Motion4D: Learning 3D-Consistent Motion and Semantics for 4D Scene Understanding
Abstract: Recent advancements in foundation models for 2D vision have substantially improved the analysis of dynamic scenes from monocular videos. However, despite their strong generalization capabilities, these models often lack 3D consistency, a fundamental requirement for understanding scene geometry and motion, thereby causing severe spatial misalignment and temporal flickering in complex 3D environments. In this paper, we present Motion4D, a novel framework that addresses these challenges by integrating 2D priors from foundation models into a unified 4D Gaussian Splatting representation. Our method features a two-part iterative optimization framework: 1) Sequential optimization, which updates motion and semantic fields in consecutive stages to maintain local consistency, and 2) Global optimization, which jointly refines all attributes for long-term coherence. To enhance motion accuracy, we introduce a 3D confidence map that dynamically adjusts the motion priors, and an adaptive resampling process that inserts new Gaussians into under-represented regions based on per-pixel RGB and semantic errors. Furthermore, we enhance semantic coherence through an iterative refinement process that resolves semantic inconsistencies by alternately optimizing the semantic fields and updating prompts of SAM2. Extensive evaluations demonstrate that our Motion4D significantly outperforms both 2D foundation models and existing 3D-based approaches across diverse scene understanding tasks, including point-based tracking, video object segmentation, and novel view synthesis. Our code is available at https://hrzhou2.github.io/motion4d-web/.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine trying to understand a busy scene in a video: people move, the camera moves, and objects get covered and uncovered. Many powerful AI tools can analyze each frame (single images) very well, but when you play the video, their results often “flicker” or don’t line up in 3D space. This paper introduces Motion4D, a method that turns a normal video into a consistent 3D-and-time model (that’s “4D”), so objects stay stable and correctly labeled as they move. It combines the strengths of popular 2D AI tools with a 3D model that keeps everything consistent across space and time.
What questions the researchers wanted to answer
- Can we fix the “flickering” and misalignment problems that 2D models have when they analyze videos frame by frame?
- Is there a way to merge 2D predictions (like object masks, point tracks, and depth) into a single 3D model that stays consistent as things move over time?
- Will this make tasks like tracking points, segmenting objects in videos, and showing the scene from new camera angles work better?
How Motion4D works (with easy analogies)
First, a quick idea of the tools involved:
- 2D models (like SAM2 for segmentation, point trackers, and depth estimators) are great at single frames but don’t always agree over time.
- A 3D scene made of tiny “blobs” called Gaussians is used to represent the world. Think of painting a scene using lots of small, soft, see-through balls that carry color and label information. If you move the camera, you can re-render what the scene looks like. If the balls move over time, you can model motion too.
Here’s the approach, step by step:
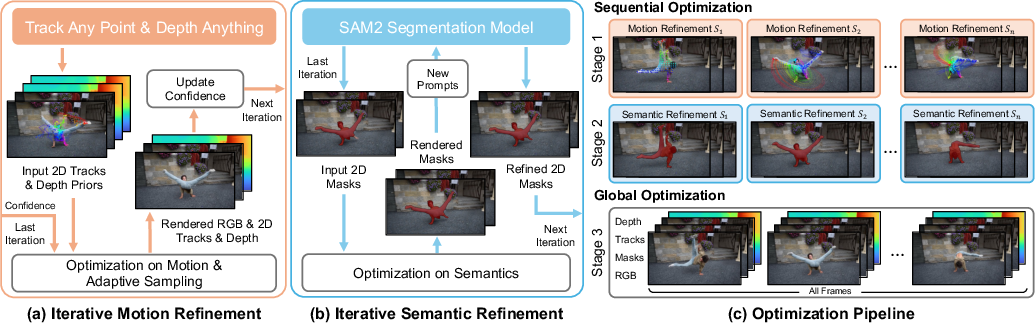
- The scene representation:
- The method uses “3D Gaussian Splatting,” which means representing the scene as many small 3D blobs that store color, opacity, and a semantic label (what object they belong to).
- Over time (the 4th dimension), these blobs can move. Motion4D learns how they move using a set of motion “bases,” like a few standard ways things can shift or rotate, and then mixes them to describe complex motion.
- Bringing in 2D predictions (and fixing them):
- The system starts with 2D predictions: object masks (from SAM2), point tracks (from trackers like TAPIR/CoTracker), and depth (from Depth Anything).
- But it doesn’t just trust them blindly. It learns a “confidence map” (think of it as a trust meter) that down-weights bad 2D hints when they don’t match what the 3D model sees over time (for example, when colors or labels disagree between frames).
