- The paper introduces the first multimodal dataset specifically designed to model the interplay between emotion and cognition in older adults.
- It employs rigorous protocols using synchronized video, EEG, and ECG recordings, coupled with validated emotion induction techniques.
- Empirical results highlight significant inter-subject variability and the challenges of feature-level fusion, underlining the need for advanced, personalized modeling approaches.
MECO: A Multimodal Dataset for Emotion and Cognitive Understanding in Older Adults
Introduction
The MECO dataset addresses a longstanding deficit in affective computing by providing the first multimodal corpus explicitly designed for modeling the interplay of emotion and cognitive states in older adults, particularly those experiencing mild cognitive impairment (MCI). Existing benchmarks overwhelmingly feature young, cognitively healthy adults, neglecting the distinct affective and physiological patterns arising from aging and cognitive decline. These limitations significantly undermine the accuracy and generalizability of automated emotion recognition (ER) and cognitive assessment tools designed for geriatric populations. MECO bridges this critical gap by capturing synchronized behavioral and physiological data, coupled with rigorous cognitive and emotional annotations, thus facilitating robust, ecologically valid research on affect and cognition in aging.
Dataset Design and Data Acquisition
MECO comprises approximately 38 hours of multimodal recordings from 42 participants (aged 57–85, mean 74.1), stratified into healthy controls (HC, n=27) and MCI individuals (n=15), resulting in 30,592 synchronized samples. Acquisition occurred in community settings using standardized, ecologically valid emotion elicitation protocols. Stimuli were drawn from an emotion-inducing video set, specifically validated for older Chinese adults, encompassing six discrete emotional categories (anger, boredom, happiness, neutral, sadness, tension) with cultural and age-specific relevance.
The protocol (Figure 1) initiated with Mini-Mental State Examination (MMSE) cognitive assessment, followed by three emotion induction sessions (each ≥24 hours apart to minimize fatigue/carryover effects). In each session, participants underwent emotion induction via targeted video stimuli, with synchronous recording of:
- Video: High-definition facial video at 30 fps
- Audio
- Electroencephalography (EEG): Fp1, Fp2, 250 Hz
- Electrocardiography (ECG): Single-channel, 250 Hz
Subsequent to each stimulus, participants provided instantaneous self-assessments of emotional states (six discrete emotions plus 9-point Likert scales for valence and arousal).
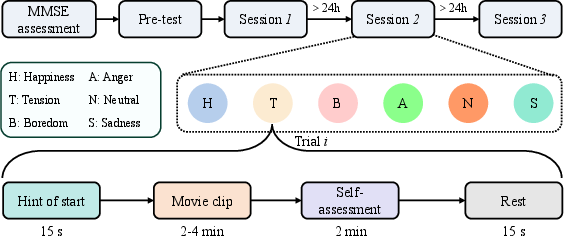
Figure 1: Overview of the experimental protocol: emotion induction via video, synchronized behavioral/physiological acquisition, self-annotation, and cognition assessment.
Annotation Strategy, Class Distributions, and Reliability
Cognitive status was binarized (HC: MMSE > 26; MCI: MMSE ≤ 26), paralleling contemporary clinical screening standards. The hybrid categorical-dimensional emotion annotation protocol captured both discrete emotion and valence-arousal ratings. Inter-annotator reliability was robust, with aggregate ICC(2, k) values of 0.9855–0.9901 for valence and 0.8962–0.9691 for arousal, supporting the quality of consensus ground truth.
Data distributions displayed realistic emotion imbalances: negative emotions dominated both global (Figure 2a–c) and subject-level (Figure 2d–e) statistics. Valence-arousal plots evidenced clustering in negative affective states, consistent with externalizing trends observed in older populations. High inter-subject variability (Figure 2d–e) is evident, underscoring the difficulty of generalizing models in this domain.
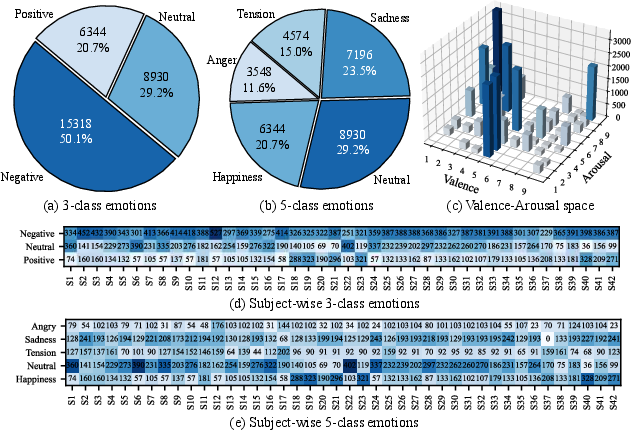
Figure 2: (a-b) Global emotion class distribution (3- and 5-class), (c) valence-arousal scatter, (d-e) individual subject-level emotion distributions under two categorization schemes.
