VoxCog: Towards End-to-End Multilingual Cognitive Impairment Classification through Dialectal Knowledge
Abstract: In this work, we present a novel perspective on cognitive impairment classification from speech by integrating speech foundation models that explicitly recognize speech dialects. Our motivation is based on the observation that individuals with Alzheimer's Disease (AD) or mild cognitive impairment (MCI) often produce measurable speech characteristics, such as slower articulation rate and lengthened sounds, in a manner similar to dialectal phonetic variations seen in speech. Building on this idea, we introduce VoxCog, an end-to-end framework that uses pre-trained dialect models to detect AD or MCI without relying on additional modalities such as text or images. Through experiments on multiple multilingual datasets for AD and MCI detection, we demonstrate that model initialization with a dialect classifier on top of speech foundation models consistently improves the predictive performance of AD or MCI. Our trained models yield similar or often better performance compared to previous approaches that ensembled several computational methods using different signal modalities. Particularly, our end-to-end speech-based model achieves 87.5% and 85.9% accuracy on the ADReSS 2020 challenge and ADReSSo 2021 challenge test sets, outperforming existing solutions that use multimodal ensemble-based computation or LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “VoxCog: Towards End-to-End Multilingual Cognitive Impairment Classification through Dialectal Knowledge”
Overview
This paper is about using the sound of a person’s voice to help detect cognitive problems like Alzheimer’s disease (AD) and mild cognitive impairment (MCI). The authors built a system called VoxCog that listens to speech and decides whether someone might have cognitive impairment—without needing to turn the speech into text or use any other information like images.
What questions did the researchers ask?
The paper focuses on two simple questions:
- Can we accurately detect signs of cognitive decline using only raw speech audio, with a single, simple system (no extra steps like speech-to-text)?
- Will a system that already understands different accents and dialects of speech do better at spotting the voice changes linked to AD or MCI?
How did they do the study?
The researchers had a key idea: people with AD or MCI often speak more slowly, stretch sounds, or change their rhythm—somewhat like how people from different regions (dialects/accents) can sound different. If a model is good at hearing dialect differences, it might be good at picking up these subtle speech changes too.
Here’s the approach in everyday terms:
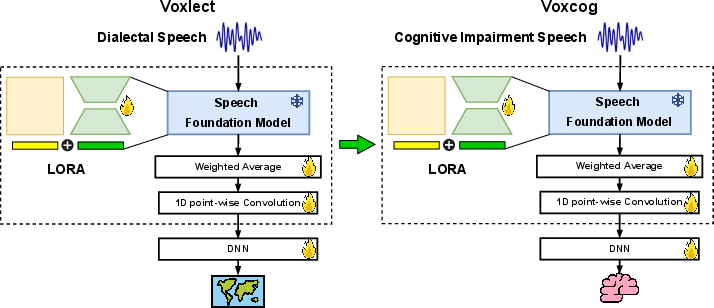
- The core idea: Start with a “speech expert” model that’s already trained to recognize dialects (regional accents) in English, Spanish, and Chinese. Think of it like a music teacher who can tell tiny differences in rhythm, pitch, and timing between performers. Then, teach this expert to notice patterns linked to cognitive decline.
- The model in simple terms: They used large pre-trained speech models (Whisper-Large and MMS-LID-256). Instead of retraining everything from scratch, they added small, efficient “tuning knobs” (a method called LoRA) to adapt the model to the new task. This makes training faster and requires less data.
- The data and tasks: People performed short speaking tasks, such as describing a picture, reading a short passage, or talking to a voice assistant. The datasets covered English, Spanish, and Chinese speakers.
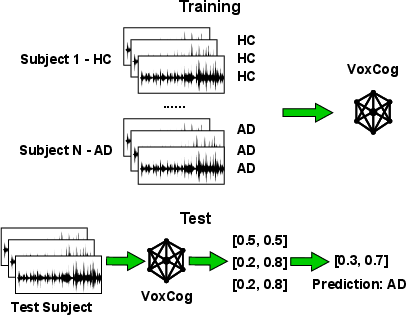
- How training and testing worked:
- Each recording was split into short 15-second clips, like cutting a movie into short scenes, to give the model manageable chunks to learn from.
