- The paper introduces a novel framework, GraphWalk, which enables LLMs to perform multi-hop reasoning by navigating property graphs using deterministic, minimal tools.
- It demonstrates that tool-based navigation boosts maze traversal accuracy from 0–10% to 80–100% compared to conventional context-based approaches.
- Empirical evaluations on synthetic graphs reveal enhanced transparency, reduced hallucinations, and scalable performance even as graph complexity increases.
Introduction and Motivation
"GraphWalk: Enabling Reasoning in LLMs through Tool-Based Graph Navigation" (2604.01610) addresses a central challenge for LLMs: robust multi-hop reasoning over enterprise-scale knowledge graphs (KGs), where the underlying structured data are orders of magnitude larger than context windows allow. Incumbent solutions either rely on encoding subgraphs into prompt context, generating formal queries (e.g., Cypher/SPARQL), or injecting task/domain-specific toolchains. These approaches either collapse at scale or confound reasoning assessment by introducing domain knowledge leakage via parametric memory or engineered tools. GraphWalk introduces a minimalist, domain-agnostic agentic framework where off-the-shelf LLMs interact with the world exclusively through a small set of primitive graph operations—eschewing both finetuning and task-specific heuristics—to isolate and surface the structural reasoning capacity of LLMs over graphical data.
Framework Overview
GraphWalk positions the LLM as an agent that sequentially explores property graphs using deterministic primitive tools (neighbor retrieval, property enumeration, node lookup). Each tool invocation corresponds to a verifiable intermediate reasoning step, forming a transparent execution trace that enables introspection into the reasoning process. By evaluating exclusively on synthetic graphs with random, non-semantic labels, the framework precludes contamination from pre-trained world knowledge and guarantees that any observed performance is attributable to structural reasoning.
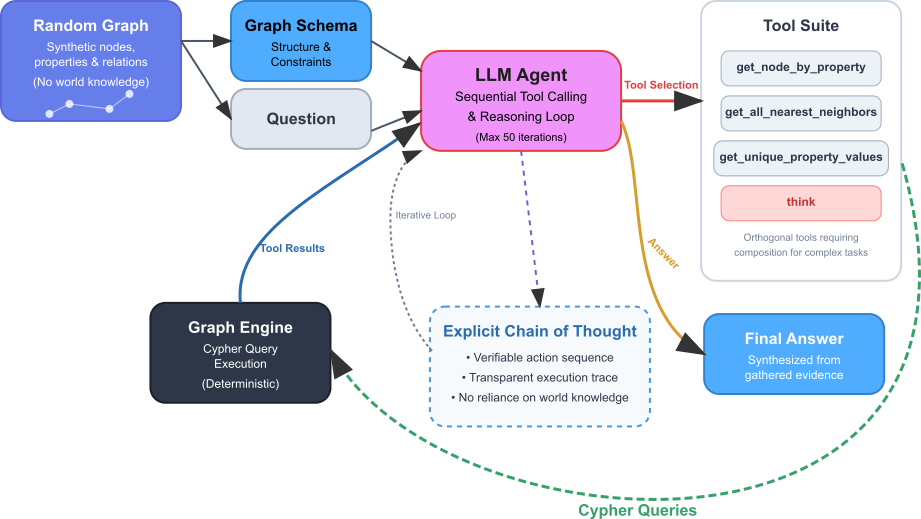
Figure 1: The GraphWalk agentic framework: the LLM explores arbitrary graphs using a minimalistic set of traversal and query tools, with each tool call forming a step in a verifiable reasoning trace.
Maze Traversal as a Concrete Instantiation
To provide intuition, the authors first apply GraphWalk to the maze traversal paradigm. Here, a 10x10 maze (representable within any model's context window) is modeled as a graph in Neo4j, with each cell as a node and ADJACENT edges. The agent is restricted to two navigation tools: (1) get_possible_next_cells(node_id), which returns valid neighbors and updates the exploration state; and (2) get_connected_path(), which validates and retrieves the explored path. Cell properties provide only minimal heuristic directionality via Euclidean distance to goal (non-informative for actual pathfinding due to wall occlusions). Critically, the agent must solve the exploration problem incrementally, never seeing the full maze layout at any time.