- It also uses “adaptive resampling”: if the model notices parts of the scene aren’t represented well (high error in color or mask), it adds more Gaussians there—like adding extra brush strokes where the picture looks blurry.
- Iterative improvements in two phases:
- Sequential optimization (short chunks of the video):
- Stage 1: Improve motion. The model adjusts how Gaussians move using the trusted parts of the 2D tracks and depth, fixing short-term errors.
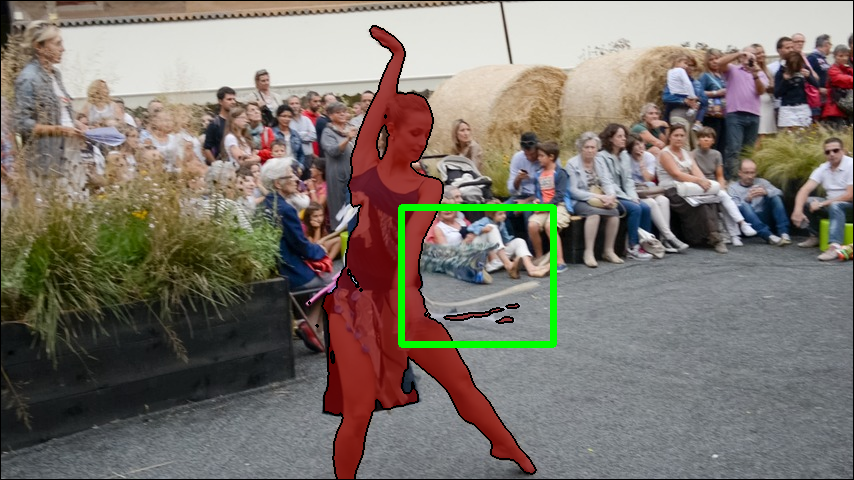
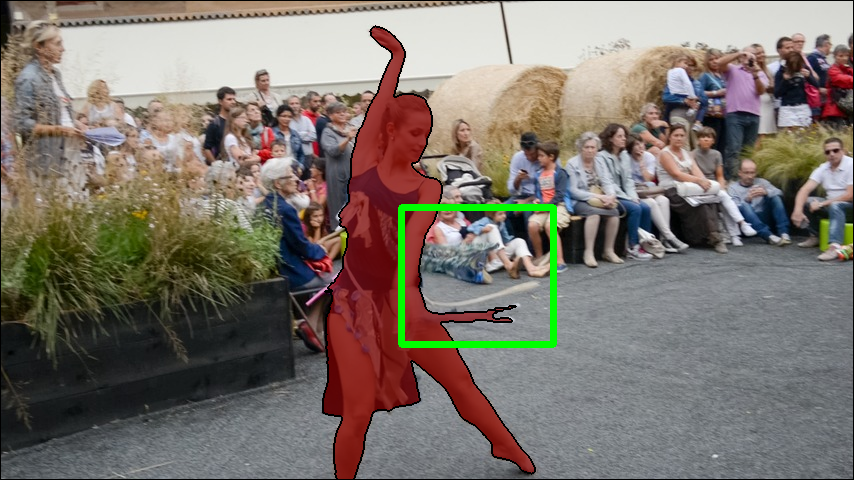
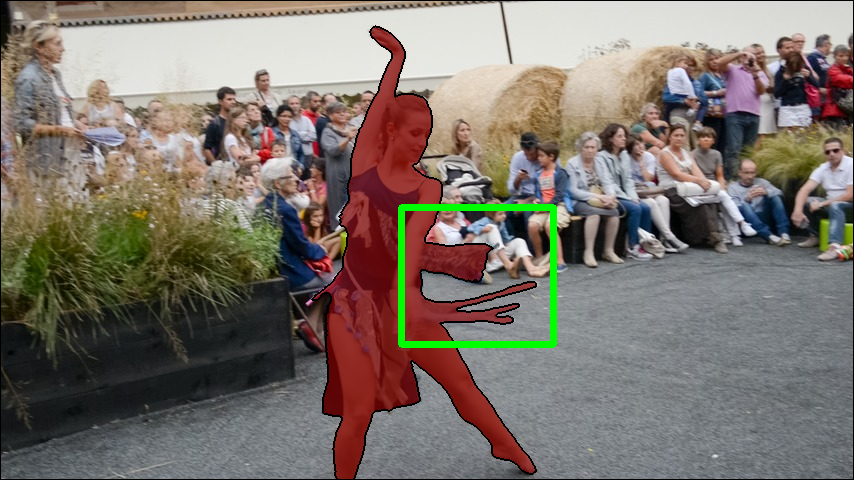
- Stage 2: Improve semantics (labels). It renders 3D masks from the current model and uses those to prompt SAM2 (with bounding boxes and a few points) to correct the 2D masks. This keeps masks consistent with the 3D structure while preserving fine edges.