- For each person, the model’s clip-level guesses were combined to make one final decision about that person.
- They compared the new dialect-aware system (VoxCog) against the same base models without the dialect training.
- They tested fairly using cross-validation (a standard way of making sure results are reliable) and reported standard scores like accuracy and Macro-F1.
Importantly, the whole system is “end-to-end,” meaning it listens to raw audio and directly makes a prediction. It does not rely on extra steps like automatic speech recognition (turning speech into text), which keeps things simpler and easier to reproduce.
What did they find?
VoxCog consistently beat the baseline models that didn’t include dialect knowledge, in both English and non-English datasets.
- Strong results on standard benchmarks:
- ADReSS 2020 challenge test set: 87.5% accuracy.
- ADReSSo 2021 challenge test set: 85.9% accuracy.
- Multilingual success: It improved scores for Spanish and Chinese datasets too, suggesting the idea works across languages.
- Simpler, yet competitive: Even though VoxCog uses only speech (no text or multiple data types), it matched or outperformed many more complicated systems that combine several kinds of data or use LLMs.
Why this matters: It shows that hearing patterns related to dialects—like timing, rhythm, and pronunciation—help the model notice the subtle changes in speech that can come with cognitive decline.
What does this mean going forward?
- Easier screening tools: A speech-only, end-to-end system is simpler to build and use. It could make early screening more accessible and more consistent across clinics and languages.
- Less complexity, more clarity: Without extra steps like speech-to-text, it’s easier to understand and maintain the system, and it may work better in real-world conditions.
- Multilingual promise: Because it learned from accents and dialects, the system can adapt to different languages and speaking styles, which is important for global use.
- Next steps: The authors note that some recordings include the interviewer’s voice. In the future, they plan to add a step to separate speakers more reliably, which could make the system even more accurate.
In short, VoxCog shows that teaching a model to be “dialect-aware” helps it pick up on speech changes tied to cognitive impairment, leading to accurate, multilingual, and simpler screening from voice alone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps that future researchers could address to strengthen, validate, and extend the findings reported in the paper.
- Quantify the specific dialectal cues that transfer to cognitive impairment detection (e.g., prosody, articulation rate, segmental/phonotactic patterns) and provide interpretability analyses linking learned representations to clinically meaningful speech markers.
- Conduct ablations to isolate the contribution of each component (dialect pretraining vs. LoRA adapters vs. 1D conv layers vs. data augmentation) to the observed gains, including comparisons to pretraining on non-dialect tasks (e.g., emotion, speaker traits, prosody).
- Test whether improvements persist when controlling for dialect group distributions; evaluate if models inadvertently learn dialect or demographic differences rather than disease-related speech changes.
- Perform fairness and bias analyses across age, gender, education level, region, and dialect groups to ensure equitable performance and to detect potential demographic confounds.
- Explicitly measure the impact of interviewer speech contamination on performance and verify whether robust diarization (and ASR-free speaker segmentation) improves accuracy and reduces confounds across datasets.
- Validate subject-level splitting rigor (to avoid segment-level leakage across folds) and clarify whether windowed segments from a subject are confined to a single fold during cross-validation.
- Provide statistical significance testing (e.g., paired tests, confidence intervals, bootstrap) for reported improvements over baselines and prior work, including effect sizes.
- Assess calibration and clinical utility metrics (ROC-AUC, sensitivity, specificity, PPV/NPV) to gauge screening suitability, rather than relying only on accuracy/Macro-F1/UAR.
- Analyze sensitivity to window size and stride (e.g., 5–30 s windows) and aggregation strategies (majority vote vs. probability averaging vs. weighted pooling) for subject-level predictions.
- Evaluate out-of-domain generalization by training on one corpus and testing on a distinct corpus (cross-corpus transfer), including task mismatch (picture description vs. reading vs. conversational command) and recording condition variability.
