- The paper introduces CogPic, a large-scale, multimodal dataset designed for early detection of cognitive impairment via picture description tasks.
- It outlines a meticulous methodology capturing audio, visual, and linguistic signals from 574 participants with expert clinical annotation.
- Multimodal fusion models demonstrated improved diagnostic accuracy over unimodal approaches, with interpretable insights from SHAP analysis.
CogPic: A Multimodal Benchmark for Early Cognitive Impairment Assessment
Motivation and Background
Early detection of Alzheimer's Disease (AD) and Mild Cognitive Impairment (MCI) is critical for timely intervention, yet conventional diagnostic modalities relying on neuropsychological batteries and neuroimaging are resource-intensive. While behavioral signals—especially those observed during naturalistic language tasks such as picture description—offer promising non-invasive digital biomarkers, progress in automated cognitive assessment is constrained by several limitations:
(1) Existing datasets provide only audio and transcript modalities, omitting critical facial and visual cues.
(2) Prevailing resources are limited in scale and annotation rigor, impeding the development and generalization of data-intensive multimodal architectures.
(3) A pronounced bias toward English-speaking cohorts limits clinical relevance for non-English populations.
The CogPic database is designed to overcome these bottlenecks by providing a large-scale, clinically pristine, and strictly multimodal dataset specifically tailored to the Chinese context. It emerges as a platform for systematic benchmarking of automated cognitive impairment detection and feature extraction pipelines.
Dataset Construction and Multimodal Acquisition
CogPic comprises synchronized audio, visual, and linguistic signals from 574 well-characterized participants, sampled to represent a diverse demographic spectrum. Data acquisition followed a rigorous protocol founded on strict exclusion criteria (neurological, psychiatric, and systemic comorbidities; cognitive-impacting medications; communication deficits). Standardized "picture description" tasks were administered in a tablet-mediated setting, capturing spontaneous, unprompted content for three distinct visual stimuli (“Cookie Theft”, “Picnic Scene”, and “Accident Scene”), with comprehensive consent and anonymization processes.
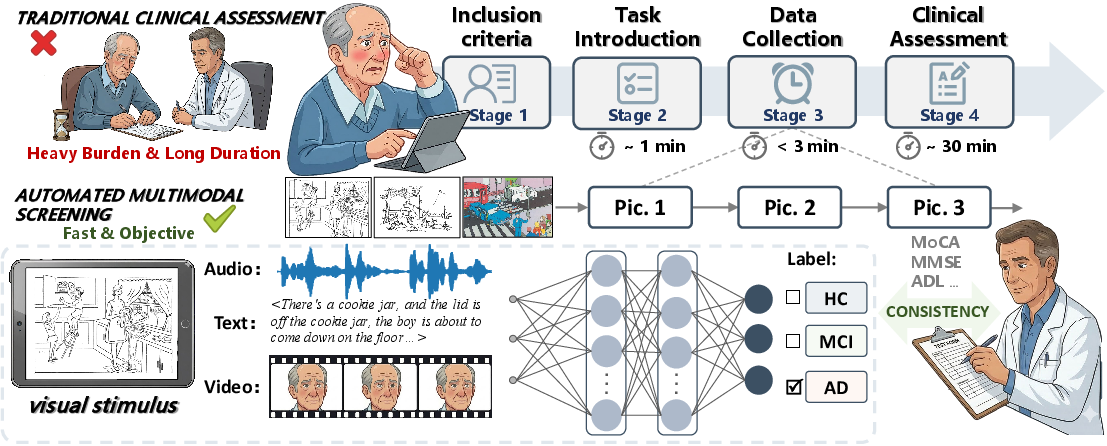
Figure 1: The overall pipeline of CogPic dataset construction, detailing subject recruitment, task protocol, synchronous multimodal acquisition, and expert diagnostic annotation.
Diagnostic ground truth was assigned by expert neuropsychologists, integrating detailed clinical evaluations, MMSE and MoCA scores, and functional status. Crucially, pathologic labels (HC, MCI, and AD) were allocated not by rigid quantitative cutoffs but by consensus, privileging clinical judgment over algorithmic thresholds.
Dataset Characteristics and Annotation
The CogPic cohort is stratified as follows: 178 healthy controls (HC), 256 MCI, and 140 AD subjects, with comprehensive meta-annotation for age, sex, education, and cognitive test scores. Multimodal data underwent uniform preprocessing (audio resampling to 16 kHz, speech-to-text transcription with <6% WER verified by manual audit, and frame-wise facial feature extraction using OpenFace after de-identification). Transcripts were normalized for disfluency and punctuation, and all data were strictly anonymized for public distribution.