- Global optimization (the whole video):
- After refining chunks, it trains everything together across the entire sequence so the whole 4D model is coherent in the long run.
In short: Motion4D combines 2D “hints” with a 3D “stage,” learns when to trust and when to correct, and keeps refining both the motion and the object labels so the scene stays consistent over time.
What the researchers found (and why it matters)
- Better video object segmentation:
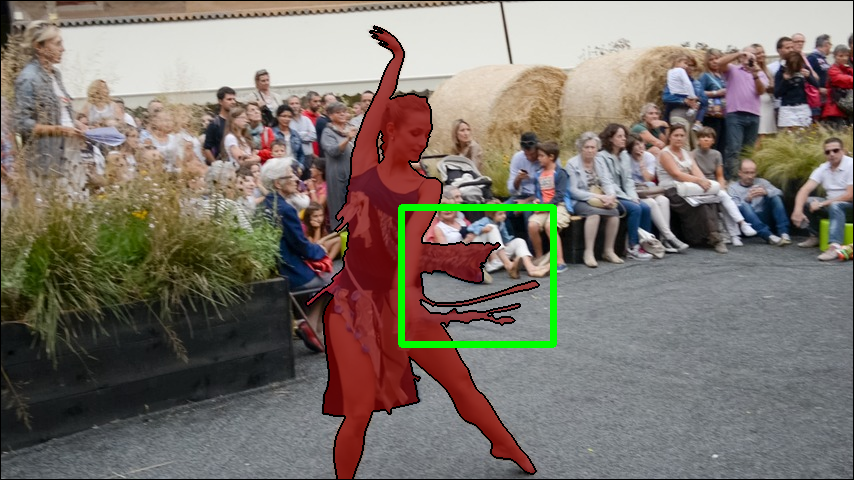
- On their new benchmark (DyCheck-VOS) and on the popular DAVIS benchmark, Motion4D produced more stable, accurate object masks than strong 2D models (like SAM2/DEVA) and prior 3D methods. That means less flicker and better alignment over time, especially when objects move fast or get occluded.
- Stronger 2D point tracking:
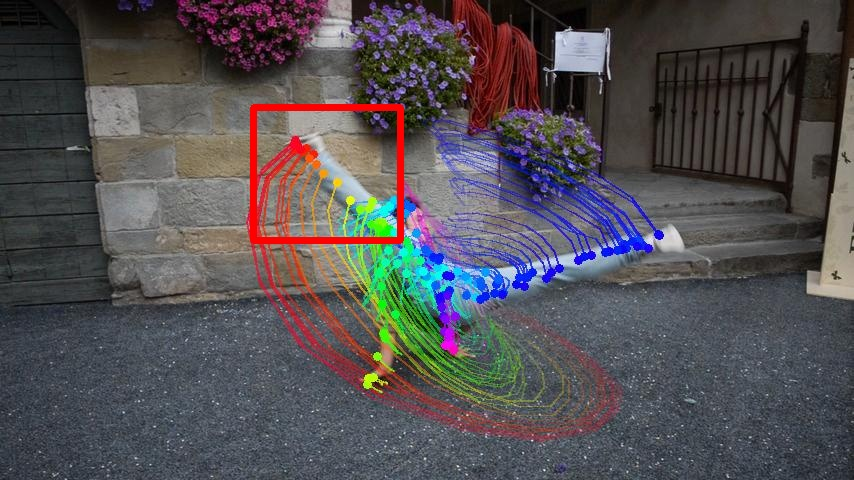
- It tracked points more reliably than top 2D trackers in tough cases (fast motion, occlusions) by anchoring them to the 3D model. Tracks were less likely to drift or break.
- Better 3D tracking and novel view synthesis:
- It more accurately followed points in 3D space over time and produced clearer, more faithful new views of the scene (seeing it from angles that weren’t in the original video).
Why this is important: A consistent 4D understanding is key for robotics (navigating dynamic places), AR/VR (placing virtual objects that stay put), video editing (stable masks for effects), and more. Motion4D shows a practical way to blend powerful 2D “foundation model” predictions with a 3D representation to get consistent results.
A few key ideas in plain words
- 3D Gaussian Splatting: Representing the scene with lots of soft 3D blobs that can be rendered from any camera view.
- 4D scene: 3D space plus time—how things change as the video plays.
- Confidence map: A learned “trust score” that tells the system when to believe 2D inputs and when to be cautious.
