- The paper introduces an instance-aware 4D Gaussian splatting framework that robustly integrates semantic embeddings for temporally coherent dynamic scene modeling.
- It combines optical flow initialization with as-rigid-as-possible regularization and SDF constraints to achieve high-fidelity rendering and precise instance segmentation.
- Comprehensive evaluations on multiple datasets demonstrate significant improvements in rendering metrics and segmentation accuracy over prior methods.
Instance-Aware 4D Gaussian Splatting for Unified Dynamic Scene Reconstruction and Understanding
Introduction
Director introduces an instance-aware, spatio-temporal Gaussian representation that advances dynamic scene modeling and semantic understanding within a unified framework. Prior approaches prioritized photometric and geometric fidelity, frequently at the expense of temporally coherent instance segmentation and open-vocabulary semantic querying. Director's core innovation lies in embedding instance-consistent semantic features directly into the Gaussian primitives, thus enforcing robust tracking and identity consistency across time and viewpoint, and establishing a reliable foundation for language-aligned scene interaction.
Methodology
Director utilizes temporally aligned instance masks (from SAM3) and instance-level language embeddings (from MLLMs) as weak supervision to optimize both geometric and semantic attributes of Gaussian primitives. This results in a primitive-level 4D scene decomposition into static background and dynamic, instance-aware foreground components, each parameterized by learnable appearance and semantic vectors. The joint training procedure integrates photometric and geometric consistency, spatial identity regularization, and temporal priors.
Director explicitly leverages optical flow cues to initialize per-frame Gaussian positions through multi-view triangulation, followed by refinement with an as-rigid-as-possible regularizer, effectively mitigating drift in fast and complex motions. A geometry-aware SDF constraint, in conjunction with temporal and smoothness regularization, further ensures instance mask consistency and suppresses attribute jitter across frames.
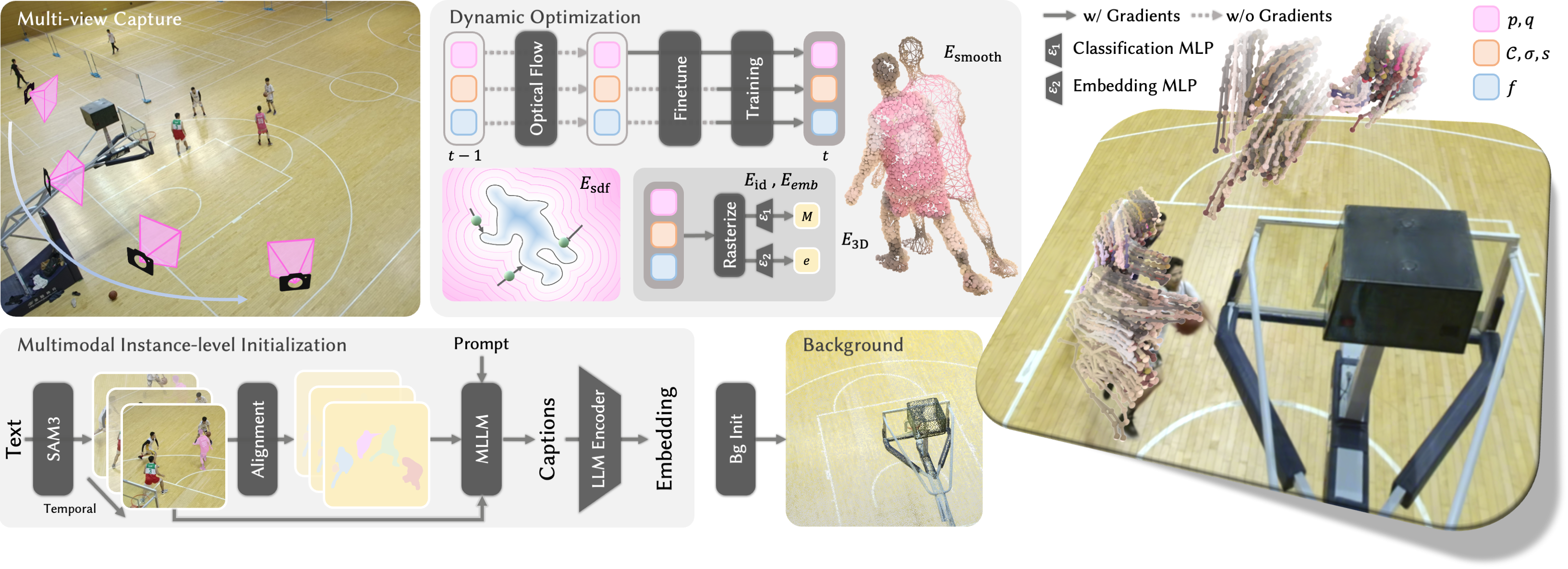
Figure 1: Overview of Director, demonstrating static/dynamic decomposition, multimodal supervision, and semantic embedding for robust dynamic scene understanding.