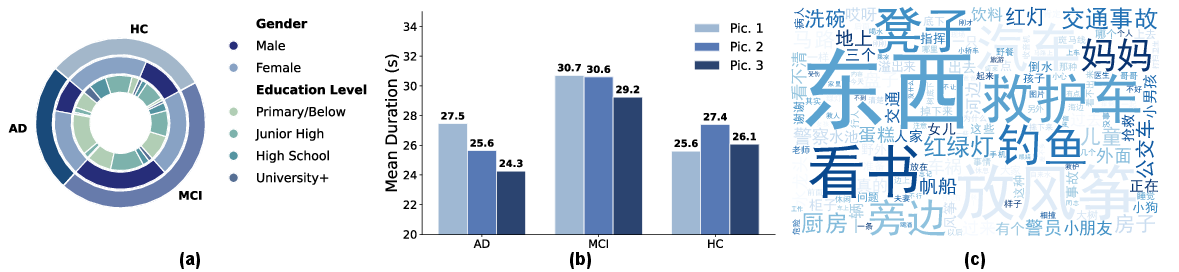
Figure 2: Dataset overview visualizing cohort demographics, mean response times by diagnostic group and task, and a linguistic word cloud highlighting high-frequency tokens.
The dataset captures salient behavioral differences: MCI participants demonstrate prolonged picture description times compared to both HC and AD, consistent with clinical observations of hesitancy and retrieval difficulty in this transition state.
Baseline Benchmarking and Model Analysis
CogPic establishes unimodal and multimodal baselines for cognitive state classification. Hand-engineered features (prosodic, facial, and linguistic) provide strong interpretability and were benchmarked using LR, SVM, and XGBoost. Deep learning backbones evaluated include LSTM/ResNet for audio, 3D-CNNs for video, and BERT/CNN/Attention-BiLSTM for text. Fusion strategies concatenated intermediate embeddings and applied MLP-based classification.
Unimodal results show SVM on handcrafted acoustic features yielding the highest UAR (60.38%) and AUC (76.06%), demonstrating the continued diagnostic value of expert-driven prosodic/pause biomarkers. Visual modality performance is optimized by MC3_18 (UAR 56.16%), with 3D-CNNs substantially outperforming classic ML on facial action units and head motion. The attention-based BiLSTM is optimal for text, outperforming transformer-based (BERT) architectures on balanced recall.
Multimodal fusion achieves substantial gains: the tri-modal (ResNetSE + MC3_18 + TextCNN) encoder yields UAR=62.16% and AUC=76.61%, confirming substantive cross-modal complementarity. Notably, fusion improvements are not always strictly additive—certain bipolar text-visual ensembles match or surpass more complex architectures, indicating some synergy ceilings and highlighting the necessity for advanced fusion strategies.
Ablation by image task demonstrates that visual stimulus selection impacts model sensitivity (Pic. 1: UAR=63.95%; Pic. 2: AUC=78.28%), supporting future investigation of task-tailored diagnostic paradigms.
Feature Attribution and Interpretability
To dissect model decision-making, SHAP global attribution analysis was performed for the optimal XGBoost classifier. The top 20 predictive features span all modalities: acoustic (MFCC statistics, shimmer), visual (mean head rotation), and linguistic (noun and adjective counts) markers dominate. This evidences that CogPic successfully supports the discovery of interpretable, modality-diverse digital biomarkers for AD and MCI.
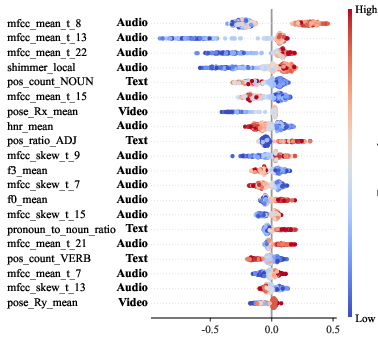
Figure 3: Beeswarm plot of SHAP global feature importance, highlighting the distribution and effect of the top 20 cross-modal handcrafted features in AD group prediction.
Implications, Limitations, and Future Directions
CogPic is unequivocally the largest, most modality-complete, and clinically validated open dataset for picture-description-based cognitive assessment in the Chinese language to date. Its empirical benchmarks set a new standard for early dementia detection, showing that multimodal fusion confers significant incremental gains over traditional unimodal methods; its design facilitates research in robust feature extraction, advanced fusion and alignment, and explainable AI.
Practically, CogPic enables the development and clinical translation of automated, non-contact screening tools, potentially alleviating healthcare system burden in routine cognitive surveillance. Theoretically, it permits detailed study of the multimodal interplay between neurodegenerative symptomatology and spontaneous behavioral signals across diverse tasks and populations.
An important limitation is that fusion efficacy may plateau due to inter-stream redundancy or noise; future research is needed on cross-modal gating, attention-based fusion, and longitudinal tracking. The inclusion of standardized, public cross-linguistic cohorts would further enhance model robustness and global translational relevance.
Conclusion
CogPic advances the field by providing a rigorously annotated, large-scale, multimodal dataset supporting systematic benchmarking for early cognitive impairment detection. Multimodal fusion models trained on CogPic achieve substantially higher diagnostic robustness over unimodal baselines, and SHAP analysis confirms that key acoustic, visual, and linguistic biomarkers are captured. By establishing this resource, the work enables both translational clinical research and foundational development of advanced AI-based cognitive diagnostic systems for diverse populations.