- Adaptive resampling: Adding more blobs where the model is making mistakes, so those regions get more detail and accuracy.
- Iterative semantic refinement: Using the current 3D understanding to prompt and improve the 2D masks, then using those better masks to further improve the 3D model—like a feedback loop.
Impact and future possibilities
Motion4D suggests a powerful recipe: use big 2D models to get initial clues, but keep everything consistent by building and refining a 3D+time model. This can make video understanding more robust for real-world uses—self-driving cars, AR apps, sports analysis, and film post-production. The authors also release DyCheck-VOS, a new test set focused on real, moving scenes, which can help others benchmark future methods.
A limitation noted by the authors: if the initial 3D reconstruction is very hard (e.g., lots of occlusions or low texture), performance can still drop. Future work could improve robustness in those hard cases.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps and open questions that remain after this paper. Each item highlights a specific uncertainty, missing analysis, or limitation that future work could directly address.
- Dependence on accurate camera poses: The method assumes posed monocular videos; robustness to erroneous or missing COLMAP poses in dynamic scenes (where SfM often fails) is not evaluated or addressed.
- Monocular depth scale ambiguity: The pipeline leverages Depth Anything without detailing metric scale alignment; the impact of scale drift or bias on 3D tracking and motion estimation remains unquantified.
- Rigid motion bases for non-rigid dynamics: Motion is modeled via weighted SE(3) bases; how well this captures articulated, highly non-rigid, or topological changes (cloth, fluids, splashes) is not analyzed.
- Number and learning of motion bases: The selection, initialization, and impact of the number of motion bases B and the assignment of per-Gaussian coefficients w_ib are not ablated; criteria for motion grouping and preventing cross-object coupling are unclear.
- Confidence weighting via heuristic consistency checks: The 3D confidence map is supervised with a pseudo-label based on RGB/semantic consistency thresholds (δ, δ′); sensitivity to these thresholds and failure cases when semantics or color are inconsistent are not studied.
- Circular dependency between semantics and confidence: Since w(p) is learned using semantic predictions that are themselves being refined, the risk of reinforcing erroneous semantics is not quantified; no safeguards or alternative supervision sources are explored.
- Adaptive resampling bias: Error-based densification may prioritize textured regions and neglect low-texture areas; its behavior under motion blur, specularities, transparency, and thin structures is untested.
- Depth error propagation in resampling: The resampling stage projects 2D points into 3D using rendered depth; the effect of inaccurate depth on initializing new Gaussians and compounding motion errors is not analyzed.
- Sequential optimization design choices: The chunk length L, windowing strategy, and scheduling (how often to alternate motion vs. semantics) are not ablated; the risk of locking in early motion errors when semantics are learned with fixed motion is unaddressed.
- Global vs. sequential optimization trade-offs: While both are shown to help, there is no systematic study on convergence behavior, stability, or when global joint optimization might overfit or degrade local consistency.
- Computational and memory footprint: Training/inference time, GPU memory usage, scalability to very long sequences, and the impact of densification on N (number of Gaussians) are not reported.
- Boundary fidelity limitations: Authors note rendered masks have coarser boundaries due to reconstruction quality; methods to improve high-frequency detail (e.g., supersampling, boundary-aware splatting) are not explored.
- Semantic field scope: The semantic field renders masks but does not support category labels or language grounding; integration with text prompts (e.g., CLIP/LMMs) and multi-class semantics is not investigated.
- Reliance on SAM2: The approach’s dependence on SAM2 prompts raises questions about generality; how results change with other segmentation backbones or weaker priors is not tested.
- Prompt generation strategy: The choice and number of prompt points m, bounding box tightness, and distance transform heuristics are not ablated; robustness for small objects, heavy occlusion, and clutter is unknown.
- Identity maintenance and multi-object occlusions: Long-term instance association, identity switches, and occlusions across multiple overlapping objects are not explicitly modeled or evaluated.
- Robustness to real-world artifacts: Effects of rolling shutter, motion blur, lighting changes, sensor noise, and exposure variations on motion/semantic consistency are not measured.
- Evaluation breadth: Comparisons omit several recent dynamic 3D representations (e.g., K-Planes/HexPlane variants) and stronger 2D segmentation backbones; fairness and representativeness of baselines could be improved.
- 3D tracking ground truth and scale alignment: Ground-truth 3D trajectories are created via LiDAR depth, but alignment between monocular depth priors and LiDAR scale is not described; potential biases in EPE and δ_3D metrics remain.
- Hyperparameter sensitivity: Loss weights (λ_rgb, λ_sem, λ_track, λ_depth, λ_w), thresholds (δ, δ′, θ_rgb, θ_sem), and optimizer settings are not systematically ablated; guidance for stable training is lacking.