- Examine robustness to noise and channel variation beyond simple augmentations (far-field microphones, reverberation, overlapping speech, background TV/radio, telehealth settings), and compare with targeted enhancement/denoising front-ends.
- Explore multi-class and severity estimation (HC vs. MCI vs. AD; or clinical scores/regression) instead of only binary tasks; analyze misclassification patterns specific to MCI (early detection focus).
- Investigate longitudinal stability and sensitivity to change (test–retest reliability, progression monitoring) to support clinical follow-up scenarios.
- Report per-class recall/precision and error breakdowns (false positives/false negatives) to understand failure modes and their clinical implications (e.g., missing MCI vs. over-flagging HC).
- Clarify language-identification decisions (e.g., Whisper-based language detection for TAUKADIAL) and quantify misclassification rates that might mis-route recordings to the wrong dialect model.
- Characterize the dialect composition of each dataset (distribution, labels available) and assess performance differences across dialect strata to validate the dialect-aware hypothesis.
- Compare language-specific vs. multilingual backbones and parameter-efficient tuning strategies (full fine-tuning vs. LoRA vs. adapters) across languages; evaluate model size/latency trade-offs for deployment.
- Test alternative priors (e.g., emotion2vec, WavLM-prosody, speaker embeddings, fluency/stuttering models) to determine which pretraining source best transfers to cognitive impairment detection.
- Include classic interpretable acoustic baselines (e.g., articulation rate, pause duration, jitter/shimmer, speech tempo) and correlate them with model outputs for clinical interpretability and validation.
- Control for clinical/demographic covariates (age, sex, education, comorbidities, medication) where available to reduce confounding and assess incremental predictive value from speech-only models.
- Extend evaluation to additional languages/dialects not covered by Voxlect (beyond English, Spanish, Mandarin/Cantonese), particularly low-resource dialects, and measure transfer under substantial phonetic divergence.
- Analyze task-specific effects (reading vs. picture description vs. spontaneous conversation) and investigate task-invariant features vs. task-dependent cues that drive performance.
- Provide reproducibility details (random seeds, exact data splits, hyperparameter schedules, code/models availability) to facilitate independent verification and replication.
- Address ethical considerations and clinical safeguards (risk of misclassification, informed consent, transparency about dialect-sensitive modeling) when deploying speech-only screening tools.
Practical Applications
Immediate Applications
The following applications can be piloted or deployed now, leveraging VoxCog’s speech-only, multilingual, dialect-aware approach and its demonstrated performance on standard datasets.
- Healthcare (clinical pre-screening and telehealth triage)
- Use case: Rapid, non-invasive pre-screening for AD/MCI during intake or telemedicine visits using 1–2 minute speech tasks (e.g., picture description or reading).
- Sector: Healthcare
- Tools/products/workflows: VoxCog-powered screening API; EMR plug-ins; smartphone/web apps; telehealth integrations; 15-second sliding-window inference with subject-level aggregation.
- Assumptions/dependencies: Requires clinical calibration (thresholds, PPV/NPV), informed consent, adequate audio quality, diarization (if interviewer speech is present), fairness checks across dialects; screening aid only (not a diagnosis).
- Remote patient monitoring (RPM) in elder care
- Use case: Weekly voice check-ins via smart speakers or mobile devices to track cognitive risk trajectories and alert caregivers to changes.
- Sector: Healthcare, Eldercare
- Tools/products/workflows: Voice assistant skills (e.g., Alexa), RPM dashboards, automated scheduling of standardized tasks; secure data pipelines.
- Assumptions/dependencies: Consistent prompts and environments, caregiver engagement, privacy compliance (HIPAA/GDPR), device variability handling.
- Call centers and senior-services routing
- Use case: Real-time or near-real-time speech analytics during customer support calls to flag potential cognitive challenges and offer specialized assistance or follow-up.
- Sector: Software, Customer Support
- Tools/products/workflows: Contact-center analytics SDK; alerting and case-management workflows.
- Assumptions/dependencies: Explicit consent, robust speaker diarization, multilingual support; policy compliance to avoid discriminatory use.