Semantic Instance Modeling and Language Alignment
Direct integration of instance masks from SAM3 allows Director to establish temporally and spatially consistent instance correspondences across multiple calibrated video streams. Instance-level identities are enforced via an 8-dimensional learnable semantic vector per Gaussian, supervised by MLP decoders for both category classification (via mask prediction) and compact language embedding regression. These embeddings are derived from both global and per-frame captions synthesized by strong MLLMs, providing dense language-grounded supervision for spatio-temporal features relevant to tracking, querying, and downstream editing tasks.
To ensure spatial coherence of learned semantics, a 3D KL-divergence regularization is imposed among k-nearest neighboring Gaussians within each instance, addressing occlusions and supporting manipulation of interior regions.
Dynamic Optimization and Temporal Consistency
For every frame, explicit warping driven by SEA-RAFT optical flow provides robust initialization of dynamic Gaussian properties. After geometric refinement, all attributes are iteratively updated under strong regularization:
Experimental Evaluation
Comprehensive evaluation on ST-NeRF basketball and MPEG GSC datasets demonstrates Director's superiority over state-of-the-art dynamic scene models (4DGS, Spacetime Gaussian, TaoGS) and 4D segmentation solutions (SA4D, SADG, 4-LEGS). Director exhibits high-fidelity rendering under rapid nonrigid motion, while providing consistent, accurate instance-level masks and robust language-driven query performance.
Numerical results indicate strong gains in both rendering (PSNR, SSIM, LPIPS) and segmentation (mIoU, Recall, F1):
- ST-NeRF, PSNR: 38.91, SSIM: 0.967, LPIPS: 0.046 (Director vs. TaoGS: 37.72/0.963/0.056)
- Instance segmentation (basketball): mIoU 0.83, Recall 0.88, F1 0.89 (Director, up to 0.3 improvement over previous methods)

Figure 3: Qualitative comparison with 4DGS, Spacetime Gaussian, and TaoGS—Director yields crisper and more temporally stable results for high-speed sequences.
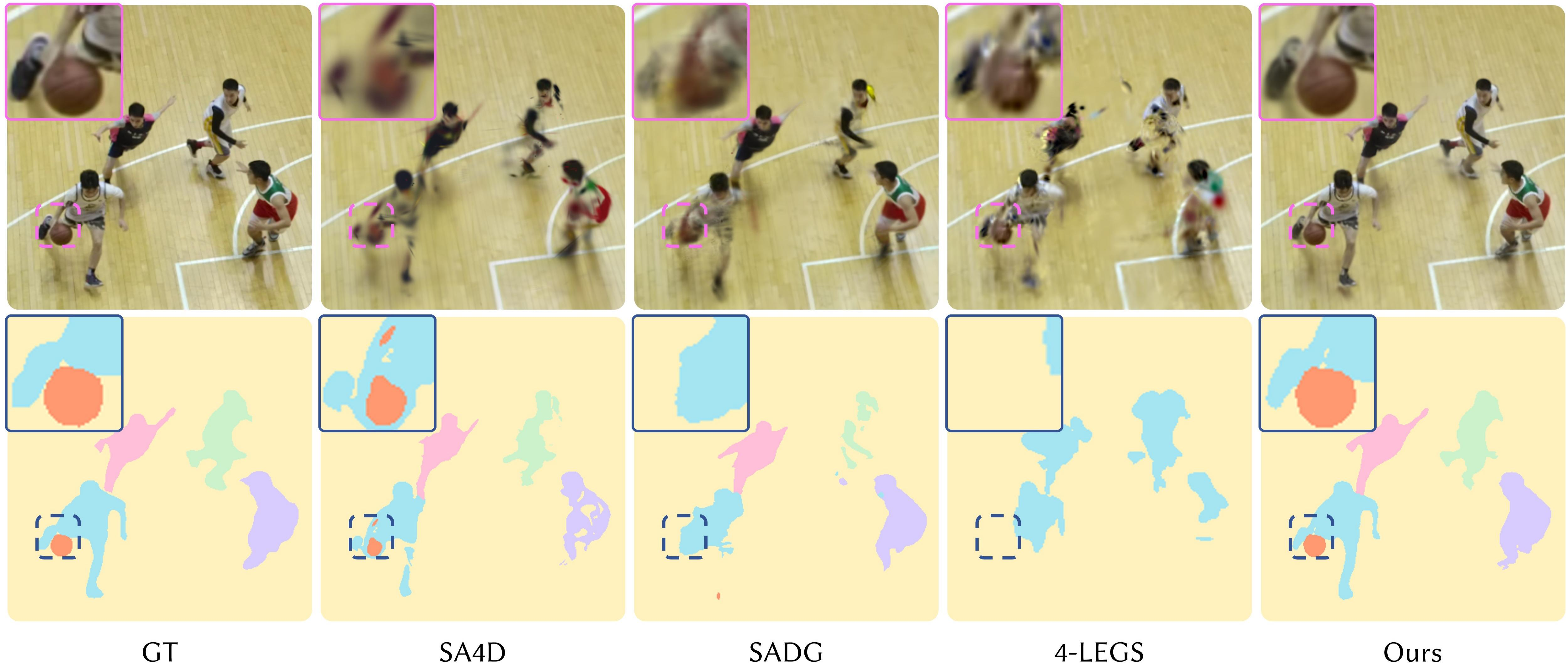
Figure 4: Segmentation benchmarking against SA4D, SADG, and 4-LEGS; Director achieves precise and temporally consistent masks even during strong motion/occlusion.