- Topology changes and scene dynamics: The framework does not discuss handling object creation/destruction, splitting/merging, or large deformations where Gaussian identity or motion bases might break down.
- Failure mode analysis: Beyond a brief note (occlusions, low-texture, inaccurate depth), comprehensive qualitative/quantitative failure analysis and mitigation strategies are not provided.
- DyCheck-VOS dataset coverage: The benchmark uses partial-object masks in 14 sequences; potential annotation bias, generalization to full-object/instance segmentation, and plans for scaling diversity and categories remain open.
- Reproducibility details: Exact training schedules, SAM2 prompting parameters, window sizes, motion base counts, and code/runtime configurations needed for faithful reproduction are not fully specified.
- Online/real-time applicability: The framework is offline and optimization-heavy; feasibility for real-time 4D understanding or on-device deployment is unexplored.
- Multi-sensor/multi-view extension: The method targets monocular videos; how to integrate stereo, multi-view, IMU, or depth sensors to improve consistency is not studied.
- Unsupervised motion grouping: Automatic discovery of motion components and segmentation purely from 3D dynamics (without 2D semantic priors) is not addressed.
- Theoretical guarantees: Convergence properties of the alternating refinement (2D priors ↔ 3D fields) and conditions under which global coherence is guaranteed are not established.
Practical Applications
Below are practical, real-world applications of Motion4D derived from its findings, methods, and innovations. Each application is labeled by sector, includes potential tools/products/workflows, and notes assumptions or dependencies that affect feasibility.
Immediate Applications
These can be piloted or deployed now with the released code and commonly available 2D foundation models (SAM2, Depth Anything, TAPIR/CoTracker) and standard SfM (e.g., COLMAP).
- 3D-consistent roto and point tracking for film/VFX and post-production (Media & Entertainment)
- What it enables: Flicker-free, spatially aligned masks and long-term point tracks for dynamic scenes; improved matte quality and motion graphics.
- Tools/Products/Workflows: Nuke/After Effects plugin or pipeline step (“Motion4D Roto”) that ingests monocular footage, estimates camera poses (COLMAP), applies SAM2 masks + CoTracker/TAPIR + Depth Anything, optimizes Motion4D, and exports stabilized masks/tracks; integrates with compositing and matchmove.
- Assumptions/Dependencies: Requires reliable pose estimation/parallax and textured scenes; GPU resources for optimization; segmentation and tracking priors must be reasonably accurate.
- AR occlusion and stable overlays in mobile apps (Software/AR)
- What it enables: 3D-consistent foreground/background separation and occlusion handling for dynamic scenes, reducing jitter and misalignment in AR filters and stickers.
- Tools/Products/Workflows: SDK component (“Motion4D-AR Occlusion”) that generates temporally coherent masks and depth from casual video; used for precompute or near-real-time on high-end devices.
- Assumptions/Dependencies: Latency and compute constraints; reliance on monocular depth and accurate camera intrinsics; works best when sequential optimization can run on short clips.
- Robotics perception upgrade for dynamic environments (Robotics)
- What it enables: Occlusion-aware, 3D-consistent segmentation and point tracking; more reliable perception during manipulation, navigation, and human–robot interaction.
- Tools/Products/Workflows: ROS node (“motion4d_node”) that fuses SAM2 masks and TAPIR tracks with 3DGS motion fields to produce consistent 4D scene understanding; downstream planners consume stable object masks/trajectories.
- Assumptions/Dependencies: Requires camera calibration and stable pose estimation; real-time deployment needs model compression or partial precomputation.
- Video analytics with reduced false positives under occlusion (Security/Smart Cities/Retail)
- What it enables: More reliable object detection/segmentation under crowding and motion; improved re-identification and trajectory consistency in monocular CCTV.
- Tools/Products/Workflows: Analytics pipeline component that replaces frame-wise segmentation/tracking with Motion4D-refined outputs; exports robust masks/tracks for event detection, counting, dwell-time.
- Assumptions/Dependencies: Compute/GPU availability; scene texture and lighting quality; privacy constraints on processing and storage.
- Sports broadcast analytics and free-viewpoint enhancements (Media/SportsTech)
- What it enables: Stable player/ball segmentation and long-term tracking from broadcast monocular feeds; improved highlight generation and tactical analysis; higher-quality view synthesis for dynamic replays.
- Tools/Products/Workflows: “Motion4D Sports” service that processes clips to produce consistent tracks/masks and dynamic 4D representations; integrates with analytics dashboards or replay engines.