- Clinical research recruitment and stratification
- Use case: Remote voice-based screening to identify eligible participants and stratify cohorts in dementia studies or trials.
- Sector: Academia, Healthcare
- Tools/products/workflows: Research pipelines using standardized tasks; segmentation-based scoring; integration with study management tools.
- Assumptions/dependencies: IRB approvals, participant consent, cross-language consistency in tasks; data quality controls.
- Education and training in speech-language pathology and neuropsychology
- Use case: Teaching modules that illustrate dialect-aware acoustic markers associated with cognitive decline.
- Sector: Education/Academia
- Tools/products/workflows: Classroom demos, lab exercises, annotated audio clips, simple dashboards.
- Assumptions/dependencies: Clear communication of model limitations; culturally appropriate task design.
- Developer SDKs for health apps
- Use case: Embed cognitive risk screening into mobile health applications or wellness platforms.
- Sector: Software
- Tools/products/workflows: Lightweight SDK with on-device/off-device inference options; LoRA-adapted backbones (Whisper, MMS-LID).
- Assumptions/dependencies: Device microphone quality, latency targets, licensing for backbone models, compute constraints.
- Multilingual clinic pilots (Spanish and Mandarin)
- Use case: Deploy screening in non-English settings using language- and dialect-aware models; localize task prompts and workflows.
- Sector: Healthcare
- Tools/products/workflows: Fine-tuned VoxCog variants for Spanish/Mandarin dialects; local clinical partners; cultural adaptation of tasks.
- Assumptions/dependencies: Adequate dialect coverage, locally validated thresholds, ground-truth labels for calibration.
- Community screening and public-health outreach
- Use case: Kiosk or mobile screening events offering immediate risk feedback and referral pathways.
- Sector: Public Health
- Tools/products/workflows: Simple web/mobile interfaces; local referral integration; non-diagnostic reporting.
- Assumptions/dependencies: Trained staff, fairness and accessibility oversight, connectivity and data governance.
- Care management (non-underwriting) in health plans
- Use case: Identify members who may benefit from cognitive support services; prioritize outreach.
- Sector: Finance/Insurance (care management only)
- Tools/products/workflows: Risk flags integrated into case-management systems; member consent workflows.
- Assumptions/dependencies: Strict policy boundaries to avoid underwriting use, fairness auditing, regulatory compliance.
- Data annotation and active learning
- Use case: Use dialect-sensitive embeddings to surface atypical prosody/phonetically deviant segments for expert review to improve dataset quality.
- Sector: Academia, Software
- Tools/products/workflows: Labeling platforms; active-learning loops; segment prioritization.
- Assumptions/dependencies: Annotator training; bias-aware sampling; representative coverage across dialects.
Long-Term Applications
These applications will require additional clinical validation, scaling, integration, or regulatory development before wide deployment.
- Regulatory-cleared diagnostic support tool
- Use case: FDA/CE-marked decision support for AD/MCI risk integrated into clinical workflows.
- Sector: Healthcare
- Tools/products/workflows: Multi-site trials; comprehensive documentation; post-market surveillance; explainability modules.
- Assumptions/dependencies: Rigorous validation, calibration across demographics/dialects, fairness audits, reimbursement pathways.
- Privacy-preserving on-device continuous assessment
- Use case: Smart speakers or wearables performing periodic speech evaluation entirely on-device with opt-in consent.
- Sector: Healthcare, Consumer Devices
- Tools/products/workflows: Model compression; hardware acceleration; federated learning; differential privacy.
- Assumptions/dependencies: Efficient inference, battery/compute constraints, privacy frameworks, robust local storage policies.
- Multimodal cognitive assessment platforms
- Use case: Combine speech-only VoxCog with diarization, ASR/NLP, cognitive test scores, and optional imaging/lab data for comprehensive evaluation.
- Sector: Healthcare, Software
- Tools/products/workflows: Unified pipelines; interpretable fusion; clinician dashboards.
- Assumptions/dependencies: Increased system complexity, reproducibility and maintenance, regulatory implications of multimodal diagnostics.