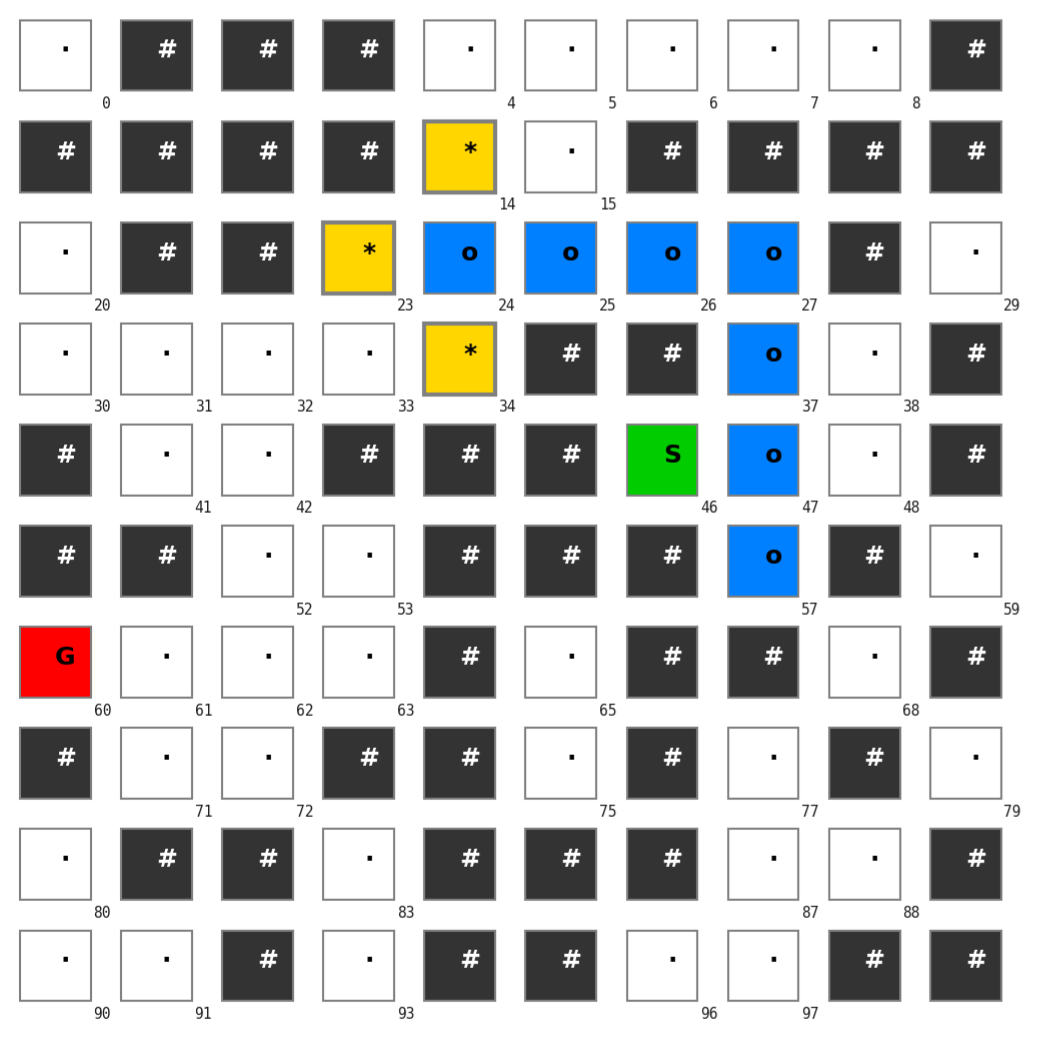
Figure 2: Agent exploration of a 10x10 maze midway: yellow cells are the outputs of the current tool step, blue are visited, and only white (unvisited) and black (walls) define the remaining search space.
Numerically, the impact is unambiguous: across GPT-4 and GPT-4o variants, non-reasoning LLMs given the entire maze context achieve 0–10% accuracy (often hallucinating non-adjacent jumps), while with tool-based navigation, accuracy soars to 80–100% even in models with no explicit multi-hop reasoning pretraining. Thus, navigation tools enable non-reasoning models to operationalize stepwise reasoning and outperform context-based inference even when the graph fits well within memory bounds.
Synthetic Property Graphs: Isolating Pure Structural Reasoning
To abstract from the spatially-interpretable maze setting, the framework scales to synthetic property graphs: node/edge classes, labels, and properties are randomly generated and devoid of semantic content. For each graph, a suite of twelve parametric query templates probes a wide reasoning spectrum—retrieval, aggregation, multi-hop traversal (k-hop pathfinding, indirect property selection), and first-order logical composition (conjunction, non-existence, property-based negation). As all ground truth is computed dynamically and none of the labels overlap with any LLM pretraining set, parametric knowledge and memorization are eliminated.