Ablation and Key Insights
Ablation studies confirm that all key training components—semantic feature embedding, explicit warping, ARAP fine-tuning, semantic/temporal regularization—are critical for optimal performance. Direct removal of language supervision or 3D feature regularization leads to significant degradation in both rendering fidelity and segmentation quality.
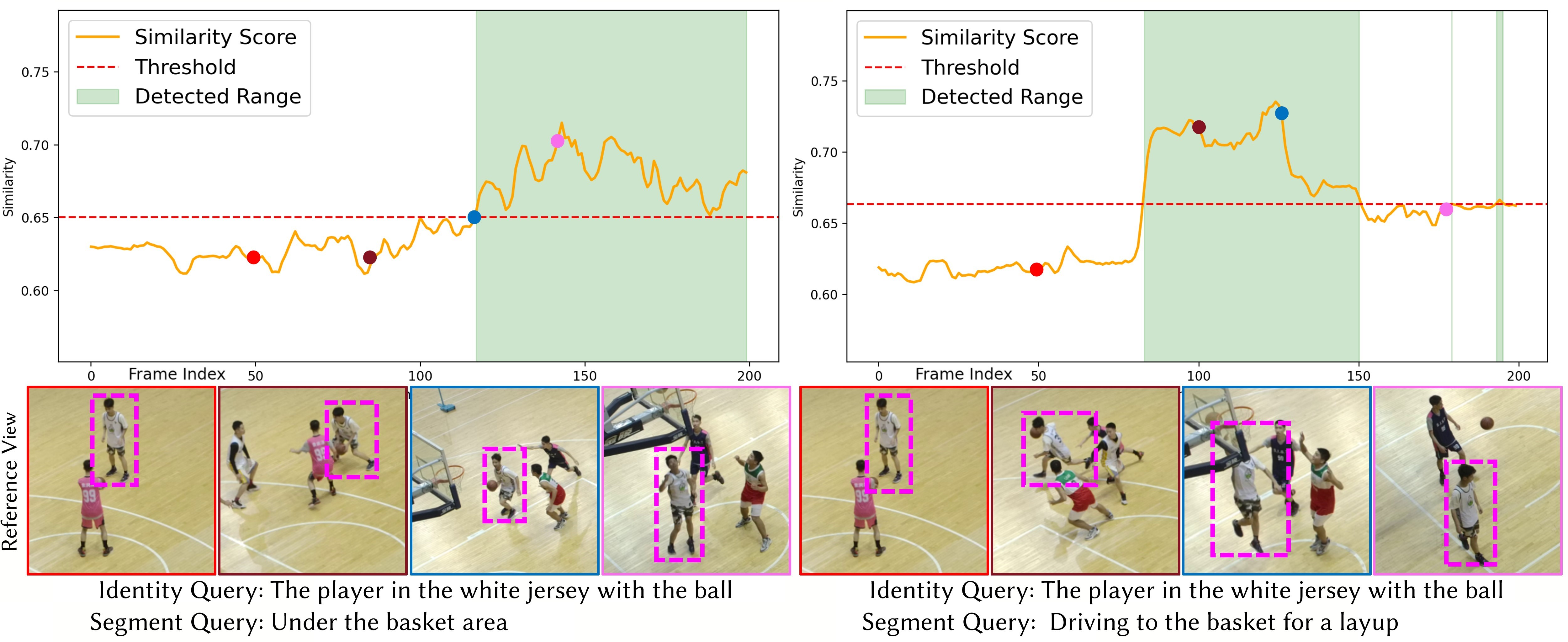
Figure 5: Visualization of query-frame similarity scores, validating open-vocabulary retrieval capabilities and segmentation consistency.