- Assistive robotics for eldercare
- Use case: Robots initiating conversational tasks and monitoring cognitive markers with personalized dialect adaptation.
- Sector: Robotics, Healthcare
- Tools/products/workflows: HRI design; on-device speech analytics; safe task scheduling.
- Assumptions/dependencies: Robustness to noise and movement, privacy and safety standards, caregiver acceptance.
- Global coverage and equity expansion
- Use case: Extend dialectal coverage to low-resource languages; ensure fair performance across global populations.
- Sector: Public Health, Academia
- Tools/products/workflows: Community data partnerships; ethical collection protocols; fairness benchmarks.
- Assumptions/dependencies: Funding, local stakeholder engagement, culturally adapted tasks, open benchmarks.
- Disease progression modeling and digital therapeutics
- Use case: Longitudinal voice biomarkers to predict conversion from MCI to dementia and measure response to interventions; adaptive voice-based cognitive exercises.
- Sector: Healthcare, Digital Therapeutics
- Tools/products/workflows: Longitudinal monitoring; outcome-linked analytics; personalized task generators.
- Assumptions/dependencies: Long-term datasets, causal validation, clinical trial evidence, adherence strategies.
- Workplace accommodations and cognitive safety
- Use case: Voluntary tools to detect sustained cognitive strain and recommend breaks or supports in safety-critical roles.
- Sector: Industry/HR
- Tools/products/workflows: Private assessments; wellness dashboards; opt-in policies.
- Assumptions/dependencies: Strong privacy protections, anti-discrimination safeguards, occupational health governance.
- EHR integration and population health analytics
- Use case: Automated documentation, alerts, and risk stratification across patient panels; integration with FHIR.
- Sector: Healthcare IT
- Tools/products/workflows: Interoperability layers; audit trails; clinician-facing controls.
- Assumptions/dependencies: Vendor collaboration, health-system change management, data governance.
- Extension to other neurological/psychiatric conditions
- Use case: Apply dialect-aware transfer to Parkinson’s, ALS, aphasia, depression, or TBI through condition-specific prompts and labels.
- Sector: Healthcare, Academia
- Tools/products/workflows: New datasets; task libraries; multi-condition screening suites.
- Assumptions/dependencies: Domain-specific validation, comorbidity handling, differential diagnosis complexity.
- Synthetic data augmentation for low-resource dialects
- Use case: Use high-fidelity accent generation and TTS to bolster training for underrepresented dialects.
- Sector: Academia, Software
- Tools/products/workflows: AccentBox/TTS pipelines; synthesis quality controls; bias monitoring.
- Assumptions/dependencies: Bridging synthetic-to-real gaps; licensing; human-in-the-loop validation.
- Policy frameworks and ethical standards for voice biomarkers
- Use case: Develop standards for consent, bias auditing, transparency, and acceptable use; establish reimbursement codes for screening.
- Sector: Policy, Public Health
- Tools/products/workflows: Multi-stakeholder consortia; audit protocols; reporting standards.
- Assumptions/dependencies: Consensus building, legislative/regulatory processes, payer engagement.
- Workforce training and operational auditing
- Use case: Training clinicians, call-center agents, and caregivers to interpret and act on voice-based cognitive indicators; continuous bias/quality audits.
- Sector: Healthcare, Industry
- Tools/products/workflows: Curriculum, certification, audit dashboards.
- Assumptions/dependencies: Resource allocation, ongoing monitoring, clear escalation pathways.