- Assumptions/Dependencies: Fast camera motion and crowding may challenge COLMAP and depth; multi-view remains superior, but Motion4D improves monocular pipelines.
- Industrial inspection of moving machinery (Manufacturing/Energy)
- What it enables: Robust tracking/segmentation of rotating or translating components (e.g., conveyor parts, wind turbine blades) for anomaly detection and maintenance scheduling.
- Tools/Products/Workflows: Edge/centralized processing that yields 3D-consistent motion trajectories; alarms based on deviations; visual QC with cohesive masks.
- Assumptions/Dependencies: Adequate texture and camera coverage; safety-critical deployment requires extensive validation.
- Data annotation acceleration and quality assurance (Academia/ML Ops)
- What it enables: Automatically produces temporally coherent masks and tracks to pre-label datasets; reduces annotator burden and corrects flicker/misalignment.
- Tools/Products/Workflows: “Motion4D Prelabeler” integrated with annotation tools; uses iterative semantic refinement to improve 2D priors; outputs masks/tracks with confidence metrics.
- Assumptions/Dependencies: Requires inspectors to review edge cases; foundation model biases may persist without curation.
- Benchmarking and research baselines for dynamic scene understanding (Academia/Research)
- What it enables: DyCheck-VOS serves as a realistic benchmark; Motion4D provides a strong baseline across VOS, 2D/3D tracking, and novel view synthesis.
- Tools/Products/Workflows: Experimental pipelines using Motion4D as a backbone for new loss functions, priors, or representations; fair comparisons across tasks.
- Assumptions/Dependencies: Community adoption of DyCheck-VOS; reproducible training with open-source code.
- Consumer video editing: object removal and background replacement (Consumer Software)
- What it enables: Stable masks for dynamic subjects, enabling cleaner object removal, background swaps, and cinematic effects without multi-view rigs.
- Tools/Products/Workflows: Mobile/desktop app feature (“Motion4D Clean Cut”) that precomputes 4D-consistent masks/tracks for selected clips.
- Assumptions/Dependencies: Usability depends on compute budget and clip length; artifacts may occur in low-texture or extreme occlusions.
Long-Term Applications
These require further research, scaling, real-time optimization, multi-sensor integration, or regulatory/operational validation.
- Monocular 4D perception in autonomous driving (Automotive/Autonomy)
- What it enables: Cost-effective dynamic scene understanding from single cameras; robust segmentation/tracking under occlusions; motion-aware depth for prediction.
- Tools/Products/Workflows: Perception stack module that fuses Motion4D with radar/LiDAR (when available); downstream behavior prediction and planning.
- Assumptions/Dependencies: Safety-critical constraints; domain shift and weather; large-scale validation and real-time execution (hardware acceleration).
- Computer-assisted surgery and instrument tracking (Healthcare/MedTech)
- What it enables: 3D-consistent segmentation/tracking of instruments and tissue dynamics in endoscopy or OR video; improved hand–eye coordination aids.
- Tools/Products/Workflows: Surgical vision system integrating Motion4D for occlusion-aware tracking; training simulators using dynamic 4D reconstructions.
- Assumptions/Dependencies: Regulatory approval; domain-specific datasets; handling specularities/low texture; strict latency and reliability requirements.
- City- or factory-scale dynamic digital twins (Smart Cities/Industrial IoT)
- What it enables: Cohesive 4D reconstructions of operational environments from monocular streams (drones, CCTV); simulation and optimization of flows and interactions.
- Tools/Products/Workflows: Platforms that aggregate Motion4D outputs into multi-scene dynamic twins; anomaly detection, optimization, and forecasting.
- Assumptions/Dependencies: Scalable compute; multi-camera fusion; data governance and privacy; robustness over long durations.
- Volumetric free-viewpoint video capture from consumer devices (Media/Consumer XR)
- What it enables: Near-volumetric capture of dynamic performances from single handheld video; interactive replays and novel viewpoints without multi-camera rigs.
- Tools/Products/Workflows: “Motion4D Capture” app that guides users to record with sufficient parallax, runs sequential/global optimization, and exports 4DGS-based assets for XR playback.
- Assumptions/Dependencies: Quality depends on scene texture, parallax, and lighting; storage and runtime constraints; on-device acceleration or cloud processing.
- Real-time 4D Gaussian Splatting for AR/robotics at the edge (Software/Robotics)
- What it enables: On-device dynamic reconstruction and consistent semantics/motion; interactive occlusion handling and tracking for agents.
- Tools/Products/Workflows: Optimized Motion4D variants with model compression, streaming optimization, and incremental updates; hardware-specific kernels.
- Assumptions/Dependencies: Significant engineering for latency, memory, and energy; adaptive resampling and confidence maps must be efficient online.