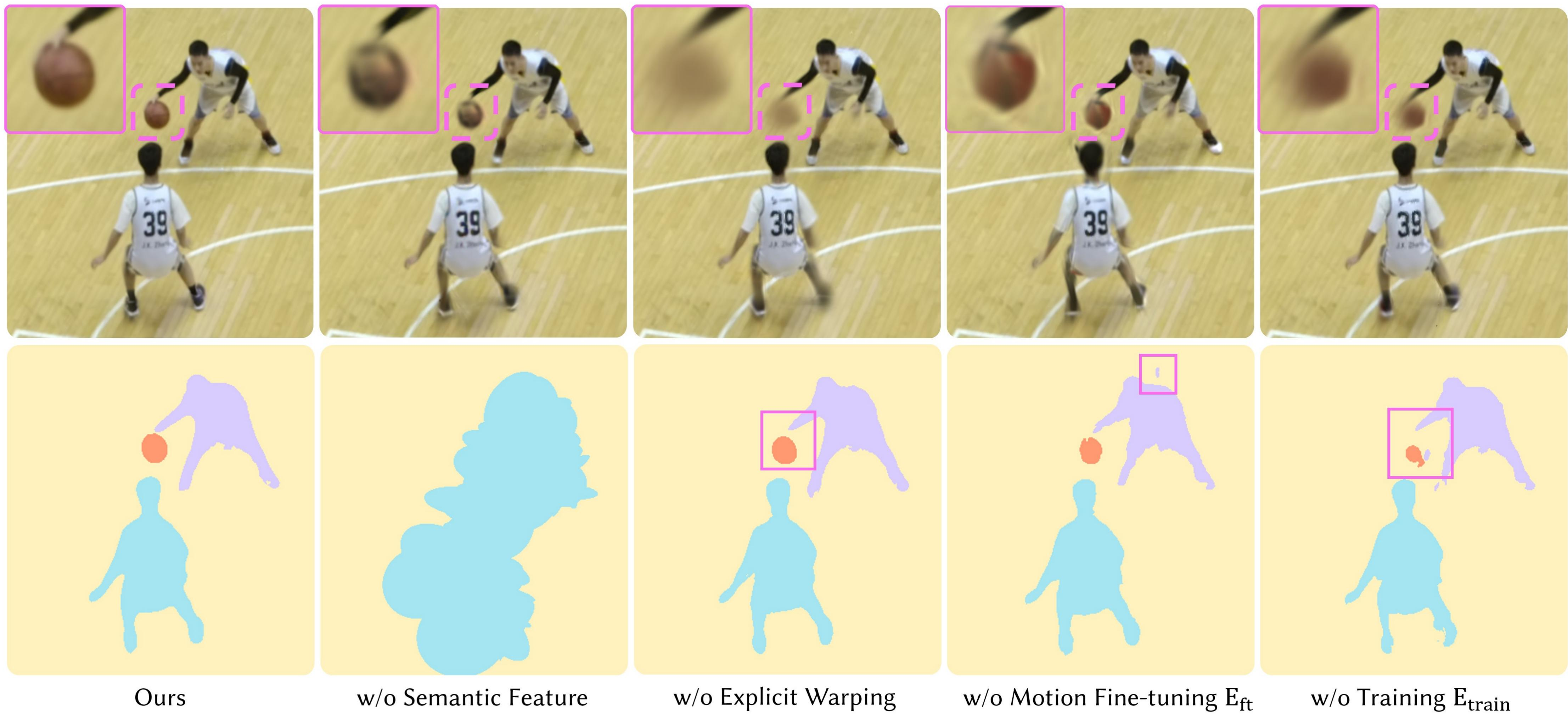
Figure 6: Qualitative ablation study illustrating artifact introduction when semantic, warping, or regularization terms are omitted.
Limitations
Despite its strong empirical results, Director presents several constraints: (1) the dynamic optimization procedure remains computationally expensive, constraining deployment in real-time or very long sequences; (2) success depends on balanced hyperparameter selection and tuning per scene; (3) the necessity to encode semantics into compact latent vectors to accommodate current training regimes reduces representational expressivity for highly granular language queries.
Implications and Future Directions
Director offers a new paradigm in tightly coupled 4D dynamic reconstruction and semantics, providing a foundation for interactive, language-driven scene editing, performance analysis, and multimodal virtual/augmented reality. The continuous integration of foundation models in vision and language, combined with efficient Gaussian optimization, points toward more generalizable and data-efficient scene representations. Future research may focus on end-to-end differentiable pipelines for mask/caption prediction, scalable Gaussian management, and richer high-dimensional semantic embeddings to further close the gap between scene understanding, interaction, and neural rendering.
Conclusion
Director demonstrates that instance-aware, tightly coupled semantic and geometric modeling at the Gaussian primitive level yields substantial improvements in temporally coherent dynamic scene modeling, instance segmentation, and open-vocabulary querying. Its architecture and training strategy provide a strong baseline and extensible foundation for unified, interpretable 4D scene understanding in complex real-world applications.