Glossary
- Acoustic representations: Feature spaces derived directly from audio signals used for modeling speech. "predominantly on acoustic representations"
- Alzheimer's Disease (AD): A neurodegenerative disorder characterized by progressive cognitive decline and dementia. "Alzheimer's disease (AD) is one of the most common neurodegenerative disorders"
- Articulation rate: The speed at which speech segments are produced, often measured in syllables per second. "slower articulation rate"
- Articulatory patterns: Movement and coordination characteristics of speech organs that shape sound production. "phonetic, prosodic, and articulatory patterns of a language"
- Automatic Speech Recognition (ASR): Technology that converts spoken language into text. "automatic speech recognition (ASR)"
- Backbone (model backbone): The core pretrained network providing feature extraction for downstream tasks. "as our backbone in training the dialect model"
- Cookie Theft picture: A standardized neuropsychological stimulus used in picture-description tasks for assessing language and cognition. "Cookie Theft picture"
- Cross-validation: A resampling strategy to evaluate models by partitioning data into training and validation folds. "3-fold cross-validation"
- Data augmentation: Techniques that modify training data to improve robustness and generalization. "data augmentations"
- Data-efficient prior: Prior knowledge that helps models achieve strong performance with limited data. "data-efficient prior"
- DementiaBank: A shared repository of speech datasets for studying cognitive impairment and dementia. "DementiaBank"
- Dialect-aware speech representations: Feature embeddings that encode dialect-specific patterns in speech. "dialect-aware speech representations"
- Dialect classifier: A model that assigns speech to dialect categories. "a dialect classifier"
- Dialect identification: The task of recognizing the dialect present in a speech signal. "pretrained dialect identification model"
- Dialect modeling: Computational methods for analyzing and predicting dialectal variation in speech. "findings in dialect modeling"
- Dialectal knowledge: Encoded information about systematic speech variation across dialects. "pre-trained models capturing dialectal knowledge"
- Elicitation task: A structured prompt or activity designed to evoke specific speech responses. "perform a predefined elicitation task"
- End-to-end speech-based model: A system trained directly from raw audio input to final prediction without intermediate hand-engineered stages. "end-to-end speech-based model"
- Ensemble: Combining multiple model predictions to improve overall performance. "a simple ensemble"
- Gaussian noise: Random noise with a normal distribution added to audio for augmentation or robustness. "adding Gaussian noise"
- Healthy Control (HC): Participants without diagnosed cognitive impairment used as a control group. "healthy control (HC) subjects"
- Inference time aggregation: Combining multiple segment-level outputs into a single prediction during inference. "inference time aggregation"
- Language modeling: Modeling the statistical structure of language for tasks like prediction or understanding. "language modeling"
- LLMs: Neural models trained on vast text corpora to perform language tasks. "LLMs"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank matrices into pretrained layers. "low-rank adaptation (LoRA)"
- Macro-F1 score: The average F1 score computed independently for each class, treating all classes equally. "Macro-F1 score"
- MMS-LID-256: A multilingual speech model focused on language identification across many languages. "MMS-LID-256"
- Multimodal ensemble-based computation: Systems that combine predictions across different data modalities (e.g., audio and text). "multimodal ensemble-based computation"
- Paralinguistic features: Non-verbal vocal cues such as pitch, intensity, and speaking rate that convey information beyond lexical content. "hand-crafted paralinguistic features"
- Polarity inversion: Audio augmentation that flips the signal’s polarity without altering its perceived content. "polarity inversion"
- Prosodic patterns: Rhythm, stress, and intonation features of speech. "phonetic, prosodic, and articulatory patterns of a language"
- Sliding window: A segmentation technique that extracts fixed-length overlapping chunks from continuous audio. "sliding window of 15 seconds"
- Speaker diarization: Partitioning audio into segments by speaker identity. "speaker diarization techniques"
- Subject-level prediction: A final decision aggregated per participant from multiple segment-level predictions. "subject-level prediction scores"
- Time stretching: Audio augmentation that changes duration without altering pitch. "time stretching"
- Unfreeze (model layers): Enabling gradient updates for previously frozen pretrained parameters during fine-tuning. "we unfreeze the pretrained LoRA and convolutional layers"
- Unweighted Average Recall (UAR): The average recall across classes without weighting by class frequency. "unweighted average recall (UAR)"
- Whisper-Large: A large pretrained speech recognition model used as a backbone. "We use the pre-trained Whisper-Large"
- x-vector: A fixed-length speaker embedding extracted from neural networks for tasks like speaker recognition. "x-vector-based systems"
Collections
Sign up for free to add this paper to one or more collections.