The toolset for this setting remains strictly minimal—node lookup, neighbor enumeration, property value enumeration, with an auxiliary think tool for chain-of-thought documentation. Tasks demand decomposition into multi-step query plans composed solely of those permitted operations.
Empirical Evaluation
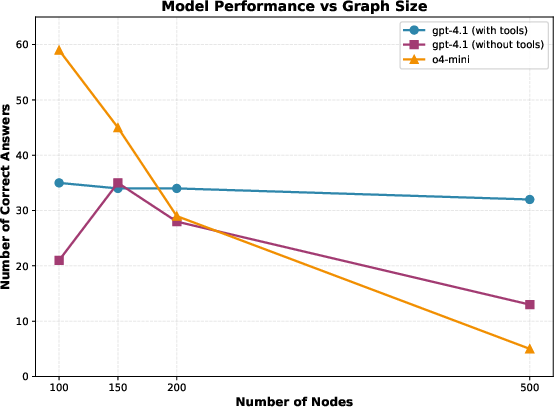
The ablation across seven LLM variants (OpenAI GPT-4.1, GPT-4o, o3/4-mini and nanoscale models) compares baseline no-tool (i.e., "perfect subgraph RAG") to the GraphWalk agentic framework. Evaluation is conducted across 12 query types, 10 random graphs per model (120 queries/model), at various node counts (100 to 500).
Key empirical findings:
Contradictory claim highlighted: Despite the intuition that larger context windows would solve KGQA scalability, GraphWalk demonstrates that tool augmentation is necessary for maintaining performance as graph complexity grows, even when raw context is sufficient to encode the full structure.
Analysis, Theoretical Implications, and Failure Modes
The empirical patterns reveal that fundamental limitations in LLM structural reasoning are independent of retrieval/extraction bottlenecks. Even with perfect subgraph provision, context-only processing fails to achieve multi-step explorational planning, complete search, or instruction adherence (e.g., output format compliance). Tool APIs grant the LLM not only the ability to decompose and update plans, but also enforce a traceable chain where each step is externally verifiable—a critical property for debugging and transparency in high-assurance environments.
Tool minimalism is central. Unlike previous approaches (e.g., KG-Agent [jiang2025kg]), which provide rich, task-specific toolkits that introduce confounds by embedding domain intelligence, GraphWalk restricts the toolbox to primitive operations, shifting all reasoning load to the LLM policy. This principled separation exposes the upper bounds of LLM reasoning capacity in isolation.
Failure modes include:
- Incomplete search with premature halting or local optimum fixation.
- Hallucinated answer anchors due to incorrect node grounding.
- Output format violations in the final step, even when correct intermediate "thoughts" are generated.
- Susceptibility to infinite reasoning loops in large, highly-connected graphs without re-planning or tool-invocation compaction.
Practical Implications and Future Directions
GraphWalk provides a foundation for scaling any LLM-graph integration architecture by advocating for agentic operation over tool APIs, generalizing to any graphical data regime (KGQA, supply chain analytics, spatial navigation, etc.). The minimal tool interface supports plug-and-play adaptation into any property graph backend (e.g., Neo4j, TigerGraph), and its transparency facilitates compliance in regulated or mission-critical environments.
As LLMs and context windows increase in capacity, the findings of GraphWalk indicate that genuine reasoning improvements will not be realized by scaling alone. Instead, architectural advances must empower LLMs with structured, tool-mediated interfaces that allow for verifiable, step-wise interaction with the underlying environment—whether for explainability, robustness, or scalability.
Open research directions include:
- Incorporating meta-reasoning mechanisms to escape infinite reasoning loops or to "compact" proof trees into concise outputs as tool traces lengthen.
- Extending to real-world KGs with fuzzy, incomplete, or evolving schemas while retaining reasoning transparency.
- Interfacing GraphWalk with emerging retrieval-augmented LLM architectures or integrating with sub-symbolic planners for hybrid agentic reasoning.
Conclusion
GraphWalk establishes a rigorous benchmark for evaluating LLM-based structural reasoning over arbitrary graphs using only a minimal, verifiable tool interface. The results underline that context scaling alone is not sufficient for robust multi-hop KG reasoning; rather, agentic, tool-driven architectures are essential for tractable, transparent, and scalable reasoning. This framework catalyzes efforts toward principled tool-augmented LLMs capable of functioning as reliable, explainable agents in complex, real-world environments.