- Policy and standards for privacy-preserving dynamic video analytics (Policy/Standards)
- What it enables: Governance structures for deploying 4D scene understanding in public spaces; standardized benchmarks (e.g., DyCheck-VOS extensions) and reporting of biases/uncertainties.
- Tools/Products/Workflows: Compliance toolkits that surface uncertainty (3D confidence maps) and anonymization strategies; auditing protocols for segmentation and tracking consistency.
- Assumptions/Dependencies: Multi-stakeholder alignment; transparent model documentation; datasets reflecting diverse conditions and populations.
- Foundation models for 4D semantics and motion (Academia/AI Research)
- What it enables: Pretraining paradigms that natively integrate semantics, geometry, and dynamics; end-to-end models reducing reliance on separate 2D priors.
- Tools/Products/Workflows: Large-scale training pipelines leveraging Motion4D’s iterative refinement and sequential/global optimization as scaffolding; synthetic + real video corpora.
- Assumptions/Dependencies: Massive data/compute; open benchmarks and tooling; careful handling of failure modes (depth errors, occlusions, texture scarcity).
- Sector-specific analytics (Retail/Agriculture/Logistics/Energy)
- What it enables: 3D-consistent tracking for livestock monitoring, crop motion in wind, warehouse item flows, wind turbine blade dynamics; improved KPI accuracy and anomaly detection.
- Tools/Products/Workflows: Domain-tuned Motion4D variants with targeted prompts and priors; dashboards for trajectory and segmentation stability over time.
- Assumptions/Dependencies: Domain adaptation and calibration; multi-sensor fusion beneficial; variable environmental conditions (weather, lighting).
Notes on global feasibility assumptions common to multiple applications:
- Motion4D’s accuracy depends on: reliable camera pose estimation (e.g., COLMAP), reasonably accurate 2D priors (SAM2 masks, TAPIR/CoTracker tracks, Depth Anything), and scene texture/parallax.
- Compute and latency: current pipeline favors offline or near-real-time processing; true real-time edge deployment requires optimization.
- Failure modes: severe occlusions, low-texture regions, or poor depth priors degrade reconstruction and, consequently, masks/tracks; sequential optimization mitigates but does not eliminate these issues.
- Licensing and integration: usage of external foundation models (SAM2, Depth Anything) and SfM components must adhere to their licenses; productization needs robust engineering, testing, and monitoring.
Glossary
- 3D confidence map: A learned map over 3D space that modulates supervision strength to handle unreliable motion priors during optimization. Example: "we introduce a 3D confidence map that dynamically adjusts the motion priors"
- 3D Gaussian Splatting (3DGS): An explicit 3D scene representation using a set of Gaussian primitives for fast, differentiable rendering. Example: "We represent the scene using {3DGS}~\cite{kerbl20233d} and further extend it with motion and semantic fields to model dynamic 3D environments."
- 4D Gaussian Splatting: An extension of 3D Gaussian Splatting that additionally models temporal dynamics (time) for 4D scene understanding. Example: "integrating 2D priors from foundation models into a unified 4D Gaussian Splatting representation."
- Adaptive Density Control: A 3DGS mechanism that splits or merges Gaussians based on gradient magnitude to control spatial density during training. Example: "the Adaptive Density Control of 3DGS~\cite{kerbl20233d} relies heavily on gradient magnitude."
- Adaptive resampling: A strategy that inserts new Gaussians in regions with high reconstruction error to improve motion and appearance modeling. Example: "We further introduce an adaptive resampling module to improve motion consistency by inserting new Gaussians into underrepresented regions identified through per-pixel RGB and semantic errors."
- Average Jaccard (AJ): A metric for 2D point tracking measuring overlap accuracy averaged across frames. Example: "reporting the Average Jaccard (AJ), average position accuracy (), and Occlusion Accuracy (OA)."
- Binary cross entropy (BCE): A loss function for binary classification tasks, used here to supervise confidence weights. Example: "where is the binary cross entropy"
- Boundary F1-score: A metric evaluating the accuracy of predicted object boundaries in segmentation. Example: "boundary F1-score ()"
- Canonical frame: A reference coordinate frame in which static Gaussian parameters are defined before applying per-frame deformations. Example: "3DGS defines a set of static Gaussians in the canonical frame as "
- COLMAP: A structure-from-motion and multi-view stereo tool used to estimate camera poses. Example: "we use camera poses estimated by COLMAP~\cite{schonberger2016structure}"
- Deformation field: A motion field that applies rigid transformations to Gaussians across time to model dynamics. Example: "we define a deformation field (motion field) which adjusts positions and orientations at each frame via rigid transformations~\cite{wang2024shape}."
