intent-constraint connections using linguistic connectives.
CSN transforms basic scene templates into structured prompts through three principles: quantitative physical grounding (metric details for distances, speeds, and timing), structured information separation (parallel encoding of ego state, roads, signals, and actors), and intent-constraint causal alignment (causal connectives and prioritization). The process is illustrated in a left-turn scenario, showing the progression from unstructured fragments to rich, causally-linked narration.

Figure 3: CSN pipeline illustrated stepwise on a left-turn, converting flat template text into a causally-structured, metric-grounded input.
System Architecture and Safety Supervision
The system architecture couples CSN-based inference-time text restructuring with two forms of safety alignment:
- Semantic runtime supervisor: Utilizes a Simplex switching architecture to monitor waypoints for semantic violations, such as direction inconsistencies at intersections, using Signal Temporal Logic formulae. The supervisor switches control to a reliable, conservative baseline (CARLA Traffic Manager) when VLA outputs violate predefined safety properties.
- PL-DPO-NLL training-time objective: Employs multi-preference Plackett-Luce ranking with NLL regularization to improve safety alignment, but empirical results demonstrate that preference training offers negligible improvements on out-of-distribution generalization and can, in some cases, degrade robustness.
Experimental Design and Evaluation
Experiments are conducted in closed-loop CARLA simulation across 8 towns, 16 routes, and multiple weather and lighting conditions (clear, rain, night, fog), employing the LMDrive backbone with LLaMA-7B. Evaluation considers multiple system variants (with and without CSN, flat text, preference-aligned weights, and safety supervisors), and reports are generated over 5 seeded runs per setup.

Figure 4: Examples of evaluation environments including daytime, heavy rain, nighttime, and dense fog.
Main Empirical Results
CSN achieves +31.1% DS improvement on the original LMDrive and +24.5% on the preference-aligned variant, both with overlapping 95% confidence intervals, indicating robust efficacy regardless of weight configuration. Notably, a flat (non-causal, but information-rich) text ablation reveals that, for the original LMDrive, 39.1% of CSN's gain is independent from information content and attributable solely to causal structure. On the preference-aligned variant, this drops to 13.5%, implying that preference optimization partly internalizes causal linkage, diminishing the additive benefit of explicit causal connectives.
Similarly, semantic safety supervision via intent-aware monitoring improves the Infraction Score (IS), whereas naive, reactive Time-To-Collision (TTC) supervisors degrade both DS and IS, underlining the necessity for contextually-aware (intent-driven) runtime safety.
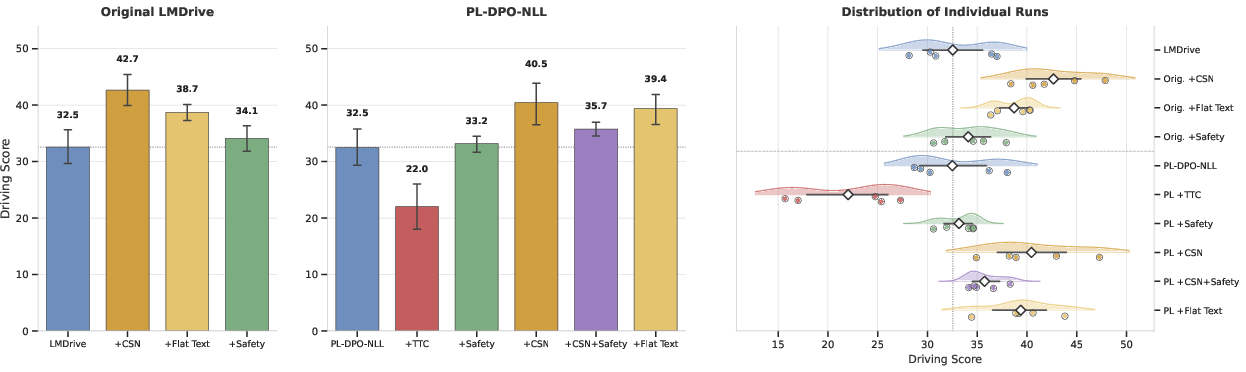
Figure 5: Driving Score comparison across ten system variants, showing robust gains from CSN and the pitfalls of reactive safety monitoring.
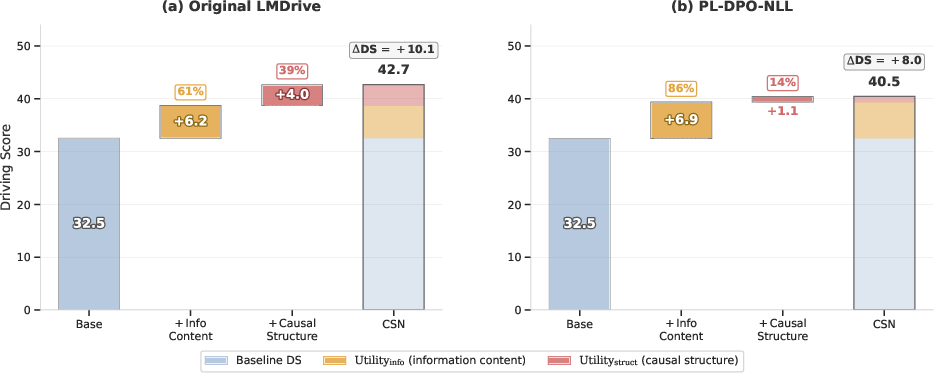
Figure 6: Decomposition of CSN’s Driving Score improvement: the majority comes from increased information, but structural (causal) organization provides a significant unique contribution, especially on non-preference-aligned weights.
Analysis and Implications
The experimental ablation confirms the pivotal role of textual causal structure in VLA system performance. CSN’s benefit is robust to significant perception noise (up to ±5 m distance error, ±30% speed noise, and 20% actor miss rates). This suggests that practical deployment with vision-based perception is feasible, and that further gains require improved architectural or prompt-based reasoning, not precision in environmental statistics.
Interaction analysis reveals that simultaneous use of CSN and safety supervisors can induce performance degradation—not due to direct intervention but rather due to passive control clamping that is mismatched with CSN’s anticipatory steering actions. Removing or relaxing these clamps can mitigate this negative interaction.
CSN’s architecture-agnostic, inference-only design (no extra GPU memory, no retraining) provides a compelling paradigm for rapid enhancement of existing VLA stacks. Future work should address integration with noisy perception, scalable architecture generalization, and adaptive safety policies responsive to input context quality.
Conclusion
This study establishes that explicit causal alignment in scene narration—implemented via the CSN pipeline—offers substantial, robust improvements to VLA-based autonomous driving, independent of underlying model weights or the presence of privileged simulation data. Empirical decomposition shows that while additional information is always beneficial, explicit, structured intent-constraint linking provides a unique performance benefit not attainable via information content alone. Semantic-level, intent-aware runtime supervision yields further safety advantages, while naive, reactive safety logics are detrimental. The results motivate further research into scalable, causally-aware interfaces between vision, language, and action in autonomous decision-making.