Feature Engineering and Baseline Modeling
Preprocessing entailed temporal alignment and denoising. For video, OpenFace extracted 35 AUs, head pose (6 DOF), and gaze features, as well as 512-D deep facial embeddings. EEG features included differential entropy and PSD across five bands, along with non-linear dynamical features (HFD, SE). ECG analysis prioritized HRV-derived time-domain statistics, HFD, and SE.
All features were temporally segmented into 4-second non-overlapping windows to ensure multimodal alignment. Multimodal features were concatenated and fed into a gated recurrent unit (GRU) followed by a multilayer perceptron (MLP), with both subject-dependent (SD: temporal within-trial splits) and subject-independent (SI: five-fold subject-wise cross-validation) protocols defined. Evaluation metrics included UAR, WAR, CCC, MAE (for regression), and F1, ACC (for binary cognitive impairment detection).
Empirical Results
Emotion Recognition
Under the SD protocol, deep video features (DF) achieved peak unimodal UARs of 69.85% for 3-class sentiment analysis and 63.64% for 5-class ER, outperforming handcrafted appearance features. EEG/ECG unimodal performance was lower, but non-linear (HFD, SE) features outperformed time-domain/linear alternatives. Multimodal (video + EEG or ECG) fusion provided consistent, but modest, improvements over best unimodal baselines, with no significant gain for three-way fusion, indicating suboptimality of simple concatenation in the presence of inter-modality redundancy.
For the SI protocol, a marked decline in generalization emerged (UAR for video DF: 40.21%), attributable to large inter-individual variability in facial/physiological patterns. Multimodal fusion did not mitigate this drop, revealing that naïve feature-level fusion is insufficient for subject-invariant modeling in older adults.
Cognitive Status Prediction
Video features yielded strong baseline ACC (60.84%–63.71%) and F1 for binary MCI recognition, though ECG achieved marginally higher ACC, but at the cost of majority-class bias (lower F1). For MMSE regression, fusion (VC, VE) improved CCC and MAE over unimodal baselines, suggesting additive value from physiological modalities for continuous cognitive assessment. However, cross-subject generalization (SI) remained challenging, highlighting persistent limitations of fusion at feature-level granularity given the heterogeneity in aging biomarkers.
Implications and Future Perspectives
The MECO dataset constitutes an essential advance for geriatric affective computing, capturing multi-aspect affect–cognition interactions absent from prior benchmarks. Direct implications include:
- Robust Emotion–Cognition Modeling: MECO enables the design and evaluation of affect recognition systems tailored to aging and cognitively impaired cohorts, presenting realistic distributional and annotation challenges.
- Personalization: The pronounced inter-subject and intra-class variability underlines the necessity for approaches that support domain adaptation, context modeling, and hierarchical/information bottleneck-based multimodal fusion [Mai 2023, Tang 2024].
- Clinical Utility: MECO supports development of screening tools for early cognitive impairment via joint behavioral/physiological analysis, a priority in non-invasive dementia risk stratification.
- Algorithmic Innovation: Baseline fusion proved insufficient under SI protocols, motivating further research in cross-modal attention [Jiang 2022], transformers [Bertasius 2021], graph-based fusion [Li 2023], and meta-learning.
The absence of audio modality analysis and limited participant pool (N=42) are notable constraints. Extension to larger, more diverse samples and full exploitation of audio/linguistic cues will be critical next steps.
Conclusion
MECO advances the state of the art by providing a public, rigorously collected multimodal dataset for emotion and cognitive modeling in aging populations. Its rich behavioral and physiological modalities, coupled with high-quality affect–cognition annotations, facilitate research in robust ER, cognitively aware interfaces, and early MCI detection. Strong baseline results reveal both the promise of multimodal integration and the challenges of subject-invariant model generalization, underscoring urgent opportunities for innovation in personalized and cross-modal representation learning (2604.03050).