- Densification strategy: The process of increasing Gaussian count in underfit regions to improve reconstruction quality. Example: "We introduce a new 3DGS densification strategy to further enhance motion modeling through an adaptive resampling process."
- Distance transform: An image operation computing distances to the nearest boundary, used to place informative prompts. Example: "determined by the maximum value of the distance transform."
- DyCheck-VOS: A benchmark for video object segmentation in dynamic scenes derived from the DyCheck dataset. Example: "We introduce DyCheck-VOS, a new benchmark for evaluating video object segmentation in realistic and dynamic scenes with camera and object motion."
- End-point-error (EPE): The Euclidean distance between predicted and ground-truth 3D point positions, used for tracking evaluation. Example: "evaluate the tracking performance using the 3D end-point-error (EPE)"
- Jaccard index: An overlap metric between predicted and ground-truth masks (also known as IoU). Example: "Jaccard index ()"
- LPIPS: A learned perceptual image patch similarity metric for assessing visual fidelity. Example: "For novel view synthesis, we assess reconstruction quality using PSNR, SSIM, and LPIPS scores."
- Monocular Depth Estimation (MDE): Predicting depth from single images or videos without stereo/multi-view input. Example: "Another important topic is the Monocular Depth Estimation (MDE) from images and videos~\cite{ranftl2020towards,chen2016single,xian2018monocular}."
- Neural Radiance Fields (NeRFs): Implicit neural scene representations for photorealistic novel view synthesis. Example: "Neural Radiance Fields (NeRFs)~\cite{mildenhall2020nerf}"
- Novel view synthesis: Rendering images from unseen viewpoints using a learned scene representation. Example: "have achieved impressive results in novel view synthesis."
- Occlusion Accuracy (OA): A tracking metric measuring correctness of occlusion handling. Example: "reporting the Average Jaccard (AJ), average position accuracy (), and Occlusion Accuracy (OA)."
- PSNR: Peak Signal-to-Noise Ratio, an image quality metric for reconstruction fidelity. Example: "For novel view synthesis, we assess reconstruction quality using PSNR, SSIM, and LPIPS scores."
- Prompt points: Positive/negative point prompts provided to a segmentation model to guide mask refinement. Example: "we place positive or negative prompt points at the center of the most prominent regions"
- Promptable segmentation: Segmentation that can be controlled via prompts (points, boxes, masks) to produce desired outputs. Example: "the Segment Anything Model (SAM)~\cite{kirillov2023segment} was introduced as a promptable segmentation network trained on billions of masks"
- Rigid transformations: Transformations preserving distances (rotations and translations) applied to 3D Gaussians over time. Example: "which adjusts positions and orientations at each frame via rigid transformations~\cite{wang2024shape}."
- SA-V: A large-scale video segmentation dataset introduced with SAM2. Example: "and builds the largest video segmentation dataset (SA-V) to date."
- SAM (Segment Anything Model): A foundation model for promptable image segmentation trained on large-scale data. Example: "the Segment Anything Model (SAM)~\cite{kirillov2023segment} has revolutionized 2D visual understanding"
- SAM2: A video-capable successor to SAM with streaming memory for segmentation across frames. Example: "SAM2 serves as a foundation model for segmentation across images and videos"
- SE(3): The Lie group of 3D rigid body transformations (rotation and translation). Example: ""
- Sequential optimization: A training strategy that updates motion and semantics in consecutive stages over short temporal windows. Example: "Sequential optimization, which updates motion and semantic fields in consecutive stages to maintain local consistency"
- SO(3): The Lie group of 3D rotations. Example: ""
- Streaming memory mechanism: A design enabling video models to leverage temporal context efficiently. Example: "extends this paradigm to video by using a streaming memory mechanism"
- Temporal flickering: Instability of predictions across frames causing inconsistent appearance or masks. Example: "temporal flickering in complex 3D environments."
- Uncertainty field: A scalar per-Gaussian parameter whose 2D rendering yields pixel-wise confidence weights for losses. Example: "We then add a new uncertainty field to each Gaussian"
- Weighted combination: Combining motion bases with learned coefficients to obtain per-frame transformations. Example: "the per-frame transformation is obtained by a weighted combination as $\mathbf{T}_i^{0\rightarrow t} = \sum_{b=0}^B w_i^{b} \hat{\mathbf{T}_{b}^{0\rightarrow t}$."
- Zero-shot segmentation: Segmenting objects in new images without task-specific training on those images. Example: "enabling strong zero-shot segmentation performance on new images."
Collections
Sign up for free to add this paper to one or more collections.